Eclipse使用Java Selenium抓取众筹网站的数据
Eclipse使用Java Selenium抓取众筹网站的数据
- Selenium简介
-
- 百度百科
- 下载地址
- 目标网站
- 代码实现
-
- 整体架构
- 代码
-
- DAO层
-
- LinkDB类
- TableManage类
- Model层
- Selenium包
-
- 更新已存在项目的方法
- 经验教训
-
- Xpath与正则表达式
- 关于无法定位元素
- 持续抓取过程中线程问题
- 服务器租用与程序设定
Selenium简介
百度百科
Selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
下载地址
我使用的是Chrome浏览器进行数据抓取,不同版本的Chrome需要下载对应的Selenium包。查看自己的Chrome版本可以在右上角的帮助->关于Chrome中看到。具体的Selenium下载地址这里也帮读者附上:http://selenium-release.storage.googleapis.com/index.html
目标网站
这次我需要爬取的网站为疾病众筹网站–轻松筹,在主页上有25个不同的展示窗口,存放了25个不同的案例。我需要获得这25个不同的案例的具体信息,跟踪记录每一个案例的后续情况(后续案例可能不在首页出现,但是仍然可以有url存在,项目会继续传播,爱心人士可以继续捐款)。
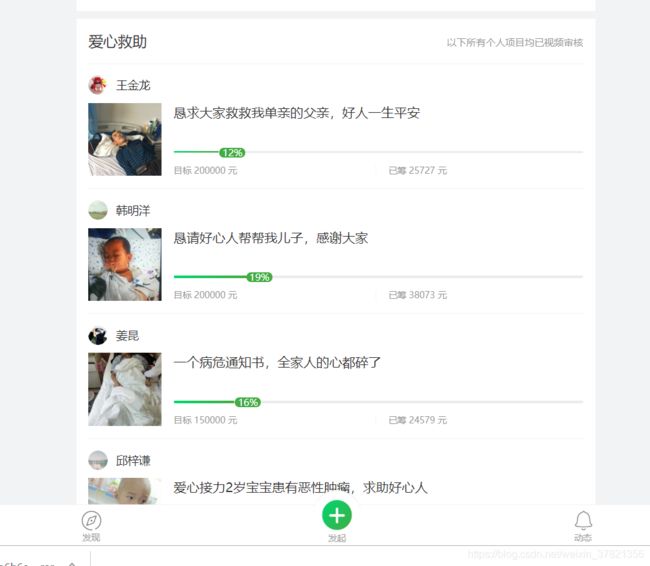
点击每一个案例的具体情况是这样的页面,我会抓取每一个具体案例的不同信息,如标题、发起人姓名、目标金额、获得帮助次数等。

代码实现
整体架构
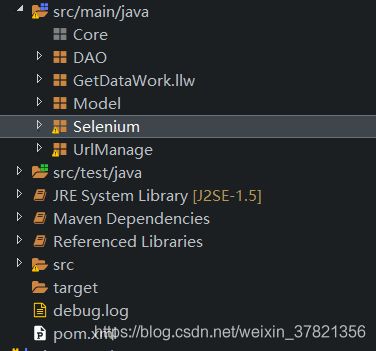
DAO层 ————负责链接数据库与数据库中表的操作方法
Model层————负责实体数据模型实现
Selenium层———负责具体数据的抓取
UrlManage层———负责管理每个项目的URL属于辅助包,后续没有继续应用
代码
DAO层

DAO层中有两个类
LinkDB负责Eclispe与Mysql的连接
TableManage负责具体数据库中表的操作
LinkDB类
package DAO;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class LinkDB {
public static Connection conn=null;
public static Statement stmt=null;
public LinkDB() {
try {
Class.forName("com.mysql.jdbc.Driver");
System.out.println("成功连接到数据库!");
conn= DriverManager.getConnection(
"jdbc:mysql://localhost:3306/qsc","root","123456");
stmt=conn.createStatement();
}catch(ClassNotFoundException e) {
e.printStackTrace();
}catch(SQLException e) {
e.printStackTrace();
}
}
}
TableManage类
package DAO;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.Statement;
import java.util.ArrayList;
import java.util.List;
import Model.Belongings;
import Model.Classifiers;
import Model.DongTai;
import Model.Proofment;
import Model.QscProject;
import Model.TopHelper;
public class TableManage {
/*
* 创建指定名称的表
* tablename stmt
*/
public String CreateTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "title varchar(255) not null,"+"finished int(10),"+
"name varchar(255),"+"target varchar(255),"+
"already varchar(255),"+"helptimes varchar(255),"
+"date varchar(255),"+"des varchar(3000),"+"url varchar(300),"
+"zhuanfa varchar(255),"+"inindex int(10)"+")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 完结的项目创捷Helper的存储表
*/
public String CreateHelperTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "name varchar(255) not null,"+
"money varchar(255),"+"people_bring varchar(255)"+
")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 向Helper表中插入数据
*/
public void InsertToHelper(List helpers,String tablename,Connection conn)
{
for(int i=0;i GetUrl(String tablename,Connection conn)
{
List urls=new ArrayList();
try {
String presql="select url from"+" `qsc`."+"`"+tablename+"`"+"where finished=0";
PreparedStatement ps=conn.prepareStatement(presql);
ResultSet res=ps.executeQuery();
while(res.next()) {
urls.add(res.getString(1));
}
System.out.println("已经获取未完成案例全部url");
}catch(Exception e)
{
e.printStackTrace();
}
return urls;
}
/*
* 判断项目是否已经结束,取是否结束字段判断
*/
public boolean IfProjectFinished(String url,Connection conn)
{
boolean result=false;
try {
String presql="select finished from `qsc`.`qsc_allurls` where url ="+url;
PreparedStatement ps=conn.prepareStatement(presql);
ResultSet res=ps.executeQuery();
if(res.getInt(1)==1)
{
result=true;
}
}catch(Exception e)
{
e.printStackTrace();
}
return result;
}
/*
* 插入名字
*/
public void InsertTheName(String url,Connection conn,String name)
{
try {
String presql="update `qsc`.`qsc_allurls` set name=? where url=?";
PreparedStatement pst=conn.prepareStatement(presql);
pst.setString(1, name);
pst.setString(2, url);
pst.executeUpdate();
}catch(Exception e)
{
e.printStackTrace();
