保姆级爬虫零基础一条龙式教程(超详细)
一、准备工作:
1、网页分析:
进入目标网页,按下键盘F12,必须要认识图中画圈的部分。

箭头:
这个小箭头非常实用,点击后,在正常网页中点击哪个部分,代码区高光就会找到相应的代码。
Element:
包含网页源码,很多数据都从这里获得。
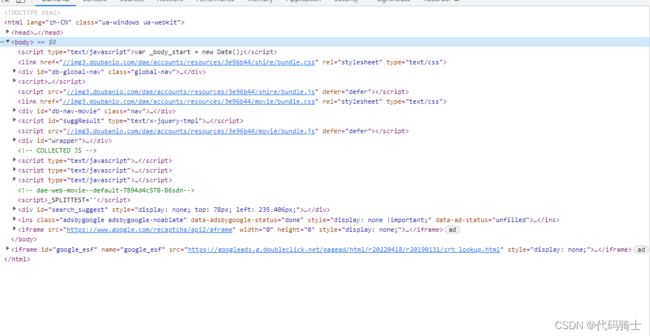
NetWork:
网络工作记录,按下图顺序点击,会得到很多响应信息。比如:请求头(Header)信息、Cookie、User-Agent等等,作用下面说。
 2、环境配置:
2、环境配置:
需要提前下载好,这部分下载去网上搜就行,这里不做过多描述。
python包安装:
bs4->BeautifulSoup(用于网页解析,获取数据)
re->正则表达式进行文字匹配
urllib.request,urllib.error->指定URL获取网页数据
xlwt->进行Excel操作
sqlite3->进行数据库操作#本教程面向编程零基础不会涉及数据库操作,这个可以不下
(后面还会用到一些其他的,看到再说)
二、构建流程:
四个模块:获取-解析-保存-可视化。后面都会写相应的函数。
1、获取网页数据
首先获取网页数据,想要获取网页数据,就要向目标网页发出请求,请求的方式有很多种,python爬虫最常用的有两种Get和Post,这里主要介绍一下这两种请求怎么使用。
这是我们测试请求方式的网站:
httpbin.org http://httpbin.org/
http://httpbin.org/
打开点击HTTP Methods: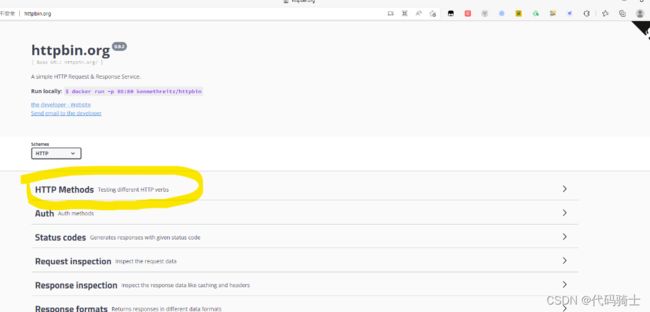
选择一种测试方式: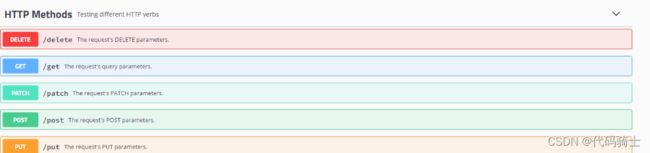
首先我们来做一个Get请求:
import urllib.request as ur
res = ur.urlopen("http://httpbin.org/get")
print(res.read().decode('utf-8'))非常简单使用的请求方式,平时只要加入一个请求头就可以了,不需要数据包等参数。
我们再来看一下Post请求怎么做:
post请求需要我们封装好一个字典形式的数据包并解码成二进制的格式传递给要访问的网页,同时在网址后面要有 /post 标识,然后将数据包传入,代码如下:
import urllib.request as ur
import urllib.parse as up
data = bytes(up.urlencode({"hello":"world"}),encoding="utf-8")#字典封装数据包解码成2进制
res = ur.urlopen("http://httpbin.org/post",data=data)#使用post请求
print(res.read().decode('utf-8'))那么,这种请求发出去都包含什么信息呢?我们来运行上述代码来看一下:
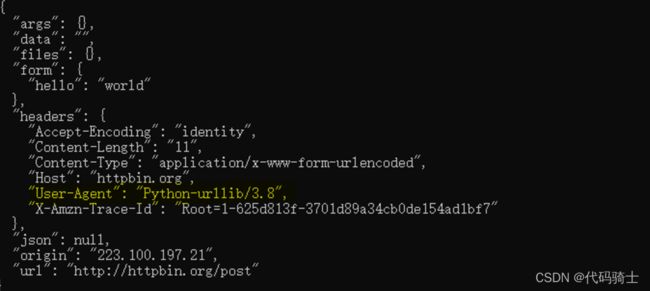
上图就是网站接收到的你发出的请求,也就是你的数据信息。非常尴尬的是,你的代理直接写的就是python-urllib,这无疑就是在对你访问的网页进行挑衅,“我就是爬虫,我就是来爬你的!”这样做无疑是非常愚蠢的,一般包容性强的网站可不会理会你,但是如果遇到强势一点的网站,那么迎接你的肯定就是:418或者403。
所以我们通常要对爬虫进行伪装,也就是用浏览器的身份去爬取信息而不是python。稍后我们会讲如何伪装,先别急,先看看其他操作。
超时处理:
import urllib.request as ur
res = ur.urlopen("http://httpbin.org/get",timeout=0.01)
print(res.read().decode('utf-8'))如果响应时间超过timeout就代表程序没有响应,这时会报错。然后我们进行超时处理。
*这里timeOut设置成0.01是为了测试超时效果

import urllib.request as ur
import urllib.error
try:
res = ur.urlopen("http://httpbin.org/get",timeout=0.01)
print(res.read().decode('utf-8'))
except urllib.error.URLError as e:
print("Time Out!") 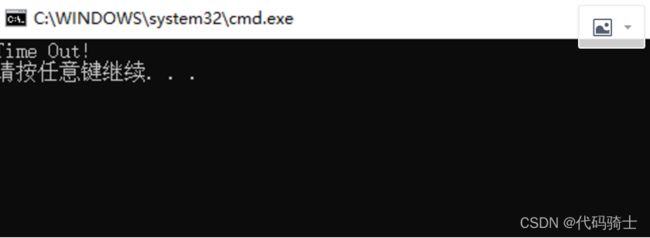
查看状态码:
import urllib.request as ur
import urllib.error
res = ur.urlopen("http://douban.com")
print(res.status)
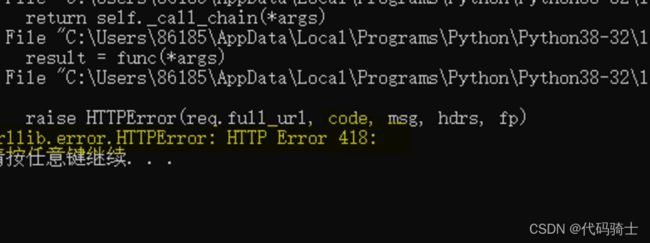
提示418,证明你的爬虫身份暴露了。
输出网页头:
import urllib.request as ur
import urllib.error
res = ur.urlopen("http://baidu.com")
print(res.getheaders())
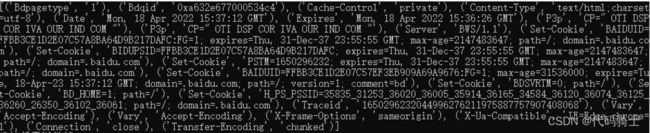 比对一下:
比对一下:

无差别。
上面这些示例主要想说明:requset的功能是十分强大的,它所获取的信息是你能在网页上找到的所有信息。
获取部分信息:
import urllib.request as ur
import urllib.error
res = ur.urlopen("http://www.baidu.com")
#print(res.getheaders());
print(res.getheader("Set-Cookie"))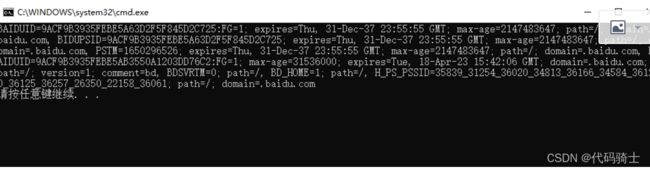
由此可见Request函数貌似可以访问网页上的所有信息这样我们也就可以获取网页代理的信息,通过这个代理就可以对爬虫进行伪装,防止被网站发现了。
伪装爬虫——模拟网页代理:
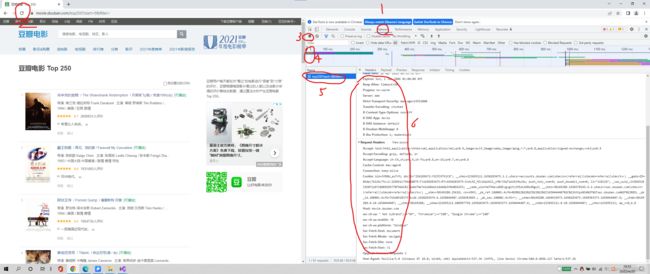
首先,找到我们浏览器的代理信息:
F12 -- NetWork -- Header -- User-Agent
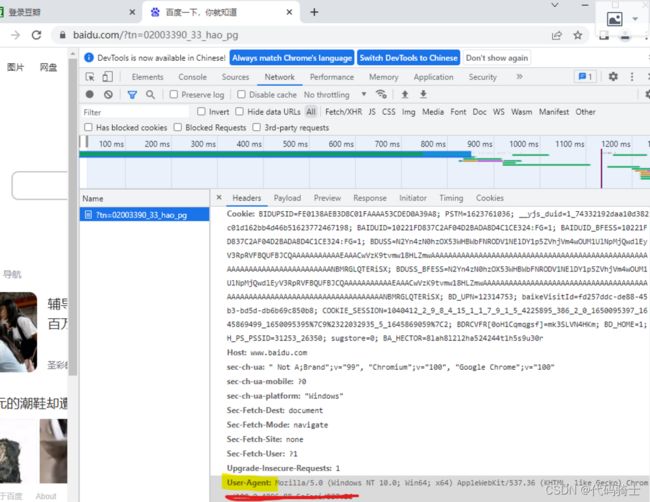
1、复制粘贴到代码中封装成键值对。
如果封装一个代理还是会被发现是爬虫,那就多封装几个信息加强对网站的迷惑性。
通常还会使用:Remote Address等等。
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}2、设置请求方式:(get可以不用写/get)
req = ur.Request(url = url,data=data,headers = headers,method="POST")
3、读取网页源码:
import urllib.request as ur
import urllib.error as ue
import urllib.parse as up
url = "http://httpbin.org/post"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}
data = bytes(up.urlencode({'name':'eric'}),encoding='utf-8')
req = ur.Request(url = url,data=data,headers = headers,method="POST")
res = ur.urlopen(req)
print(res.read().decode("utf-8"))
输出结果:
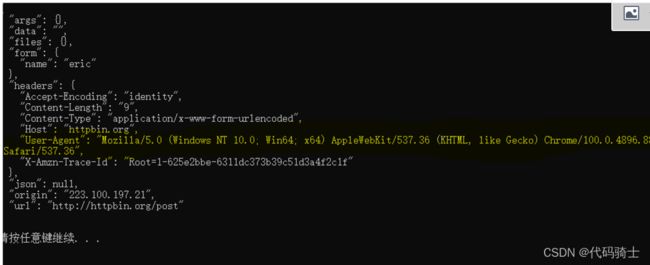
妈妈再也不用担心我的爬虫被发现啦!
下面再用get请求的方式访问一下刚刚被发现的网站:
import urllib.request as ur
import urllib.error as ue
import urllib.parse as up
url = "https://douban.com"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}
