程序读取txt文件(C++)识别图片语法进行修改
1.目的
有这样一篇Word文档我需要转为Markdown语法的格式,乍眼一看,214页,5W多字,有点累,想到了代码实现该问题,但是重复造轮子太麻烦了,我的具体操作步骤如下:

提出如下需求:
- 修改图片名
- 按照一级标题拆分文档,创建多个文档
2.使用Writage工具将文档转为Markdown格式
步骤较为简单,安装后另存为Markdown即可,具体步骤查看该链接
借助Writage,将 Word 转换为 Markdown
3.存在问题
3.1 图片格式问题
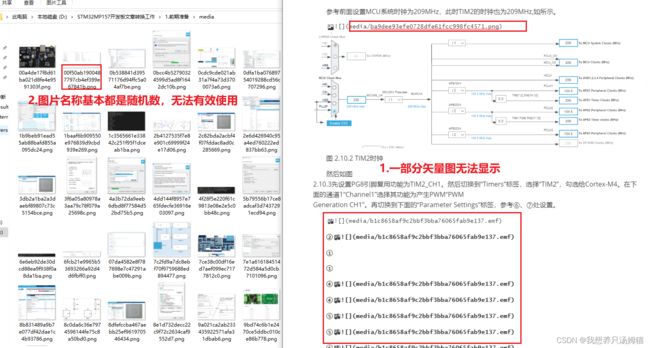
3.1.1 矢量图
作者当时在Word上编写文档时,这些标志都是矢量图,即和原图并不在一块,导致了上述情况的发生,一部分图片无法正常显示,即使显示也将无法到正常的位置,失去了意义。
- 需求:解决矢量图与原图组合之间的问题
- 解决:这个问题我还没有找到其他的解决方式,要么通过Word中的组合,或者直接重新截图完成,我重新截图了,没得办法。

3.1.2 语法中的图片名
图片中我们可以看出,直接转出来的图片名称应该是随机产生的,这样不利于讲图片上传到服务器,也不方便检索,因此提出新需求。
- **需求:**按照序号更换markdown图片语法中的名称,并注意图片相互对应
-
- 解决:查看4.2节
- 解决:查看4.2节
3.2 换行问题
在一些数字和英文前会突然换行,我还不清楚是怎么回事,这个问题手动改吧,起码使用程序解决了一部分问题。

- 需求:解决出现的这类断层换行问题。
- 解决:我感觉这应该是转换程序的bug,核对文档的时候手动更改吧,中文不难的,扫一眼就好。
3.3 无序列表格式部分错误
表现出的状况如下:
这些源文档中无序列表的符号在转换后的markdown文件中有一部分没有得到识别,应该是原文档中格式有点问题,转换不成功。
- 需求:更改无序列表转换不成功的问题。
- 解决:由于问题比较统一,所以这里可以直接复制转换后这个未识别的符号“ ”,使用Word的替换功能,将其替换为“ * ”,即可
3.4 代码无法正常识别转换为代码格式

虽然原文档中的代码格式很好,很方便识别,但是经过Writage转换后,失去了其较为明显的格式信息,且转换出的文本中也没有明显的标识,无法通过程序来修改(程序无法判断这是代码还是文本)。
- 需求:代码无法正常识别转换为代码格式
- 解决:没有特殊规律的问题,这部分情况只能通过手动解决,但是可以通过一些小方法提高下效率。
4. 文档预处理
4.1 标题等级提高
将现在的一级目录删除,将原先的二级目录提高到一级目录,原先的三级目录提高到二级目录。
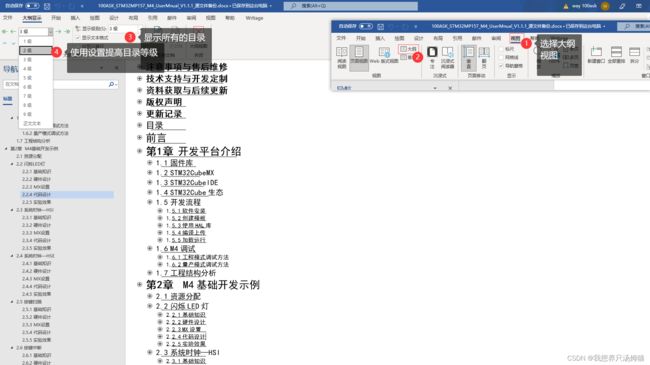
4.2 按照文章顺序获取word图片并批量改名
前面说道我需要让markdown文档中的图片按顺序重新命名,这样就需要更改markdown文档中所有markdown图片语法中图片的路径名称,修改路径名称的问题交给后面的程序去做,这里首先我们需要获取文档中图片的顺序,才可以进行下一步操作。
将源文件的docx后缀名更改为zip后缀,解压到当前目录。

