Spring Data Commons 之 Repository
2 Spring Data Commons 之 Repository
Spring Data 对整个数据操作做了很好的封装,其中 Spring Data Common 定义了很多公⽤的接⼝和⼀些相对数据操作的公共实现(如分⻚排序、结果映射、Autiting 信息、事务等),⽽ Spring Data JPA 就是 Spring Data Common 的关系数据库的查询实现。
2.1 Spring Data Commons 的依赖关系
我们可以通过 maven 工具,来查看 Spring Data Common 的依赖关系。
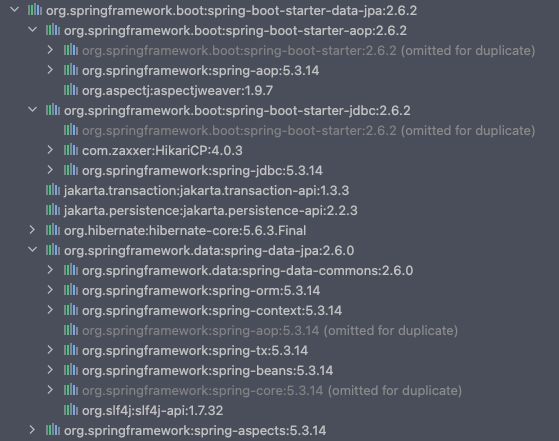
通过上图的项⽬依赖,不难发现,数据库连接⽤的是 JDBC,连接池⽤的是 HikariCP,强依赖 Hibernate;Spring Boot Starter Data JPA 依赖 Spring Data JPA;⽽ Spring Data JPA 依赖 Spring Data Commons。
在这些 jar 依赖关系中,Spring Data Commons 是我们要重点介绍的,因为 Spring Data Commons 是终极依赖。下⾯我们学习 DB 操作的⼊⼝ Repository 和 Repository 的⼦类。
2.2 Repository 接口
Repository 是 Spring Data Common ⾥⾯的顶级⽗类接⼝,操作 DB 的⼊⼝类。⾸先先看 Repository 接⼝的源码、类层次关系和使⽤实例。
2.2.1 Repository 接⼝源码
查看 Common ⾥⾯的 Resposiory 源码,了解⼀下⾥⾯实现了什么。
package org.springframework.data.repository;
import org.springframework.stereotype.Indexed;
@Indexed
public interface Repository<T, ID> {
}
Repository 是 Spring Data 里面做数据库操作的最底层的抽象接口、最顶级的父类,源码里面其实什么方法都没有,仅仅起到一个标识作用。管理域类以及域类的 id 类型作为类型参数,此接口主要作为标记接口捕获要使用的类型,并帮助你发现扩展此接口的接口。Spring 底层做动态代理的时候发现只要是它的子类或者实现类,都代表储存库操作。
有了这个类,我们就能顺藤摸瓜,找到好多 Spring Data JPA 提供的基本接口和操作类,及其实现方法。这个接口定义了所有 Repostory 操作的实体和 ID 两个泛型参数。我们不需要继承任何接口,只要继承这个接口,就可以使用 Spring JPA 里面提供的很多约定的方法查询和注解查询。
2.2.2 Repository 的类层次关系
我们用工具 IntelliJ IDEA,打开类 Repository.class,单击 Navigate→Type Hierarchy。
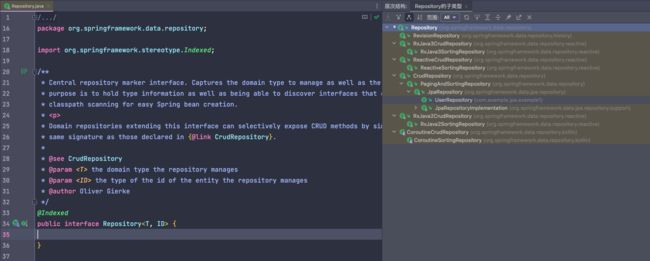
通过该层次结构视图,可知,存储库分为以下 4个⼤类。
ReactiveCrudRepository是响应式编程,主要⽀持当前 NoSQL ⽅⾯的操作,因为这⽅⾯⼤部分操作都是分布式的,所以由此我们可以看出 Spring Data 想统⼀数据操作的“野⼼”,即想提供关于所有 Data ⽅⾯的操作。⽬前 Reactive 主要有 Cassandra、MongoDB、Redis 的实现。RxJava2CrudRepository和RxJava2CrudRepository是为了⽀持 RxJava 做的标准响应式编程的接⼝。CoroutineCrudRepository是为了⽀持 Kotlin 语法⽽实现的。CrudRepository是 JPA 相关的操作接⼝。
然后,通过 Intellij Idea,我们也可以打开类 UserRepository.java,在此类⾥⾯,⿏标右键点击 Show Diagram 显示层次结构图,⽤
图表的⽅式查看类的关系层次,打开后如下图(Repository 继承关系图)所示:
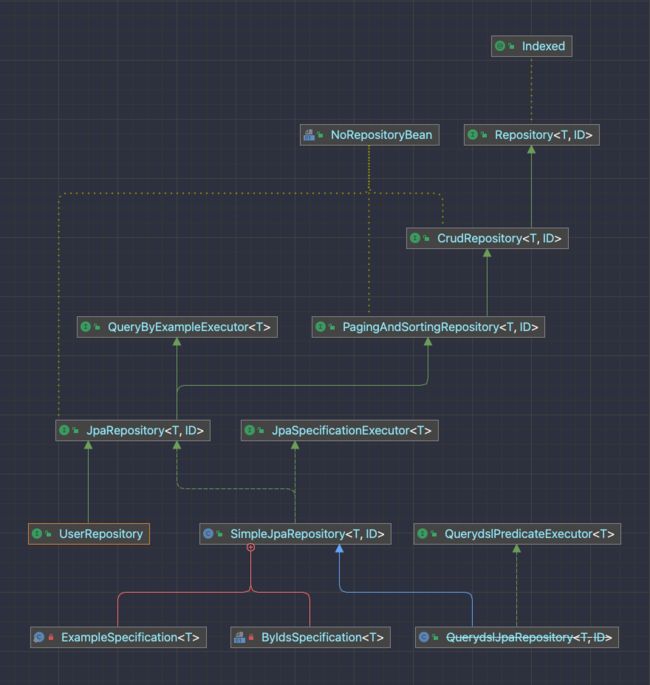
在这⾥简单介绍⼀下,我们需要掌握和使⽤到的类如下所示:
7 个⼤ Repository 接⼝:
- Repository(org.springframework.data.repository),没有暴露任何⽅法;
- CrudRepository(org.springframework.data.repository),简单的 Curd ⽅法;
- PagingAndSortingRepository(org.springframework.data.repository),带分⻚和排序的⽅法;
- QueryByExampleExecutor(org.springframework.data.repository.query),简单 Example 查询;
- JpaRepository(org.springframework.data.jpa.repository),JPA 的扩展⽅法;
- JpaSpecificationExecutor(org.springframework.data.jpa.repository),JpaSpecification 扩展查询;
