特征工程概述笔记
特征工程
1.定义
1.1为什么需要特征工程
- 样本数据中的特征有可能会存在缺失值,重复值,异常值等,需要对特征中的相关的噪点数据进行处理
- 处理目的:有一个更纯净的样本集,让模型基于这组数据可以有更好的预测能力…
1.2什么是特征工程
- 特征工程是将原始数据转换为更好的代表预测模型的潜在问题的特征过程,从而提高对未知数据预测的准确性
- 比如:AlphaGo学习的数据中既有棋谱,又有食谱和歌词,一些干扰数据绝对会影响AlphaGo的学习
1.3特征工程的意义
- 直接会影响模型预测的结果
1.4实现特征工程
- 工具:
sklearn sklearn介绍- 是python语言中的机器学习工具,包含了很多知名的机器学习算法的实现,其文档完善,容易上手
- 功能
- 分类模型
- 回归模型
- 聚类模型
- 特征工程
2.特征提取
2.1目的
-
采集到的样本中的特征数据往往很多时候为字符串或者其他类型的数据,电脑只可以识别二进制数值型的数据,如果把字符串给电脑,电脑不能识别【如果不是数值型数据,识别不了】
-
效果演示【将字符串转换为数字】
from sklearn.feature_extraction.text import CountVectorizer vector=CountVectorizer() res=vector.fit_transform(['lift is short,I love python','lift is too long,I hate python']) print(res.toarray()) # [[0 1 1 0 1 1 1 0] # [1 1 1 1 0 1 0 1]] -
结论
- 特征抽取对文本等数据进行特征值化【将数据转为数值型数据】,特征值化是为了让机器更好的理解数据
2.2特征提取的方式
2.2.1字典特征提取
- 作用:对字典数据进行特征值化
from sklearn.feature_extraction import DictVectorizer
fit_transform(X) #X为字典或者包含字典的迭代器,返回值为sparse矩阵
inverse_transform(X) #X为sparse矩阵或者array数组,返回值为转换之前的数据格式
transform(X) #按照原先的标准转换
get_feature_names() #返回类别名称
- 示例代码
from sklearn.feature_extraction import DictVectorizer
alist=[
{"city":'AHui','temp':33},
{'city':'GZ','temp':42},
{'city':'SH','temp':40}
]
d=DictVectorizer() #实例化一个工具类对象
feature=d.fit_transform(alist) #返回一个sparse矩阵(存储的就是特征值化之后的结果)
print(feature)
# (0, 0) 1.0
# (0, 3) 33.0
# (1, 1) 1.0
# (1, 3) 42.0
# (2, 2) 1.0
# (2, 3) 40.0
print(d.get_feature_names())
# ['city=AHui', 'city=GZ', 'city=SH', 'temp']
print(feature.toarray())
# [[ 1. 0. 0. 33.]
# [ 0. 1. 0. 42.]
# [ 0. 0. 1. 40.]]
-
补充,sparse矩阵的理解
- 在
DictVectorizer类的构造方法中设定sparse=False,则返回的就不是sparse矩阵,而是一个数组 - sparse矩阵就是一个变相的数组或者列表,目的是为了节省内存
- 在
-
示例代码
from sklearn.feature_extraction import DictVectorizer
alist=[
{"city":'AHui','temp':33},
{'city':'GZ','temp':42},
{'city':'SH','temp':40}
]
d=DictVectorizer(sparse=False)
#返回一个二维列表
fature=d.fit_transform(alist)
print(d.get_feature_names()) # ['city=AHui', 'city=GZ', 'city=SH', 'temp']
print(feature)
