预测模型| 2. Nomogram文献抄读 (2): 如何建立和解读癌症预后列线图
今天分享一篇2008发表于JCO的列线图综述。
翻译水平有限,如有错误,请指正!原文在文末。
本次结合自身的拒稿经历来说明构建细节的重要性。

参考文献:Iasonos A, et al. How to build and interpret a nomogram for cancer prognosis. J Clin Oncol. 2008 Mar 10; 26(8): 1364-70.

目 录
摘要
介绍
步骤1:确定患者群体
步骤2:定义结局
步骤3:识别潜在的协变量
步骤4:构建列线图
选择模型
选择预测因子
a. 混杂因子/多重共线性
b. 交互作用
c. (变量性质) 转换
第5步:完成模型: 验证
交叉验证
Bootstrap 验证
外部验证
步骤6:解释最终的列图
步骤7:应用列线图
Go
摘要
列线图被广泛应用于癌症预后,主要是因为它们能够将预测模型量化为对事件概率的数值估计,这是针对单个患者的特点量身定制的。
然而,模型的统计学基础需要仔细检查,并且需要注意分数估算的不确定性程度。
本指南为非统计的读者提供了构建、解释和使用列线图来估计癌症预后或其他健康结果的方法学方法。
介绍
肿瘤学家和患者都希望得到针对每个患者的可靠预后信息。列线图与传统的TNM分期系统相比更有优势,因此已被提出作为一种替代或甚至是一种新的标准。列线图的个性化预测能力使其能够用于对参与临床试验的患者进行识别和分层。友好的界面和广泛的网络可用性相结合使得它们在肿瘤学家和患者中很受欢迎。
本文的目的是揭示列线图的开发过程,以便临床医生了解其统计基础。此外,我们提出了报告列线图的标准指南,以促进已出版列线图的正确使用。

步骤1:确定患者群体
数据来源:人群可以来自单中心、多个中心或基于人群的队列。来自多中心或基于人群队列的模型更具普遍性;然而,它们可能会受到缺乏一致且有用的变量,例如可以提高预后准确性的特异性肿瘤标志物。
评估数据质量:
数据是唯一的吗?
它能代表整个年龄谱吗?
它的治疗模式有代表性吗?
这些因素必须在建模之前考虑。
【刚开始学习列线图时并未读到该文,结果在投稿后被审稿人疯狂提问 - -!,审稿意见下】
步骤2:定义结局
列线图的构建需要对主要结局精确定义。结局通常是一个事件,如恶性肿瘤的诊断或事件发生的时间,如复发或死亡的时间。
【笔记:
结局定义不清容易被审稿人提问,如DFS (无病生存) 应把所有情况说明,类似还有LRRFS(无局部区域复发生存)等;
再如LR(局部复发)指明部位,那里复发才算局部复发。
其次,尽量不要用有包含关系的结局,例如DFS这种,它的对立事件包括了复发、转移等,有的审稿人会提议做竞争风险分析、有的会提议将结局分主次。血淋淋的教训!
列线图类文章不同于一般的临床回顾性研究,它可以做预测、可以被患者使用,如果定义不清会产生很多不良后果,要谨慎对待每一步。】

总的来说,在构建列线图时所有细节都有可能被提出质疑,因为这涉及到了一个预测准确性的问题。因此,我们在方法部分要仔细仔细再仔细。
刚开始投的时候被5个审稿人提了将近30个问题,但也感谢那些认真的审稿人。这让我去阅读了更多的文献,更加深刻的理解了该类型文章的行文思路与需注意的细节。
与列线图相关的审稿意见 ↓↓↓

从以上评论可以看出,几乎所有构建列线图的细节都未掌握:
- 研究核心目的不明;
- 人群选择受质疑;
- 协变量选择质疑;
- 缺乏外部验证;
- 列线图缺陷表述不全面。
上期文献抄读-1中所有需要注意的问题,均未注意【被拒稿了】

