Docker六脉神剑 (六) 1. Docker集群之Kubernetes(K8S) 了解k8s - 理论篇
到了k8s的文章了, 博主前面介绍了swarm集群, swarm集群本身相对来说比较简单、 轻量, 所以并没有重点介绍, 但是k8s不太一样, 这玩意还是比较复杂, 一两篇简单介绍不完, 所以博主这边得细说几篇, 最后也会做个实例, 方便大家参考。
选择swarm还是k8s,两者有什么区别?
- 背景不一样,
k8s是谷歌,swarm是官网方案 swarm轻量, 直接docker就有了,k8s还得安装且较为复杂。这里就出现一个点, 简单意味着部署运维成本低, 所以成本这方面,k8s要高不少- k8s集群完善, 最小单元
pod比swarm的service更加强大 - 还一个很重要的就是
k8s健康机制完善,Replication Controllers可以监控并维持容器的生命 - 在网络上
k8s选用Flannel作为overlay网络,可以让每一个使用Kuberentes的CoreOS主机拥有一个完整的子网。 - 组件这方面还是
k8s占据优势, 启动速度swarm要快, 它只需要两层交换, 而k8s需要五层 - 内置负载均衡
k8s要,比较完善 - 弹性伸缩: 弹性伸缩是指根据宿主机硬件资源承载的情况而做出的一种容器部署架构动态变化的过程。比如某台宿主机的
CPU使用率使用偏高,k8s可以根据Pod的使用率自动调整一个部署里面Pod的个数,保障服务可用性,但swarm则不具备这种能力。
两者架构图对比
- swarm
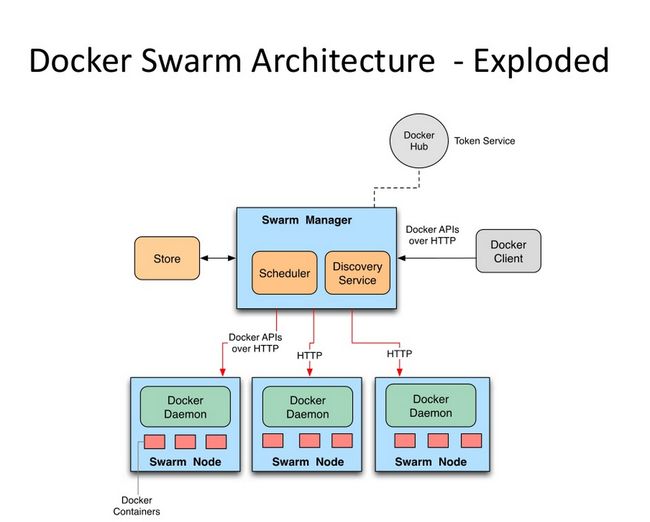
- k8s
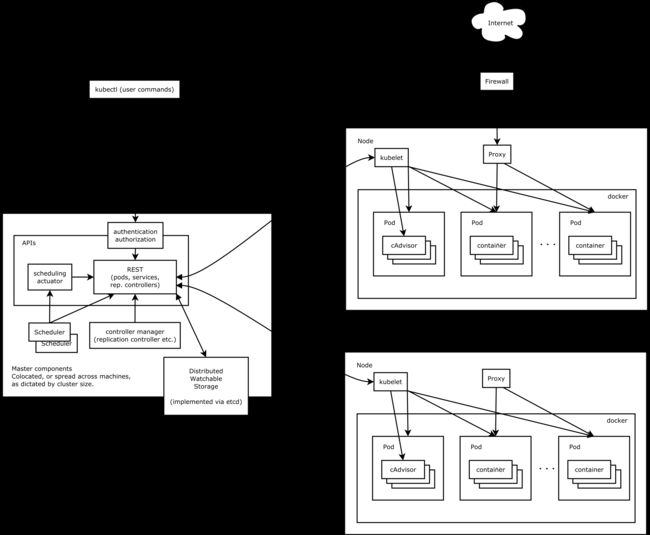
网上找的两张图, 大家可以看看, 明显k8s看着要线段要多, 等大家玩了这两个集群再来看看这个架构图比较好, 现在只是让大家看看里面的基本概念
k8s的重要知识点 (要想明白得懂啊,不懂也先看看)
一般高可用集群副本数据最好是 > 3 的奇数 (5,7,9...),主要是方便选举leader
- 非常重要,要考的, k8s最小单元pod
pod由一个或者多个为实现某个特定功能而放在一起的容器组成。在pod内的docker共享volume和网络namespace,彼此之间可以通过localhost通信或者标准进程间通信。
用pod有什么好处呢?