#输出结果:1为是,0为不是
# [[ 1. 0. 0. 33.]
# [ 0. 1. 0. 42.]
# [ 0. 0. 1. 40.]]
2.2.2 文本特征提取
-
作用:对文本数据进行特征值化
from sklearn.feature_extraction.text import CountVectorizer fit_transform(X) #X为文本或者包含文本字符串的可迭代对象,返回sparse矩阵 inverse_transform(X) #X为sparse矩阵或者array数组,返回值为转换之前的数据格式 toarray() #将sparse矩阵转化为数组-
示例代码
from sklearn.feature_extraction.text import CountVectorizer vector=CountVectorizer() res=vector.fit_transform(['lift is is short,I love python','lift is too long,I hate python']) print(res)#sparse矩阵 # (0, 2) 1 # (0, 1) 2 # (0, 6) 1 # (0, 4) 1 # (0, 5) 1 # (1, 2) 1 # (1, 1) 1 # (1, 5) 1 # (1, 7) 1 # (1, 3) 1 # (1, 0) 1 print(vector.get_feature_names()) #['hate', 'is', 'lift', 'long', 'love', 'python', 'short', 'too'] print(res.toarray())#将sparse矩阵转换成数组 # [[0 2 1 0 1 1 1 0] # [1 1 1 1 0 1 0 1]] #注意:单字母不统计(因为单个字母代表不了实际含义),然后每个数字表示的是单词出现的次数
-
-
中文文本特征提取【对有标点符号的中文文本进行特征提取】
from sklearn.feature_extraction.text import CountVectorizer vector=CountVectorizer() res=vector.fit_transform(['人生苦短 我用python','人生满长,不用python']) print(res) # (0, 2) 1 # (0, 3) 1 # (1, 1) 1 # (1, 0) 1 print(vector.get_feature_names()) ['不用python', '人生满长', '人生苦短', '我用python'] print(res.toarray()) # [[0 0 1 1] # [1 1 0 0]] -
中文文本特征提取【对有标点符合且有空格分隔的中文文本进行特征提取】【注意:单个汉字不统计】
from sklearn.feature_extraction.text import CountVectorizer vector=CountVectorizer() res=vector.fit_transform(['人生 苦短, 我 用python','人生 漫长, 不用 python']) print(res) # (0, 2) 1 # (0, 5) 1 # (0, 4) 1 # (1, 2) 1 # (1, 3) 1 # (1, 1) 1 # (1, 0) 1 print(vector.get_feature_names()) # ['python', '不用', '人生', '漫长', '用python', '苦短'] print(res.toarray()) # [[0 0 1 0 1 1] # [1 1 1 1 0 0]] -
目前
CountVectorizer只可以对有标点符号和用分隔符对应的文本进行特征提取,满足不了需求【在自然语言处理中,我们是需要将一段中文文本中相关的词语,成语,形容词…都要进行提取的】
2.2.3jieba分词
-
对中文文章进行分词处理
-
使用
#基本使用:对文章进行分词 import jieba jb = jieba.cut('我是一个好人') content = list(jb) ct = ' '.join(content) print(ct) #返回空格区分的词语import jieba from sklearn.feature_extraction.text import CountVectorizer jb1=jieba.cut('人生苦短,我用python,你觉得我说的对吗?') ct1=" ".join(list(jb1)) print(ct1) # 人生 苦短 , 我用 python , 你 觉得 我 说 的 对 吗 ? jb2=jieba.cut('人生满长,不用python,你说我说的对不对?') ct2=" ".join(list(jb2)) print(ct2) # 人生 满长 , 不用 python , 你 说 我 说 的 对 不 对 ? vector=CountVectorizer() res=vector.fit_transform([ct1,ct2]) print(res) # (0, 2) 1 # (0, 5) 1 # (0, 3) 1 # (0, 0) 1 # (0, 6) 1 # (1, 2) 1 # (1, 0) 1 # (1, 4) 1 # (1, 1) 1 print(vector.get_feature_names()) # ['python', '不用', '人生', '我用', '满长', '苦短', '觉得'] print(res.toarray()) # [[1 0 1 1 0 1 1] # [1 1 1 0 1 0 0]]
2.3onhot编码
-
sparse矩阵中的0和1就是
onehot编码
-
-
为什么需要
onehot编码-
特征抽取主要目的就是对非数值型的数据进行特征值化!如果现在需要对下图中的human和alien进行手动特征值化Alien为4,human为1。则1和4有没有优先级或者权重大小之分呢?
