深度学习-用PyTorch实现面部形象分类(非常详细-适合初学者)
文章目录
- 前言
- 一、数据集的介绍
-
- 1.下载数据集
- 2.下载的数据集介绍
- 二、数据处理
-
- 1.导入库
- 2.数据预处理
- 3.导入数据集
- 三、初始化参数
-
- 1.初始化超参数
- 2.构建Mish激活函数
- 四、构建模型
-
- 1.定义神经网络结构
- 2.实例化模型和定义优化器
- 五、前向传播
-
- 1.定义变量
- 2.定义训练函数
- 六、定义测试函数
- 七、开始运行
- 八、载入模型
- 总结
前言
学习了卷积神经网络之后,我就迫不及待地想找个数据集来练练手,花了三天时间完成了,模型效果不错,特写此文来一次复盘和给大家分享一下我的经验,希望我的文章对各位有所帮助。
一、数据集的介绍
1.下载数据集
我的数据集是在kaggle下载的,kaggle是一个有众多的开源数据集和比赛的平台,数据集可供大家免费下载。(如果大家在注册kaggle的时候也出现了验证码出不来的情况,是因为国内网站不支持,试试fq就可以了)
我选的数据集是关于面部形象分类的,数据集的名称是:Good Guys-Bad Guys Image Data Set,链接:面部形象分类数据集
数据集有614MB,下载之后解压有1.16G,解压后内容如下:

2.下载的数据集介绍
训练集有11220张图片,测试集有600张图片。标签分为两类:savory和unsavory,savory图片是“普通人”,而unsavory的图片来自被定罪的重罪犯。
百度翻译savory是令人愉快的;体面的;名声好的;好吃的,unsavory是:讨厌的,不良。这个翻译没有直观的感受,给大家上图看看:
savory:

有木有觉得他们给你的第一印象是友好的,是不是觉得他们是个好人
unsavory:
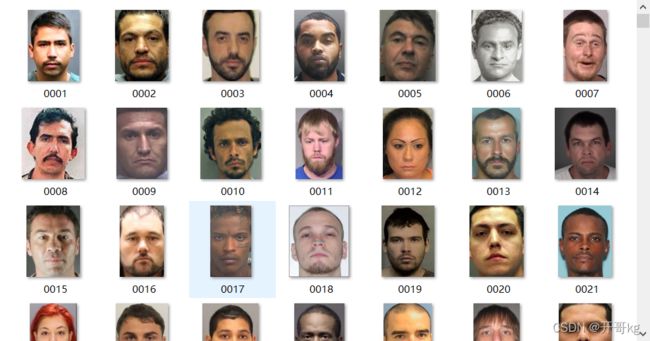
他们表情大多严肃,感觉桀骜不训,一看就感觉不是好人。
我们人的大脑是如何根据他们的特征来分类的呢?计算机又该如何识别,难道把特征一一列出来再传进去吗?那样会把自己累死,所以这些工作还是交给深度学习来处理吧!
二、数据处理
1.导入库
有很多库现在看不出是干嘛的,之后调用时就知道了
import torch#pytorch的库
from torchvision.transforms import Compose,ToTensor,Normalize,Resize#用于数据预处理
from torch.utils.data import DataLoader#可将数据集包装
import matplotlib.pyplot as plt#用于画图
import torch.nn as nn#用于构造网络模型
import torch.nn.functional as F#用于构造网络模型
import torch.optim as optim#调用优化器
import os#用于判断文件路径是否存在
import numpy as np#用于计算
import time#用于记录训练所用的时间
import cv2#可用于导入自己创建的图片
from torchvision.datasets import ImageFolder#用于导入数据
2.数据预处理
代码如下(示例):
transform =Compose([Resize([32,32]),ToTensor(),
Normalize((0.5988722 , 0.4951797, 0.44306183),
( 0.2429065, 0.22244553, 0.22060251))])
这里创建了一个名为transform的类,用于之后的数据转化,compose()的作用是把多个转化函数组合在一起再赋给transform,方便之后的处理,也就是说当你需要用到多个转化函数的时候,可以使用compose()。当只有一个转化函数时,可以不用compose(),例如:transform=ToTensor()。
Resize()的作用是改变图像大小,我们来看看换成高和宽为32*32的图像是怎么样的
新建一个文件1.py
代码如下:
import cv2
a=cv2.imread("E:/face_dataset/train/savory/0001.jpg")#导入一张图片
b=cv2.resize(a,(32,32))#改变图片大小
cv2.imshow("a",a)#展示原图
cv2.imshow("b",b)#展示改变后的图
cv2.waitKey()#等待响应
cv2.destroyAllWindows()#关闭所以窗口
a图:

b图:

原图为326x247大小,转化后很多特征消失了,不过还能看到大体的面部特征,有人可能会问,为什么要缩小图片成32x32?直接原图训练不行吗?首先不用原图是因为数据集的图片大小各不相同,要转化成相同的大小输入卷积神经网络才行,而且原图数据量为326x247=139202,相比转化后的32x32=1024数据量差了136倍,会使训练速度无敌无敌的慢,而且很容易过拟合。选择32x32也没特别的原因,首先一定要保证训练速度快,当出现欠拟合时,再考虑放大一下图片大小。
现在回到原代码,注意torchvision.transforms的Resize()用的是[]把高宽括起来,而cv2的resize()里面的高宽是用()括起来,我因为把这个搞错了,当时花了一个多小时来找bug,谨记!
改变图像大小后需将图片转换为张量,之后进行归一化处理,归一化的参数是经过计算得出的,计算的方法和为什么归一化可以参考我的这篇文章:
简单教你计算图片数据集的均值和方差
3.导入数据集
之后导入图片数据集和对图片进行预处理,代码如下:
train_loader=ImageFolder("E:/face_dataset/train/",transform=transform)
test_loader=ImageFolder("E:/face_dataset/test/",transform=transform)
测试集也应该和训练集进行数据预处理,有时候测试集的预处理方式可以与训练集不同,如为增大数据容量,对训练图片进行裁剪,旋转等,测试集可以不进行,但上面三种预处理方式测试集应该要和训练集相同。
接下来加载数据:
train_loader=DataLoader(train_loader,batch_size=64,shuffle=True)
test_loader=DataLoader(test_loader,batch_size=1000,shuffle=True)
DataLoader是一个包装类,能把数据包装成Dataset类,我们可以使用DataLoader这个类来更加快捷的对数据进行操作。
DataLoader有很多参数,这里讲解常用的三个参数,第一个是指定要包装的数据集,第二个batch_size是说明要把多少个数据包装在一起,最后整除不了的几个数据图片包装在一起,shuffle是要是否打乱数据集的顺序,建议打乱。
三、初始化参数
1.初始化超参数
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")#设定在gpu设备上训练
print(device)
n_epochs = 11#训练迭代次数
learning_rate = 0.01#初始学习率
momentum = 0.9#引入动量
random_seed = 1
torch.manual_seed(random_seed)#设定随机种子
建议大家使用GPU训练,可以大大地提高训练速度,安装CUDA失败的话可以看看是不是自己的python解释器选错了,我就是选错了,搞了4天都没搞好,最后去淘宝花了30元请人帮忙才搞定的,把解释器换到Anaconda上就解决了。
设定随机种子的目的是使每次运行代码的时候初始化的参数都一致,减小因参数的不同对模型训练的影响,可以把我们的注意力更多地放到修改模型结构和参数上,当确定模型和参数都没问题时,但loss还不收敛,可以改改随机种子,看看是不是因为初始化的参数影响了收敛。
2.构建Mish激活函数
每个初学者肯定都了解过relu激活函数,它确实很强,前几年一直统治着激活函数,但近几年出现一个新的激活函数Mish,使用Mish的模型有比relu更高的准确率和收敛速度,具体可了解:Mish:一个新的state of the art的激活函数,ReLU的继任者
现在我们来构建Mish激活函数:
class Mish(nn.Module):
def __init__(self):
super().__init__()
def forward(self,x):
x=x*(torch.tanh(F.softplus(x)))
return x
四、构建模型
1.定义神经网络结构
#定义神经网络结构
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()#继承父类参数
self.mish = Mish()#实例化激活函数
self.conv1 = nn.Conv2d(3, 30, kernel_size=5)#2d卷积操作,用于处理二维图片
self.bn1=nn.BatchNorm2d(30)#批量归一化
self.conv2 = nn.Conv2d(30, 60, kernel_size=5)#卷积核大小为5
self.bn2=nn.BatchNorm2d(60)#批量归一化
self.fc1 = nn.Linear(60*5*5, 90)#全连接层
self.fc2 = nn.Linear(90, 2)#二分类
def forward(self, x):#前向传播
x = self.mish(self.bn1(F.max_pool2d(self.conv1(x), 2)))#卷积>池化>批量归一化>激活
x = self.mish(self.bn2(F.max_pool2d(self.conv2(x), 2)))#卷积>池化>批量归一化>激活
x = x.reshape(-1, 60*5*5)#改变张量形状以输入到全连接层内
x = self.mish(self.fc1(x))
x = self.fc2(x)
return F.softmax(x,dim=1)#使用softmax获取每一种类的概率
现在来详细讲讲上面代码的含义:
首先第一个卷积层输入是3,是因为我们是数据集是彩色图片,有3通道,输出为30,代表用3x30=90个不同的5x5卷积核对图片提取特征,之后对图片数据进行池化,池化之后对数据进行批量归一化操作,批量归一化是近几年出来的技术,可以加速模型的收敛,减缓过拟合,减少对dropout的依赖,这也是我模型中不用dropout的原因,把归一化后的数据传给激活函数,再重复一次上述过程。
关于bn详解可参考这篇文章:【深度学习】Batch Normalizaton 的作用及理论基础详解
进行完卷积操作后要把数据传入全连接层,第一层全连接层有60x5x5=1500个神经元,故要把改变数据张量的形状,变成2维的张量,每行有1500个元素,reshape中的-1是自动计算其有多少行,如果大家使用reshape时报错,要看看元素总数是否可以被整除,如有3000个元素,reshape后变为2x1500形状的张量,如有3001个元素,reshape就会报错,我设定的每批次有64张图片,所以经过reshape之后变为64x1500大小形状的张量。
经过两层全连接层后,输出2个数,对这两个数进行softmax操作,使两数相加等于1,每个数就可以代表相关的概率了,dim=0代表对列进行softmax,dim=1代表对行进行softmax。
定义神经网络结构现在就完成了,大家可能会有疑问,模型结构里面的具体数字是怎么来的,现在给出说明,前两个卷积层输出30和60是后来调整得来的,刚开始我用的是12和36,最后训练发现训练集准确率一直在50%旁边徘徊,那就是说明这是欠拟合了,模型什么特征都没有学到,我试着提高模型复杂度,把数字改为60,120,训练10次,训练集准确率为90%多,测试集准确率为70%多,现在就是过拟合了,那就继续减小模型复杂度,最终改为30,60,训练集准确率为99.97%,测试集准确率为96.76%,效果很好。