req = ur.Request(url = url,headers = headers)
res = ur.urlopen(req)
print(res.read().decode("utf-8"))
成功打入对方内部,是获取信息的第一步。
下面进行获取数据:
示例网址:豆瓣电影 Top 250
(1)得到一个指定页面信息
import urllib.request as ur
import urllib.error as ue
import urllib.parse as up
#得到一个指定的URL内容
def askURL(url):
#模拟请求头
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}
#保存网页信息的字符串
html=""
#请求网页信息
req = ur.Request(url,headers=header)
try:
res = ur.urlopen(req)
html=res.read().decode("utf-8")
print(html)
except ue.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
if __name__ == "__main__":
url = "https://movie.douban.com/top250?end=249&filter="
askURL(url)
print(1)
用循环获取多个页面信息:
import urllib.request as ur
import urllib.error as ue
import urllib.parse as up
#得到一个指定的URL内容
def askURL(url):
#模拟请求头
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}
#保存网页信息的字符串
html=""
#请求网页信息
req = ur.Request(url,headers=header)
try:
res = ur.urlopen(req)
html=res.read().decode("utf-8")
print(html)
except ue.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
#爬取网页
def getData(url):
dataList = []
for i in range(0,10):#调用获取页面信息函数10次250条
url = url+str(i*25)#左闭右开
html = askURL(url)#保存获取到的网页源码
#逐一解析
if __name__ == "__main__":
url = "https://movie.douban.com/top250?start="
#1、爬取网页
dataList = getData(url)
savepath = ".\\豆瓣电影Top250.xls"
2、解析网页数据
解析网页数据常用的库就是BeautifulSoup
示例:百度一下,你就知道
(1)、获取网页Tag(标签):
import urllib.request as ur
from bs4 import BeautifulSoup
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
print(html.title)
print(html.a)
print(type(html.title))
print(type(html.a))
print("标签及其内容:默认是第一个找到的")输出:
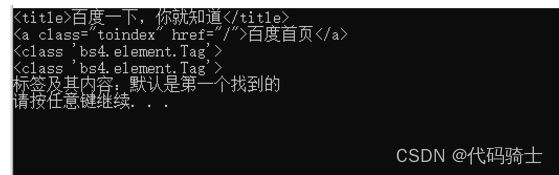
(2)获取NavigableString(标签里的内容):
以字符串形式:
import urllib.request as ur
from bs4 import BeautifulSoup
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
print(html.title)
print(html.title.string)输出:
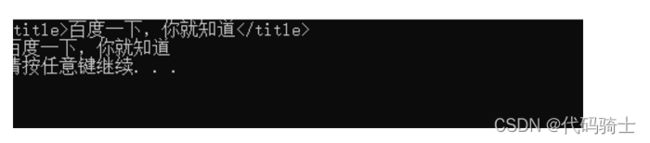
获取标签的内容以字典形式:
import urllib.request as ur
from bs4 import BeautifulSoup
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
print(html.a)
print(html.a.attrs)输出:

(3) 获取BeautifulSoup(整个网易文档):
import urllib.request as ur
from bs4 import BeautifulSoup
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
print(html)
print(type(html))输出:

(4)获取Comment(注释:特殊的NavigableString输出内容不包含字符串):
import urllib.request as ur
from bs4 import BeautifulSoup
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
print(html.a.string)输出:

(5)遍历BeautifulSoup:
我们什么时候用遍历这个词?通常是用在一组可连续查找的数据结构中对吧,比如列表、树等等。在我们的beautifulsoup中获取的内容也都是存在列表中的,如下:
import urllib.request as ur
from bs4 import BeautifulSoup
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
print(html.body.contents)输出:
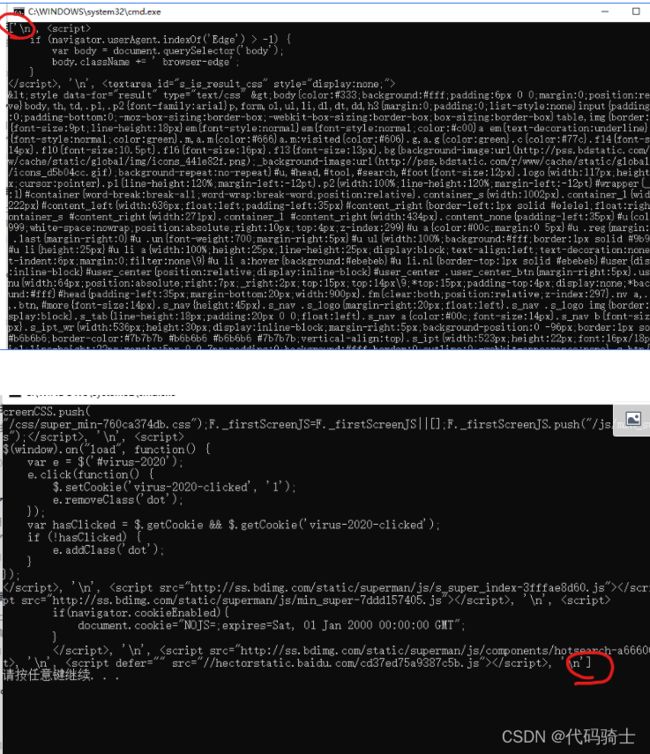
既然是列表,那么我们就可以用下标来找其中的某一个固定元素:
import urllib.request as ur
from bs4 import BeautifulSoup
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
print(html.body.contents[0])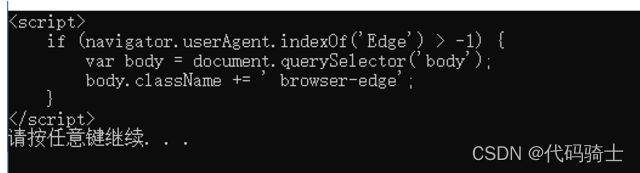
除了content以外,还有更多的获取子节点的方法:
BeautifulSoup——搜索
上面讲的是一种遍历方法,把获取的文件内容(结点)放在容器(生成器)中然后遍历找到某一个想要获取的信息(元素)。
接下来介绍一种更加实用且便捷的方式,通过搜索来到自己想要的内容。
(1)find_all()
字符串过滤:会找到与字符串完全匹配的内容。
import urllib.request as ur
from bs4 import BeautifulSoup
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.find_all("a")
print(t_list)
(2)正则表达式搜索:使用search()方法来匹配内容
import urllib.request as ur
from bs4 import BeautifulSoup
import re
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.find_all(re.compile("a"))
print(t_list)
这次输出的内容明显和上次的不同,因为在使用正则表达式时要按照符合正则表达式的内容进行查找,而不是单独去找一个带“a”的字符串。
但是相同点是,查找的范围都是标签,字符串查找“a”是找Tag就是a的标签
正则表达式查找“a”是找Tag中带有a的标签。
(3)方法:传入一个函数,根据函数来搜索。
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.find_all(name_is_exists)
print(t_list)
查找所有带有name的标签。
(4)kwargs(参数)搜索
