Kafka 3.x 三万三千字精讲(侧重原理)
Kafka 3.x
- 一、Kafka原理
-
- 1.Kafka基础架构
-
- 1)发布订阅模式
- 2)架构模型
- 2.生产消息原理
-
- 1)原理概述
- 2)数据可靠性
- 3.broker工作原理
-
- 1)kafka在zk上存储的信息
- 2)副本Leader选举流程
- 4. 故障处理(Offset / HW / LEO)
-
- 1)正常情况
- 2)Follower故障
- 3)Leader故障
- 5.Topic副本存储原理
-
- 1)存储机制
- 2).log / .index / .timeindex
- 3)存储细节
- 4) 分区副本分配
-
- a. 自动分区
- b.手动分区
- 6.消费者原理
-
- 1)消费者组
- 2)消费流程
- 3)消费者组初始化
- 4)消费者组的工作流程
- 5)消费分配策略
-
- a. Range模式
- b. RoundRobinAssignor
- c. StickyAssignor
- 二、Kafka集群安装
-
- 1.初始安装
-
- 1)下载kafka安装包
- 2)集群规划
- 3)集群安装
- 4)集群启动与关闭
- 2.节点上线与下线
-
- 1)新节点上线
- 2)副本再分配
- 3)老节点下线
- 三、kafka命令行操作
-
- 1.topic相关的命令
-
- 1)常用参数
- 2)创建topic
- 3)查看topic信息
- 4)查看、修改、删除topic
- 2.生产者与消费者相关命令
- 四、Kafka的Java API
- 五、附录
- 六、鸣谢
一、Kafka原理
1.Kafka基础架构
1)发布订阅模式
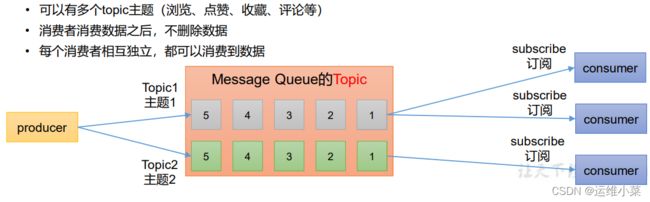
- 生产者生产数据,将数据分批分主题地发送到消息队列中
- 订阅者(消费者)消费数据,可以有多个消费者消费同一批消息
2)架构模型
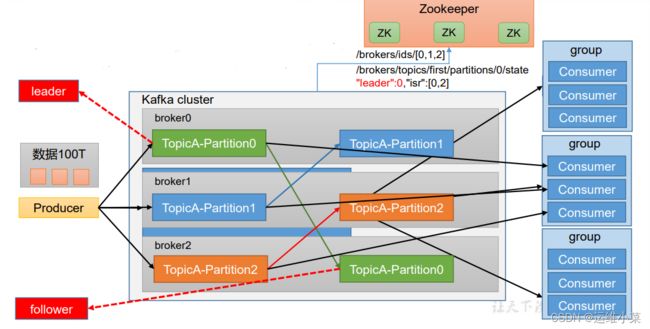
- Producer负责接收外部数据,将数据按照不同的partition(每个topic会被分成多个Partition)发送到kafka集群的不同节点
- 为提高可用性,每个partition都会有若干个副本,副本分别存在于一个leader和若干Follower之上,对于不同的partition,leader和Follower为不同的kafka节点,Consumer消费数据都是直接消费leader上的数据,leader所在节点宕机之后,flower之一会变成新的leader
- Consumer按照功能会分成不同的goup,每个group里有若干Consumer,每个consumer在消费数据时对应一个Partition
- zookeeper会记录kafka集群中每个节点运行的状态、每个partition对应的leader与Follower是谁等等元数据信息(2.8.0版本之后zookeeper可选,可使用craft模式)
2.生产消息原理
1)原理概述
在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程中创建了一个双端队列RecordAccumulator。main 线程将消息发送给 RecordAccumulator,Sender 线程不断从 RecordAccumulator 中拉取消息发送到Kafka Broker
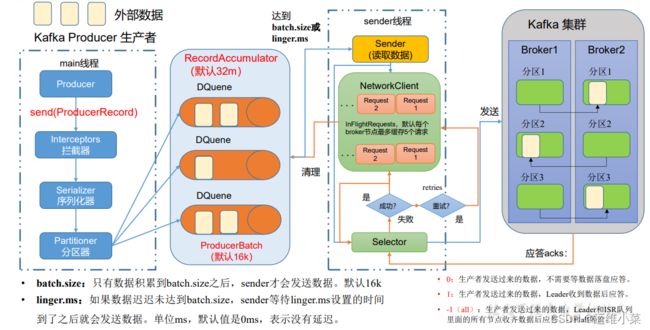
(1)producer在本地开启main线程,外部数据通过send方法发送数据,过程中经过拦截器(类似于数据清洗过程)、序列化器(kafka的序列化器)和分区器(将数据分成不同的分区partition)
(2)RecordAccumulator在内存中按分区创建若干分区队列(DQueue),该内存默认值为32M。队列中每16K为一个批次(ProducerBatch)(该批次达到16k才会被发送,参数batch.size,linger.ms为0时该参数无效)
(3)Sender线程负责发送数据,它按照broker创建若干请求队列,每个队列对应一个broker,每个队列最多缓存5个request
(4)selector负责建立传输管道向各brocker发送数据
(5)kafka集群有Leader与Follower之间的数据同步机制(replication)
- 调优参数
batch.size:批次大小,默认16k
linger.ms:等待时间,修改为5-100ms
compression.type:压缩snappy
RecordAccumulator:缓冲区大小,修改为64m
2)数据可靠性
数据从producer发送到broker有三种应答(acknowledge)级别–【0,1,-1】
Ack = 0:生产者发送数据,不需要等待数据落盘应答;弊端:极有可能可造成数据丢失(丢数)
Ack = 1:生产者发送数据,需要等待Leader收到数据后应答;弊端:可能造成同步Follower失败,Follower丢数(因为不需要Follower应答)
Ack = 1-:生产者发送数据,需要等待Leader和ISR里的所有Follower收到数据后应答;
如果仅设置Ack = -1,则弊端是可能因为某个或某几个Follower无应答而阻塞。
针对此弊端,kafka的解决方式为,由Leader维护一个同步副本集(ISR,in-sync replica set),这里面是和Leader保持同步的brokerid(格式:leader:0,isr:0,1,2)
如果Follower长时间(参数:replica.lag.time.max.ms,默认30秒)与Leader无法通信,则Leader会将该Follower将被移出ISR。
如果分区副本设置为1个,或 者ISR里应答的最小副本数量( min.insync.replicas 默认为1)设置为1,和ack=1的效果是一样的,仍然有丢数的风险(leader:0,isr:0)
综上:数据完全可靠条件 = (ACK= -1) + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
生产环境中,acks=0很少使用;acks=1,一般用于传输普通日志,允许丢个别数据;acks=-1,一般用于传输和钱相关的数据,对可靠性要求比较高的场景
3.broker工作原理
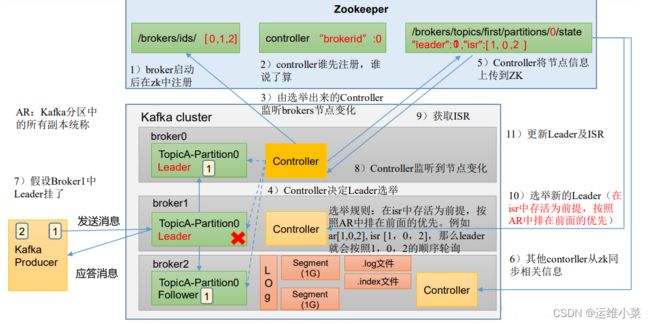
1)kafka在zk上存储的信息
登录zk查看kfk目录
[hadoop@hadoop102 bin]$ ./zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /kafka
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature,
isr_change_notification, latest_producer_id_block, log_dir_event_notification]
重要的data:
- 所有在线的broker
[zk: localhost:2181(CONNECTED) 1] ls /kafka/brokers/ids
[0, 1, 2]
- 每个topic下的每个分区以及对应的Leader与ISR
[zk: localhost:2181(CONNECTED) 3] ls /kafka/brokers/topics/test/partitions
[0, 1, 2]
