这是我看过的最好的Python零基础Pandas教程(可以下载)
作者:腾讯数据分析师 cooper
编辑:公众号高级农民工
今天给各位分享一下鹅厂数据分析师 cooper 的 Pandas 学习经验,争取让你十分钟入门 Pandas。
你可能零编程基础,但你应该会 Excel。入门 Python 最简单的途径就是去学习它最基础也是最重要的库之一:Pandas。
一方面这个库不难学,可以结合着你会的 Excel 来练习;另一方面,一旦你学会 Pandas 它就会发现比 Excel 做数据分析效率高太多了,能让你更加自信去地继续学习 Python。
Pandas 是一个高效而便捷的 Python 工具包,广泛应用于数据处理与分析的各种场景,在数据接入,清洗,聚合等功能上无往不利。原作者是来自于 AQR 资本公司的 McKinney,所以 Pandas 在(金融)时间数据的处理上更是大放异彩。笔者基于 Pandas 文档中的《10 minutes to pandas》篇章,也结合自己从业经历中的一些思考,整理了这篇基础文档,可供参考。
在使用 Pandas 几年的时间之后,再谈论起这款工具时,对其最深刻的感受是“全而简洁”。Pandas 提供的功能是相当全面的,数据怎么接入,缺失怎么处理,数据如何观察,变换,采样,汇总,几乎都可以在里面找到对应的答案。而集成了这么多的功能之后,Pandas 却几乎不会显得笨重,不让人觉得繁冗,其中一个原因是它提供的是重要却简洁的功能。
Pandas 就像是一个兴趣广泛却不轻易沉迷的孩子,在许多的模块上都是点到即止。 比如数据的接入,除了其 Pandas 本身的接口外,往前一步,可以用 Mysqldb 连接数据库,Xlwings 处理 Excel;比如数据的绘图,除了用自身的 plot 之外,往前一步可以用 Python 绘图全家桶 Matplotlib,也可以用“美图相机”Seaborn;统计往前一步用 Statsmodel,建模往前一步用 Scikit,Tensorflow。这些工具包的数据基础,几乎都是来自于 Pandas。
在数据处理与分析工作中,有三个基本问题是可以思考的:1.数据从哪里来?2.数据怎么处理?3.数据要往哪里去? 基于这三个问题,Pandas 提供了非常丰富的功能,用于各种场景下的操作和处理。以下将这些丰富的功能简化在十个应用场景里,逐一展开介绍。
1.创建数据
Python 里面有三种很重要的数据结构,其中一种是 Numpy 里的 Array,应用在了很多的科学计算场景里。另外两种则是 Pandas 的 Series 和 DataFrame,其中 Series 是一维的结构,DataFrame 则是二维的结构。DataFrame 可以来自于列表、字典,也可以来自于我们从各种接口里面读到的数据/文本。只要我们对其成功地 DataFrame 化,便可进入下一步的处理。
 图 1.1 Pandas 的两种结构
图 1.1 Pandas 的两种结构
 图 1.2 基础结构-Series
图 1.2 基础结构-Series

2.预览数据
就像是 SQL 里面常用 limit100 来观察数据样例,也像是 Excel 常用 Ctrl+上下箭头来观察数据的头部和尾部一样,不管在哪种工具里,人们拿到一份数据时,总是希望能对其有一个简单而直观的印象。在这个方面,Pandas 也提供了一些基本的预览数据的功能。
其中比较常用的有:1.通过 head 和 tail 观察头部和尾部的数据;2.通过 index 和 columns 观察索引和列名;3.通过 describe 进行简单的统计观察;4.通过 sort 进行排序观察。
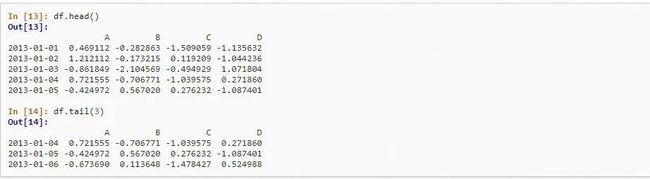
图 2.1 head 和 tail

图 2.2 index 和 columns

图 2.3 用 describe 进行简单的统计观察

图 2.4 用 sort_values 进行排序观察
3.数据筛选
数据筛选,其实也是一种广义上的数据观察,只是相对于上面所说的预览数据而言,数据筛选不再局限于数据的外部轮廓,而是深入到了其内部的肌理。
Pandas 的数据筛选,其中有 4 个功能是可以注意的:1.通过列名和行数直接筛选;2.基于行与列标签的 loc 筛选;3.基于行与列位置的 iloc 筛选;4.基于布尔索引的筛选。