-
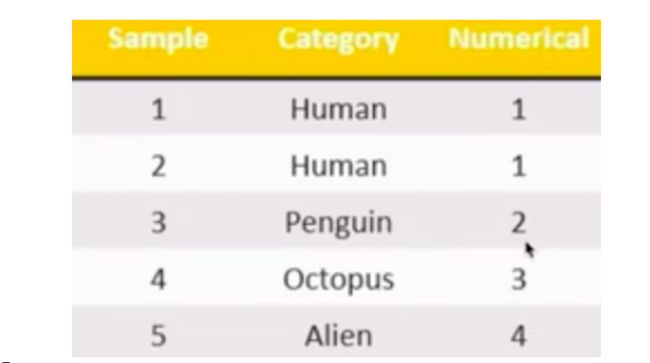
-
就需要用
onehot编码 -
基于
pandas实现onehot编码【pd.get_dummies(df['col']】import pandas as pd df=pd.DataFrame([ ['green','M',20,'class1'], ['red','L',21,"class2"], ['blue','XL',30,'class3'] ]) df.columns=['color','size','weight','class label'] #将color这一列变成one-hot编码 pd.get_dummies(df['color']) # blue green red # 0 0 1 0 # 1 0 0 1 # 2 1 0 0
-
3.特征值的预处理
-
对数值型数据进行处理
-
预处理就是用来实现无量钢化的方式
-
无量钢化:
- 在机器学习算法实践中,我们往往有着将不同规格的数据转换到同一规格,或不同分布的数据转换到某个特定分布的需求,这种需求统称为将数据"无量纲化"
- 例如:
- 梯度和矩阵为核心的算法中;逻辑回归,支持向量机,神经网络,无量钢化可以加快求解速度;
- 在距离类模型,譬如K近邻,K-Means聚类中,无量钢化可以帮我们提升模型精度,避免某一个取值范围特别大的特征对距离计算造成的影响(一个特例是决策树和树的集成算法,对决策树不需要无量钢化,决策树可以把任意数据都处理的很好)
-
含义:特征抽取后我们就可以获取对应的数值型的样本数据,然后进行数据处理
-
概念:通过特定的统计方式(数学方法),将算法转换成算法要求的数据
-
方式
- 归一化
- 标准化
-
案例分析
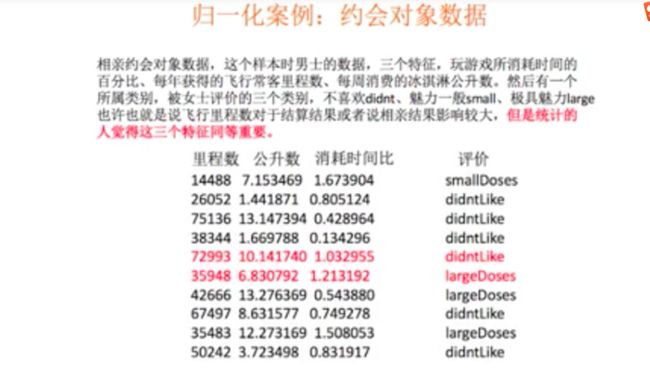
- 如果认为每一个特征具有同等大小的权重都同等重要,则必须要对其进行归一化处理
- 可以使用KNN算法对特征影响进行说明。
3.1归一化实现

- 归一化后的数据服从正态分布
from sklearn.preprocessing import MinMaxScaler
参数:feature_range表示缩放范围,通常使用(0,1)
作用:使得某一个特征对最终结果不会造成很大的影响
from sklearn.preprocessing import MinMaxScaler
mm=MinMaxScaler(feature_range=(0,1)) #每个特征缩放的范围
data=[[90,2,10,40],[60,5,15,45],[73,3,13,45]]
data=mm.fit_transform(data)#data需要归一化的特征
print(data)
# [[1. 0. 0. 0. ]
# [0. 1. 1. 1. ]
# [0.43333333 0.33333333 0.6 1. ]]
-
问题:如果数据中存在的异常值比较多,会有什么影响?