查找标签中带有id=head的字段。
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.find_all(id = "head")
print(t_list)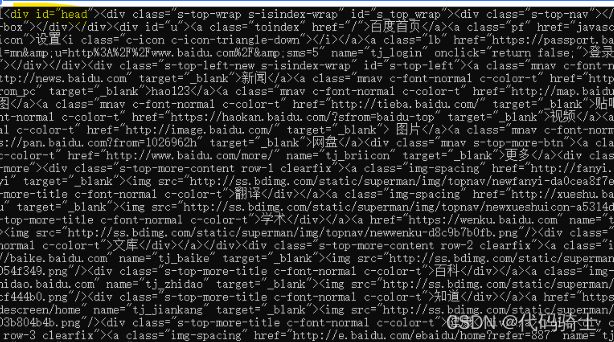
查找一段带有这个超链接的字段。
mport urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.find_all(href = "http://news.baidu.com")
print(t_list) 
(5)text 文本参数
获取文本内容
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.find_all(text = "hao123" )
for i in t_list:
print(i) 
还可以用列表去查找文本
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.find_all(text = ["hao123","新闻","视频"] )
for i in t_list:
print(i) 
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.find_all(text = re.compile("\d") )#用正则表达查找带有特定内容的文本字符串
for i in t_list:
print(i)
(6)limit 参数
限定查找个数。
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.find_all("a",limit=3)
for i in t_list:
print(i)
(7)css选择器
通过标签查找
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.select("title")
for i in t_list:
print(i)
(8)通过类名查找
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.select(".mnav")
for i in t_list:
print(i)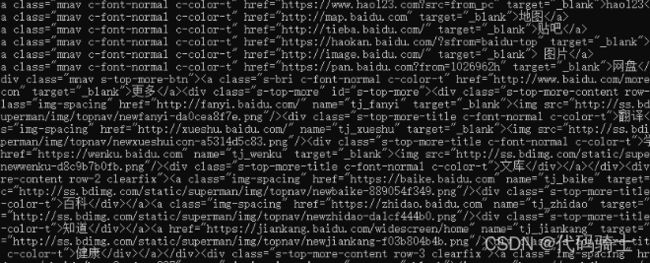
(9)通过id查找
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.select("#u1")
for i in t_list:
print(i)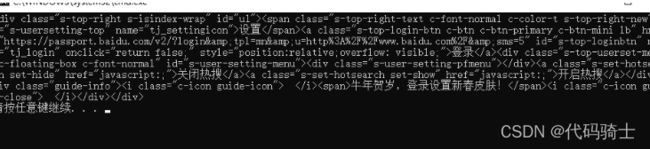
(10) 通过属性查找
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.select("a[class = 'text-color']")
for i in t_list:
print(i)
(11) 通过子标签查找
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.select("div>div")
for i in t_list:
print(i)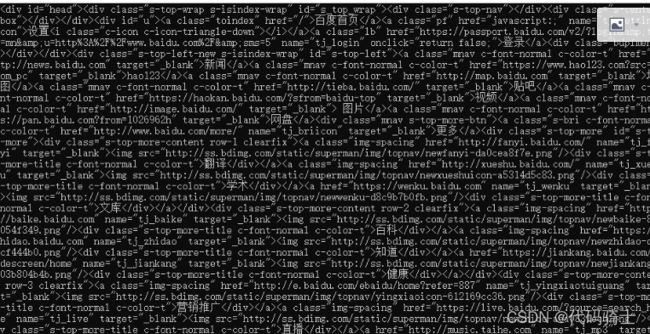
(12)通过兄弟标签查找
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.select("div~div")
for i in t_list:
print(i)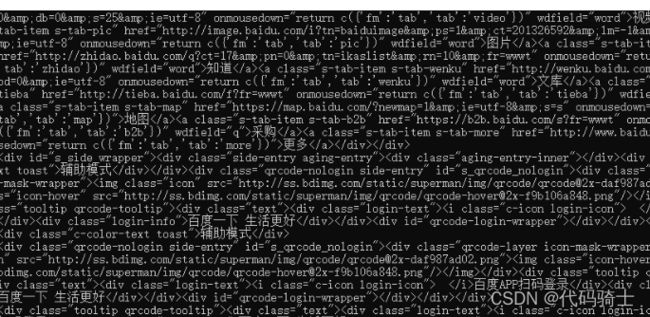
(13)通过下标查找文本
import urllib.request as ur
from bs4 import BeautifulSoup
import re
def name_is_exists(tag):
return tag.has_attr("name")
url = ur.urlopen("https://baidu.com")
html = BeautifulSoup(url,'html.parser')