我们试想这样一个场景:我们有一个web应用的容器,现在我们为了收集web日志需要安装一个日志插件,如果把插件安装在web应用容器的里面,则会面临如下一些问题:
- 如果插件有更新,尽管
web应用没有变化,但因为两者共享一个镜像,则必须把整个镜像构建一遍; - 如果插件存在内存泄露的问题,整个容器就会有被拖垮的风险
- 如果把插件安装在不同的容器,同样也不合适,因为你要想办法解决插件所在容器读取
web容器的日志的问题。
有了pod以后,这些问题都可以迎刃而解。在pod里面为日志插件和web应用各自创建一个容器,两者共享volume,web应用容器只需将日志保存到volume,变可以很方便的让日志插件读取。同时,两个容器拥有各自的镜像,彼此更新互不影响。
- Pod 网络 flannel
pod之间能够通信网络, 需要部署网络, 其中就可以选择flannel来解决
- 复杂产品系统拆分之namepsace
在复杂系统中,团队会非常容易意外地或者无意识地重写或者中断其他服务service。相反,请创建多个命名空间来把你的服务service分割成更容易管理的块。
命名空间具有一定隔离性, 但是并不是绝对的隔离,一个namespace中service可以和另一个namespace中的service通信。
- apiserver
这玩意, 就是对外提供api的, 可以让更多客户端灵活控制集群, 例如我们后面使用的kubectl, 通过调用apiserver的api很方便对集群进行操作, 谁用谁知道, 真好!
- etcd
这可是个厉害的东西, 是一个单独项目, 在k8s是个很重要的组件etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值(key-value)数据库。etcd内部采用raft协议作为一致性算法,etcd基于Go语言实现。
整个kubernetes系统中一共有两个服务需要用到etcd用来协同和存储配置:
- 网络插件
flannel、对于其它网络插件也需要用到etcd存储网络的配置信息 kubernetes本身,包括各种对象的状态和元信息配置,当数据发生变化会快速通知kubernetes相关组件
- kubelet 代理人
在kubernetes集群中,每个Node节点都会启动kubelet进程,用来处理Master节点下发到本节点的任务,管理Pod和其中的容器。kubelet会在API Server上注册节点信息,定期向Master汇报节点资源使用情况,并通过cAdvisor监控容器和节点资源。可以把kubelet理解成【Server-Agent】架构中的agent,是Node上的pod管家。直接和容器引擎交互实现容器的生命周期管理
- controller-manager
运行控制器,它们是处理集群中常规任务的后台线程。逻辑上,每个控制器是一个单独的进程,但为了降低复杂性,它们都被编译成独立的可执行文件,并在单个进程中运行。
这些控制器包括:
- 节点控制器
(Node Controller): 当节点移除时,负责注意和响应。 - 副本控制器
(Replication Controller): 负责维护系统中每个副本控制器对象正确数量的Pod。 - 端点控制器
(Endpoints Controller): 填充 端点(Endpoints)对象(即连接 Services & Pods)。 - 服务帐户和令牌控制器
(Service Account & Token Controllers): 为新的namespace创建默认帐户和API访问令牌.
- scheduler
Scheduler负责Pod调度。在整个系统中起"承上启下"作用,承上:负责接收Controller Manager创建的新的Pod,为其选择一个合适的Node;启下:Node上的kubelet接管Pod的生命周期。
- 通过调度算法为待调度
Pod列表的每个Pod从Node列表中选择一个最适合的Node,并将信息写入etcd中 kubelet通过API Server监听到kubernetes Scheduler产生的Pod绑定信息,然后获取对应的Pod清单,下载Image,并启动容器。
- proxy
这也挺, 是做转发的, 还能实现内部负载均衡,例如说:
一般service在逻辑上代表了后端的多个Pod,外界通过service访问Pod。service接收到的请求就是通过kube-proxy转发到Pod上的。
每个Node都会运行kube-proxy服务,它负责将访问service的TCP/UDP数据流转发到后端的容器。如果有多个副本,kube-proxy会实现负载均衡。
- coredns
可以为集群中的svc创建一个域名IP的对应关系解析, pod之间可以直接利用coredns生成域名来进行访问
- dashboard
给集群提供B/S结构访问体系
- ingress controller
官方只能实现四层代理, 这玩意实现七层
- federation
跨集群中心多k8s统一管理
- prometheus
集群监控
- elk
集群日志统一分析介入平台
差不多了, 再啥有再更新吧, 这些理论总结于互联网, 我实在没法全面写出这些东西, 我白话一些没问题, 也当做个笔记, 看官们也可以整理一下这些概念, 看完这些再去看看架构图, 应该会清晰不少
结束语
博主之所以学习这个集群, 那完全是公司现在集群方面全转k8s了, 以前还是使用swarm的, 所以也没必要为了追求高端一点的技术选择k8s(但是现在阿里云已经将swarm下架了,没法在阿里上玩了), 不要增加了软件开发难度, 适合自己的最好。(不过使用阿里生态没得选了,阿伟)
综上所述???! 偏向于k8s, 果然, 越南的越吃香。下篇更新一下k8s的相关操作!!!!记得来看。
本文为作者原创,手码不易,允许转载,转载后请以链接形式说明文章出处。