Spark SQL 底层实现原理
1. Spark SQL架构设计
直接使用SQL的方式实现大数据的开发,它同时支持DSL以及SQL的语法风格,目前在spark的整个架构设计当中,所有的spark模块,例如SQL,SparkML,sparkGrahpx以及Structed Streaming等都是基于 Catalyst Optimization & Tungsten Execution模块之上运行,如下图所示就显示了spark的整体架构模块设计

2. SparkSQL执行过程
- Parser: 将sql语句利用Antlr4进行词法和语法的解析
- Analyzer:主要利用 Catalog 信息将 Unresolved Logical Plan 解析成 Analyzed logical plan;
- Optimizer:利用一些 Rule (规则)将 Analyzed logical plan 解析成 Optimized Logical Plan;
- Planner:前面的 logical plan 不能被 Spark 执行,而这个过程是把 logical plan 转换成多个 physical plans,然后利用代价模型(cost model)选择最佳的 physical plan;
- Code Generation:这个过程会把 SQL 查询生成 Java 字 节码。

3. SQL举例
例如执行以下SQL语句:
select temp1.class,sum(temp1.degree),avg(temp1.degree) from (SELECT students.sno AS ssno,students.sname,students.ssex,students.sbirthday,students.class, scores.sno,scores.degree,scores.cno FROM students LEFT JOIN scores ON students.sno = scores.sno ) temp1 group by temp1.class代码实现过程如下:
package com.kkb.sparksql
import java.util.Properties
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
//todo:利用sparksql加载mysql表中的数据
object DataFromMysqlPlan {
def main(args: Array[String]): Unit = {
//1、创建SparkConf对象
val sparkConf: SparkConf = new SparkConf().setAppName("DataFromMysql").setMaster("local[2]")
//sparkConf.set("spark.sql.codegen.wholeStage","true")
//2、创建SparkSession对象
val spark: SparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
spark.sparkContext.setLogLevel("WARN")
//3、读取mysql表的数据
//3.1 指定mysql连接地址
val url="jdbc:mysql://localhost:3306/mydb?characterEncoding=UTF-8"
//3.2 指定要加载的表名
val student="students"
val score="scores"
// 3.3 配置连接数据库的相关属性
val properties = new Properties()
//用户名
properties.setProperty("user","root")
//密码
properties.setProperty("password","123456")
val studentFrame: DataFrame = spark.read.jdbc(url,student,properties)
val scoreFrame: DataFrame = spark.read.jdbc(url,score,properties)
//把dataFrame注册成表
studentFrame.createTempView("students")
scoreFrame.createOrReplaceTempView("scores")
//spark.sql("SELECT temp1.class,SUM(temp1.degree),AVG(temp1.degree) FROM (SELECT students.sno AS ssno,students.sname,students.ssex,students.sbirthday,students.class, scores.sno,scores.degree,scores.cno FROM students LEFT JOIN scores ON students.sno = scores.sno ) temp1 GROUP BY temp1.class; ").show()
val resultFrame: DataFrame = spark.sql("SELECT temp1.class,SUM(temp1.degree),AVG(temp1.degree) FROM (SELECT students.sno AS ssno,students.sname,students.ssex,students.sbirthday,students.class, scores.sno,scores.degree,scores.cno FROM students LEFT JOIN scores ON students.sno = scores.sno WHERE degree > 60 AND sbirthday > '1973-01-01 00:00:00' ) temp1 GROUP BY temp1.class")
resultFrame.explain(true)
resultFrame.show()
spark.stop()
}
}
4. Catalyst执行过程
从上面的查询计划我们可以看得出来,我们编写的sql语句,经过多次转换,最终进行编译成为字节码文件进行执行,(注意,图是从下往上看的)其中包括以下几个重要步骤
- sql解析阶段 parse
- 生成逻辑计划 Analyzer
- sql语句调优阶段 Optimizer
- 生成物理查询计划 planner
4.1 sql解析阶段Parser
我们常见的大数据 SQL 解析都用到了Antlr,包括 Hive、Cassandra、Phoenix、Pig 以及 presto 等。能够读取、处理、执行和翻译结构化的文本或二进制文件,是当前 Java 语言中使用最为广泛的语法生成器工具。
目前最新版本的 Spark 使用的是antlr4,通过这个对 SQL 进行词法分析并构建语法树。我们可以通过github去查看spark的源码
如果需要重构sparkSQL的语法,对SqlBase.g4进行语法解析,生成相关的java类,包含
- 词法解析器SqlBaseLexer.java
- 语法解析器SqlBaseParser.java。

