零基础教程--教你使用php-ml机器学习预测泰坦尼克号生还率案例
关于php-ml与php
随着人工智能的发展,越来越多的新技术涌现出来,无论是深度学习还是传统机器学习的出现,让整个技术可以实现更多的可能
本文作为启蒙科普文章,简单介绍机器学习基本技法,如果你是一个phper,看了这篇文章,对机器学习产生了极大的兴趣,那么文章最后面会给出指引学习路线,帮助更多的人去入门,去学习解决生活中更多的问题
学习目标
使用php-ml库的随机森林算法训练一个基本分类模型,预测泰坦尼克号上面
乘客的生存率
然后在kaggle(模型比拼网站)提交你的训练模型结果
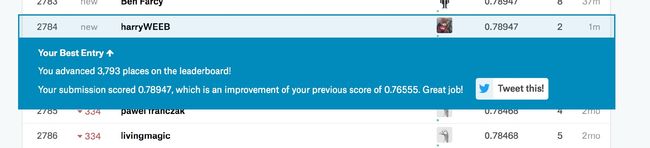
wow!这很酷!一共8000人参与了这次算法比赛,我使用php库训练的算法拿
到了2784名!你不准备动手试试?
php-ml库简介

这个库我最早是在2017年初看到的,当时在github上star只有寥寥几百颗
经过半年的迭代更新,这个库拥有了更多的star,但是我发现中文教程却是极
少,几乎没有什么中国文档(可能是中国phper都忙着赚钱了,手动滑稽)
php作为我的入门语言,我是非常感谢他的简单,实用主义,为我的人生带来
了很多不一样的精彩,虽然他使用场景比较单一,虽然我后来学习了更多
更有意思的语言,但是我依然忘不了那个夏天,用php在屏幕上打出hello world
那个时候激动的感觉,所以我这次选择了php来进行现在流行的机器学习,我
个人比较看好php未来的发展,swoole的诞生,让php拥有了新的不一样的
思路,再加上这次的php-ml,这更酷了!
我在文章最后简单的翻译一下文档列表,有兴趣的初学同学可以根据我翻译的中文
搜索更多的相关的内容,我收集了官方文档。翻译如果不准确,请指出修正
感谢!
数据准备与工具
数据data下载链接
php>=7.0
php-ml库
数据分析
在github上的数据包里面,我们可以看到有几个不同的csv文件
其中for_php_train.csv/for_php_test.csv是我已经处理好的数据
建议大家直接使用,在这篇科普启蒙文章里,我就不多说关于数据分析的内
容了,那些知识比较琐碎繁杂,我们这次着重关注机器学习
安装
composer require php-ai/php-ml代码编写
- 引入php-ml
require_once 'vendor/autoload.php';- 使用库中的两个类
use Phpml\Dataset\CsvDataset;
use Phpml\Classification\Ensemble\RandomForest;- 引入数据
$dataset = new CsvDataset('./data/for_php_train.csv',5,true);
$testset = new CsvDataset('./data/for_php_test.csv',5,true);- 分析数据列(可选)
$dataset->getColumns()- 提取数据中的特征与训练目标值
$sample = $dataset->getSamples();
$label = $dataset->getTargets();- 训练模型(随机森林算法)
$RandomForest = new RandomForest();
$RandomForest->train($sample,$label);- 使用测试数据预测结果
$result = $RandomForest->predict($testset->getSamples());- 组装结果,导出csv文件
$csv=[];
$csv[0]['PassengerId']='PassengerId';
$csv[0]['Survived']='Survived';
foreach ($result as $k=>$value){
$csv[$k+1]['PassengerId']=$k+892;
$csv[$k+1]['Survived']=$value;
}
var_dump($csv);
$file = fopen('write.csv','a+b');
$data = $csv;
foreach ($data as $value){
fputcsv($file,$value);
}
fclose( $file);查看结果并提交
wow!我们做到了,我们训练了第一个模型,并得到了结果!
让我们把他提交上去kaggle并获得你自己的分数吧!
总结
经过这次最最最基础的教程,恭喜你!你已经从机器学习的婴儿,迈出了婴
儿的第一步,接下来就是我们知识的补充与学习,如果你想在机器学习上
有所斩获的话,你还需要更多的知识来填充你的思路与想法!
下面是我写的另一篇文章,里面有关于机器学习的路线,come on!
学习路线文章
翻译php-ml列表目录
- Association rule learning 关联规则算法
- Apriori–这是十大经典挖掘算法之一
- Classification 分类算法
- SVC–SVM的分类形式
- k-Nearest Neighbors–knn算法,机器学习上,地位等同于于web经典的
hello world - Naive Bayes–朴素贝叶斯算法,P(A/B)=P(B/A)*P(A)/P(B),由贝叶斯公式变形的一种算法
- Decision Tree (CART)–决策树算法
- Ensemble Algorithms–集成算法
- Bagging (Bootstrap Aggregating)–自助法
- Random Forest–随机森林算法,后现代SVM
- AdaBoost–自适应迭代上升算法
- Linear–线性分类器
- Adaline–学习机
- Decision Stump–决策桩
- Perceptron–感知器
- LogisticRegression–逻辑回归,初学者必备算法
- Regression–回归算法
- Least Squares–最小平方法
- SVR–SVM的回归形式
- Clustering–聚类算法
- k-Means–经典聚类算法,常问:与knn区别?
- DBSCAN–基于密度聚类算法
- Fuzzy C-Means–模糊聚类算法,很有意思的算法
- Metric–度量方式(校验模型是否收敛较好的方法)
- Accuracy–准确率,关联信息,F1得分与召回率和查准率
- Confusion Matrix–混淆矩阵
- Classification Report–分类报告
- Workflow–工作流
- Pipeline–管道
- Neural Network–神经网络,近几年非常强大算法之一
- Multilayer Perceptron Classifier–多层感知器
- Cross Validation–交叉验证,必学的train/test/cv
- Random Split–随机分割
- Stratified Random Split–分层随机分割
- Preprocessing–数据预处理(数据清洗)
- Normalization–标准化
- Imputation missing values–补充缺失值,很好用
- Feature Extraction–特征提取
- Token Count Vectorizer–文本处理方式之一
- Tf-idf Transformer–文本方式处理方式之一,目的上解决减少频繁单词权重,增加冷门有决定因素单词权重
- Dimensionality Reduction–降低维度
- PCA (Principal Component Analysis)–降低维度高效方法
- Kernel PCA–套核的PCA
- LDA (Linear Discriminant Analysis)
- Datasets–数据结构
- Array
- CSV
- Files
- Ready to use:–官方准备的测试数据
- Iris
- Wine
- Glass
- Models management–模型惯例方法
- Persistency–持久性
- Math–数学结构与类型
- Distance
- Matrix
- Set
- Statistic
- Linear Algebra