[zk: localhost:2181(CONNECTED) 5] get /kafka/brokers/topics/test/partitions/0/state
{"controller_epoch":2,"leader":1,"version":1,"leader_epoch":3,"isr":[1,2]}
- controller的"leader" 辅助leader选举
[zk: localhost:2181(CONNECTED) 8] get /kafka/controller
{"version":1,"brokerid":0,"timestamp":"1649940120345"}
2)副本Leader选举流程
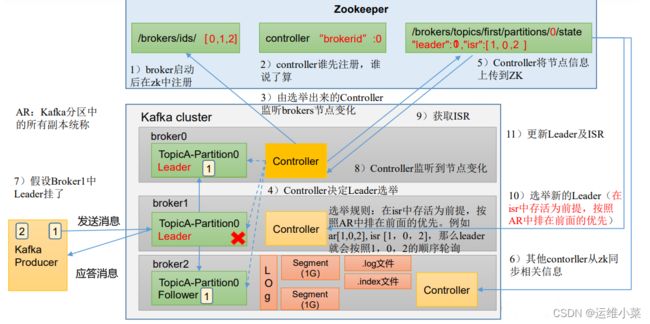
(1)kfk集群各broker启动后在zk的/kafka/brocker/ids下注册(掉线后也会在zk中注销)
(2)每个broker里都有一个controller,kfk集群启动后各个broker尝试去zk的/kafka/controller下注册信息,第一个注册到的为controller的"leader",该"leader"会监听/kafka/brocker/ids中AR的变化
(3)正式选举:后选Leader为ISR中的broker,然后采用一定的算法(比如AR中排在最前面)选出Leader
查看AR:(Replicas后的副本集合)
[hadoop@hadoop103 bin]$ ./kafka-topics.sh --topic test01 --bootstrap-server hadoop102:9092,hadoop103:9092 --describe
Topic: test01 TopicId: Sfwa2XLZTAOAb0ST5NiqYA PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: test01 Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: test01 Partition: 1 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test01 Partition: 2 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
(4)重新选举:原来的leader挂了,则有controller的"leader"监听到/brocker/ids中的节点变化,并更新ISR中的信息重新进行选举。
4. 故障处理(Offset / HW / LEO)
首先介绍几个概念:
Offset:partition中的每个消息都有一个连续的序号,用于partition唯一标识一条消息,可以理解为每个offset就是一条消息
LEO(Log End Offset):ISR分区副本最后一条消息的待写位!即每个副本最大offset+1=LEO
ISR(In-Sync Replica ):分区所有副本中offset最小的副本他最后一条消息后的待写位置(即所有副本的最小LEO)。也是该副本的LEO
1)正常情况
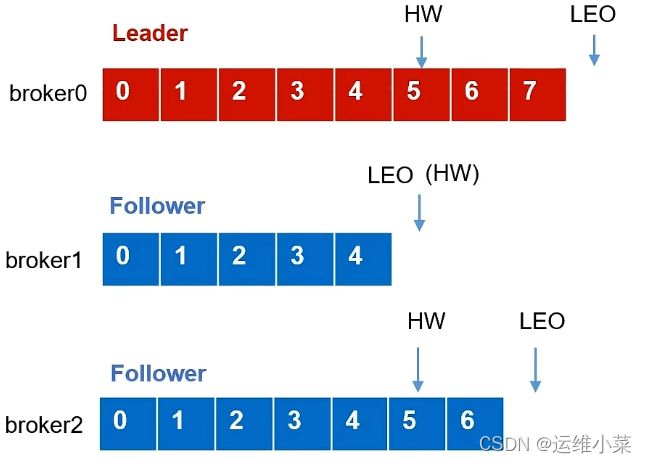
(1)broker0为Leader,Producer首先将消息发送给Leader,然后Follower主动同步Leader中的数据,
(2)鉴于Leader和Follower接收消息的时间不同,所以每个broker的LEO不同,broker1、broker2中的消息量会比broker0中的少一些,LEO就会小一些
(3)此时该分区的HW为5,也就是broker1的HW
(4)没有故障发生时,该分区的ISR为[0,1,2],即三个副本都同时正常在线
2)Follower故障
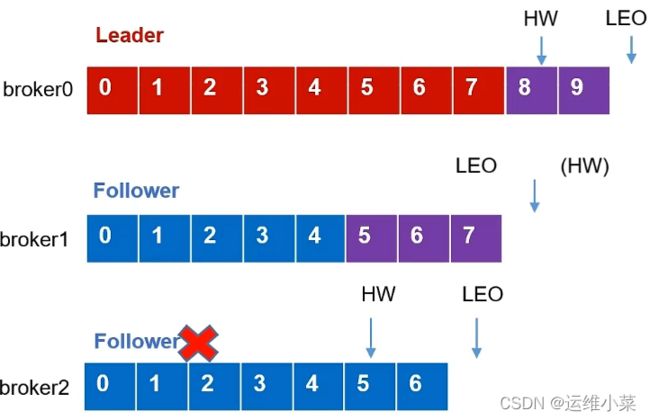
(1)当某个Follower(比如broker2)故障时,该broker记录的HW为5,LEO为7
(2)其他broker继续正常工作,Leader接收新消息,其LEO变为10,broker1继续同步消息,其LEO变为8,该分区的HW即变为8
(3)故障的节点恢复运行后,首先将其故障前记录的HW及HW之后的数据删掉,如下:
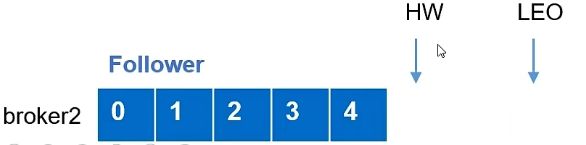
(4)然后再向Leader同步数据,当同步数据达到当前的HW之后,该broker重新加入ISR
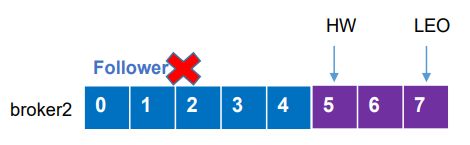
3)Leader故障
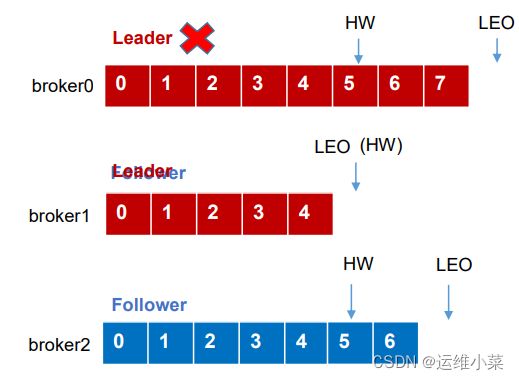
(1)Leader故障后,ISR为[1,2],重新选举新Leader(比如为broker1)
(2)如果此时存活的Follower的LEO大于新Leader的LEO,则会被要求删掉高于HW的部分,新leader继续接收消息
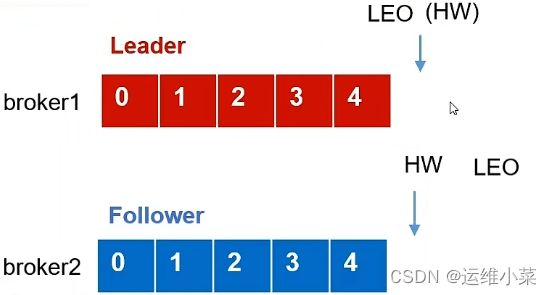
(3)Leader故障可能导致数据丢失或重复
5.Topic副本存储原理
1)存储机制
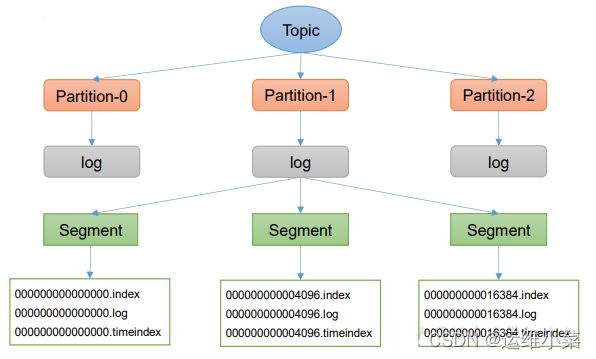
(1)Topic为逻辑上的概念,每个Topic在物理上分为一个或多个Partition,每个Partition按Replica存储在不同的Broker上,命名方式为–[topicName-partitionNo]
(2)一个Partition在Broker上按Segment存储,每个Segment默认为1G
(3)每个Segment由一个.log文件、一个.index文件,一个.timeindex文件组成
- 创建单分区2副本的topic用于测试
[hadoop@hadoop102 datas]$ kafka-topics.sh --create --topic saveTest --bootstrap-server hadoop102:9092 --partitions 1 --replication-factor 2
Created topic saveTest.
- 生产大于1G的数据,这里个人虚拟机5分钟大概写了2.5G的数据,生产中会很快,代码见 本文 附录
- 查看数据存储路径
[hadoop@hadoop102 saveTest-0]$ pwd
/opt/module/kafka/datas/saveTest-0
[hadoop@hadoop102 saveTest-0]$ du -sh *
[hadoop@hadoop102 saveTest-0]$ du -sh *
516K 00000000000000000000.index
1.0G 00000000000000000000.log
768K 00000000000000000000.timeindex
516K 00000000000038751300.index
1.0G 00000000000038751300.log
4.0K 00000000000038751300.snapshot
768K 00000000000038751300.timeindex
160K 00000000000077106001.index
314M 00000000000077106001.log
4.0K 00000000000077106001.snapshot
236K 00000000000077106001.timeindex
4.0K leader-epoch-checkpoint
4.0K partition.metadata