最终通过Lexer以及parse解析之后,生成语法树,生成语法树之后,使用AstBuilder将语法树转换成为LogicalPlan,这个LogicalPlan也被称为Unresolved LogicalPlan。
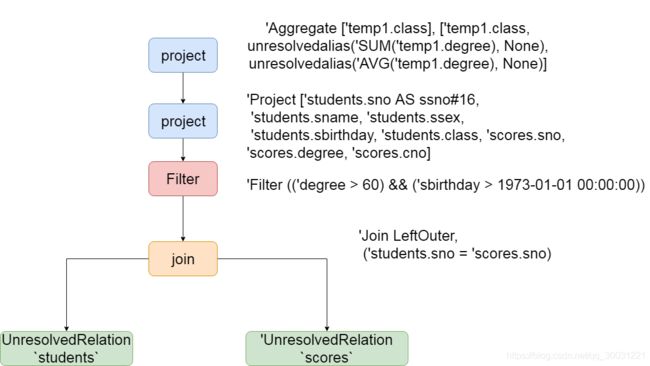
解析之后的逻辑计划如下,
== Parsed Logical Plan ==
'Aggregate ['temp1.class], ['temp1.class, unresolvedalias('SUM('temp1.degree), None), unresolvedalias('AVG('temp1.degree), None)]
+- 'SubqueryAlias temp1
+- 'Project ['students.sno AS ssno#16, 'students.sname, 'students.ssex, 'students.sbirthday, 'students.class, 'scores.sno, 'scores.degree, 'scores.cno]
+- 'Filter (('degree > 60) && ('sbirthday > 1973-01-01 00:00:00))
+- 'Join LeftOuter, ('students.sno = 'scores.sno)
:- 'UnresolvedRelation `students`
+- 'UnresolvedRelation `scores`

从上图可以看得到,两个表被join之后生成了UnresolvedRelation,选择的列以及聚合的字段都有了,sql解析的第一个阶段就已经完成,接着准备进入到第二个阶段
4.2 绑定逻辑计划Analyzer
在sql解析parse阶段,生成了很多未解析出来的有些关键字,这些都是属于 Unresolved LogicalPlan解析的部分。 Unresolved LogicalPlan仅仅是一种数据结构,不包含任何数据信息,例如不知道数据源,数据类型,不同的列来自哪张表等等。。
Analyzer 阶段会使用事先定义好的 Rule 以及 SessionCatalog 等信息对 Unresolved LogicalPlan 进行 transform。SessionCatalog 主要用于各种函数资源信息和元数据信息(数据库、数据表、数据视图、数据分区与函数等)的统一管理。而Rule 是定义在 Analyzer 里面的,具体的类的路径如下
org.apache.spark.sql.catalyst.analysis.Analyzer
具体的rule规则定义如下:
lazy val batches: Seq[Batch] = Seq(
Batch("Hints", fixedPoint,
new ResolveHints.ResolveBroadcastHints(conf),
ResolveHints.RemoveAllHints),
Batch("Simple Sanity Check", Once,
LookupFunctions),
Batch("Substitution", fixedPoint,
CTESubstitution,
WindowsSubstitution,
EliminateUnions,
new SubstituteUnresolvedOrdinals(conf)),
多个性质类似的 Rule 组成一个 Batch,而多个 Batch 构成一个 batches。这些 batches 会由 RuleExecutor 执行,先按一个一个 Batch 顺序执行,然后对 Batch 里面的每个 Rule 顺序执行。每个 Batch 会执行一次(Once)或多次(FixedPoint,由 spark.sql.optimizer.maxIterations 参数决定),执行过程如下:

-
所以上面的 SQL 经过这个阶段生成的 Analyzed Logical Plan 如下:
== Analyzed Logical Plan ==
class: string, sum(degree): decimal(20,1), avg(degree): decimal(14,5)
Aggregate [class#4], [class#4, sum(degree#12) AS sum(degree)#27, avg(degree#12) AS avg(degree)#28]
+- SubqueryAlias temp1
+- Project [sno#0 AS ssno#16, sname#1, ssex#2, sbirthday#3, class#4, sno#10, degree#12, cno#11]
+- Filter ((cast(degree#12 as decimal(10,1)) > cast(cast(60 as decimal(2,0)) as decimal(10,1))) && (cast(sbirthday#3 as string) > 1973-01-01 00:00:00))
+- Join LeftOuter, (sno#0 = sno#10)
:- SubqueryAlias students
: +- Relation[sno#0,sname#1,ssex#2,sbirthday#3,class#4] JDBCRelation(students) [numPartitions=1]
+- SubqueryAlias scores
+- Relation[sno#10,cno#11,degree#12] JDBCRelation(scores) [numPartitions=1]
从上面的解析过程来看,students和scores表已经被解析成为了具体的字段,其中还有聚合函数并且最终返回的四个字段的类型也已经确定了,而且也已经知道了数据来源是JDBCRelation(students)表和 JDBCRelation(scores)表。
总结来看Analyzed Logical Plan主要就是干了一些这些事情
1、确定最终返回字段名称以及返回类型:
2、确定聚合函数
3、确定表当中获取的查询字段
4、确定过滤条件
5、确定join方式
6、确定表当中的数据来源以及分区个数
4.3 逻辑优化阶段Optimizer
这个阶段的优化器主要是基于规则的(Rule-based Optimizer,简称 RBO),而绝大部分的规则都是启发式规则,也就是基于直观或经验而得出的规则
与前文介绍绑定逻辑计划阶段类似,这个阶段所有的规则也是实现 Rule 抽象类,多个规则组成一个 Batch,多个 Batch 组成一个 batches,同样也是在 RuleExecutor 中进行执行这里按照 Rule 执行顺序一一进行说明。
4.3.1 谓词下推
谓词下推在 SparkQL 是由 PushDownPredicate 实现的,这个过程主要将过滤条件尽可能地下推到底层,最好是数据源。
如图谓词下推将 Filter 算子直接下推到 Join 之前了,也就是在扫描 student表的时候使用条件过滤条件过滤出满足条件的数据;同时在扫描 t2 表的时候会先使用 isnotnull(id#8) && (id#8 > 50000) 过滤条件过滤出满足条件的数据。经过这样的操作,可以大大减少 Join 算子处理的数据量,从而加快计算速度
4.3.2 列裁剪
列裁剪在 Spark SQL 是由 ColumnPruning 实现的。利用列裁剪可以把那些查询不需要的字段过滤掉,使得扫描的数据量减少。
经过列裁剪后,students 表只需要查询 sno和 class 两个字段;scores 表只需要查询 sno,degree 字段。这样减少了数据的传输,而且如果底层的文件格式为列存(比如 Parquet),可以大大提高数据的扫描速度的。
4.3.3 常量替换
常量替换在 Spark SQL 是由 ConstantPropagation 实现的。也就是将变量替换成常量,
SELECT * FROM table WHERE i = 5 AND j = i + 3 可以转换成 SELECT * FROM table WHERE i = 5 AND j = 8。
4.3.4 常量累加
-
常量累加在 Spark SQL 是由
ConstantFolding实现的。这个和常量替换类似,也是在这个阶段把一些常量表达式事先计算好。 -
所以经过上面四个步骤的优化之后,得到的优化之后的逻辑计划为
== Optimized Logical Plan ==
Aggregate [class#4], [class#4, sum(degree#12) AS sum(degree)#27, cast((avg(UnscaledValue(degree#12)) / 10.0) as decimal(14,5)) AS avg(degree)#28]
+- Project [class#4, degree#12]
+- Join Inner, (sno#0 = sno#10)
:- Project [sno#0, class#4]
: +- Filter ((isnotnull(sbirthday#3) && (cast(sbirthday#3 as string) > 1973-01-01 00:00:00)) && isnotnull(sno#0))
: +- Relation[sno#0,sname#1,ssex#2,sbirthday#3,class#4] JDBCRelation(students) [numPartitions=1]
+- Project [sno#10, degree#12]
+- Filter ((isnotnull(degree#12) && (degree#12 > 60.0)) && isnotnull(sno#10))
+- Relation[sno#10,cno#11,degree#12] JDBCRelation(scores) [numPartitions=1]
- 到此为止,优化逻辑阶段基本完成,另外更多的其他优化,参见spark的Optimizer.scala源码