按照图片步骤进行操作,即可获得符合文章顺序的图片
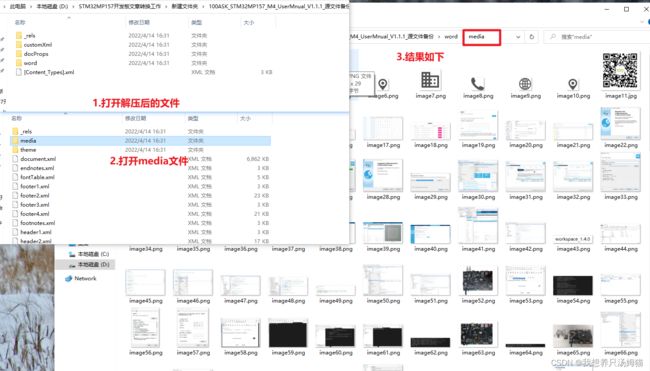
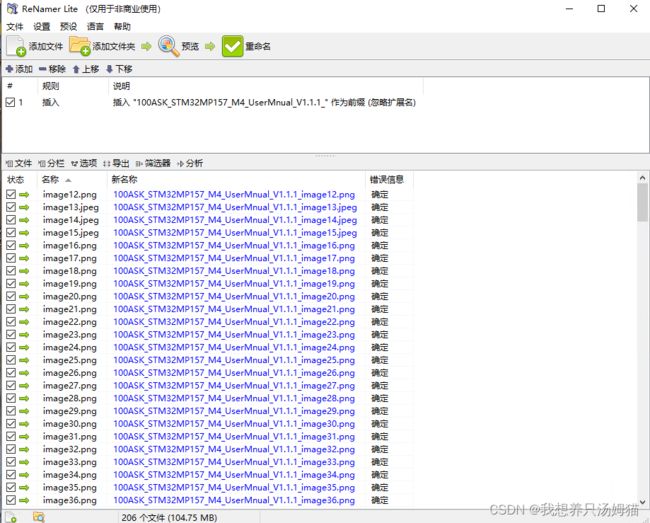
获取之后,查看文件名,基本符合要求,但是还需要统一添加一个前缀以防重复。
使用ReNamer工具统一添加前缀
4.3 md图片语法格式初步处理
在Word生成的Markdown文档中,有时候会出现这样的问题,导出的图片会自带一些属性文本,这一点不利于后续程序的处理,所以这里我们需要将其删除。

由于"[ ]“符号中间自动生成的文本不统一,但是我们确定它在” ![ "和“ ] ”之间,因此需要找到一款支持通配符替换的软件来完成该操作——Word。
将之前导出的md文件改为txt后缀,方便程序读写,更改完成后,使用Word打开该文件。
![]()
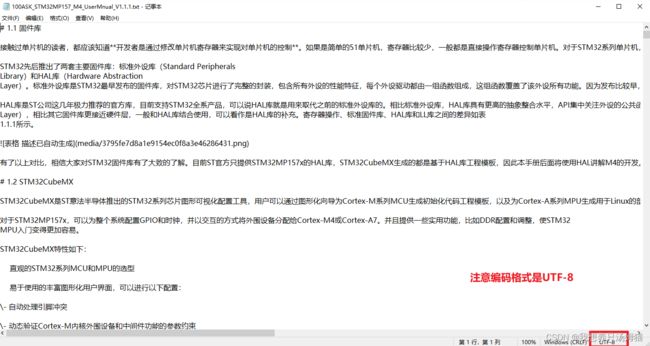
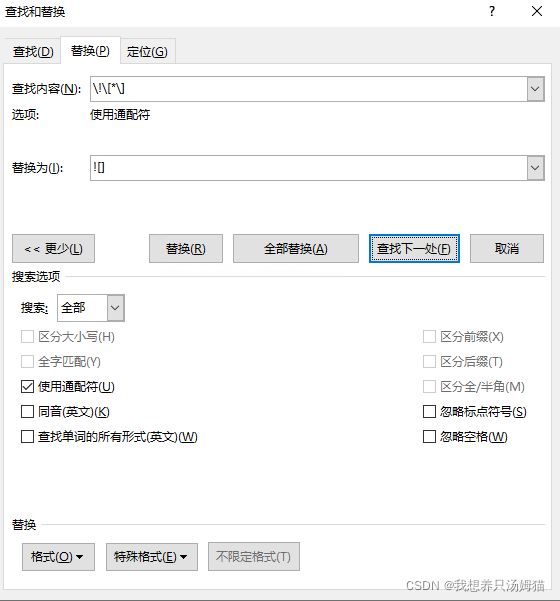
使用Word打开文件,使用通配符进行替换。