这位审稿专家所关注的是方法部分:
人群选择与治疗信息不完善;
以及对列线图应用性的质疑。

这位审稿专家所关注的是治疗信息与结局。
步骤3:识别潜在协变量
Prognostic parameters must be selected a priori, based on either prior research or sound clinical reasoning, so that excluding variables because of missing data is eliminated and consistent data collection is maintained
预后参数必须基于之前的研究或合理的临床推理预先选择,这样就消除了由于缺少数据而排除变量的问题,并保持了数据收集的一致性。
In published nomograms, the range of variables considered is usually determined based on data availability and clinical evidence rather than on statistical significance.
在已发表的列线图中,通常考虑的变量范围取决于数据的可用性和临床证据,而不是基于统计意义。
笔记:虽然大部分的列线图构建指南都在说变量选取基于临床意义,但大部分的研究还是基于统计学结果。
步骤4:构建列线图
1. 选择模型
一般是Cox或logistic回归。
2. 选择预测因子
2-1 研究人员首先从他们预期的可能对结果产生影响的协变量开始选择。统计检验可以确定数据是否支持这些最初的想法。
2-2 统计意义取决于结果效应的大小、样本大小和数据的差异 (方差)。
大型研究可以发现微小的差异,而小型回顾性研究可能无法发现重要的临床意义。
许多列图是使用回顾性或单机构数据库开发的。因此,可能没有足够的样本量来确定显著效应。
因此,考虑样本大小是很重要的。
根据Harrell’s guidelines,当结局为二分类时,两个分类数目的最小值应大于预测因子数目的10倍 (the minimum value of the frequencies of the two response levels should be greater than 10 times the number of predictors)
【笔记:例感兴趣结局为死亡,那么样本中死亡的人数=10*预测因子数目】
2-3 从统计学角度看,其他因素也可能影响统计显著性,可以改变对结果的影响程度或提供错误的影响估计。
混杂因子/多重共线性
混杂因素是与结果和模型中的其他独立预测因素相关的因素,但请注意,在这种关系中没有因果。
预测因子之间的关系,也就是所谓的多重共线性,会影响模型中的β系数,从而产生奇怪的关联,并可能导致不可靠的效果估计。
选用岭回归、主成分分析等变量选择的方法,不完全依赖于P值小于0.05为标准进行处理多重共线性,但这些方法还没有被应用于临床列线图,也许应该加以考虑。
b. 交互作用
交互作用是一种协同效应 (即两个或两个以上因素共同作用的方式)。这是一些模型尽管有很好的敏感性,但缺乏特异性的原因之一。