}
}
/*
* 改变结束状态
*/
public void ChangeFinished(String url,Connection conn)
{
try {
String presql="update `qsc`.`qsc_allurls` set finished=? where url=?";
PreparedStatement pst=conn.prepareStatement(presql);
pst.setInt(1, 1);
pst.setString(2, url);
pst.executeUpdate();
}catch(Exception e)
{
e.printStackTrace();
}
}
/*
* 获取项目ID
*/
public List GetNames(String tablename,Connection conn)
{
List names=new ArrayList();
try {
String presql="select name from"+" `qsc`."+"`"+tablename+"`";
PreparedStatement ps=conn.prepareStatement(presql);
ResultSet res=ps.executeQuery();
while(res.next()) {
names.add(res.getString(1));
}
System.out.println("已经获取全部url");
}catch(Exception e)
{
e.printStackTrace();
}
return names;
}
/*
* 创建证明资料的表
*/
public String CreateProofTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "patient varchar(255) not null,"+"patient_des varchar(255),"+"illness varchar(255),"+"illness_des varchar(255),"+
"moneygetter varchar(255),"+"moneygetter_des varchar(255)"+
")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 向证明表中插入信息
*/
public void AddToProof(Proofment proof,Connection conn,String tablename)
{
try {
String sql= "INSERT INTO `qsc`."+"`"+tablename+"`"+" (`patient`, `patient_des`, `illness`, `illness_des`, `moneygetter`, `moneygetter_des`) VALUES (?,?, ?, ?, ?, ?);";
PreparedStatement ps=conn.prepareStatement(sql);
ps.setString(1, proof.getPatient());
ps.setString(2, proof.getPatient_des());
ps.setString(3, proof.getIllness());
ps.setString(4, proof.getIllness_des());
ps.setString(5, proof.getMoneygetter());
ps.setString(6, proof.getMoneygetter_des());
ps.executeUpdate();
System.out.println("插入了证明信息");
}catch(Exception e)
{
e.printStackTrace();
}
}
/*
* 创建财产表
*/
public String CreateBelongTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "house varchar(255) not null,"+"cars varchar(255),"+"insurance varchar(255)"+
")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 插入财产数据
*/
public void AddToBelong(Belongings belong,Connection conn,String tablename)
{
try {
String sql= "INSERT INTO `qsc`."+"`"+tablename+"`"+" (`house`, `cars`, `insurance`) VALUES (?,?, ?);";
PreparedStatement ps=conn.prepareStatement(sql);
ps.setString(1, belong.getHouse());
ps.setString(2, belong.getCars());
ps.setString(3, belong.getInsurance());
ps.executeUpdate();
System.out.println("插入了财产信息");
}catch(Exception e)
{
e.printStackTrace();
}
}
/*
* 创建动态表
*/
public String CreateDongTaiTable(String tablename,Statement stmt)
{
String creatsql = "CREATE TABLE "+tablename+"("
+ "name varchar(255) not null,"+"text varchar(255),"+"date varchar(255),"+
"catchdate varchar(255),"+"des varchar(500)"+")";
try {
stmt.executeLargeUpdate(creatsql);
System.out.println("创建表"+tablename+"成功!");
}catch(Exception e)
{
e.printStackTrace();
}
return tablename;
}
/*
* 向动态表中插入数据
*/
public void AddToDongTai(List dongtais,Connection conn,String tablename)
{
for(int i=0;i classifiers,Connection conn,String tablename)
{
for(int i=0;i Model层
Model层负责创建项目数据结构对象,自我感觉像是在写JSP中的JavaBean。主要实体类为QscProject。内设了一些我需要存储的字段,筹款是否完成,项目是否在网站的首页等等。
package Model;
import java.util.List;
public class QscProject {
private String name;
private String title;
private String date;
private String desciption;
private String phurl;
private String target;
private String alreadyget;
private String helptimes;
private String url;
private String zhuanfa;
private int if_finish;
private int inindex;
private List helpers;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
public String getDesciption() {
return desciption;
}
public void setDesciption(String desciption) {
this.desciption = desciption;
}
