爬虫学习10月
爬虫学习
-
- 一、理解爬虫的操作步骤
-
- 1、首先理解http请求
- 2、理解URL
- 二、学习查找需要的url
-
- 1、首先本人推荐大家找url时使用谷歌浏览器
- 2、寻找url
- 三、爬虫进行伪装
- 四、学习爬json数据
- 五、学习使用xpath
- 六、学习找到内容所需要的xpath
一、理解爬虫的操作步骤
1、首先理解http请求

2、理解URL




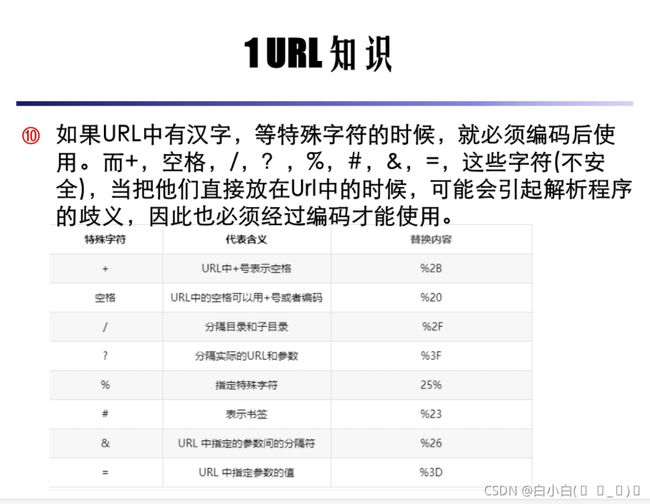
二、学习查找需要的url
1、首先本人推荐大家找url时使用谷歌浏览器
附下载地址:https://www.google.cn/intl/en_uk/chrome/
2、寻找url
在谷歌浏览器打开自己需要爬取的网页:https://lol.qq.com/data/newbie-what.shtml(以英雄联盟官网新手指引为例)
点击鼠标右键,或者敲击键盘F12:

假设要爬取本页面文字内容:
点击搜索键,将需要爬取文字放入搜索框中搜索:
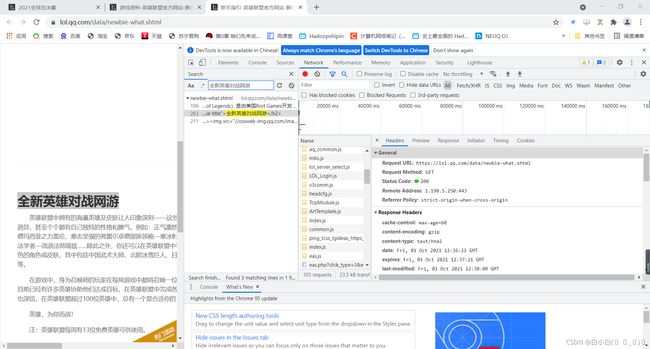
由此找到需要的URL
三、爬虫进行伪装
仍然以英雄联盟官网新手指引为例:
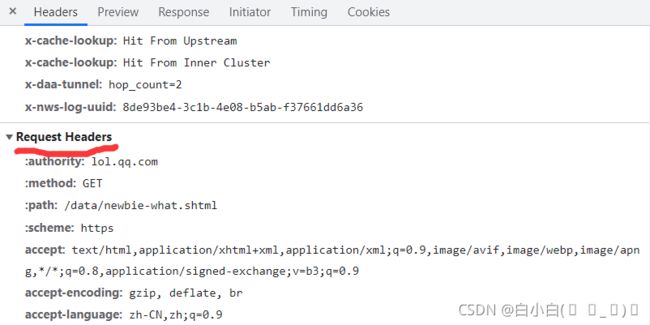
设置爬虫请求头headers,写成字典格式
常用headers:
headers={
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4651.0 Safari/537.36’
}
注:反反爬技术经常与请求头中的Cookies有关。
四、学习爬json数据
直接上例子:
这是从爬取了腾讯招聘网得每一类工作类别招聘的前五页招聘信息的具体内容(爬出来的数据未进行清洗处理)
import requests
import json
def pcid():
url="https://careers.tencent.com/tencentcareer/api/post/ByHomeCategories"
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52'
}
keyword={
'timestamp': '1632023467530',
'num': '6',
'language': 'zh-cn'
}
res=requests.get(url=url,headers=headers,params=keyword)
js=json.loads(res.text)
# print(js)
zhongleilist=[]
for i in range(6):
pcid1=js['Data'][i]['CategoryId']
zhongleilist.append(pcid1)
return zhongleilist
# pcid()
def postId(geshu):
url="https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1632021455041&num=6"
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52'
}
list1=pcid()
list2=[]
for i in range(len(list1)):
for j in range(1,5):
keyword={
'timestamp': '1632021455041',
'countryId': '',
'cityId': '',
'bgIds': '',
'productId': '',
'categoryId': '',
'parentCategoryId': int(list1[i]),
'attrId': '',
'keyword': '',
'pageIndex': j,
'pageSize': 10,
'language': 'zh-cn',
'area': 'cn'
}
res=requests.get(url=url,headers=headers,params=keyword)
js=json.loads(res.text)
PostIDlist=[]
for i in range(geshu):
PostID=js["Data"]["Posts"][i]["PostId"]
PostIDlist.append(PostID)
list2.append(PostIDlist)
return list2
print(postId(5))
def write():
url="https://careers.tencent.com/tencentcareer/api/post/ByPostId?timestamp=1632023166017"
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36 Edg/93.0.961.52'
}
list3=postId(5)
for i in range(len(list3)):
for j in range(len(list3[i])):
keyword={
'timestamp': 1632043000653,
'postId': int(list3[i][j]),
'language': 'zh-cn'
}
res=requests.get(url=url,headers=headers,params=keyword)
js=json.loads(res.text)
print(js)
write()
这是爬取了国家电网招标信息的前五页招标内容的具体信息:
import requests
import json
from lxml import etree
def Id():
url="https://ecp.sgcc.com.cn/ecp2.0/ecpwcmcore//index/noteList"
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.12 Safari/537.36'
}
list1=[]
for i in range(1,6):
data={
'firstPageMenuId': "2018032700291334",
'index': i,
'key': "",
'orgId': "",
'orgName': "",
'purOrgCode': "",
'purOrgStatus': "",
'purType': "",
'size': 20
}
res=requests.post(url=url,headers=headers,data=json.dumps(data))#post请求请求json格式,需要使用json=参数,或者data=json.dumps(data)参数
#在通过requests.post()进行POST请求时,传入报文的参数有两个,一个是data,一个是json。
js=json.loads(res.text)
for j in range(20):
ID=js["resultValue"]["noteList"][j]["id"]
list1.append(ID)
return list1
def NeiRong():
url="https://ecp.sgcc.com.cn/ecp2.0/ecpwcmcore//index/getNoticeBid"
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.12 Safari/537.36'
}
list2=Id()
count=0
for i in list2:
data=str(i)
res=requests.post(url=url,headers=headers,json=data)
js=json.loads(res.text)
count+=1
print(count)
try:
print("PURPRJ_NAME"+js["resultValue"]["notice"]["PURPRJ_NAME"])
except Exception:
print(i)
url01="https://ecp.sgcc.com.cn/ecp2.0/ecpwcmcore//index/getDoc"
header01={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.12 Safari/537.36'
}
resHtml=requests.post(url=url01,headers=header01,json=data)
resHtml.encoding="utf-8"
print(resHtml.text)
NeiRong()
五、学习使用xpath
仍然直接上例子(需要提前去学习xpath):
这是使用xpath爬取清华的所有系的系名:
import requests
from lxml import etree
def Html():
url="https://www.tsinghua.edu.cn/yxsz.htm" #https://www.tsinghua.edu.cn/xxgk/zzjg.htm
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4651.0 Safari/537.36'
}
res=requests.get(url=url,headers=headers)
print(res)
res.encoding="utf-8"
html=res.text
html=etree.HTML(res.text)
title=html.xpath('//*[@class="yxszBox"]//div//ul//li//a//text()')# //*[@class="organization"]//ul//li//a//text()组织机构
print(title)
Html()
这是爬取了58同城的二手房的信息:
import requests
from lxml import etree
from lxml import html
def ershou(list1):
list2=[]
url2='https://bj.58.com/ershoufang/?PGTID=0d30000c-0000-16d3-a519-bad0adebbd10'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4651.0 Safari/537.36'
}
reqs2=requests.get(url=url2,headers=headers,verify=False)#proxies=proxy
reqs2.encoding='utf-8'
html2=etree.HTML(reqs2.text)
list3=[]
for i in list1:
if i=='//*[@class="property-content-info-text property-content-info-attribute"]':
title=html2.xpath(i)
for j in title:
list3.append(j.xpath('string(.)'))