而模型的第一个神经元个数又是怎么算的呢?首先初始输入的32x32大小张量经过2次卷积和池化后大小为:(32-5+1)/2=14,(14-5+1)/2=5,即大小为5x5,最后一层卷积输出为60个特征集,所以得到每张图片输入到全连接层的特征个数为60x5x5=1500个,全连接层的层数和第二层的神经元个数也是我后期调整得到的。所以我自己设计我网络模型最开始是很简单的,再根据效果慢慢微调得到。如果大家自己设计的模型无论怎么调,效果都不满意,可以试试一些经典的网络模型,如VGG,AlexNet等,这些网络模型是公认为不错的,这里我就不详细讲了。
2.实例化模型和定义优化器
定义了模型之后需要实例化模型,如模型需要用gpu训练,可以转移设备,代码如下:
network = Net()#实例化模型
network=network.to(device)#使模型用gpu训练
接下来定义优化器,我这里使用SGD优化器,即为动量小批量随机梯度下降法
optimizer = optim.SGD(network.parameters(), lr=learning_rate,
momentum=momentum)
把模型参数传进去优化器,在训练的时候,我们还可以动态地改变学习率,代码如下:
scheduler=torch.optim.lr_scheduler.StepLR(optimizer,step_size=525,gamma=0.5)
即为每隔一定步长,学习率乘以0.5,我们的模型每训练一次,即每批次步长=总图片量/批次大小=11220/64=175,我设置的步长是525,即训练迭代3次后学习率乘0.5
其实这段代码大家也可以不用,对于训练次数不多的模型,可以自己根据训练集的loss或准确率变化快慢来手动调学习率。
五、前向传播
1.定义变量
现在先定义一些之后要用到的变量
lr_list=[]#学习率
train_losses = []#训练的loss
train_counter = []#训练次数
precision=[]#准确率
x=0#训练批次次数,当做学习率的横坐标
2.定义训练函数
def train(epoch):
network.train()#定义网络为训练状态
correct=0
global x#把x当成全局变量,才能记录训练迭代次数
for batch_idx, (data, target) in enumerate(train_loader):#遍历数据集
data,target=data.to(device),target.to(device)#将数据集转移到gpu上训练
x+=1#记录迭代次数
optimizer.zero_grad()#把梯度清零
output = network(data)#前向传播获取输出结果
loss = F.cross_entropy(output, target)#用交叉熵计算误差
loss.backward()#反向计算求取梯度,更新参数
optimizer.step()#更新优化器
scheduler.step()#更新学习率
pred = output.data.max(1, keepdim=True)[1]#函数返回每一行的最大值和其索引,我们只需要它的第二个元素,即为其最大值索引
correct += (pred.eq(target.data.view_as(pred)).sum()).cpu()#计算预测的正确个数,注意,要当前数据在gpu,需转移到cpu才能添加到列表
lr_list.append(optimizer.state_dict()["param_groups"][0]["lr"])#获取优化器的学习率
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f},Accuracy: {}/{} ({:.3f}%)\n'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item(),correct, len(train_loader.dataset),
100. * correct / len(train_loader.dataset)))#打印进度,loss和准确率
train_losses.append(loss.item())#记录训练损失值
precision.append(correct / len(train_loader.dataset))
train_counter.append((batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset)))#记录训练次数
torch.save(network.state_dict(), './model/model_face.pth')#保存模型
torch.save(optimizer.state_dict(), './model/optimizer_face.pth')#保存优化器
六、定义测试函数
def test():
network.eval()#设置为测试状态
test_loss = 0
correct = 0
with torch.no_grad():#测试时不用记录梯度
for data, target in test_loader:#遍历图片和标签
data, target = data.to(device), target.to(device)#将张量放到gpu上训练
output = network(data)#获取输出结果
pred = output.data.max(1, keepdim=True)[1]#获取概率最大值索引
correct += pred.eq(target.data.view_as(pred)).sum()#计算比较正确个数
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.6f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))#打印测试准确率
各位可能注意到训练和测试函数前面有network.train()和network.eval(),这是用来设定模型是训练状态还是测试状态的,详细可看这篇文章:Pytorch的net.train 和 net.eval的使用
七、开始运行
至此,我们的定义工作已经完成,可以开始训练了。运行代码如下:
t_1=time.time()
for i in range(1,n_epochs):#训练n_epochs次
train(i)
t_2=time.time()
t=t_2-t_1
print("所用时间:",t)#记录训练所用时间
test()#测试
同时,我们也想可视化我们的参数,代码如下:
fig = plt.figure()#定义画布
plt.subplot(2, 2, 1)#把画布划分为2x2大小,取第一个位置
plt.tight_layout()#自动排版,防止文字与图片,文字与图片重合
plt.plot([a * 64 for a in range(x)], lr_list, color="r")#横轴为训练的n_epochs
plt.ylabel('lreaning rate')#可视学习率变化
plt.subplot(2, 2, 2)#取第二个位置
plt.tight_layout()
plt.plot(train_counter, train_losses, color="blue")#横轴为训练的次数
plt.ylabel('loss')#可视损失值变化
plt.subplot(2, 2, 3)#取第三个位置
plt.tight_layout()
plt.plot(train_counter, precision, color="green")#横轴为训练的次数
plt.ylabel('precision')#可视准确率变化
plt.show()#展示图片
运行如下:

我的电脑现状:


训练10次之后:


这里我只展示运行了10次的效果,大家可以继续训练,我训练集可达到99.97%,测试集可达到96.74,模型泛化效果不错。
八、载入模型
前面我只训练了10次,那么我想再训练几次要怎么做?难道是把n_epochs调大再重新训练吗?当然不用这么麻烦,我们前面的训练函数已经说明每迭代完64张图片就保存一次模型和优化器,我们只要载入模型就可以按上次的训练的参数和进度继续训练了,在开始运行的代码前加入下面代码:
if os.path.exists("./model/model_face.pth"): # 判断模型是否存在
network.load_state_dict(torch.load("./model/model_face.pth")) # 导入模型
optimizer.load_state_dict(torch.load("./model/optimizer_face.pth") #导入优化器)
这样再次运行就可以继续训练了
总结
这是我写的第一篇博文,没想到我心血来潮会写下这么多东西,这次总结又让我又学到了很多东西,本来还想继续写写利用此训练好的模型对自己选取的人脸进行识别分类的,想了想还是留给下次再补充吧!
希望我的文章对大家有所帮助,若有错误和不足,请大家指出批评。
参考文章
简单教你计算图片数据集的均值和方差
Mish:一个新的state of the art的激活函数,ReLU的继任者
【深度学习】Batch Normalizaton 的作用及理论基础详解
Pytorch的net.train 和 net.eval的使用