在查找内容的地方输入:
\!\[*\]
在替换为的地方输入
![]
点击全部替换

结果显示完成205处替换,恰好我们得到Word中的图片也只有205张,证明所有的图片格式均已经完成替换。
5. 进度分析
目前已经对由Word导出的markdown文档进行了初步格式修改。
获得目前修改好的txt文档,接下来还有两个事情需要程序来完成。
- 图片路径统一修改
- 按照章节拆分文档
6.代码实现
不想看下文的直接下载源码修改下用吧。
源码下载链接:CSDN下载
我这代码写的很乱,够用就行(0.0)
代码使用宏定义分为两步(其实不用也行,当时写程序的时候防止干扰来着),第一步为读取txt文本,更换图片markdown语法中图像的路径。第二步是根据当前的章节名拆分文件,将不同章节分割为不同的md文件保存。
程序只能在Windows下运行,在UTF-8转GBK格式时我调用了Windows的API。程序所使用到的头文件为:
#include 6.1 代码框架
代码里面注释很详细,就不讲了。

新建三个文件夹,用来存放输入文件和输出结果。

6.2 代码——更换内容中图像的路径名
ifstream InputFile(".\\InputFileStore\\100ASK_STM32MP157_M4_UserMnual_V1.1.1.txt");
ofstream OutputFile(".\\MedianFileStore\\100ASK_STM32MP157_M4_UserMnual_V1.1.1_PutOut.txt");
string filename;
/*
*因为英文在UTF-8文件中和ASCII文件中的编码是一样的,都只占据1个字符,所以这里使用string也可以
*/
string CurrentLine;
if (!InputFile) //读取失败
{
cout << "no such file" << endl;
return -1;
}
int ImageCount = 0;
while (getline(InputFile, CurrentLine)) // line中不包括每行的换行符
{
//当前行有图片,就批量更改图片的路径
if (CurrentLine.find(" + strlen(" - 1;
cout << "当前图像标识起始坐标位置:" << StartMarkPos << endl;
int EndMarkPos = CurrentLine.find(".png)") - 1;
cout << "当前图像标识结束坐标位置:" << EndMarkPos << endl;
int DifferenceValue = EndMarkPos - StartMarkPos;
cout << "所需更换字符长度:" << DifferenceValue << endl;
//目标格式:100ASK_STM32MP157_M4_UserMnual_V1.1.1_image1.png
//将图像计数的整型变量转换为字符串,使用stringstream类对象来规避预留空间的问题
string ReplaceCharater = "100ASK_STM32MP157_M4_UserMnual_V1.1.1_image";
stringstream ImageName;
ImageName << ReplaceCharater << ImageCount << ".png";
cout << "当前所更改的图像名:" << ImageName.str() << endl;
/*得到名字后,也知道标识符的位置了,现在该替换了*/
CurrentLine.replace(StartMarkPos + 1, EndMarkPos + 1, ImageName.str());
OutputFile << CurrentLine << endl;
cout << "********************************************************" << endl;
}
else //当前行没有图片,就正常输出
{
//正常输出文件
OutputFile << CurrentLine << endl;
}
}