2).log / .index / .timeindex
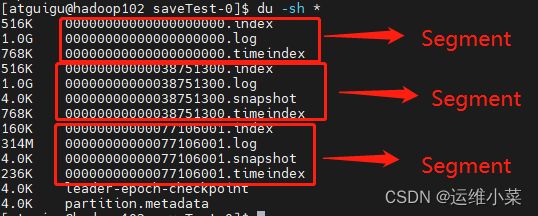
(1)每个Segment中的.log文件、.index文件,.timeindex文件都以当前Segment的第一个offset命名
(2)当前Segment包含了由本Segment的第一个offset到下一个Segment第一个offset - 1的所有消息
.log文件是Segment的日志文件,包含实际的消息数据
.index文件是偏移量索引文件
.timeindex文件是时间戳索引文件
查看.log与.index文件的命令
[hadoop@hadoop102 saveTest-0]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000077106001.index | head
Dumping ./00000000000077106001.index
offset: 77107170 position: 16377
offset: 77107755 position: 32754
offset: 77108340 position: 49131
offset: 77108925 position: 65508
offset: 77109510 position: 81885
offset: 77110095 position: 98262
offset: 77110680 position: 114639
offset: 77111265 position: 131016
offset: 77111850 position: 147393
[hadoop@hadoop102 saveTest-0]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000077106001.log | head -n 5
Dumping ./00000000000077106001.log
Starting offset: 77106001
baseOffset: 77106001 lastOffset: 77106585 count: 585 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1650165099963 size: 16377 magic: 2 compresscodec: none crc: 1202492431 isvalid: true
baseOffset: 77106586 lastOffset: 77107170 count: 585 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 16377 CreateTime: 1650165099964 size: 16377 magic: 2 compresscodec: none crc: 3290634006 isvalid: true
baseOffset: 77107171 lastOffset: 77107755 count: 585 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 32754 CreateTime: 1650165099967 size: 16377 magic: 2 compresscodec: none crc: 3691937790 isvalid: true
3)存储细节
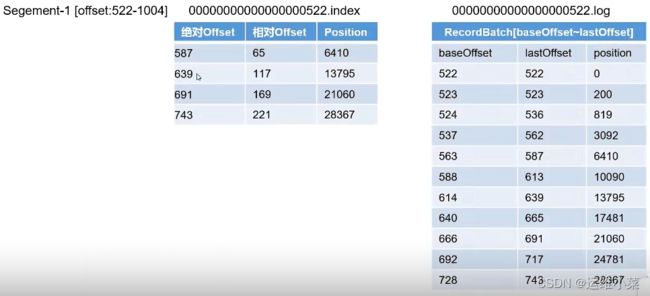
(1).index存储offset和position,使用稀疏存储方式,大概每4K消息在.index中存储一条信息
(2).index中存储的offset为相对offset(有时候也是绝对offset,不知道为啥,有待考证),即相对于.index文件名的offset,确保offset的值本身不会占用太大空间,
绝对offset = 相对offset + 文件名
(3).log文件中主要有三个数据 baseOffset,lastOffset,position,且.index中的position和.index文件中的position是一个意思
(4)如何定位一条消息?(比如定位绝对offset为600的消息)
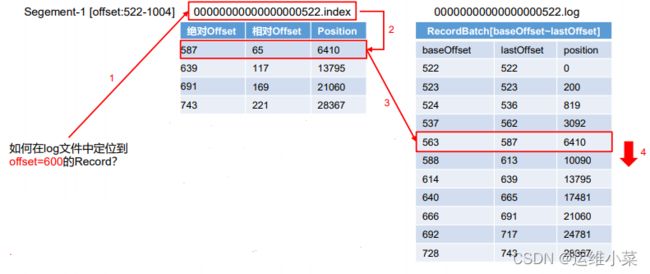
- (二分查找)首先根据绝对offset定位出.index文件(第一个文件名大于600的前一个文件)
- 根据绝对offset计算出相对offset,比如相对offset = 600 -522 = 78
- (二分查找)同理在.index中定位出该offset对应的position(第一个大于相对offset的offset的前一个offset对应的offset),比如65对应的6415
- 同理在.log中定位出第一个大于该position的前一个position,比如6410
- (顺序查找)在.log文件中从6410往下找,直到找到offset为6415的数据
(5)查看.log中详细的每条数据,添加参数 --print-data-log
[hadoop@hadoop102 saveTest-0]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000077106001.log --print-data-log | head -n 20
Dumping ./00000000000077106001.log
Starting offset: 77106001
baseOffset: 77106001 lastOffset: 77106585 count: 585 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1650165099963 size: 16377 magic: 2 compresscodec: none crc: 1202492431 isvalid: true
| offset: 77106001 CreateTime: 1650165099960 keySize: -1 valueSize: 20 sequence: -1 headerKeys: [] payload: dataFormIdea77106001
| offset: 77106002 CreateTime: 1650165099960 keySize: -1 valueSize: 20 sequence: -1 headerKeys: [] payload: dataFormIdea77106002
| offset: 77106003 CreateTime: 1650165099960 keySize: -1 valueSize: 20 sequence: -1 headerKeys: [] payload: dataFormIdea77106003
| offset: 77106004 CreateTime: 1650165099960 keySize: -1 valueSize: 20 sequence: -1 headerKeys: [] payload: dataFormIdea77106004
| offset: 77106005 CreateTime: 1650165099960 keySize: -1 valueSize: 20 sequence: -1 headerKeys: [] payload: dataFormIdea77106005