- QueryDslPredicateExecutor(org.springframework.data.querydsl),QueryDsl 的封装。
两⼤ Repository 实现类:
- SimpleJpaRepository(org.springframework.data.jpa.repository.support),JPA 所有接⼝的默认实现类;
- QueryDslJpaRepository(org.springframework.data.jpa.repository.support),QueryDsl 的实现类。
2.2.3 Repository 的实例
我们通过⼀个例⼦,利⽤ UserRepository 继承 Repository 来实现我们之前的测试用例,如下:
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.repository.Repository;
import java.util.List;
public interface UserRepository extends Repository<User, Long> {
/**
* 查询全部
*/
List<User> findAll();
/**
* 分页查询
*/
Page<User> findAll(Pageable pageable);
/**
* 保存⽤户
*/
User save(User user);
}
再运行我们的测试,可以发现也是可以测试通过的。
上⾯这个实例通过继承 Repository,使 Spring 容器知道 UserRepository 是 DB 操作的类,是我们可以对 User 对象进⾏ CURD 的操作。
2.3 CrudRepository 接口
CrudRepository 主要是用于实体类的 CRUD 操作,源码如下:
package org.springframework.data.repository;
import java.util.Optional;
@NoRepositoryBean
public interface CrudRepository<T, ID> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
Optional<T> findById(ID id);
boolean existsById(ID id);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> ids);
long count();
void deleteById(ID id);
void delete(T entity);
void deleteAllById(Iterable<? extends ID> ids);
void deleteAll(Iterable<? extends T> entities);
void deleteAll();
}
简单说明一下:
save(S entity)保存实体⽅法,参数和返回结果可以是实体的⼦类;saveAll(Iterable批量保存,原理和 save ⽅法相同,我们去看实现的话,就是 for 循环调⽤上⾯的 save ⽅法。entities)findById(ID id)根据主键查询实体,返回 JDK 1.8 的 Optional,这可以避免 null exception;existsById(ID id)根据主键判断实体是否存在;findAll()查询实体的所有列表;findAllById(Iterable ids)根据主键列表查询实体列表;count()查询总数返回 long 类型;deleteById(ID id)根据主键删除,查看源码会发现,其是先查询出来再进⾏删除;delete(T entity)根据 entity 进⾏删除;deleteAllById(Iterable ids)根据主键批量删除;deleteAll(Iterable entities)根据 entity 批量删除;deleteAll()删除所有;
因为我们使用的是 JPA,因此上述方法的实现都是在 SimpleJpaRepository 里面,我们可以看下 save、deleteById、deleteAll 的源码
/**
* 新增或保存
*/
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
/**
* 删除
*/
@Transactional
@Override
public void deleteById(ID id) {
Assert.notNull(id, ID_MUST_NOT_BE_NULL);
delete(findById(id).orElseThrow(() -> new EmptyResultDataAccessException(
String.format("No %s entity with id %s exists!", entityInformation.getJavaType(), id), 1)));
}
/**
* 批量删除
*/
@Override
@Transactional
public void deleteAll() {
for (T element : findAll()) {
delete(element);
}
}
发现在进⾏ Update、Delete、Insert 等操作之前,我们看上⾯的源码,会通过 findById 先查询⼀下实体对象的 ID,然后再去对查询出来的实体对象进⾏保存操作。⽽如果在 Delete 的时候,查询到的对象不存在,则直接抛异常。而 deleteAll 是利⽤ for 循环调⽤ delete ⽅法进⾏删除操作。