- 结合着归一化计算的公式,异常值对原始特征中的最大值和最小值的影响很大,因此也会影响对归一化的值,这个也是归一化的一个弊端,无法很多好的处理异常值
-
归一化总结:
- 在特定场景下最大值和最小值是变化的,另外最大最小值很容易受到异常值的影响,所以这种归一化的方式具有一定的局限性。因此引出了一种更好的方式叫做:标准化!!!
3.2标准化处理
-
当数据按均值中心化后,再按标准差缩放,数据就会服从为均值为0,方差为1的正态分布(即标准正态分布),而这个过程,就叫做数据标准化(Standardization,又称Z-score normalization),公式如下
-

-
从公式可以看出,异常值对均值和标准差的影响不大
-
API
-
处理后,每列所有的数据都聚集在均值为0,标准差为1范围附近
-
标准化API:
from sklearn.preprocessing import StandardScaler fit_transform(X) #对X标准化 mean_#均值 var_ #方差 -
示例
from sklearn.preprocessing import StandardScaler ss=StandardScaler() data=[[90,2,10,40],[60,5,15,45],[73,3,13,45]] ss.fit_transform(data) # array([[ 1.27540458, -1.06904497, -1.29777137, -1.41421356], # [-1.16685951, 1.33630621, 1.13554995, 0.70710678], # [-0.10854507, -0.26726124, 0.16222142, 0.70710678]]) ss.mean_ #array([74.33333333, 3.33333333, 12.66666667, 43.33333333]) ss.var_ #array([150.88888889, 1.55555556, 4.22222222, 5.55555556])
-
3.3 归一化和标准化总结
- 归一化,如果出现了异常值则会影响特征的最大值最小值,那么最终结果会受到比较大影响
- 标准化,如果出现异常点,由于具有一定的数据量,少量的异常点对于平均值的影响并不大,从而标准差改变比较少
3.4StandardScaler和MinMaxSclaer选哪个?
- 大多数机器学习算法中,会选择
StandardSclaer来进行特征缩放,因为MinMaxSclaer对异常值非常敏感。在CPA,聚类,逻辑回归,支持向量机,神经网络这些算法中,StandardSclaer往往是最好的选择。 MinMaxScaler在不涉及距离度量,梯度,协方差计算以及数据需要被压缩到特定区间时,使用广泛,比如数字图像处理中量化像素强度时,都会使用MinMaxScaler将数据压缩于[0,1]区间之中- 建议先用
StandardScaler,效果不好换MinMaxScaler
4.特征选择
4.1定义
-
从特征中选择出有意义对模型有帮助的特征作为最终的机器学习输入的数据
-
注意
- 在做特征选择之前,有三件非常重要的事:
- 跟数据提供者联系
- 跟数据提供者沟通
- 跟数据提供者开会
- 一定要抓住给你提供数据的人,尤其是理解业务和数据含义的人,跟他们聊一段时间,技术能够让模型起飞,前提是你和业务员一样理解数据。所以特征选择是第一步,根据目标,用业务常识来选择特征
- 在做特征选择之前,有三件非常重要的事:
4.2特征选择的原因
- 冗余:部分特征的相关度高,容易消耗计算机的性能【数据相似度高】【例如:房价预测数据中有楼层和高度,这两个特征相关度高】
- 噪点:部分特征对预测结果有偏执影响【预测无关的数据】【例如:房价预测,数据中有购买房子的人的身高,跟预测无关的数据】
4.3特征选择的实现
-
人为对不相关的特征进行主关舍弃
-
在真正的数据应用领域,比如:金融,医疗,电商,我们得数据特征非常多,这样明显,如果遇见极端的情况,我们无法依赖对业务的理解来选则特征怎么办?