| offset: 77106006 CreateTime: 1650165099961 keySize: -1 valueSize: 20 sequence: -1 headerKeys: [] payload: dataFormIdea77106006
4) 分区副本分配
a. 自动分区
创建16个分区3个副本的topic
[hadoop@hadoop102 bin]$ kafka-topics.sh --create --topic partitionsTest --bootstrap-server hadoop102:9092 --partitions 16 --replication-factor 3
Created topic partitionsTest.
[hadoop@hadoop102 bin]$ kafka-topics.sh --describe --topic partitionsTest --bootstrap-server hadoop102:9092
Topic: partitionsTest TopicId: NS4cElLyTi-VgHD9vdaByA PartitionCount: 10 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: partitionsTest Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: partitionsTest Partition: 1 Leader: 0 Replicas: 0,2,3 Isr: 0,2,3
Topic: partitionsTest Partition: 2 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1
Topic: partitionsTest Partition: 3 Leader: 3 Replicas: 3,1,0 Isr: 3,1,0
Topic: partitionsTest Partition: 4 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: partitionsTest Partition: 5 Leader: 0 Replicas: 0,3,1 Isr: 0,3,1
Topic: partitionsTest Partition: 6 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: partitionsTest Partition: 7 Leader: 3 Replicas: 3,0,2 Isr: 3,0,2
Topic: partitionsTest Partition: 8 Leader: 1 Replicas: 1,3,0 Isr: 1,3,0
Topic: partitionsTest Partition: 9 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
可以看出,Leader以及Replicas会均匀的分布在ISR中,尽量保证数据的可靠性
b.手动分区
由于各broker服务器资源不同,配置不同,自动分区只能保证"均匀",不能保证"公平",这里假设broker3资源较少,将broker3上一部分副本转移到其他broker上
(1)创建分区配置文件
[hadoop@hadoop102 ~]$ vi test_partitions_manually.json
[hadoop@hadoop102 ~]$ cat test_partitions_manually.json
{
"version":1,
"partitions":[{"topic":"partitionsTest","partition":0,"replicas":[0,1,2]},
{"topic":"partitionsTest","partition":1,"replicas":[0,1,2]},
{"topic":"partitionsTest","partition":2,"replicas":[1,0,2]},
{"topic":"partitionsTest","partition":3,"replicas":[2,0,1]},
{"topic":"partitionsTest","partition":4,"replicas":[1,0,2]},
{"topic":"partitionsTest","partition":5,"replicas":[2,0,1]}]
}
(2)执行重新分区计划
[hadoop@hadoop102 ~]$ kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file test_partitions_manually.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"partitionsTest","partition":0,"replicas":[1,0,2],"log_dirs":["any","any","any"]},{"topic":"partitionsTest","partition":1,"replicas":[0,2,3],"log_dirs":["any","any","any"]},{"topic":"partitionsTest","partition":2,"replicas":[2,3,1],"log_dirs":["any","any","any"]},{"topic":"partitionsTest","partition":3,"replicas":[3,1,0],"log_dirs":["any","any","any"]},{"topic":"partitionsTest","partition":4,"replicas":[1,2,3],"log_dirs":["any","any","any"]},{"topic":"partitionsTest","partition":5,"replicas":[0,3,1],"log_dirs":["any","any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for partitionsTest-0,partitionsTest-1,partitionsTest-2,partitionsTest-3,partitionsTest-4,partitionsTest-5
(3)验证分区计划
[hadoop@hadoop102 ~]$ kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file test_partitions_manually.json --verify
Status of partition reassignment:
Reassignment of partition partitionsTest-0 is complete.
Reassignment of partition partitionsTest-1 is complete.
Reassignment of partition partitionsTest-2 is complete.
Reassignment of partition partitionsTest-3 is complete.
Reassignment of partition partitionsTest-4 is complete.
Reassignment of partition partitionsTest-5 is complete.