这⾥特别强调了⼀下 Delete 和 Save ⽅法,是因为在实际⼯作中,看到有部分代码在做 Save 的时候先去 Find ⼀下,其实是没有必要的,Spring JPA 底层都考虑到了。因此当我们⽤任何第三⽅⽅法的时候,最好先查⼀下其源码和逻辑或者 API,然后才能写出更优雅的代码。
关于 entityInformation.isNew(entity),在这⾥简单说⼀下,如果当传递的参数⾥⾯没有 ID,则直接 insert;若当传递的参数⾥⾯有 ID,则会触发 select 查询。此⽅法会去看⼀下数据库⾥⾯是否存在此记录,若存在,则 update,否则 insert。
因此,如果我们打算对 User 实体进行 CRUD 操作,则我们只需要继承 CrudRepository 就可以实现。
public interface UserRepository extends CrudRepository<User,Long> {
}
2.4 PagingAndSortingRepository 接口
PagingAndSortingRepository 接⼝,该接⼝也是 Repository 接⼝的⼦类。
PagingAndSortingRepository 源码只有两个⽅法,分别是⽤于分⻚和排序的时候使⽤的,如下所示:
package org.springframework.data.repository;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}
其中,第⼀个⽅法 findAll 参数是 Sort,是根据排序参数,实现不同的排序规则获取所有的对象的集合;第⼆个⽅法 findAll 参数是 Pageable,是根据分⻚和排序进⾏查询,并⽤ Page 对返回结果进⾏封装。⽽ Pageable 对象包含 Page 和 Sort 对象。
我们可以看到 PagingAndSortingRepository 继承了 CrudRepository,进⽽拥有了⽗类的⽅法,并且增加了分⻚和排序等对查询结果进⾏限制的通⽤的⽅法。
PagingAndSortingRepository 和 CrudRepository 都是 Spring Data Common 的标准接⼝,那么实现类是什么呢?如果我们采⽤ JPA,那对应的实现类就是 Spring Data JPA 的 jar 包
⾥⾯的 SimpleJpaRepository。如果是其他 NoSQL的 实现如 MongoDB,那实现就在 Spring Data MongoDB 的 jar ⾥⾯的 MongoRepositoryImpl。
因此如果我们打算对 User 实体进行分页和排序操作,则我们只需要继承 PagingAndSortingRepository 就可以实现。
public interface UserRepository extends PagingAndSortingRepository<User,Long> {
}
2.5 JpaRepository 接口
到这⾥可以进⼊到分⽔岭了,上⾯的那些都是 Spring Data 为了兼容 NoSQL ⽽进⾏的⼀些抽象封装,⽽从 JpaRepository 开始是对关系型数据库进⾏抽象封装。从类图可以看出来它继承 PagingAndSortingRepository 类,也就继承了其所有⽅法,并且其实现类也是 SimpleJpaRepository。从类图上还可以看出 JpaRepository 继承和拥有了 QueryByExampleExecutor 的相关⽅法,我们先来看⼀下 JpaRepository 有哪些⽅法。⼀样的道理,我们直接看它的源码有什么方法。
package org.springframework.data.jpa.repository;
import java.util.List;
import javax.persistence.EntityManager;
import org.springframework.data.domain.Example;
import org.springframework.data.domain.Sort;
import org.springframework.data.repository.NoRepositoryBean;
import org.springframework.data.repository.PagingAndSortingRepository;
import org.springframework.data.repository.query.QueryByExampleExecutor;
@NoRepositoryBean
public interface JpaRepository<T, ID> extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
@Override
List<T> findAll();
@Override
List<T> findAll(Sort sort);
@Override
List<T> findAllById(Iterable<ID> ids);
@Override
<S extends T> List<S> saveAll(Iterable<S> entities);
void flush();
<S extends T> S saveAndFlush(S entity);
<S extends T> List<S> saveAllAndFlush(Iterable<S> entities);