InputFile.close();
OutputFile.close();
6.3 代码——拆分章节并保存为md文件
//C++的标准输出是ANSI的,控制台默认是GB2312的格式输出,这里更换成UTF-8才可以在不乱码地控制台输出章节名,
// 因为我txt文本的格式是UTF-8,更改控制台输出为UTF-8
//system("chcp 65001");
ifstream MedianFile(".\\MedianFileStore\\100ASK_STM32MP157_M4_UserMnual_V1.1.1_PutOut.txt");
if (!MedianFile) //读取失败
{
cout << "no such file" << endl;
return -1;
}
/*string NowLine:读取到的新行,但是新行是UTF-8格式的,在GBK2312控制台输出乱码*/
string NowLine;
int OneLevelNumber = 0;
string CurrentUsedFile = "";
while (getline(MedianFile, NowLine)) //读到新行,对文本来说就是段落
{
/*如果是一级标题,就将后续的行全部放入一个文件中,只在前10个字符中判断当前行是否是首行*/
/*string LineFirstN:前10个字符中判断是不是标题的标志*/
string LineFirstN;
LineFirstN = NowLine.substr(0, 10);
/*在程序内部通过ofstream去创建文件的话,文件编码是ANSI*/
ofstream NewChapterFile;
//如果当前行是新行,就创建新的文件,反之则将正常输出信息到当前文件
if ((LineFirstN.find("##") == LineFirstN.npos) && (LineFirstN.find("# ") != LineFirstN.npos))
{
if (OneLevelNumber != 0)
{
//先关闭之前打开的流,章节+1
NewChapterFile.close();
OneLevelNumber++;
}
else
{
OneLevelNumber++;
}
cout << "行的数目" << OneLevelNumber << endl;
/*string ChapterName:UTF-8格式的章节名,直接用来创建文件会乱码,需要转为GBK格式*/
string ChapterName;
ChapterName = NowLine.substr(LineFirstN.find("# ") + 2);
/*需要将读取到的UTF-8代码转为GBK2312*/
/*string NewCapterFileName:GBK格式的章节名*/
char* NewChapterName = (char*)ChapterName.data();
string NewCapterFileName = UTF8ToGBK((const char*)NewChapterName);
cout << "文件名:" << NewCapterFileName << endl;
/*string NewFileName:包含文件路径和文件名的变量*/
stringstream NewFileName;
NewFileName << ".\\FinalFileStore\\" << NewCapterFileName << ".md";
CurrentUsedFile.assign(NewFileName.str());
//创建txt文件,按照章节名命名
NewChapterFile.open(NewFileName.str()); // 采用默认模式,默认会清空文件内容然后再写入数据
//创建好了写入文本
NewChapterFile << NowLine << endl;
}
else
{
//以追加方式打开之前创建的文件,不清空原有数据
NewChapterFile.open(CurrentUsedFile, ofstream::app);
//创建好了写入文本
NewChapterFile << NowLine << endl;