Clearing broker-level throttles on brokers 0,1,2,3
Clearing topic-level throttles on topic partitionsTest
(4)重新查看分区
[hadoop@hadoop102 ~]$ kafka-topics.sh --describe --topic partitionsTest --bootstrap-server hadoop102:9092
Topic: partitionsTest TopicId: NS4cElLyTi-VgHD9vdaByA PartitionCount: 16 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: partitionsTest Partition: 0 Leader: 0 Replicas: 0,1,2 Isr: 1,0,2
Topic: partitionsTest Partition: 1 Leader: 0 Replicas: 0,1,2 Isr: 0,2,1
Topic: partitionsTest Partition: 2 Leader: 2 Replicas: 1,0,2 Isr: 2,1,0
Topic: partitionsTest Partition: 3 Leader: 2 Replicas: 2,0,1 Isr: 1,0,2
Topic: partitionsTest Partition: 4 Leader: 1 Replicas: 1,0,2 Isr: 1,2,0
Topic: partitionsTest Partition: 5 Leader: 0 Replicas: 2,0,1 Isr: 0,1,2
Topic: partitionsTest Partition: 6 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: partitionsTest Partition: 7 Leader: 3 Replicas: 3,0,2 Isr: 3,0,2
Topic: partitionsTest Partition: 8 Leader: 1 Replicas: 1,3,0 Isr: 1,3,0
Topic: partitionsTest Partition: 9 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
(5)副本数增加
副本数不能通过kafka-topic.sh命令行直接增加可以使用如下方式调整(可增可减可调整)
[hadoop@hadoop102 ~]$ vi test_increase-replication.json
[hadoop@hadoop102 ~]$ cat test_increase-replication.json
{
"version": 1,
"partitions": [{
"topic": "partitionsTest",
"partition": 0,
"replicas": [0, 1]
}, {
"topic": "partitionsTest",
"partition": 1,
"replicas": [0, 1, 2, 3]
}, {
"topic": "partitionsTest",
"partition": 2,
"replicas": [1, 2, 3]
}]
}
[hadoop@hadoop102 ~]$ kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file test_increase-replication.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"partitionsTest","partition":0,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"topic":"partitionsTest","partition":1,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"topic":"partitionsTest","partition":2,"replicas":[1,0,2],"log_dirs":["any","any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for partitionsTest-0,partitionsTest-1,partitionsTest-2
[hadoop@hadoop102 ~]$ kafka-topics.sh --describe --topic partitionsTest --bootstrap-server hadoop102:9092
Topic: partitionsTest TopicId: NS4cElLyTi-VgHD9vdaByA PartitionCount: 16 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: partitionsTest Partition: 0 Leader: 0 Replicas: 0,1 Isr: 1,0
Topic: partitionsTest Partition: 1 Leader: 0 Replicas: 0,1,2,3 Isr: 0,2,1,3
Topic: partitionsTest Partition: 2 Leader: 2 Replicas: 1,2,3 Isr: 2,1,3
Topic: partitionsTest Partition: 3 Leader: 2 Replicas: 2,0,1 Isr: 1,0,2
Topic: partitionsTest Partition: 4 Leader: 1 Replicas: 1,0,2 Isr: 1,2,0
Topic: partitionsTest Partition: 5 Leader: 0 Replicas: 2,0,1 Isr: 0,1,2
Topic: partitionsTest Partition: 6 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: partitionsTest Partition: 7 Leader: 3 Replicas: 3,0,2 Isr: 3,0,2
Topic: partitionsTest Partition: 8 Leader: 1 Replicas: 1,3,0 Isr: 1,3,0
Topic: partitionsTest Partition: 9 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2
Topic: partitionsTest Partition: 10 Leader: 2 Replicas: 2,0,3 Isr: 2,0,3
6.消费者原理
1)消费者组
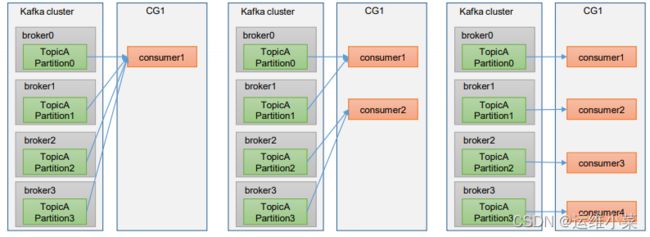
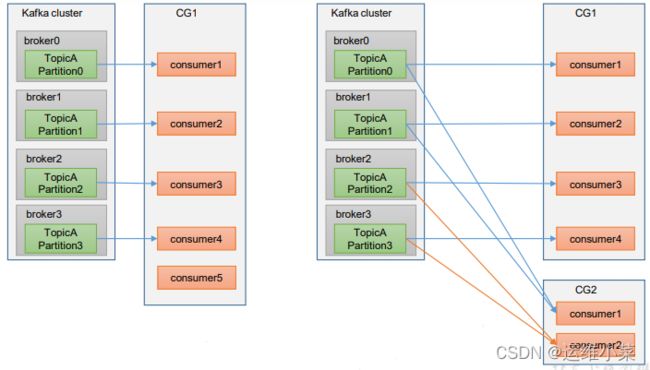
(1)每个consumer都有一个groupid,groupid相同的consumer为一个消费者组(CG)
(2)每个消费者组可以消费不同partition中的消息
(3)相同消费者组总的不同消费者消费不同的partition中的消息
(4)一个消费者可以消费多个partition中的消息,但一个partition中的消息只能由同一个消费者组中的一个消费者消费
(5)如果消费者来自不同组则可以由多个消费者消费,即不同消费者组之间的消费者互不影响
(6)如果一个消费者组中的消费者数量超过了partition数量,则同一时间必定有消费者处于空闲状态
2)消费流程
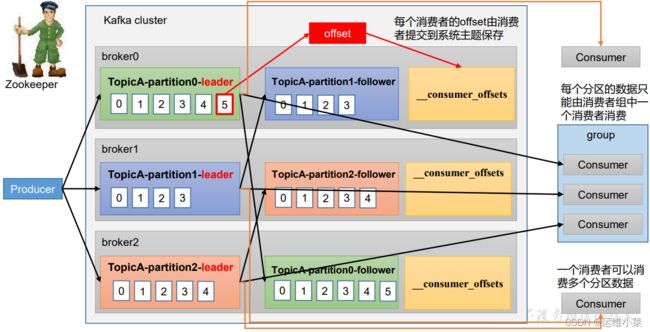
(1)生产者生产数据,将Topic分成多个Partition发送到kafka集群各个Broker的leader中,然后Follower向Leader同步数据
(2)消费者(组)消费数据,在kafka中会创建一个__consumer_offsets的Topic,默认50个分区,用来记录消费者消费到哪儿了
[hadoop@hadoop102 datas]$ kafka-topics.sh --describe --topic __consumer_offsets --bootstrap-server hadoop102:9092
Topic: __consumer_offsets TopicId: pXqSKyGjQP68NH8u9EhnvQ PartitionCount: 50 ReplicationFactor: 1 Configs: compression.type=producer,cleanup.policy=compact,segment.bytes=104857600
Topic: __consumer_offsets Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: __consumer_offsets Partition: 1 Leader: 1 Replicas: 1 Isr: 1
Topic: __consumer_offsets Partition: 2 Leader: 0 Replicas: 0 Isr: 0
Topic: __consumer_offsets Partition: 3 Leader: 2 Replicas: 2 Isr: 2
Topic: __consumer_offsets Partition: 4 Leader: 1 Replicas: 1 Isr: 1
Topic: __consumer_offsets Partition: 5 Leader: 0 Replicas: 0 Isr: 0
……