@Deprecated
default void deleteInBatch(Iterable<T> entities){deleteAllInBatch(entities);}
void deleteAllInBatch(Iterable<T> entities);
void deleteAllByIdInBatch(Iterable<ID> ids);
void deleteAllInBatch();
@Deprecated
T getOne(ID id);
T getById(ID id);
@Override
<S extends T> List<S> findAll(Example<S> example);
@Override
<S extends T> List<S> findAll(Example<S> example, Sort sort);
}
JpaRepository ⾥⾯重点新增了批量删除,优化了批量删除的性能,类似于之前 SQL 的 batch 操作,并不是像上⾯的 deleteAll 来 for 循环删除。其中 flush() 和 saveAndFlush() 提供了⼿动刷新 session,把对象的值⽴即更新到数据库⾥⾯的机制。因为 JPA 是 由 Hibernate 实现的,所以有 session ⼀级缓存的机制,当调⽤ save() ⽅法的时候,数据库⾥⾯是不会⽴即变化的。
JpaRepository 的使⽤⽅式也⼀样,直接继承 JpaRepository 即可。
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User, Long> {
}
2.6 Repository 的实现类 SimpleJpaRepository
关系数据库的所有 Repository 接⼝的实现类就是 SimpleJpaRepository,如果有些业务场景需要进⾏扩展了,可以继续继承此类,如 QueryDsl 的扩展(虽然不推荐使⽤了,但我们可以参考它的做法,⾃定义⾃⼰的 SimpleJpaRepository),如果能将此类⾥⾯的实现⽅法看透了,基本上 JPA 中的 API 就能掌握⼤部分内容。
我们可以通过 Debug 视图看⼀下动态代理过程,如下⾯【类的继承关系图】所示:

可以发现 UserRepository 的实现类是 Spring 启动的时候,利⽤ Java 动态代理机制帮我们⽣成的实现类,⽽真正的实现类就是 SimpleJpaRepository。
通过之前的类的继承关系可以分析出 SimpleJpaRepository 是 Repository 接⼝、CrudRepository 接⼝、PagingAndSortingRepository 接⼝、JpaRepository 接⼝的实现。其中,SimpleJpaRepository 的部分源码如下:
@Repository
@Transactional(readOnly = true)
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
private static final String ID_MUST_NOT_BE_NULL = "The given id must not be null!";
private final JpaEntityInformation<T, ?> entityInformation;
private final EntityManager em;
private final PersistenceProvider provider;
private @Nullable CrudMethodMetadata metadata;
private EscapeCharacter escapeCharacter = EscapeCharacter.DEFAULT;
......
@Override
@Transactional
public void deleteAllInBatch() {
em.createQuery(getDeleteAllQueryString()).executeUpdate();
}
......
}
通过此类的源码,我们可以挺清晰地看出 SimpleJpaRepository 的实现机制,是通过 EntityManger 进⾏实体的操作,⽽ JpaEntityInforMation ⾥⾯存在实体的相关信息和 Crud ⽅法的元数据等。
上⾯讲到利⽤ Java 动态代理机制帮我们⽣成的实现类,那么关于动态代理的实现,我们可以在 RepositoryFactorySupport 设置⼀个断点,启动的时候,在我们的断点处就会发现 UserRepository 的接⼝会被动态代理成 SimpleJapRepository 的实现,如下图所示:

这⾥需要注意的是每⼀个 Repository 的⼦类,都会通过这⾥的动态代理⽣成实现类,在实际⼯作中 debug 看源码的时候,这个就可以派上用场。
2.7 小结
在接触了 Repository 的源码之后,我们在⼯作中遇到过⼀些类似需要抽象接⼝和写动态代理的情况,就可以学习 Repository 的源码的设计,例如上⾯的 7 个⼤ Repository 接⼝,我们在使⽤的时候可以根据实际场景,来继承不同的接⼝,从⽽选择暴露不同的 Spring Data Common 给我们提供的已有接⼝。这其实利⽤了 Java 语⾔的 interface 特性,在这⾥可以好好理解⼀下 interface 的妙⽤。