}
}
6.4 代码——UTF-8格式转GBK
string UTF8ToGBK(const char* strUTF8)
{
int len = MultiByteToWideChar(CP_UTF8, 0, strUTF8, -1, NULL, 0);
wchar_t* wszGBK = new wchar_t[len + 1];
memset(wszGBK, 0, len * 2 + 2);
MultiByteToWideChar(CP_UTF8, 0, strUTF8, -1, wszGBK, len);
len = WideCharToMultiByte(CP_ACP, 0, wszGBK, -1, NULL, 0, NULL, NULL);
char* szGBK = new char[len + 1];
memset(szGBK, 0, len + 1);
WideCharToMultiByte(CP_ACP, 0, wszGBK, -1, szGBK, len, NULL, NULL);
string strTemp(szGBK);
if (wszGBK) delete[] wszGBK;
if (szGBK) delete[] szGBK;
return strTemp;
}
7. 校对工作
在刚开始我们使用Writage工具将Word转为初步的md文件后,还存在以下三个问题。
- 图片格式问题(程序已解决)
- 换行问题(未解决)
- 无序列表格式部分错误(Word替换解决)
- 代码无法正常识别转换为代码格式 (未解决)
因此目前还需要在校对工作中完成这两部分内容,这部分内容只能手动完成,但是可以提高一点效率。
7.1 typora代码块设置默认语言——快捷键
重新更换代码这一步骤时,常规操作是
- 输入~~~c
- 回车
- 在创建出来的代码块中输入代码
但是这样的话代码多的时候操作比较麻烦,还是快捷键方便,typora默认的代码块快捷键是Ctrl + shift + K,但是!这个键位太远了,而且快捷键创建的代码块中需要手动选择编程语言,更慢了,这会需要做两个事情。
- 更改代码块创建typora的快捷键
- 让代码快捷键创建的同时文本输出C,设置默认语言
7.1.1 typora代码块快捷键修改
参考链接:Typora设置代码块快捷键
为了方便一遍修改断行一遍添加代码段,我设置快捷键为"Code Fences": “Ctrl+P”,
7.1.2 ahk脚本设置
- 下载autohotkey 软件安装:官网下载链接
- 新建txt,填写下列代码(注意快捷键要和代码快捷键一致,并且在英文模式下才有效),修改后缀为ahk,双击运行
#IfWinActive ahk_exe Typora.exe
{
; Ctrl+Alt+K javaCode
; crtl是 ^ , shift是 + , k是 k键
^+k::addCodeJava()
}
addCodeJava(){
Send,{```}
Send,{```}
Send,{```}
Send,python
Send,{Enter}
Return
}
7.1.3 校对
接下里就一边修改代码段,一遍删除断行,这一步骤完成后基本也就完事了。
7.2 图像数量校对
7.2.1 当前符号排名
导出的文件(txt或md格式)在word中搜索符号可以得到当前搜索符号的计数,以及当前符号的排序,方便文档核对(Notepad++也可以达到这样的效果,但是只能计总数,不知道当前是第几个)。
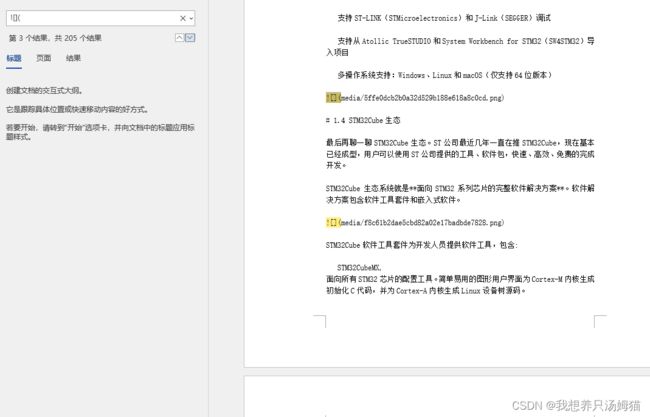
7.2.2 图像数量统计
- Word/WPS通用方法
打开导航窗格
输入
^g
即可查到当前图片的数目,并能查看到当前图片的序号排名。
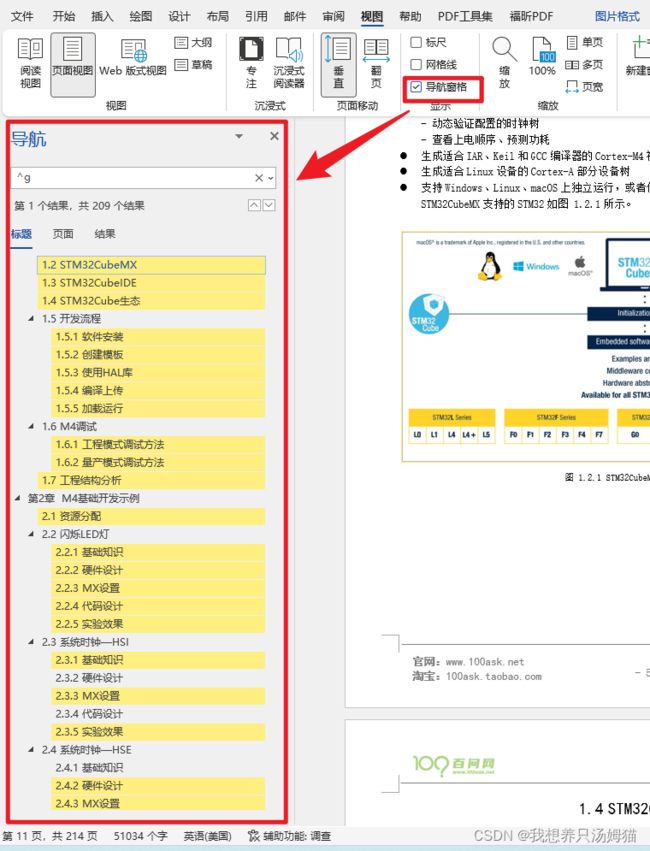
-
有时候会出现一些矢量图,我知道文档中有,但是我找不到在哪,这会可以使用WPS查看,视图比较方便。点击选择->选择窗格->右侧窗口。
看到那些矩形、文本框啥的,都是矢量图,截图合并吧,不然在解压出来的media文件夹中出现的emf格式图片就是这些东西,一点用都没有,还浪费序号。