图 3.1 基于列名的直接筛选

图 3.2 基于行与列标签的 loc 筛选

图 3.3 基于行与列位置的 iloc 筛选

图 3.4 基于布尔索引的筛选
4.缺失值处理
缺失值的处理,真的是一门手艺。在不同的场景下,缺失值可以填 0,填众数,或者平均值。把缺失值填充掉很简单,但往里面填什么数值,则是一个需要考量的问题。 作为一个简洁的工具,Pandas 提供了很便捷的缺失值处理功能,至于如何使用则是读者需思考的问题。

图 4.1 缺失值清除

图 4.2 缺失值填充
5.函数操作
Pandas 的许多功能,其实是层层递进的,比如预览数据时观察了数据的整体轮廓,数据筛选则深入了数据的内部肌理,缺失值处理是针对全盘数据的统一更改,那么到了函数操作这一部分时,则是对于数据所做的更为精细,灵活,也更为个性化的操作。
函数操作部分,Pandas 本身提供了一些简单的统计函数,如 mean,sum,count 等,可以直接应用;对于字符串也有对应的处理函数,如 lower,upper;而**pandas 在函数操作部分真正的大杀器,无疑是 lambda 匿名函数了,简洁,优雅,而无往不利。**通过 lambda 匿名函数,人们基本上可以随心所欲地对关心的局部数据做处理,成本则只需要写一句表达式即可。

图 5.1 简单的统计函数

图 5.2 lambda 匿名函数

图 5.3 字符串函数
6.数据拼接
数据的拼接,可能是无数 SQLBoy/Girl 的心头痛了,似乎人生就是无尽的 Join 和 Union,还要应对层出不穷的数据问题,一不小心就笛卡尔积了,然后就是出库失败或者数据爆仓。在数据拼接的层面,Pandas 提供的功能主要是 Merge 和 Concat。
其中 Merge 和 SQL 里的 Join 较为相似,用于数据的两两拼接,SQL 里的 Join 有六种情况,Merge 里的 How 则有四种参数可以选择。Concat 可用于多表的拼接,通过 axis 参数可以切换横向或者纵向的拼接方式,其特色是在于支持多表一次性拼接完成。

图 6.1 Merge 里的 how 参数

图 6.2 两表拼接的 Merge
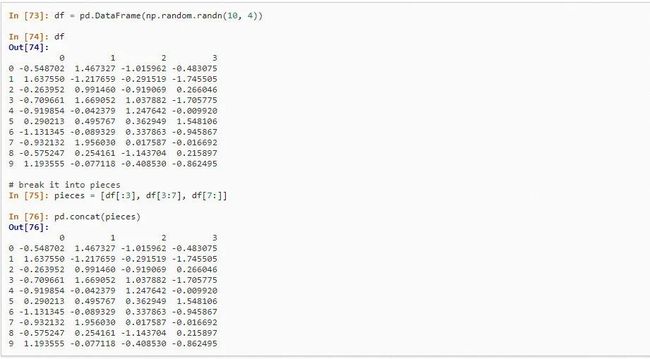
图 6.3 多表拼接的 Concat
7.数据聚合与重塑
数据的聚合与重塑,在 Excel 和 SQL 的场景里是非常重要的,尤其是数据透视表,几乎应用到了 Excel 的方方面面。但在 Python 的场景下,似乎在聚合和重塑方面的需求不是很大,虽然 Pandas 提供了与数据透视表相似的 Pivot 功能,但似乎好几年的时间里也没用过几次,以及 SQL 里面无所不在的 groupby 聚合,Pandas 虽然也支持,但似乎我没怎么深入使用过。

图 7.1 groupby

图 7.2 stack
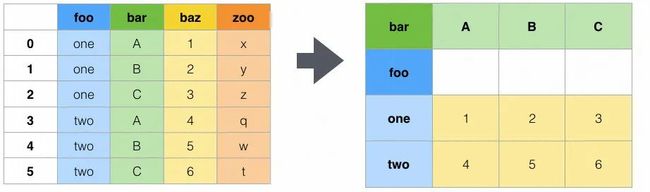
图 7.3 图解 groupby
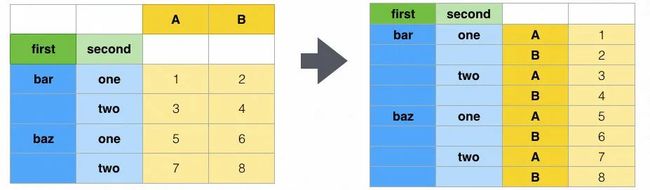
图 7.4 图解 stack
8.时间序列
时间数据的处理,是金融领域里一个古老而重要的问题,对于其它众多行业来说,其实也有其重要之处。在一些简单的场景里,常用到时间的格式化,日期和月份的加减,以及特殊日期的判别等;在一些深入的场景里,则需要考虑时间的采样,频率的转换,以及与时间序列高度相关的移动平均等内容。所幸 Pandas 本就是为处理金融数据而生的,所以在时间数据的处理上相对优异,基本上涵盖了用户的在时间序列上的各种需求点。
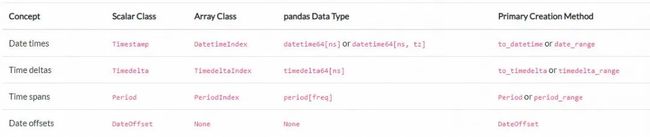
图 8.1 Pandas 处理时间序列的几个模块