t_list = html.select("div~div")
print(t_list[1].get_text())
正则表达式——Re库

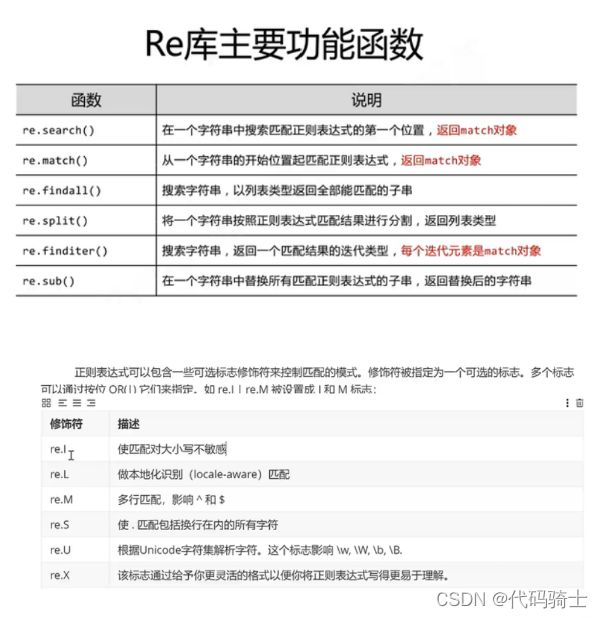
举个例子:
字符串的匹配测试:
import re
slist=["aaa","AA","ACA","AAA","CAB"]#等待校验的字符串列表
bat = re.compile("AA")#定义正则表达式
for i in slist:
res = bat.search(i)#搜索与之匹配的字符串
print(res) 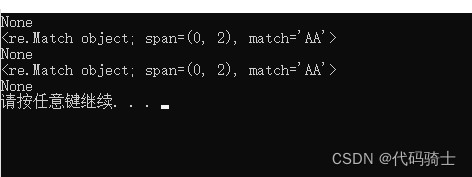
上述匹配也可以简写:
import re
bat = re.compile("AA")#定义正则表达式
m = re.search("AA","ABCAA");
print(m) 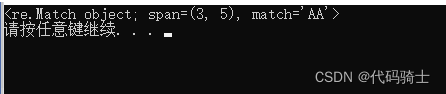
findall()与正则表达式结合
将符合规则的字符存入列表。
import re
print(re.findall("[A-Z]","sdsaASDSAdfdsSasdSda")); 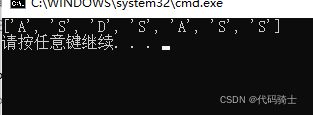
sub()函数(替换)
import re
print(re.sub("a","A","sdsaASDSAdfdsSasdSda"));#所有a被A替换 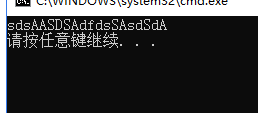
建议在正则表达式中,被比较的对象前面加上 r 避免转义字符被误用
a = r"\asdas\'"
正则提取
找到肖申克的救赎代码信息:
对内容进行正则提取:
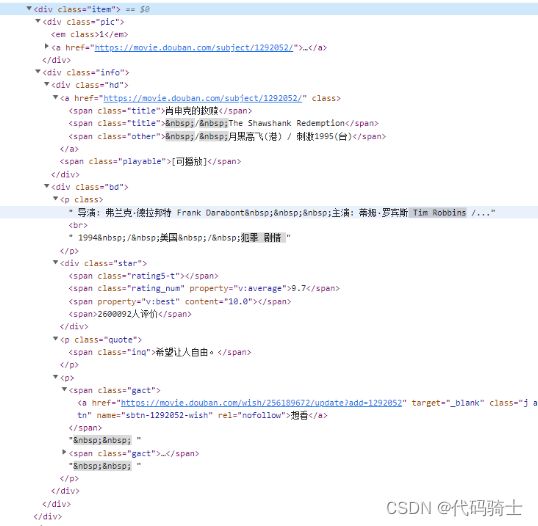
#创建正则表达式
#影片链接
findLink=re.compile(r'')#(.*?):.*:任意字符出现多次 ?:前面的元组内容出现仅出现一次
#影片图片
findImagSrc=re.compile(r'(.*)')
#评分
findRating = re.compile(r'')
#评价人数
findJudge = re.compile(r'(\d)*人评价')
#找到概况
findInq = re.compile(r'(.*)')
#相关内容
findBd = re.compile(r'(.*)
',re.S) 标签解析
将爬取数据存入列表
import urllib.request as ur
import urllib.error as ue
import urllib.parse as up
from bs4 import BeautifulSoup
import re
#得到一个指定的URL内容
def askURL(url):
#模拟请求头
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.127 Safari/537.36 Edg/100.0.1185.44"}
#保存网页信息的字符串
html=""
#请求网页信息
req = ur.Request(url,headers=header)
try:
res = ur.urlopen(req)
html=res.read().decode("utf-8")
#print(html)
except ue.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
#创建正则表达式
#影片链接
findLink=re.compile(r'')#(.*?):.*:任意字符出现多次 ?:前面的元组内容出现仅出现一次
#影片图片
findImagSrc=re.compile(r'(.*)')
#评分
findRating = re.compile(r'')
#评价人数
findJudge = re.compile(r'(\d)*人评价')
#找到概况
findInq = re.compile(r'(.*)')
#相关内容
findBd = re.compile(r'(.*?)