[hadoop@hadoop103 __consumer_offsets-37]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log --print-data-log
Dumping 00000000000000000000.log
Starting offset: 0
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 0 CreateTime: 1649581940063 size: 397 magic: 2 compresscodec: none crc: 296324366 isvalid: true
| offset: 0 CreateTime: 1649581940063 keySize: 26 valueSize: 301 sequence: -1 headerKeys: [] key: console-consumer-31930 payload:consumerrangeFconsumer-console-consumer-31930-1-83803557-6ebe-486d-a46c-3bcb8d19fd68���FFconsumer-console-consumer-31930-1-83803557-6ebe-486d-a46c-3bcb8d19fd68��!consumer-console-consumer-31930-1/192.168.10.103����test���� test����
baseOffset: 1 lastOffset: 1 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false position: 397 CreateTime: 1649594571140 size: 127 magic: 2 compresscodec: none crc: 1099527437 isvalid: true
| offset: 1 CreateTime: 1649594571140 keySize: 26 valueSize: 32 sequence: -1 headerKeys: [] key: console-consumer-31930 payload:consumer������
baseOffset: 2 lastOffset: 2 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 2 isTransactional: false isControl: false position: 524 CreateTime: 1649940721504 size: 94 magic: 2 compresscodec: none crc: 1432751996 isvalid: true
| offset: 2 CreateTime: 1649940721504 keySize: 26 valueSize: -1 sequence: -1 headerKeys: [] key: console-consumer-31930
也可使用命令直接查看
[hadoop@hadoop102 kafka]$ bin/kafka-console-consumer.sh --topic __consumer_offsets --bootstrap-server hadoop102:9092 --consumer.config config/consumer.properties --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --from-beginning
[offset,hadoop,1]::OffsetAndMetadata(offset=7, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622442520203, expireTimestamp=None)
[offset,hadoop,0]::OffsetAndMetadata(offset=8, leaderEpoch=Optional[0], metadata=, commitTimestamp=1622442520203, expireTimestamp=None)
3)消费者组初始化
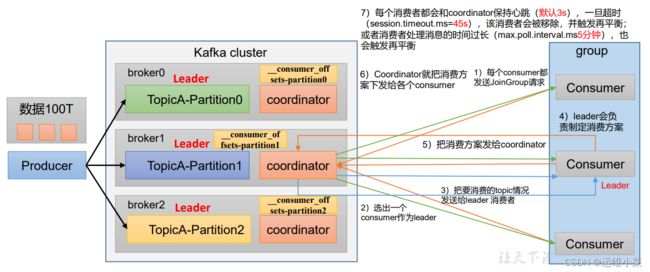
(1)每个Broker上都有一个Coordinator,辅助实现消费者组的初始化和分区的分配
(2)每个Consumer消费数据前会首先找到对应的Coordinator,请求加入组
Coordinator节点选择 = GroupId的hashcode值 % 50( __consumer_offsets的分区数量)
Consumer在找Coordinator时先根据上面的公式找到__consumer_offsets,然后确定该__consumer_offsets所在的Broker上的Coordinator
(3)Coordinator会选出一个Consumer作为改组内所有Consumer的Leader
(4)Coordinator将所有消费者要消费的Topic情况发送个Leader
(5)Leader统筹制定消费方案,并将方案发送给Coordinator
(6)Coordinator将消费方案同步给所有Consumer
消费方案再平衡:
每个消费者都会和coordinator保持心跳(默认3s),一旦超时(session.timeout.ms 默认45s),该消费者会被从组内移除,并触发再平衡(消费方案变更);或者消费者处理消息的时间过长(max.poll.interval.ms 默认5分钟),也会触发再平衡
4)消费者组的工作流程
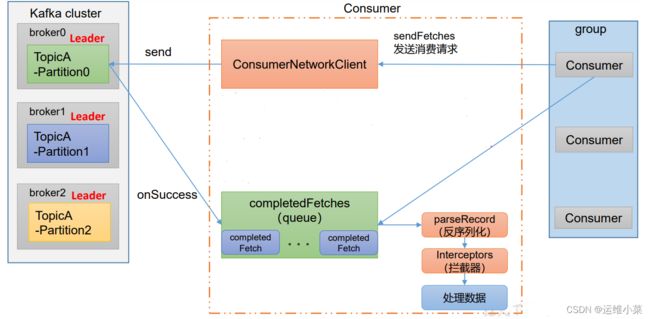
(1)消费者创建ConsumerNetworkClient客户端,与各个Broker交互,从Broker中pull数据
pull 数据的几个参数
Fetch.min.bytes每批次最小抓取大小,默认1字节
fetch.max.wait.ms 超时时间,默认500ms,也就是不到1字节但到了500ms,也进行pull
Fetch.max.bytes每批次最大抓取大小,默认50m
(2)通过回调函数onSuccess将数据拉取到本地的消息队列completeFetches
(3)consumer从队列中拉取数据,经过反序列化、拦截器后处理数据完成消费
5)消费分配策略
a. Range模式

首先对同一个 topic 里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。
通过 partitions数/consumer数 来决定每个消费者应该消费几个分区。如果除不尽,那么前面几个消费者将会多消费1个分区。
例如:现在有 7 个分区,3 个消费者,排序后的分区将会是0,1,2,3,4,5,6;消费者排序完之后将会是C0,C1,C2。
例如,7/3 = 2 余 1 ,除不尽,那么 消费者 C0 便会多消费 1 个分区。 8/3=2余2,除不尽,那么C0和C1分别多消费一个。
弊端:
数据倾斜:如果只是针对 1 个 topic 而言,C0消费者多消费1个分区影响不是很大。但是如果有 N 多个 topic,那么针对每个 topic,消费者 C0都将多消费 1 个分区,topic越多,C0消费的分区会比其他消费者明显多消费 N 个分区。
b. RoundRobinAssignor
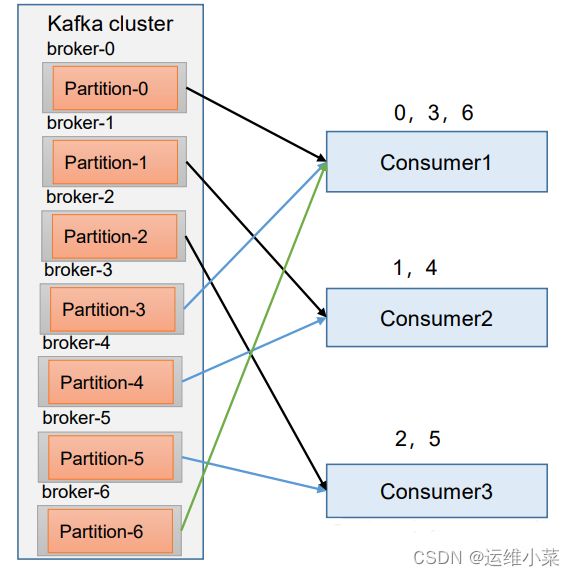
RoundRobin 针对集群中所有Topic而言。
RoundRobin 轮询分区策略,是把所有的 partition 和所有的consumer 都列出来,然后按照 hashcode 进行排序,最后通过轮询算法来分配 partition 给到各个消费者。
c. StickyAssignor
kafka 在 0.11.x 版本支持了 StrickyAssignor, 翻译过来叫粘滞策略,它主要有两个目的:
1.分区的分配尽可能的均匀
2.分区的分配尽可能和上次分配保持相同
当两者发生冲突时, 第 一 个目标优先于第二个目标。 鉴于这两个目标, StickyAssignor 分配策略的具 体实现要比 RangeAssignor 和 RoundRobinAssi gn or 这两种分配策略要复杂得多,假设我们有这样一个场景
假设消费组有 3 个消费者:C0,C1,C2,它们分别订阅了 4 个 Topic(t0,t1,t2,t3),并且每个主题有两个分 区(p0,p1),也就是说,整个消费组订阅了 8 个分区:t0p0 、 t0p1 、 t1p0 、 t1p1 、 t2p0 、 t2p1 、t3p0 、 t3p1 ,那么最终的分配场景结果为
- C0: t0p0、t1p1 、 t3p0
- C1: t0p1、t2p0 、 t3p1
- C2: t1p0、t2p1
这种分配方式有点类似于轮询策略,但实际上并不是,因为假设这个时候,C1 这个消费者挂了,就势必会造成 重新分区(reblance),如果是轮询,那么结果应该是:
C0: t0p0、t1p0、t2p0、t3p0
C2: t0p1、t1p1、t2p1、t3p1
然后,strickyAssignor 它是一种粘滞策略,所以它会满足分区的分配尽可能和上次分配保持相同,所以 分配结果应该是:
C0: t0p0、t1p1、t3p0、t2p0
C2: t1p0、t2p1、t0p1、t3p1
也就是说,C0 和 C2 保留了上一次是的分配结果,并且把原来 C1 的分区分配给了 C0 和 C2。 这种策略的好处是 使得分区发生变化时,由于分区的“粘性,减少了不必要的分区移动
二、Kafka集群安装
1.初始安装
前提:安装zookeeper集群 zookeeper集群安装
1)下载kafka安装包
地址
2)集群规划

3)集群安装
三台机器操作基本一致,只有配置broker.id不一致
(1)传包到/opt/module,并解压,更名为kafka
[hadoop@hadoop102 module]$ ll kafka_2.12-3.0.0.tgz
