SQL分析——常见问题四
一、 where、having和on的区别
where与having的根本区别在于:
- where子句在group by分组和数据汇总
之前对数据行进行过滤; - having子句在group by分组和数据汇总
之后对数据行进行过滤;
在连接查询中,where和on的主要区别在于:
3. 对于内连接查询,where子句和on子句等效;
4. 对于外连接查询,on子句在连接操作之前执行,where子句(逻辑上)在连接操作之后执行;
二、表别名
/*
假如存在以下两个表t1和t2:
*/
create table t1
(
id int,
name varchar(10)
);
insert into t1 values
(1, 'tom');
create table t2
(
id int,
name varchar(10)
);
insert into t2 values
(2, 'jerry');
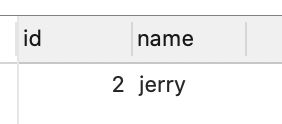
-- 请问,下面这条查询的结果是什么?
select t1.id, t1.name
from t1 t
cross join t2 t1
表的别名有效,局部变量优先
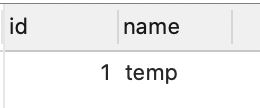
临时表:
-- 创建临时表t1
-- oracle不允许临时表和普通表名相同,SQL SERVER临时表必须以#开头,所以不存在此问题
create TEMPORARY table t1
(
id int,
name varchar(10)
);
insert into t1 values(1, 'temp');
-- 此时,下面查询语句的结果是什么?
select * from t1;
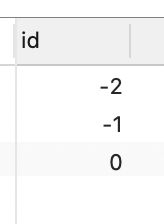
三、列别名
-- 假如存在以下表t3:
create table t3
(
id int
);
insert into t3 values
(0),(1),(2);
-- 请问,下面查询语句的结果是什么?
select -id as id
from t3
order by id
order by 按照别名排序
该查询等价于:
select *
from (
select -id as id
from t3
) t
order by id;
四、索引和性能优化
问题一:
-- 假如存在以下表和索引
create table t_index1
(
id int not null primary key,
i int,
dt date
);
create index idx1 on t_index1(dt);
-- 下面的查询语句有没有性能问题?
select *
from t_index1
where year(dt) = '2019';
索引字段如果使用了计算或函数,则索引会失效,使用了全表扫描:
![]()
优化:范围扫描索引
select *
from t_index1
where dt between date '2019-01-01' and date '2019-12-31';
![]()
问题二:
-- 假如存在以下表和索引
create table t_index2
(
id int not null primary key,
i int,
dt date
);
create index idx2 on t_index2(i, dt);
-- 下面的查询语句有没有性能问题?
select *
from t_index2
where i = 99
order by dt desc
limit 5;
没有性能问题:使用了常量的索引匹配和反向索引扫描:
![]()
问题三:
-- 为了优化下面两个查询,表t_index3中的索引有没有问题?
select *
from t_index3
where col1 = 99 and col2 = 10;
select *
from t_index3
where col2 = 10;
-- 表t_index3结构和索引如下:
create table t_index3
(
id int not null primary key,
col1 int,
col2 int,
col3 varchar(50)
);
create index idx3 on t_index3(col1, col2);
查询1没有问题:
![]()
查询2存在问题:因为where条件只使用了col2,不符合索引的最左的原则,所以没有使用到索引
![]()
优化:create index idx3 on t_index3(col2, col1);
问题四:
-- 假如存在以下表和索引:
create table t_index4
(
id int not null primary key,
col1 int,
col2 varchar(50)
);
create index idx4 on t_index4(col2);
-- 下面的查询语句有没有性能问题?
select *
from t_index4
where col2 like '%sql%';
有问题:模糊查询以%开头,索引会失效
![]()
问题五:
-- 假如存在以下表和索引:
create table t_index5
(
id int not null primary key,
col1 int,
col2 int,
col3 varchar(50)
);
create index idx5 on t_index5(col1, col3);
-- 下面两个查询语句,哪个性能更快?