- 在已有特征和对应预测结果的基础上,使用相关的工具过滤一些无用或权重较低的特征
- 工具
- Filter(过滤式)
- Embedded(嵌入式):决策树模型会自己选择出对其重要的特征
- PCA降维
- 工具
- 在已有特征和对应预测结果的基础上,使用相关的工具过滤一些无用或权重较低的特征
4.4特征选择工具
4.4.1Filter过滤式(方差过滤):
-
原理:这是通过特征本身的方差来筛选特征的类,比如:一个特征本身的方差很小,就表示样本在这个特征上基本没有差异,可能特征中的大多数值都一样,甚至整个特征的取值都相同,那这个特征对于样本区分没有作用,所以无论接下来特征工程要做什么,都要优先消除方差为0或方差较低的特征
-
API
from sklearn.feature_selection import VarianceThreshold VarianceThreshold(threshold=x) #threshold为方差的值,删除所有方差低于x的特征,默认为0表示保留所有方差为非0的特征 fit_transform(X) #X为特征 -
示例
from sklearn.feature_selection import VarianceThreshold #threshold方差的值,threshold=1,删除所有方差低于1的特征,默认为0,宝石保留所有方差为非0的特征 v=VarianceThreshold(threshold=1) v.fit_transform([[0,2,4,3],[0,3,7,3],[0,9,6,3]])#X为特征【数据为特征】
-
-
如果将方差为0或方差极低的特征取出后,剩余特征还有很多且模型的效果没有显著提升,则可以用方差将特征选择【一步到位】。留下一半的特征,那可以设定一个让特征总数减半的方差阈值,即找到特征方差的中位数,将中位数作为参数threshold的值即可
from sklearn.feature_selection import VarianceThreshold #threshold方差的值,threshold=1,删除所有方差低于1的特征,默认为0,宝石保留所有方差为非0的特征 v=VarianceThreshold(threshold=np.median(X.var().values)) v.fit_transform(X)## X为样本数据中的特征列 -
方差过滤对模型的影响
-
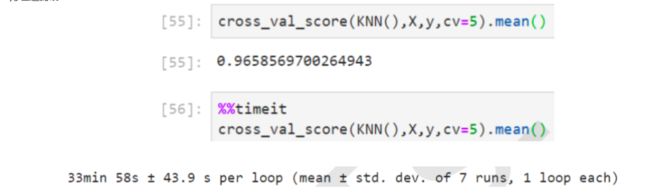
例如:KNN在方差过滤前和方差过滤后运行的效果和运行时间的对比。KNN是K近邻算法中的分类算法,其原理非常简单,是利用每个样本到其他样本点的距离来判断每个样本点的相似度,然后对样本进行分类。KNN必须遍历每个特征和每个样本,因而特征越多,KNN的计算也就会越缓慢,以下是代码运行时间对比。
-
方差过滤前
-
方差过滤后
-
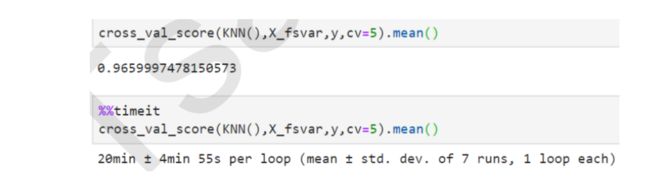
-
可以看出,对于KNN,过滤后的效果十分明显:准确率稍有提升,但平均运行时间减少了10分钟,特征选择过后算 法的效率上升了1/3.