public String getPhurl() {
return phurl;
}
public void setPhurl(String phurl) {
this.phurl = phurl;
}
public String getTarget() {
return target;
}
public void setTarget(String target) {
this.target = target;
}
public String getAlreadyget() {
return alreadyget;
}
public void setAlreadyget(String alreadyget) {
this.alreadyget = alreadyget;
}
public String getHelptimes() {
return helptimes;
}
public void setHelptimes(String helptimes) {
this.helptimes = helptimes;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getZhuanfa() {
return zhuanfa;
}
public void setZhuanfa(String zhuanfa) {
this.zhuanfa = zhuanfa;
}
public int getIf_finish() {
return if_finish;
}
public void setIf_finish(int if_finish) {
this.if_finish = if_finish;
}
public List getHelpers() {
return helpers;
}
public void setHelpers(List helpers) {
this.helpers = helpers;
}
public int getInindex() {
return inindex;
}
public void setInindex(int inindex) {
this.inindex = inindex;
}
}
Selenium包
重点来了,Selenium包中我只写了一个Getter类,类中有按照需求写的一些方法。
先来看类中的引用包和属性,类中直接设置了两个静态量,LinkDB和TableManage,负责连接数据库和读写表。
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import UrlManage.*;
import DAO.LinkDB;
import DAO.TableManage;
import Model.QscProject;
import Model.TopHelper;
import Model.*
;public class Getter {
private static LinkDB mylink=new LinkDB();
private static TableManage tablemanage=new TableManage();
用于获取首页的项目的方法GetIndex(),方法返回了一个String的List,目的是为了后续判断已经存在数据库中的项目在更新时,判断还是否存在在首页上面。
代码中设置Selenium的配置代码。driver.get(url)为浏览器打开目标网页。
WebDriver driver;
System.setProperty("webdriver.chrome.driver", "D:\\chromedriver_win32\\chromedriver.exe");
driver =new ChromeDriver();
driver.get("https://m2.qschou.com/index_v7_3.html");
GetIndex()全部代码
public List GetIndexUrl(){
List namesinindex=new ArrayList();
WebDriver driver;
System.setProperty("webdriver.chrome.driver", "D:\\chromedriver_win32\\chromedriver.exe");
driver =new ChromeDriver();
driver.get("https://m2.qschou.com/index_v7_3.html");
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
List webElement = driver.findElements(By.xpath("/html/body/div[1]/div[3]/div[2]/div/a"));
List webElementName = driver.findElements(By.xpath("/html/body/div[1]/div[3]/div[2]/div/div/a/span[2]"));
List NamesGetted=new ArrayList(tablemanage.GetNames("qsc_allurls", mylink.conn));
if( webElement!=null)
{
for(int i=0;i 更新已存在项目的方法
public void UpDateProject(List namesinindex)
{
WebDriver driver;
System.setProperty("webdriver.chrome.driver", "D:\\chromedriver_win32\\chromedriver.exe");
driver =new ChromeDriver();
List UrlsGetted=tablemanage.GetUrl("qsc_allurls", mylink.conn);
try {
for(int i=0;i 经验教训
Xpath与正则表达式
在这次的数据爬取中,我刻意回避了正则表达式的使用(因为我不会),全程使用Xpath定位网页元素。定位方法为,鼠标移动到目标元素上后右键,点击审查元素。

随后在网页源码中点击Copy Xpath即可。

关于无法定位元素
有时候会出现无法定位到目标Xpath的情况,这时候原因有如下的可能:
1.页面需要加载,还没有加载完全部的元素。
解决方法:设置程序等待即可。
2.元素定位出现问题,需要滚动网页的滚动条。
解决方法:滚动滚动条即可。
下面的代码给出了设置等待和自动滚动滚动条的代码。等待了2000毫秒,滚动了一个滚动条的长度。
Thread.sleep(2000);
((JavascriptExecutor) driver).executeScript("window.scrollTo(0, document.body.scrollHeight)");
Thread.sleep(2000);
((JavascriptExecutor) driver).executeScript("window.scrollTo(0, document.body.scrollHeight)");
Thread.sleep(2000);
((JavascriptExecutor) driver).executeScript("window.scrollTo(0, document.body.scrollHeight)");
持续抓取过程中线程问题
在我的项目中,我需要持续循环运行抓取程序。main方法中的线程不会自动回收,记得将不用的对象及时指向null,并且定期执行系统的垃圾回收。
public static void main(String[] args)
{
int count=0;
while(true){
count++;
Getter test=new Getter();
test.UpDateProject(test.GetIndexUrl());
test=null;
if(count==100)
{
System.gc();
count=0;
}
}
服务器租用与程序设定
这次使用了腾讯云,系统为Windows Server。我只是简单的复制了在本机的操作环境,将Eclipse中的程序简单的移植过去,这种方法较low,请大家不要学习。