select col3, count(*)
from t_index5
where col1 = 99
group by col3;
select col3, count(*)
from t_index5
where col1 = 99 and col2 = 10
group by col3;
语句一:使用了索引匹配

语句二:where中有col2,需要回表查询一次
![]()
所以查询1速度更快。
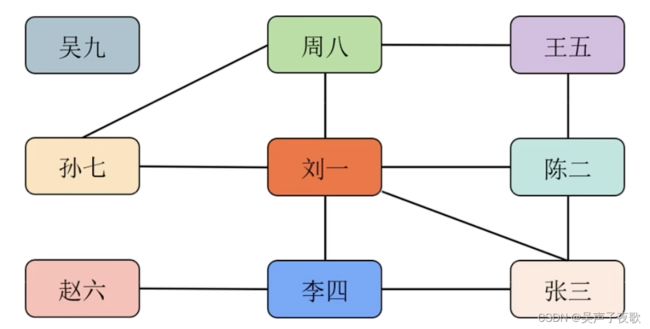
五、 社交网络关系
/*
社交网络是一个复杂的非线性结构,通常使用图(Graph)这种数据结构进行表示。对于好友这种关系,每个用户是一个顶点(Vertex),两个用户相互加好友就会在两者之间建立一条边(Edge)。
*/
create table t_user(user_id int primary key, user_name varchar(50) not null);
insert into t_user values(1, '刘一');
insert into t_user values(2, '陈二');
insert into t_user values(3, '张三');
insert into t_user values(4, '李四');
insert into t_user values(5, '王五');
insert into t_user values(6, '赵六');
insert into t_user values(7, '孙七');
insert into t_user values(8, '周八');
insert into t_user values(9, '吴九');
create table t_friend(
user_id int not null,
friend_id int not null,
created_time timestamp not null,
primary key (user_id, friend_id)
);
insert into t_friend values(1, 2, current_timestamp);
insert into t_friend values(2, 1, current_timestamp);
insert into t_friend values(1, 3, current_timestamp);
insert into t_friend values(3, 1, current_timestamp);
insert into t_friend values(1, 4, current_timestamp);
insert into t_friend values(4, 1, current_timestamp);
insert into t_friend values(1, 7, current_timestamp);
insert into t_friend values(7, 1, current_timestamp);
insert into t_friend values(1, 8, current_timestamp);
insert into t_friend values(8, 1, current_timestamp);
insert into t_friend values(2, 3, current_timestamp);
insert into t_friend values(3, 2, current_timestamp);
insert into t_friend values(2, 5, current_timestamp);
insert into t_friend values(5, 2, current_timestamp);
insert into t_friend values(3, 4, current_timestamp);
insert into t_friend values(4, 3, current_timestamp);
insert into t_friend values(4, 6, current_timestamp);
insert into t_friend values(6, 4, current_timestamp);
insert into t_friend values(5, 8, current_timestamp);
insert into t_friend values(8, 5, current_timestamp);
insert into t_friend values(7, 8, current_timestamp);
insert into t_friend values(8, 7, current_timestamp);
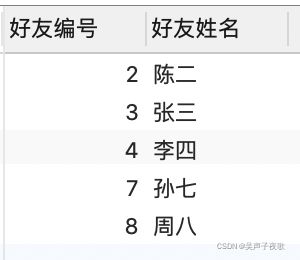
-- 查看好友列表
SELECT u.user_id AS "好友编号", u.user_name AS "好友姓名"
FROM t_user u
JOIN t_friend f
ON (u.user_id = f.friend_id)
WHERE f.user_id = 1;
-- 查看共同好友
-- 3号的好友id
with f1(friend_id) as (
select friend_id
from t_friend
where user_id = 3
),
-- 4号的好友id
f2(friend_id) as (
select friend_id
from t_friend
where user_id = 4
)
-- 共同好友
select f1.friend_id '好友编号', f3.user_name '好友名称'
from f1
join f2 on f1.friend_id = f2.friend_id
join t_user f3 on f1.friend_id = f3.user_id

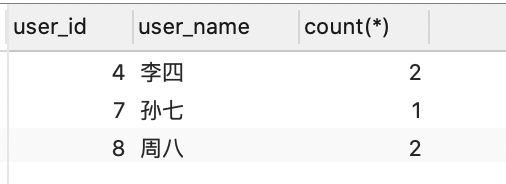
-- 推荐好友
-- 2号的好友
with friend(friend_id) as (
select friend_id
from t_friend
where user_id = 2
),
-- 2号好友的好友
fof(friend_id) as (
select f.friend_id
from t_friend f
join friend on f.user_id = friend.friend_id
-- 过滤掉2号自身
where f.friend_id != 2
-- 过滤掉2号已经有的好友
and f.friend_id not in (select friend_id from friend)
)
select u.user_id, u.user_name, count(*)
from fof
join t_user u on fof.friend_id = u.user_id
group by u.user_id, u.user_name
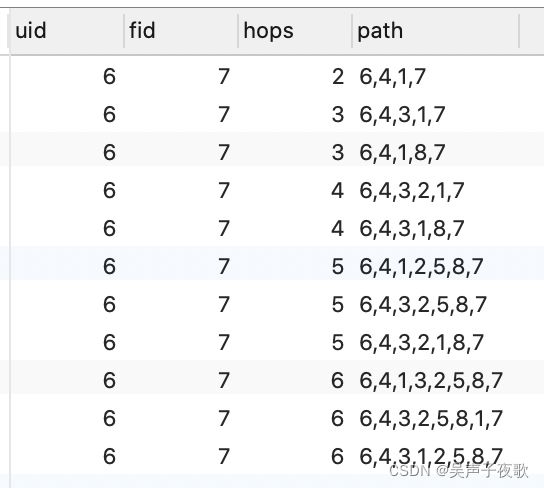
-- 关系链
WITH RECURSIVE relation(uid, fid, hops, path) AS (
SELECT user_id, friend_id, 0 AS hops, concat(',', user_id, ',', friend_id) AS path
FROM t_friend tf
WHERE user_id= 6
UNION ALL
SELECT r.uid, f.friend_id, hops+1, concat(r.PATH, ',', f.friend_id)
FROM relation r
JOIN t_friend f ON (r.fid = f.user_id)
-- 过滤掉重复路径