list2.append(list3)
else:
title=html2.xpath(i)
list2.append(title)
return list2
def Write():
xpathList=['//*[@class="property-content-title"]//h3//text()','//*[@class="property-content-info-text property-content-info-attribute"]','//*[@class="property-content-info-comm-address"]//text()']
list4=ershou(xpathList)
for i in range(len(list4[1])):
a=list4[0][i],list4[1][i],list4[2][i]
with open(r"D:\Users\lenovo\Desktop\王志磊.xls",'a',encoding='UTF-8-SIG') as f:
f.write(str(a).replace("'"," ")+'\n')
Write()
六、学习找到内容所需要的xpath
首先:
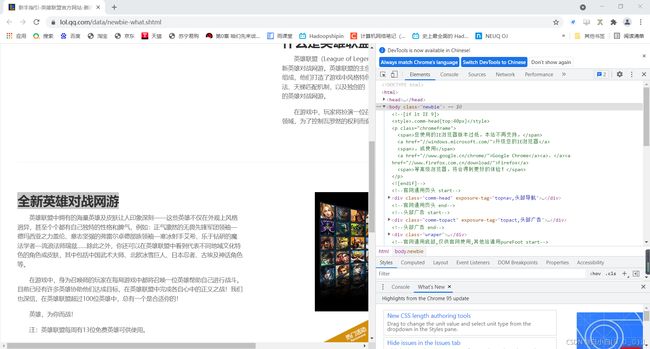
点击标红处:
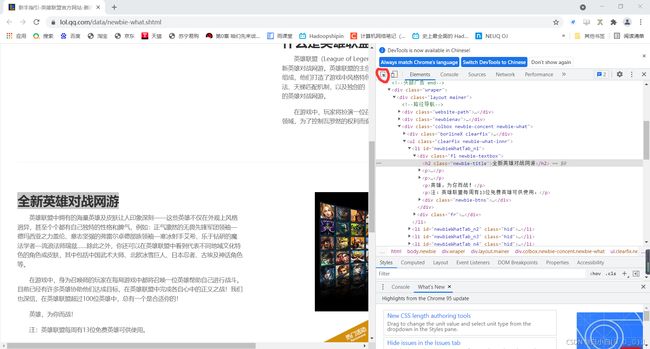
然后鼠标点击需要爬取的内容,Elements会自动匹配html中的内容。
键盘敲击Ctrl+f:
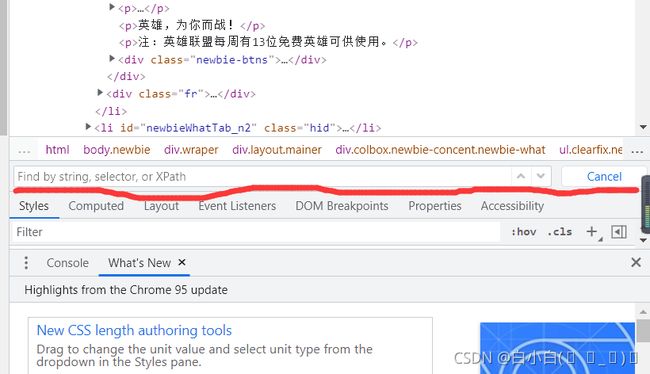
可以在里面输入自己的xpath,来匹配内容。
#####################################################
或者谷歌浏览器打开开发者功能,下载拓展包xpath Helper,添加进谷歌拓展包中,键盘Ctrl+Shift+x,可以打开该拓展包(更加直观的可以看到xpath路径下对应的内容):
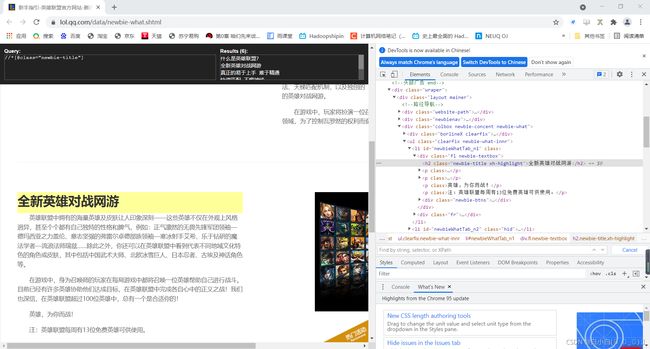
具体xpath内容需要花时间去学习。。。。。。。。。。。。。。