图 8.2 时间序列的生成和格式化
9.数据绘图
Python 里面有很丰富的绘图工具包,人们常说数据绘图有三种境界,基于 model,基于 plot,和基于 chart,由此也生成了多种绘图包,如 matplotlib,seaborn,bokeh 等,都是优美而好用的工具。Pandas 的绘图功能,延续了其整体的“全而简洁”的风格,也是点到即止。 所以若你是想对数据做一些快速的绘图分析,可以直接使用 pandas 的 plot,若是要深入去绘制一些精美而繁密的图表,则可以在 pandas 的基础上,借用其它工具包来实现。


图 9.1 用 Pandas 绘制相关系数图

图 9.2 用 pandas 绘制柱形图
10.数据读取与写入
以上所述的内容,更多是对于手头的数据的处理,而数据的基本思考里还有很重要的两个问题,即数据从哪里来和到哪里去。Pandas 在数据的输入输出里提供了全面而丰富的接口,基本上覆盖了我们日常里的所有数据类型。 比如数据库的数据,Excel 的数据,Html 的数据,Json 的数据,甚至是传统软件 SAS 和 Spss 里的数据,都可以轻松地在 Pandas 里进出。

图 10.1 Pandas 的部分 IO 接口
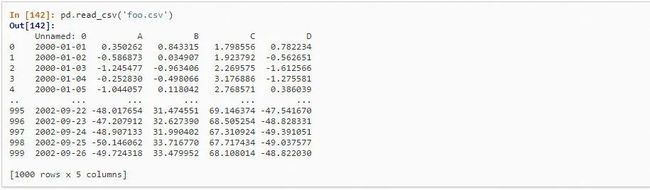
图 10.2 Pandas 读取 CSV 数据
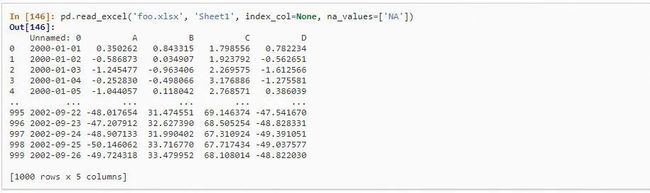
图 10.3 Pandas 读取并处理 Excel 数据
综合上述内容,基于 Pandas 的官方文档,本文梳理和介绍了其十个重要和常用的功能:
01.创建数据: Series 和 DataFrame 是 Pandas 的基本结构;
02.预览数据: 用于观察数据的整体轮廓;
03.数据筛选: 用于观察数据的内部肌理;
04.缺失值处理: 缺失值处理是一个简单但需要深思的问题;
05.函数操作: 对局部数据展开的个性化处理,lambda 函数是大杀器;
06.数据拼接: 对两表或多表的合并操作,主要是 Merge 和 Concat;
07.数据聚合与重塑: 对原有表结构的调整和变换;
08.时间序列: 一个古老而永恒的数据领域;
09.数据绘图: Pandas 提供了简单化的绘图基础;
10.数据读取与写入: Pandas 提供了全面而丰富的接口。
十分钟的时间,是时间长河里一片微小的浪花。十分钟可以让年华老去,十分钟也可以用来入门 Pandas,了解其中十个重要而常用的功能。如果你对 Pandas 感兴趣并想要学习的话,这篇文档也许可以作为一个参考。
最后,分享下 Pandas 的最新官方文档(2020 年 3 月 18 日),有 3000 页 PDF,保存下来作为资料查询很不错,扫码回复:pandas 即可获取:

继续送书,前两天中奖的朋友是:@127.0.0.1,麻烦看到以后,在后台加我微信,告诉我快递信息,之后安排寄给你。
今天也会从留言区中抽一位朋友,送出下面一本书,后续公布中奖人,感兴趣的话就留言吧,中奖率还是蛮高的。多说句,如果你留言了,那么一定要关注我之后的推文,说不定你就中奖了,如果你忘记了,我就会发给别人。