',re.S)
#爬取网页
def getData(url):
dataList = []
for i in range(0,1):#调用获取页面信息函数10次250条
url = url+str(i*25)#左闭右开
html = askURL(url)#保存获取到的网页源码
#逐一解析
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):#查找比较好的字符串放入列表
#print(item) 测试:查看电影item全部信息
data = [] #保存一部电影的所有信息
item = str(item)
#影片详情链接
Link = re.findall(findLink,item)[0]#re库用来通过正则表达式查找指定字符串,0表示只要第一次找到的
data.append(Link)
ImgSrc = re.findall(findImagSrc,item)[0]
data.append(ImgSrc)
Title = re.findall(findTitle,item)#区分中英文
if len(Title)==2:
ctitle=Title[0]
data.append(ctitle)
otitle = Title[1].replace("/","")#去掉无关符号
data.append(otitle)#添加外国名
else:
data.append(Title[0])
data.append(' ')#表中留空
Rating = re.findall(findRating,item)[0]
data.append(Rating)
Judge = re.findall(findJudge,item)[0]
data.append(Judge)
Inq = re.findall(findInq,item)
if len(Inq)!=0:
Inq=Inq[0].replace("。","")#去掉句号
data.append(Inq)
else:
data.append(" ")#表留空
Bd = re.findall(findBd,item)[0]
Bd = re.sub('
Bd = re.sub('/'," ",Bd)#去掉/
data.append(Bd.strip())#去掉前后空格
dataList.append(data)#把处理好的一部电影信息放入dataList
print(dataList)
return dataList
if __name__ == "__main__":
url = "https://movie.douban.com/top250?start="
#1、爬取网页
dataList = getData(url)
savepath = ".\\豆瓣电影Top250.xls" 3、保存数据
保存数据到Excel
四步保存法:
创建表
创建子表
写入数据
保存数据
import xlwt
workbook = xlwt.Workbook(encoding="utf-8")#创建workbook对象
worksheet = workbook.add_sheet('sheet1')#创建工作表
worksheet.write(0,0,'hello')#0行0列存入内容hello
workbook.save('student.xls')#保存数据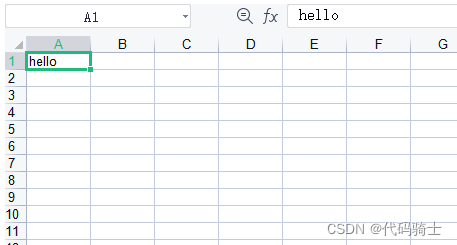
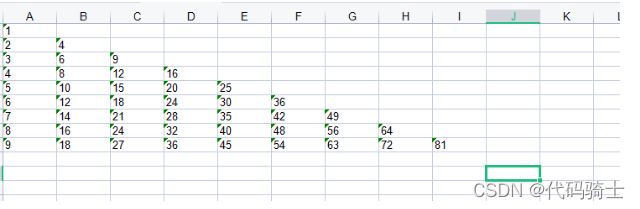
实例:用python在excel中打印九九乘法表:
import xlwt
workbook = xlwt.Workbook(encoding="utf-8")#创建workbook对象
worksheet = workbook.add_sheet('sheet1')#创建工作表
for k in range(1,10):
for i in range(1,10):
if i<=k:
worksheet.write(k-1,i-1,str(i*k))#0行0列存入内容hello
workbook.save('student.xls')#保存数据
完善之前的代码:
import urllib.request as ur
import urllib.error as ue
import urllib.parse as up
from bs4 import BeautifulSoup
import re
import xlwt
#创建正则表达式
#影片链接
findLink=re.compile(r'')#(.*?):.*:任意字符出现多次 ?:前面的元组内容出现仅出现一次
#影片图片
findImagSrc=re.compile(r'(.*)')
#评分
findRating = re.compile(r'')
#评价人数
findJudge = re.compile(r'(\d*)人评价')
#找到概况
findInq = re.compile(r'(.*)')
#相关内容
findBd = re.compile(r'(.*?)