WHERE instr(r.PATH,concat(',',f.friend_id,','))=0
-- 路径长度要小于6
AND hops <= 6
)
-- 查询用户6到用户7之间的路径
SELECT uid, fid, hops, SUBSTR(path, 2) AS path
FROM relation
WHERE fid = 7
ORDER BY hops;
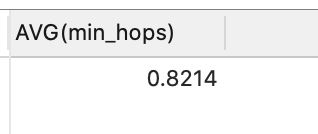
-- 平均最少间隔的人数
WITH RECURSIVE relation(uid, fid, hops, path) AS (
SELECT user_id, friend_id, 0 AS hops, concat(',', user_id, ',', friend_id) AS path
FROM t_friend tf
UNION ALL
SELECT r.uid, f.friend_id, hops+1, concat(r.PATH, ',', f.friend_id)
FROM relation r
JOIN t_friend f ON (r.fid = f.user_id)
WHERE instr(r.PATH,concat(',',f.friend_id,','))=0
),
mh(uid, fid, min_hops) AS (
SELECT uid, fid, MIN(hops) min_hops
FROM relation
GROUP BY uid, fid
)
SELECT AVG(min_hops)
FROM mh;
六、可疑支付交易监控
/*
银行客户交易流出存储在transfer_log表中:
*/
-- 创建交易流水表
CREATE TABLE transfer_log
( log_id INTEGER NOT NULL PRIMARY KEY,
log_ts TIMESTAMP NOT NULL,
from_user VARCHAR(50) NOT NULL,
to_user VARCHAR(50),
type VARCHAR(10) NOT NULL,
amount NUMERIC(10) NOT NULL
);
-- 初始化数据
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (1,'2019-01-02 10:31:40','62221230000000',NULL,'存款',50000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (2,'2019-01-02 10:32:15','62221234567890',NULL,'存款',100000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (3,'2019-01-03 08:14:29','62221234567890','62226666666666','转账',200000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (4,'2019-01-05 13:55:38','62221234567890','62226666666666','转账',150000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (5,'2019-01-07 20:00:31','62221234567890','62227777777777','转账',300000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (6,'2019-01-09 17:28:07','62221234567890','62227777777777','转账',500000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (7,'2019-01-10 07:46:02','62221234567890','62227777777777','转账',100000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (8,'2019-01-11 09:36:53','62221234567890',NULL,'存款',40000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (9,'2019-01-12 07:10:01','62221234567890','62228888888881','转账',10000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (10,'2019-01-12 07:11:12','62221234567890','62228888888882','转账',8000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (11,'2019-01-12 07:12:36','62221234567890','62228888888883','转账',5000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (12,'2019-01-12 07:13:55','62221234567890','62228888888884','转账',6000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (13,'2019-01-12 07:14:24','62221234567890','62228888888885','转账',7000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (14,'2019-01-21 12:11:16','62221234567890','62228888888885','转账',70000);
/*
1. 找出5天之内累积转账超过100万的账号
2. 找出相同收付款人5天内连续转账3次以上的记录
*/
-- 1. 找出5天之内累积转账超过100万的账号
select *
from (
select
*,
sum(amount) over(partition by from_user order by log_ts RANGE BETWEEN INTERVAL '5' DAY PRECEDING AND CURRENT ROW ) total
from transfer_log
where type = '转账'
) t
WHERE t.total>=1000000;

-- 2. 找出相同收付款人5天内连续转账3次以上的记录
select *
from (
select
*,
count(1) over(partition by from_user, to_user order by log_ts RANGE BETWEEN INTERVAL '5' DAY PRECEDING AND CURRENT ROW ) times
from transfer_log
where type = '转账'
) t
WHERE t.times >= 3;

七、地铁换乘线路查询
-- 北京地铁线路数据存储在表bj_subway中:
-- 创建地铁线路表
CREATE TABLE bj_subway(
station_id INT NOT NULL PRIMARY KEY,
line_name VARCHAR(20) NOT NULL,
station_name VARCHAR(50) NOT NULL,
next_station VARCHAR(50) NOT NULL,
direction VARCHAR(50) NOT NULL
);
-- 如何查找【王府井】到【积水潭】的换乘路线?