-rw-rw-r-- 1 hadoop hadoop 86486610 4月 9 17:03 kafka_2.12-3.0.0.tgz
[hadoop@hadoop102 module]$ tar -xvf kafka_2.12-3.0.0.tgz
[hadoop@hadoop102 module]$ mv kafka_2.12-3.0.0 kafka
[hadoop@hadoop102 module]$ ls -l
总用量 84460
drwxr-xr-x 7 hadoop hadoop 105 9月 9 2021 kafka
-rw-rw-r-- 1 hadoop hadoop 86486610 4月 9 17:03 kafka_2.12-3.0.0.tgz
drwxrwxr-x 8 hadoop hadoop 160 4月 4 20:50 zookeeper-3.5.7
(2)修改配置文件
[hadoop@hadoop102 config]$ vi server.properties
# 以下为建议修改的参数
broker.id=0 # 每个机器不能相同
log.dirs=/opt/module/kafka/datas #自定义
zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka #配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理)
(3)设置环境变量并source
[hadoop@hadoop102 etc]$ tail profile
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#hadoop
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
[hadoop@hadoop102 etc]$ source /etc/profile
4)集群启动与关闭
先启动zk集群
[hadoop@hadoop102 kafka]$ zk.sh start
三台机器分别启动kafka
[hadoop@hadoop102 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[hadoop@hadoop103 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[hadoop@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
查看zk与kafka的java进程
[hadoop@hadoop102 etc]$ jps | grep -v Jps
2432 Kafka
1708 QuorumPeerMain
三台机器分别关闭kafka
[hadoop@hadoop102 kafka]$ bin/kafka-server-stop.sh
[hadoop@hadoop103 kafka]$ bin/kafka-server-stop.sh
[hadoop@hadoop104 kafka]$ bin/kafka-server-stop.sh
关闭zk集群
[hadoop@hadoop102 etc]$ zk.sh stop
2.节点上线与下线
1)新节点上线
新节点安装jdk与kafka(参考初始安装),复制原节点的配置文件,修改broker.id,启动kafka
[hadoop@hadoop105 ~]$ java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
[hadoop@hadoop105 ~]$ cd /opt/module/kafka/bin/
[hadoop@hadoop105 bin]$ ./kafka-server-start.sh -daemon ../config/server.properties
[hadoop@hadoop105 bin]$ jps
1858 Jps
1834 Kafka
zk查看brokers
# 新节点kafka启动前
[zk: localhost:2181(CONNECTED) 1] ls /kafka/brokers/ids
[0, 1, 2]
# 启动后
[zk: localhost:2181(CONNECTED) 2] ls /kafka/brokers/ids
[0, 1, 2, 3]
2)副本再分配
(1)创建再分配需要的json(在原有节点)
[hadoop@hadoop102 ~]$ vim test-topic.json
[hadoop@hadoop102 ~]$ cat test-topic.json
{
"topics": [
{"topic": "test01"}
],
"version": 1
}
(2)获取再分配计划
[hadoop@hadoop102 ~]$ kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --topics-to-move-json-file test-topic.json --broker-list "0,2,3" --generate
# 当前分配
Current partition replica assignment
{"version":1,"partitions":[{"topic":"test01","partition":0,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"test01","partition":1,"replicas":[1,0,2],"log_dirs":["any","any","any"]},{"topic":"test01","partition":2,"replicas":[0,2,1],"log_dirs":["any","any","any"]}]}
# 计划分配
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"test01","partition":0,"replicas":[0,2,3],"log_dirs":["any","any","any"]},{"topic":"test01","partition":1,"replicas":[2,3,0],"log_dirs":["any","any","any"]},{"topic":"test01","partition":2,"replicas":[3,0,2],"log_dirs":["any","any","any"]}]}
(3)创建再分配计划配置(拷贝上一步计划分配里的json)
[hadoop@hadoop102 ~]$ vi reassignment.json
[hadoop@hadoop102 ~]$ cat reassignment.json
{
"version":1,
"partitions":[
{
"topic":"test01",
"partition":0,
"replicas":[
0,
2,
3
],
"log_dirs":[
"any",
"any",
"any"
]
},
{
"topic":"test01",
"partition":1,
"replicas":[
2,
3,
0
],
"log_dirs":[
"any",
"any",
"any"
]
},
{
"topic":"test01",
"partition":2,
"replicas":[
3,
0,
2
],
"log_dirs":[
"any",
"any",
"any"
]
}
]
}
(4)执行再分配计划
-执行之前
[hadoop@hadoop102 bin]$ ./kafka-topics.sh --topic test01 --bootstrap-server hadoop102:9092,hadoop103:9092 --describe
Topic: test01 TopicId: Sfwa2XLZTAOAb0ST5NiqYA PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: test01 Partition: 0 Leader: 2 Replicas: 2,1,0 Isr: 1,0,2
Topic: test01 Partition: 1 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test01 Partition: 2 Leader: 1 Replicas: 0,2,1 Isr: 1,0,2
-执行
[hadoop@hadoop102 ~]$ kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file reassignment.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"test01","partition":0,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"test01","partition":1,"replicas":[1,0,2],"log_dirs":["any","any","any"]},{"topic":"test01","partition":2,"replicas":[0,2,1],"log_dirs":["any","any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for test01-0,test01-1,test01-2
-验证
[hadoop@hadoop102 ~]$ kafka-reassign-partitions.sh --bootstrap-server hadoop102:9092 --reassignment-json-file reassignment.json --verify
Status of partition reassignment:
Reassignment of partition test01-0 is complete.