-
注意:方差过滤主要服务对象是:需要遍历特征的算法模型,而过滤的主要目的是在维持算法表现的前提下,帮助算法降低计算成本
-
4.4.2PCA降维(主成分分析)
-
定义
- PCA降维(主成分分析):是一种分析,简化数据集的技术
-
降维的维度值就是特征的种类
-
思想:如何跟好的对一个立体的物体用二维表示
-

-
当然,第四张二维图片可以比较好的标识一个立体三维的水壶。但是也要清楚,用一个低纬度去表示高纬度的物体时,一定会造成一些信息的差异。可以让低纬度也可以能正确的表示高纬度的事物,或者信息差异最小。
-
目的:特征数量达到上百,上千的时候,考虑数据的优化。使数据维度压缩,尽可能降低源数据的维度(复杂度),损失少量信息。
-
作用:可以削减回归分析或者聚类分析中特征的数量
-
PCA大致原理
-
-
红色为原始的样本特征,为二维的特征,如果降为一维,则可以将5个红色的原始特征,映射到一维的线段上就变成了4个特征。
-
PCA语法
from sklearn.decomposition import PCA pca=PCA(n_components=None) # n_components可以为小数(保留特征的百分比),整数(减少到的特征数量) pca.fit_transform(X) -
示例
from sklearn.decomposition import PCA #将数据分解为较低维度的空间 #n_components可以为小数(保留特征的百分比),整数(减少到的特征数量)【保留几个特征值】 pca=PCA(n_components=2) pca.fit_transform([[0,2,4,3],[0,3,7,3],[0,9,6,3]])
5.特征筛选
5.1概述
概述:IV和WOE通常是用在对模型的特征筛选中,在模型刚建立时,变量往往很多,IV和WOE可以帮助我们衡量什么变量应该进入模型什么变量应该舍弃。用IV和WOE值来进行判断,值越大表示该特征的预测能力越强,则该特征应该加入到模型的训练中
5.2应用
- 变量筛选。我们需要选取比较重要的变量加入模型,预测强度可以作为我们判断变量是否重要的依据
- 指导变量离散化,在建模过程中,时常需要对连续变量进行离散化处理,如将年龄里进行分段。但是变量不同的离散化结果会对模型产生不同影响,因此,可以根据指标所反映的预测强度,调整变量离散化结果。(对一些取值很多的分类变量,在需要时也可以对其进行再分组,实现降维)
5.3 计算方法
5.3.1WOE
WOE(Weight Of Evidence)用来衡量特征的预测强度,要是用WOE,首先要对特征进行分箱(分组:将一种特征的组成元素进行分组),分享之后,对于其中第i组的WOE值公式如下:
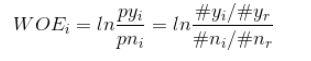
-
py_i表示该组中的正例占负例样本的比例,pn_i表示整体的正例占负例样本的比例 -
例子
-
假设现在某个公司举行一个活动,在举行这个活动之前,先在小范围的客户中进行了一次试点,收集了一些用户对这次活动的一些响应,然后希望通过这些数据,去构造一个模型,预测如果举行这次的活动,是否能够得到很好的响应或者得到客户的响应概率之类。
-
假设我们已经从公司客户列表中随机抽取了100000个客户进行了营销活动测试,收集了这些客户的响应结果,作为我们的建模数据集,其中响应的客户有10000个。另外假设我们也已经提取到了这些客户的一些变量,作为我们模型的候选变量集,这些变量包括以下这些:
- 最近一个月是否有购买;
- 最近一次购买金额;
-
假设,我们已经对这些变量进行了离散化,统计的结果如下面几张表所示。
-

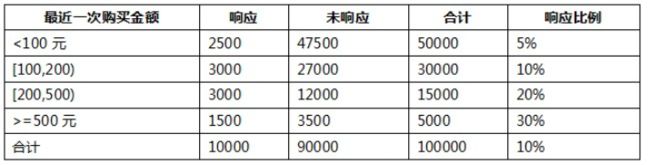
- 我们以其中的一个变量“最近一次购买金额”变量为例:
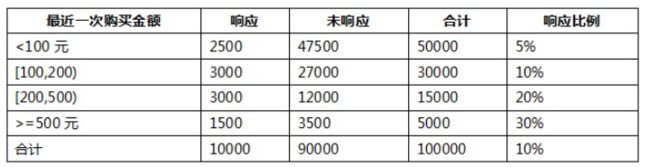

- 我们把这个变量离散化为了4个分段:<100元,[100,200),[200,500),>=500元。首先,根据WOE计算公式,这四个分段的WOE分别为:
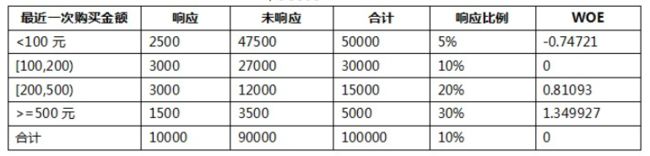
-
根据结果,对结果的正负值分析,根据ln函数的特性,当这个组中响应样本的比例比总体的响应比例小时为负数,相等时为0,大于时为整数
-
把这个变量的所有分组的
WOE值的绝对值加起来,这个可以在一定程度上表示这个变量的预测能力,但是一般不会这么做,因为对于分组中的样本数量相差悬殊的场景,WOE值可能不能很好的表示出这个变量的预测能力,一边会用到另一个值:IV值。IV在计算的时候,比WOE值多考虑了一层该变量下该分组占该变量下所有样本的比例
5.3.1IV
- IV值的计算公式在WOE的基础上多乘了一个(
py_i-pn_i),py_i表示该组中的正例占负例样本的比例,pn_i表示整体的正例占负例样本的比例