-- 查询“王府井”到“积水潭”的换乘路线
WITH RECURSIVE transfer (start_station, stop_station, stops, path) AS (
SELECT station_name, next_station, 1, CAST(CONCAT(line_name,station_name , '->', line_name,next_station) AS CHAR(1000))
FROM bj_subway WHERE station_name = '王府井'
UNION ALL
SELECT p.start_station, e.next_station, stops + 1, CONCAT(p.path, '->', e.line_name, e.next_station)
FROM transfer p
JOIN bj_subway e
ON p.stop_station = e.station_name AND (INSTR(p.path, e.next_station) = 0)
)
SELECT * FROM transfer WHERE stop_station ='积水潭';

八、销售排行榜
-- 创建示例表
create table products(
product_id integer not null primary key,
product_name varchar(100) not null unique,
product_subcategory varchar(100) not null,
product_category varchar(100) not null
);
insert into products values(1, 'iPhone 11', '手机', '手机通讯');
insert into products values(2, 'HUAWEI P40', '手机', '手机通讯');
insert into products values(3, '小米10', '手机', '手机通讯');
insert into products values(4, 'OPPO Reno4', '手机', '手机通讯');
insert into products values(5, 'vivo Y70s', '手机', '手机通讯');
insert into products values(6, '海尔BCD-216STPT', '冰箱', '大家电');
insert into products values(7, '康佳BCD-155C2GBU', '冰箱', '大家电');
insert into products values(8, '容声BCD-529WD11HP', '冰箱', '大家电');
insert into products values(9, '美的BCD-213TM(E)', '冰箱', '大家电');
insert into products values(10, '格力BCD-230WETCL', '冰箱', '大家电');
insert into products values(11, '格力KFR-35GW', '空调', '大家电');
insert into products values(12, '美的KFR-35GW', '空调', '大家电');
insert into products values(13, 'TCLKFRd-26GW', '空调', '大家电');
insert into products values(14, '奥克斯KFR-35GW', '空调', '大家电');
insert into products values(15, '海尔KFR-35GW', '空调', '大家电');
create table sales(
product_id integer not null,
sale_time timestamp not null,
quantity integer not null
);
-- 生成模拟销量数据
insert into sales
with recursive s(product_id, sale_time, quantity) as (
select product_id, '2022-04-01 00:00:00', floor(10*rand(0)) from products
union all
select product_id, sale_time + interval 1 minute, floor(10*rand(0))
from s
where sale_time < '2022-04-01 10:00:00'
)
select * from s;
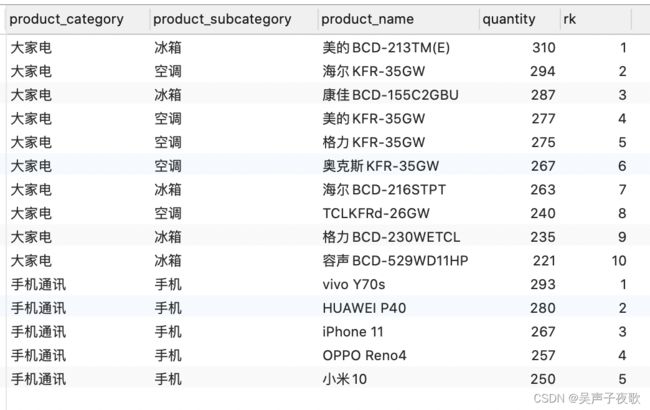
# 按照产品的分类,计算2022-04-01 09:00:00到2022-04-01 09:59:59一小时的销量排名
-- MySQL,其他数据库需要替换date_format函数
with hourly_sales(product_id, ymdh, quantity) as (
select product_id, date_format(sale_time, '%Y%m%d%H'), sum(quantity)
from sales
where sale_time between '2022-04-01 09:00:00' and '2022-04-01 09:59:59'
group by product_id, date_format(sale_time, '%Y%m%d%H')
),
hourly_rank as(
select product_category, product_subcategory, product_name, quantity,
rank() over (partition by ymdh, product_category order by quantity desc) as rk
from hourly_sales s
join products p on (p.product_id = s.product_id)
)
select *
from hourly_rank;
九、同比、环比以及复合增长率
/*
1. 同比增长:指本期数据与上一年度或历史同期相比的增长,例如产品2019年6月份的销量与2018年6月份的销量相比。
2. 环比增长:指本期数据与上期数据相比的增长,例如产品2019年6月份的销量与2019年5月份的销量相比。
问题:sales_monthly表中存储了不同产品每个月份的销量情况:
*/
-- 创建销量表sales_monthly
-- product表示产品名称,ym表示年月,amount表示销售金额(元)
CREATE TABLE sales_monthly(product VARCHAR(20), ym VARCHAR(10), amount NUMERIC(10, 2));
-- 生成测试数据
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201801',10159.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201802',10211.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201803',10247.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201804',10376.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201805',10400.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201806',10565.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201807',10613.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201808',10696.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201809',10751.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201810',10842.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201811',10900.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201812',10972.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201901',11155.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201902',11202.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201903',11260.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201904',11341.