Reassignment of partition test01-1 is complete.
Reassignment of partition test01-2 is complete.
Clearing broker-level throttles on brokers 0,1,2,3
Clearing topic-level throttles on topic test01
-执行之后
[hadoop@hadoop102 ~]$ kafka-topics.sh --topic test01 --bootstrap-server hadoop102:9092,hadoop103:9092 --describe
Topic: test01 TopicId: Sfwa2XLZTAOAb0ST5NiqYA PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: test01 Partition: 0 Leader: 2 Replicas: 0,2,3 Isr: 0,2,3
Topic: test01 Partition: 1 Leader: 2 Replicas: 2,3,0 Isr: 0,2,3
Topic: test01 Partition: 2 Leader: 3 Replicas: 3,0,2 Isr: 0,2,3
3)老节点下线
针对所有topic进行副本再分配(注意在获取再分配计划时–broker-list 参数要将要下线的brokerID去掉),然后直接下线(kill掉kafka进程,关机,砸服务器随意)即可。
三、kafka命令行操作
1.topic相关的命令
使用脚本:kafka-topics.sh
[hadoop@hadoop102 bin]$ pwd
/opt/module/kafka/bin
[hadoop@hadoop102 bin]$ ls -l kafka-topics.sh
-rwxr-xr-x 1 hadoop hadoop 863 9月 9 2021 kafka-topics.sh
1)常用参数
- –bootstrap-server hostname:port,[hostname:port] 连接的kafka的broker的主机名与端口号
- –topic topicName 操作的topic名称
- –create 创建topic
- –delete 删除topic
- –alter 修改topic
- –list 查看topic列表
- –describe 查看topic描述
- – partitions num 设置分区数
- –replication-factor num 设置分区副本数
- –config name=value 更新默认配置
2)创建topic
!!!必须指定分区数partitions与每个分区的副本数replication-factor
[hadoop@hadoop102 bin]$ ./kafka-topics.sh --topic fisrtTopic --bootstrap-server hadoop102:9092,hadoop103:9092 --create --partitions 2 --replication-factor 2
Created topic fisrtTopic.
3)查看topic信息
[hadoop@hadoop102 bin]$ ./kafka-topics.sh --topic fisrtTopic --bootstrap-server hadoop102:9092,hadoop103:9092 --describe
Topic: fisrtTopic TopicId: Hry2LNbNQkeVzLQwCOPEIA PartitionCount: 2 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: fisrtTopic Partition: 0 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: fisrtTopic Partition: 1 Leader: 0 Replicas: 0,2 Isr: 0,2
其中,PartitionCount为分区数,ReplicationFactor为副本数,segment.bytes为存储单位,默认以1G为单位存储
下面是每个topic的基本信息,数字表示BrokerID,即server.properties配置的broker.id
4)查看、修改、删除topic
查看topic列表
[hadoop@hadoop102 bin]$ ./kafka-topics.sh --topic fisrtTopic --bootstrap-server hadoop102:9092,hadoop103:9092 --list
fisrtTopic
修改topic分区数(只能增加,不能减少)
[hadoop@hadoop102 bin]$ ./kafka-topics.sh --topic fisrtTopic --bootstrap-server hadoop102:9092,hadoop103:9092 --alter --partitions 3
删除topic
[hadoop@hadoop102 bin]$ ./kafka-topics.sh --topic fisrtTopic --bootstrap-server hadoop102:9092,hadoop103:9092 --delete
[hadoop@hadoop102 bin]$ ./kafka-topics.sh --topic fisrtTopic --bootstrap-server hadoop102:9092,hadoop103:9092 --list
[hadoop@hadoop102 bin]$
2.生产者与消费者相关命令
使用脚本kafka-console-producer.sh与kafka-console-consumer.sh
[hadoop@hadoop102 bin]$ ll kafka-console-*.sh
-rwxr-xr-x 1 hadoop hadoop 945 9月 9 2021 kafka-console-consumer.sh
-rwxr-xr-x 1 hadoop hadoop 944 9月 9 2021 kafka-console-producer.sh
生产数据
[hadoop@hadoop103 config]$ kafka-console-producer.sh -topic secondtopicaa --bootstrap-server hadoop102:9092
>somedata
消费数据–from-beginning参数可消费历史数据
[hadoop@hadoop102 config]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic secondtopic
somedata
四、Kafka的Java API
本文着重原理,API相关知识移步以下链接(非本人所写,但感觉比较全面):
Kafka API详解
kafka API详解
五、附录
生产大于1G的数据
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.util.Properties;
public class KafkaTest {
public KafkaProducer<String, String> kafkaProducer;
@Before
public void config(){
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());
kafkaProducer = new KafkaProducer<>(properties);
}
@Test
public void reallyMethod() {
for (int i = 0; i < 1000000000; i++) {
kafkaProducer.send(new ProducerRecord<>("saveTest","dataFormIdea" + i));
}
}
@After
public void close(){
kafkaProducer.close();
}
}
六、鸣谢
感谢尚硅谷,此文根据尚硅谷课程而写,bili连接 尚硅谷HBase教程