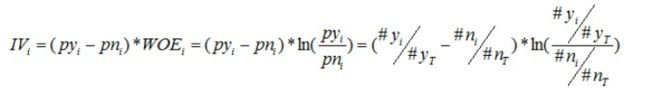
- 把上面的IV1,IV2,IV3,IV4加起来,就是变量的IV值,然后把所有的变量IV值都算出来,就可以根据IV值的大小来看出变量的预测能力
5.4分箱
-
数据分箱(也称为离散分箱或分段)是一种数据预处理技术,用于减少次要观察误差的影响,是一种将多个连续值分组为较少数量的"分箱"的方法,就是将连续型特征进行离散化
-
分箱的作用和意义
- 离散特征的增加和减少都很容易,易于模型的快速迭代,提升计算速度
- 特征离散化后,模型会更稳定,比如对年龄离散化,20-30为一个区间,不会因为一个用户年龄增长了一岁就变成了一个完全不同的人
- 特征离散化后,起到了简化模型的作用,可以适当降低模型过拟合的风险
-
注意:对特征进行分箱后,需要对分箱后的每组(箱)进行woe编码,然后才能放进模型训练
-
例如我们有一组关于人年龄的数据,如下图所示
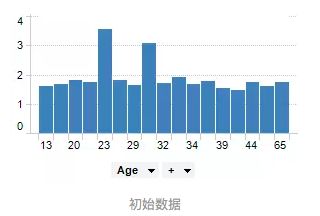
- 将他们的年龄分组到更少的间隔中,对连续性特征进行离散化
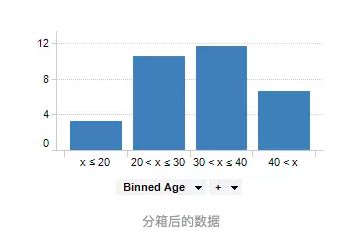
-
注意
- 分箱的数据不一定必须是数字,可以是任意类型的值,如"狗","猫"等,分箱也用于图像处理,通过将相邻像素组合成单个像素,它可用于减少数据量
5.4.1 pandas实现数据分箱
-
pd.cut()import numpy as np import pandas as pd from pandas import Series,DataFrame score_list=np.random.randint(30,100,size=20) # [92 73 73 49 62 35 56 90 81 84 84 89 96 94 54 51 91 43 54 98] #设置分箱:方式一 bins=[0,59,70,80,100] score_cat=pd.cut(score_list,bins)#指定分箱数据的范围 print(pd.value_counts(score_cat)) # Categories (4, interval[int64]): [(0, 59] < (59, 70] < (70, 80] < (80, 100]] # (0, 59] 9 # (80, 100] 4 # (70, 80] 4 # (59, 70] 3 # dtype: int64 #设置分箱:方式2 bins = 3#指定分箱数据的范围的个数 score_cat = pd.cut(score_list, bins,labels=range(3))#labels设置分箱的每一个范围标识 print(score_cat) print(pd.value_counts(score_cat)) # [0, 2, 0, 1, 1, ..., 0, 0, 2, 2, 0] # Length: 20 # Categories (3, int64): [0 < 1 < 2] # 0 9 # 2 7 # 1 4 # dtype: int64import sklearn.datasets as ds bc=ds.load_breast_cancer() feature=bc.data target=bc.target #查看第一列数据范围,判定是连续数据 feature[:,1].min(),feature[:,1].max()#(9.71, 39.28) #对其进行分箱处理,将其离散化 fea_bins=pd.cut(feature[:,1],bins=5,labels=range(5)) fea_bins.value_counts() #0 113 # 1 299 # 2 129 # 3 25 # 4 3 # dtype: int64 #对分箱后的特征进行woe编码 gi=pd.crosstab(fea_bins,target) gb=pd.Series(data=target).value_counts() bgi=(gi[1]/gi[0])/(gb[1]/gb[0]) # row_0 # 0 7.794118 # 1 1.164157 # 2 0.257330 # 3 0.755793 # 4 0.296919 # dtype: float64 woe=np.log(bgi) # row_0 # 0 2.053369 # 1 0.151997 # 2 -1.357398 # 3 -0.279987 # 4 -1.214297 # dtype: float64 #进行映射操作 dict=woe.to_dict() woe_bins=fea_bins.map(dict) woe_bins.tolist()
6.样本类别分布不均衡处理
6.1什么是样本类别分布不均衡?