',re.S)
def main():
baseurl = "https://movie.douban.com/top250?start="
datalist = getData(baseurl)
savepath = "douban.xls"
saveData(datalist,savepath)
#得到一个指定的URL内容
def askURL(url):
#模拟请求头
header = {"Remote Address":"140.143.177.206:443","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36"}
#保存网页信息的字符串
html=""
#请求网页信息
req = ur.Request(url,headers=header)
try:
res = ur.urlopen(req)
html=res.read().decode("utf-8")
#print(html)
except ue.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
#爬取网页
def getData(baseurl):
dataList = []#用来存储网页信息
for i in range(0,10):#调用获取页面信息函数10次250条
url = baseurl+str(i*25)#左闭右开
html = askURL(url)#保存获取到的网页源码
#逐一解析
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):#查找比较好的字符串放入列表
#print(item) 测试:查看电影item全部信息
data = [] #保存一部电影的所有信息
item = str(item)
#影片详情链接
Link = re.findall(findLink,item)[0]#re库用来通过正则表达式查找指定字符串,0表示只要第一次找到的
data.append(Link)
ImagSrc = re.findall(findImagSrc,item)[0]
data.append(ImagSrc)
Title = re.findall(findTitle,item)#区分中英文
if len(Title)==2:
ctitle=Title[0]
data.append(ctitle)
otitle = Title[1].replace("/","")#去掉无关符号
data.append(otitle)#添加外国名
else:
data.append(Title[0])
data.append(' ')#表中留空
Rating = re.findall(findRating,item)[0]
data.append(Rating)
Judge = re.findall(findJudge,item)[0]
data.append(Judge)
Inq = re.findall(findInq,item)
if len(Inq)!=0:
Inq=Inq[0].replace("。","")#去掉句号
data.append(Inq)
else:
data.append(" ")#表留空
Bd = re.findall(findBd,item)[0]
Bd = re.sub('
Bd = re.sub('/'," ",Bd)#去掉/
data.append(Bd.strip())#去掉前后空格
dataList.append(data)#把处理好的一部电影信息放入dataList
return dataList
def saveData(datalist,savepath):
print("saving")
book = xlwt.Workbook(encoding="utf-8",style_compression=0)#创建workbook对象
sheet = book.add_sheet('豆瓣电影Top',cell_overwrite_ok=True)#创建工作表
col=("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i])#列名
for i in range(0,250):
print("第%d条"%i)
data = datalist[i]
for j in range(0,8):#数据
sheet.write(i+1,j,data[j]) #保存
book.save(savepath)#保存
if __name__ == "__main__":
main()
print("爬取成功!") 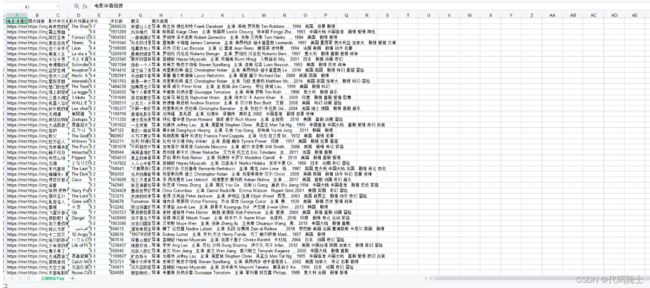
符合预期效果。
4、数据可视化
制作词云:
掩图:

词图:

环境配置:
import jieba#分词
from matplotlib import pyplot as plt#绘图数据可视化
from wordcloud import WordCloud#词云
from PIL import Image#图像处理
import numpy as np#矩阵运算
import pandas as pd
import re示例:
import jieba#分词
from matplotlib import pyplot as plt#绘图数据可视化
from wordcloud import WordCloud#词云
from PIL import Image#图像处理
import numpy as np#矩阵运算
import pandas as pd
import re
data = pd.read_excel('douban.xls')#打开Excel文件
data_cy = data.copy()#不影响原数据所以拷贝一份
#print(data.iloc[0:4,:2])#从x开始到第y行的前x列
#print(data.iloc[[0],[2,3]])#第0行的2、3列
list=[]
for i in range(0,250):
datas = data.iloc[[i],[2]]#获取名字
datas = str(datas).strip()
datas = re.sub(r"影片中文名\n\d*","",datas)
datas = str(datas).strip()#再去掉一次空格
list.append(datas)
#print(list)#得到影片名字的列表
#获取所有文字
text=""
for item in list:
text+=item
#print(text)
#分词
cut = jieba.cut(text)
string = " ".join(cut)
print(string)#1220
img = Image.open("kobe.jpg")
img_=np.array(img)
wc=WordCloud(
mask=img_,
background_color='white',
font_path='msyh.ttc'
)
wc.generate_from_text(string)
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off')
plt.savefig("D:\代码文件夹\VS代码\PythonApplication30\PythonApplication30\wc.jpg")