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201905',11459.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201906',11560.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201801',10138.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201802',10194.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201803',10328.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201804',10322.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201805',10481.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201806',10502.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201807',10589.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201808',10681.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201809',10798.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201810',10829.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201811',10913.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201812',11056.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201901',11161.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201902',11173.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201903',11288.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201904',11408.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201905',11469.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201906',11528.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201801',10154.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201802',10183.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201803',10245.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201804',10325.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201805',10465.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201806',10505.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201807',10578.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201808',10680.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201809',10788.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201810',10838.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201811',10942.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201812',10988.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201901',11099.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201902',11181.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201903',11302.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201904',11327.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201905',11423.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201906',11524.00);
-- 问题:如何分析每种产品每个月份的同比增长率和环比增长率?
-- 环比增长率
SELECT product AS "产品", ym "年月", amount "本期销量",
LAG(amount, 1) OVER (PARTITION BY product ORDER BY ym) "上期销量",
((amount - LAG(amount, 1) OVER (PARTITION BY product ORDER BY ym))/
LAG(amount, 1) OVER (PARTITION BY product ORDER BY ym)) * 100
AS "环比增长率(%)"
FROM sales_monthly
ORDER BY product, ym;

-- 同比增长率
SELECT product AS "产品", ym "年月", amount "本期销量",
LAG(amount, 12) OVER (PARTITION BY product ORDER BY ym) "去年同期销量",
((amount - LAG(amount, 12) OVER (PARTITION BY product ORDER BY ym))/
LAG(amount, 12) OVER (PARTITION BY product ORDER BY ym)) * 100
AS "同比增长率(%)"
FROM sales_monthly
ORDER BY product, ym;
-- 月均复合增长率
WITH s(product, ym, amount, first_amount, num) AS (
SELECT product, ym, amount,
FIRST_VALUE(amount) OVER (PARTITION BY product ORDER BY ym),
ROW_NUMBER() OVER (PARTITION BY product ORDER BY ym)
FROM sales_monthly
)
SELECT product AS "产品", ym "年月", amount "销量",
(POWER(1.0*amount/first_amount, 1.0/NULLIF(num-1, 0)) - 1) * 100
AS "月均复合增长率(%)"
FROM s
ORDER BY product, ym;
十、隐藏敏感数据
/*
为了保护个人隐私,应用系统在前端显示个人信息时需要将姓名、手机号、身份证号以及银行卡号等的部分信息进行隐藏,也就是显示为星号(*)
*/
# 隐藏姓名
SELECT name "隐藏之前",
CASE char_length(name)
WHEN 2 THEN concat('*', substr(name, 2, 1))
WHEN 3 THEN concat(substr(name, 1, char_length(name)-2), '*', substr(name, -1, 1))
ELSE concat(substr(name, 1, char_length(name)-2), '**')
END "隐藏之后"
FROM users;

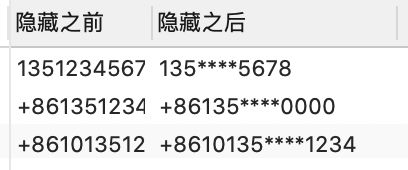
# 隐藏手机号
SELECT phone "隐藏之前",
insert(phone, char_length(phone)-7, 4, '****') "隐藏之后"
FROM users;
# 隐藏身份证号
SELECT id_card "隐藏之前",
insert(id_card, 7, 8, '*******') "隐藏之后"
FROM users;