4.4 生成可执行的物理计划阶段Physical Plan
一个逻辑计划(Logical Plan)经过一系列的策略处理之后,得到多个物理计划(Physical Plans),物理计划在 Spark 是由 SparkPlan 实现的。多个物理计划再经过代价模型(Cost Model)得到选择后的物理计划(Selected Physical Plan),整个过程如下所示: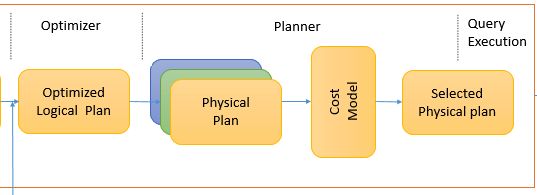
Cost Model 对应的就是基于代价的优化(Cost-based Optimizations,CBO,主要由华为的大佬们实现的,详见 SPARK-16026 ),核心思想是计算每个物理计划的代价,然后得到最优的物理计划。但是在目前最新版的 Spark 2.4.3,这一部分并没有实现,直接返回多个物理计划列表的第一个作为最优的物理计划
== Physical Plan ==
*(6) HashAggregate(keys=[class#4], functions=[sum(degree#12), avg(UnscaledValue(degree#12))], output=[class#4, sum(degree)#27, avg(degree)#28])
+- Exchange hashpartitioning(class#4, 200)
+- *(5) HashAggregate(keys=[class#4], functions=[partial_sum(degree#12), partial_avg(UnscaledValue(degree#12))], output=[class#4, sum#32, sum#33, count#34L])
+- *(5) Project [class#4, degree#12]
+- *(5) SortMergeJoin [sno#0], [sno#10], Inner
:- *(2) Sort [sno#0 ASC NULLS FIRST], false, 0
: +- Exchange hashpartitioning(sno#0, 200)
: +- *(1) Project [sno#0, class#4]
: +- *(1) Filter (cast(sbirthday#3 as string) > 1973-01-01 00:00:00)
: +- *(1) Scan JDBCRelation(students) [numPartitions=1] [sno#0,class#4,sbirthday#3] PushedFilters: [*IsNotNull(sbirthday), *IsNotNull(sno)], ReadSchema: struct
+- *(4) Sort [sno#10 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(sno#10, 200)
+- *(3) Scan JDBCRelation(scores) [numPartitions=1] [sno#10,degree#12] PushedFilters: [*IsNotNull(degree), *GreaterThan(degree,60.0), *IsNotNull(sno)], ReadSchema: struct
- 从上面的结果可以看出,物理计划阶段已经知道数据源是从 JDBC里面读取了,也知道文件的路径,数据类型等。而且在读取文件的时候,直接将过滤条件(PushedFilters)加进去了同时,这个 Join 变成了 SortMergeJoin,

4.5 代码生成阶段
从以上多个过程执行完成之后,最终我们得到的物理执行计划,这个物理执行计划标明了整个的代码执行过程当中
- 执行过程
- 数据字段以及字段类型,
- 数据源的位置
然得到了物理执行计划,但是这个物理执行计划想要被执行,最终还是得要生成完整的代码,底层还是基于sparkRDD去进行处理的
4.5.1 生成代码与sql解析引擎的区别
- 在sparkSQL当中,通过生成代码,来实现sql语句的最终生成,说白了最后底层执行的还是代码然而在spark2.0版本之前使用的都是基于Volcano Iterator Model(参见 《Volcano-An Extensible and Parallel Query Evaluation System》)
- 当今绝大多数数据库系统处理 SQL 在底层都是基于这个模型的。这个模型的执行可以概括为:首先数据库引擎会将 SQL 翻译成一系列的关系代数算子或表达式,然后依赖这些关系代数算子逐条处理输入数据并产生结果。每个算子在底层都实现同样的接口,比如都实现了 next() 方法,然后最顶层的算子 next() 调用子算子的 next(),子算子的 next() 在调用孙算子的 next(),直到最底层的 next(),具体过程如下图表示:

- Volcano Iterator Model 的优点是抽象起来很简单,很容易实现,而且可以通过任意组合算子来表达复杂的查询。但是缺点也很明显,存在大量的虚函数调用,会引起 CPU 的中断,最终影响了执行效率。databricks的官方博客对比过使用 Volcano Iterator Model 和手写代码的执行效率,结果发现手写的代码执行效率要高出十倍!所以总结起来就是将sql解析成为代码,比sql引擎直接解析sql语句效率要快,所以spark2.0最终选择使用代码生成的方式来执行sql语句
4.5.2 Tungsten 代码生成分为三部分:
- 表达式代码生成(expression codegen)
- 全阶段代码生成(Whole-stage Code Generation)
- 加速序列化和反序列化(speed up serialization/deserialization)
表达式代码生成
这个其实在 Spark 1.x 就有了。表达式代码生成的基类是 org.apache.spark.sql.catalyst.expressions.codegen.CodeGenerator,其下有七个子类:

我们前文的 SQL 生成的逻辑计划中的 (isnotnull(sbirthday#3) && (cast(sbirthday#3 as string) > 1973-01-01 00:00:00) 就是最基本的表达式。它也是一种 Predicate,所以会调用 org.apache.spark.sql.catalyst.expressions.codegen.GeneratePredicate 来生成表达式的代码。表达式代码生成主要是想解决大量虚函数调用(Virtual Function Calls),泛化的代价等
全阶段代码生成(Whole-stage Code Generation)
全阶段代码生成(Whole-stage Code Generation),用来将多个处理逻辑整合到单个代码模块中,其中也会用到上面的表达式代码生成。和前面介绍的表达式代码生成不一样,这个是对整个 SQL 过程进行代码生成,前面的表达式代码生成仅对于表达式的。
相比 Volcano Iterator Model,全阶段代码生成的执行过程如下:
通过引入全阶段代码生成,大大减少了虚函数的调用,减少了 CPU 的调用,使得 SQL 的执行速度有很大提升。
代码编译
代码生成是在 Driver 端进行的,而代码编译是在 Executor 端进行的。
SQL执行
终于到了 SQL 真正执行的地方了。这个时候 Spark 会执行上阶段生成的代码,然后得到最终的结果,DAG 执行图如下:

5. Spark SQL 执行过程总结

主要步骤:
输入sql,dataFrame或者dataSet
经过Catalyst过程,生成最终我们得到的最优的物理执行计划
parser阶段
主要是通过Antlr4解析SqlBase.g4 ,所有spark支持的语法方式都是定义在sqlBase.g4里面了,生成了我们的语法解析器SqlBaseLexer.java和词法解析器SqlBaseParser.java
parse阶段 --> antlr4 —> 解析 —> SqlBase.g4 —> 语法解析器SqlBaseLexer.java + 词法解析器SqlBaseParser.java
analyzer阶段
使用基于Rule的规则解析以及Session Catalog来实现函数资源信息和元数据管理信息
Analyzer 阶段 --> 使用 --> Rule + Session Catalog --> 多个rule --> 组成一个batch --> session CataLog --> 保存函数资源信息以及元数据信息等
optimizer阶段
optimizer调优阶段 --> 基于规则的RBO优化rule-based optimizer --> 谓词下推 + 列剪枝 + 常量替换 + 常量累加
planner阶段
生成多个物理计划 --> 经过Cost Model进行最优选择 --> 基于代价的CBO优化 --> 最终选定得到的最优物理执行计划
选定最终的物理计划,准备执行
最终选定的最优物理执行计划 --> 准备生成代码去开始执行
将最终得到的物理执行计划进行代码生成,提交代码去执行我们的最终任务