例如:年龄(<65 vs. >=65岁)和性别 (男vs女)有交互作用,则应为年轻和年长的男性患者以及年轻和年长的女性患者提供不同的预测。
c. (变量性质) 转换
【笔记:当数据间呈现非线性关系时,为了使列线图得到更好的结果,常会将数据进行转换,如样条函数。
很多文章在方法部分会将连续变量处理为分类变量,其使用的方法就有非限制性三次样条(RCS)这个曲线在R语言|0. R简介及临床研究应用实例介绍过,之后会介绍如何用R代码实现,这是个挺好用的连续变量转分类变量的方法】
第5步:完成模型: 验证
一个模型区分不同结果的病人的能力被称为区分度(Discrimination)。
预测与实际结果之间的距离称为校准(Calibration)。校准通常通过比较列线图预测概率图与实际概率图来评估。一个非常精确的列线图预测模型会得出这样一个图: 给定组的观察和预测概率会沿着45度线下降。概率置信区间(CI)的宽度取决于每组包含的患者数量,当组的人数越少,CI 的宽度越大。【即图中的黑线=CI】
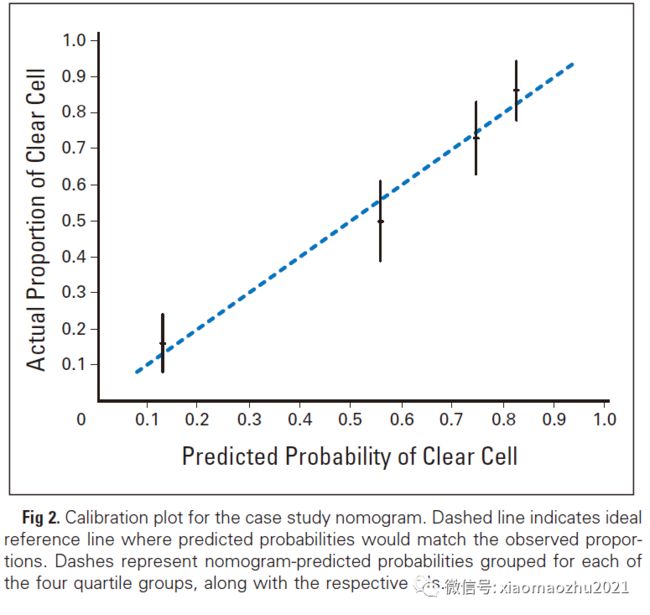
列线图的预测精度是通过一致性指数(C-index)来衡量的,该指数量化了预测概率和发生感兴趣事件的实际机会之间的一致性水平。
【C指数≈AUC(ROC的曲线下面积),二者可互相代替。例如C指数或AUC=0.8, 列线图预测一患者5年复发可能性为70%。则C指数和AUC评估模型得出结论:该列线图有80%的把握预测该患者的5年复发率为70%。注意,70%这个值有多精确要靠校准图来判断,校准曲线越接近45°线,这个结果越可信】
交叉验证
交叉验证和Bootstrap是防止过度解释当前数据的样本重用方法
Bootstrap 验证
外部验证
交叉验证和Bootstrap不能确保列线图外部适用性。列线图是否适用于新的患者群体是一个比过度拟合更值得关注的问题。
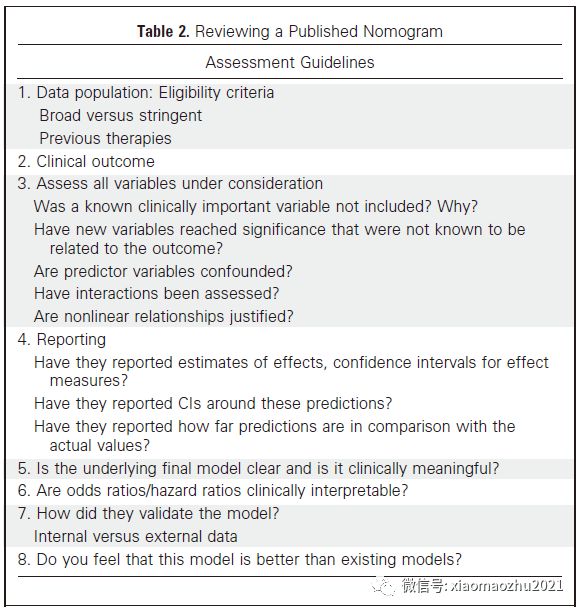
评估指南
步骤6:解释最终的列线图
列线图的有用之处在于,它将预测的概率映射到图形中从0到100分的刻度,各协变量累积的总分数对应着患者的预测概率。它代表了最不重要的变量与最重要的变量相比较的相对重要性。
【笔记:将个协变量的亚变量量化为分数,患者所具备的各亚变量相加后的总分对应概率为预测结果。】
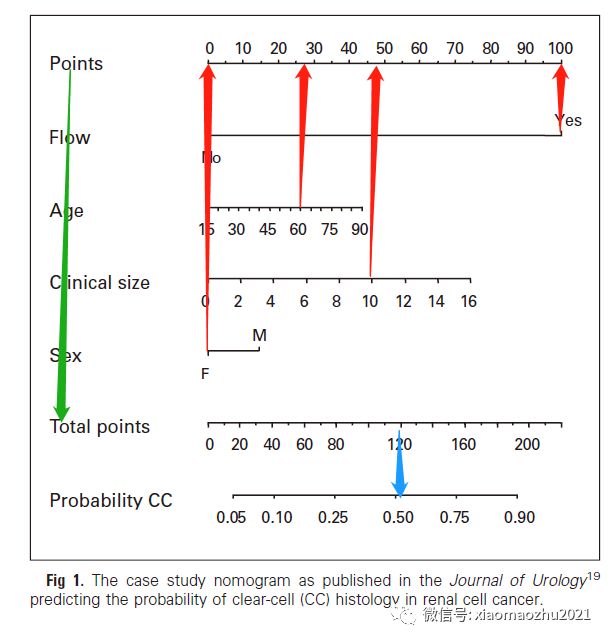
步骤7:应用列线图
临床医生应该理解列线图构建的方法论,这样才能恰当地进行预后评估。
应用列线图之前需要考虑的基本问题

参考文献


END
本公众号致力于打造一个实用的科研干货和临床学习资料分享平台,假如你有临床和科研上的问题或经验分享,请私信我。
感谢阅读,如有错误请指正!