- 在一组样本种不同类别的样本量差异非常大,比如拥有1000条数据样本的数据集,有一类样本分类只占10条,此时属于非常严重的数据样本分布不均衡
6.2 样本类别分布不均衡导致的危害
- 样本类别不均衡将导致样本量少的分类所包含的特征过少,并很难提取规律;即使得到分类模型,也容易产生过度依赖与有限的数据样本而导致过拟合问题,当模型应用到新的数据上时,模型的准确性会很差
6.3解决方法
- 通过过抽样和欠抽样解决样本不均衡
6.3.1 过抽样(over-sampling)
-
from imblearn.over_sampling import SMOTE -
通过增加分类中少数类样本的数量来实现样本均衡,比较好的方法有
SMOTE算法 -
SMOTE算法原理smote算法的思想是合成新的少数类样本,合成的策略是对每个少数类样本a,从他的最近邻中随机选一个样本b,然后再a,b之间连线上随机选一点作为新合成的少数类样本
-
示例
import pandas as pd import numpy as np from imblearn.over_sampling import SMOTE #数据源生成 x=np.random.randint(0,100,size=(100,3)) y=pd.Series(data=np.random.randint(0,1,size=(95,))) y=y.append(pd.Series(data=[1,1,1,1,1]),ignore_index=False).values y=y.reshape((-1,1)) all_data_up=np.concatenate((x,y),axis=1) np.random.shuffle(all_data_up) df=pd.DataFrame(all_data_up) #提取样本数据 feature=df[[0,1,2]] target=df[3] target.value_counts() # 0 95 # 1 5 # Name: 3, dtype: int64 target.shape #(190,) s=SMOTE(k_neighbors=3) #实例化算法对象 s_feature,s_target=s.fit_resample(feature,target)#合成新的样本数据 s_target.shape #(190,) s_target.value_counts() #1 95 # 0 95 # Name: 3, dtype: int64
6.3.2欠抽样(under-sampling)
-
欠抽样:通过减少分类中多数类样本的数量来实现样本均衡
-
from imblearn.under_sampling import RandomUnderSamplerimport pandas as pd import numpy as np from imblearn.under_sampling import RandomUnderSampler #数据源生成 x=np.random.randint(0,100,size=(100,3)) y=pd.Series(data=np.random.randint(0,1,size=(95,))) y=y.append(pd.Series(data=[1,1,1,1,1]),ignore_index=False).values y=y.reshape((-1,1)) all_data_up=np.concatenate((x,y),axis=1) np.random.shuffle(all_data_up) df=pd.DataFrame(all_data_up) #提取样本数据 feature=df[[0,1,2]] target=df[3] target.value_counts() # 0 95 # 1 5 # Name: 3, dtype: int64 r=RandomUnderSampler() r_feature,r_target=r.fit_resample(feature,target) r_target.shape #(10,) r_target.value_counts() # 1 5 # 0 5 # Name: 3, dtype: int64 r_feature.shape #(10, 3)
https://www.luffycity.com/