《数据结构修炼手册》----链式二叉树的实现
链式二叉树的实现
- 1. 前置说明
- 2. 二叉树的遍历
-
- 2.1 前序、中序以及后序遍历(深度优先遍历(DFS))
- 2.2 三种遍历的实现
-
- 2.2.1 前序遍历的实现
- 2.2.2 中序遍历的实现
- 2.2.3 后序遍历的实现
- 2.3 层序遍历(广度优先遍历(BFS))
- 2.4 层序遍历的应用----完全二叉树的判断
- 3. 节点个数以及高度等
-
- 3.1 二叉树节点个数
-
- 方法一
- 方法二(推荐使用)
- 3.2 二叉树叶子节点的个数
-
- 方法一
- 方法二
- 3.3 二叉树第k层节点个数
- 3.4 二叉树的深度
- 3.5 二叉树查找值为x的节点
1. 前置说明
为什么要构建链式二叉树?
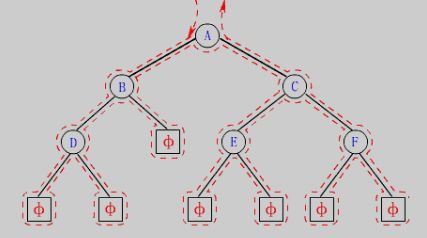
为了存储非完全二叉树结构,即不规则的二叉树结构,中间节点可能并没有存储元素。例如:

注意:普通二叉树的增删查改没有意义,如果只是为了存储数据,不如使用顺序表二叉树的结构。?
问:那么为什么要学习链式二叉树呢?
答:为了能够更好的控制它的结构,为后续学习更复杂的搜索二叉树打基础。另外,很多二叉树OJ题,都出在普通二叉树上。
简单创建一个链式二叉树:
typedef int BTDataType;
typedef struct BinaryTreeNode
{
BTDataType data;//节点存储的数据
struct BinaryTreeNode* left;//存储左子节点的地址
struct BinaryTreeNode* right;//存储右子节点的地址
}BTNode;
BTNode* BuyNode(BTDataType x)//开辟一个新节点
{
BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));
assert(newnode);
newnode->data = x;
newnode->left = NULL;
newnode->right = NULL;
return newnode;
}
BTNode* CreatBinaryTree()
{
BTNode* node1 = BuyNode(1);
BTNode* node2 = BuyNode(2);
BTNode* node3 = BuyNode(3);
BTNode* node4 = BuyNode(4);
BTNode* node5 = BuyNode(5);
BTNode* node6 = BuyNode(6);
node1->left = node2;
node1->right = node4;
node2->left = node3;
node4->left = node5;
node4->right = node6;
return node1;
}
注意:上述代码并不是创建二叉树的方式,真正创建二叉树方式后序详解重点讲解。
在看二叉树基本操作前,再回顾下二叉树的概念,二叉树是:
- 空树
- 非空:根节点,根节点的左子树、根节点的右子树组成的。

从概念中可以看出,二叉树定义是递归式的,因此后序基本操作中基本都死按照该概念实现的。
2. 二叉树的遍历
2.1 前序、中序以及后序遍历(深度优先遍历(DFS))
二叉树遍历(Traversal)是按照某种特定的规则,依次对二叉 树中的节点进行相应的操作,并且每个节点只操作一次。访问结点所做的操作依赖于具体的应用问题。 遍历是二叉树上最重要的运算之一,也是二叉树上进行其它运算的基础。

按照规则,二叉树的遍历有:前序/中序/后序的递归结构遍历:
-
前序遍历(也叫先根遍历)——访问根结点的操作发生在遍历其左右子树之前。即访问顺序为:根节点——左子树——右子树
以上面的那张二叉树的图为例,前序遍历如图所示:
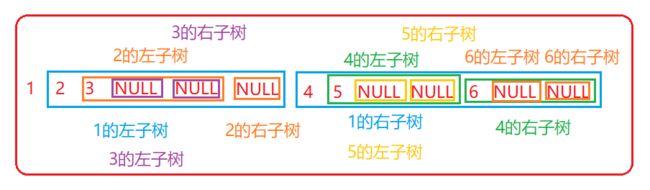
-
中序遍历(也叫中根遍历)——访问根结点的操作发生在遍历其左右子树之中(间)。即访问顺序为:左子树——根节点——右子树
中序遍历如图所示:

-
后序遍历(也叫后根遍历)——访问根结点的操作发生在遍历其左右子树之后。即访问顺序为:左子树——右子树——根节点
后序遍历如图所示:

2.2 三种遍历的实现
2.2.1 前序遍历的实现
代码实现:
void PreOrder(BTNode*root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
printf("%d ", root->data);//遍历根节点
PreOrder(root->left);//遍历左子树节点
PreOrder(root->right);//遍历右子树节点
}
图示:()中的数字为代码执行顺序
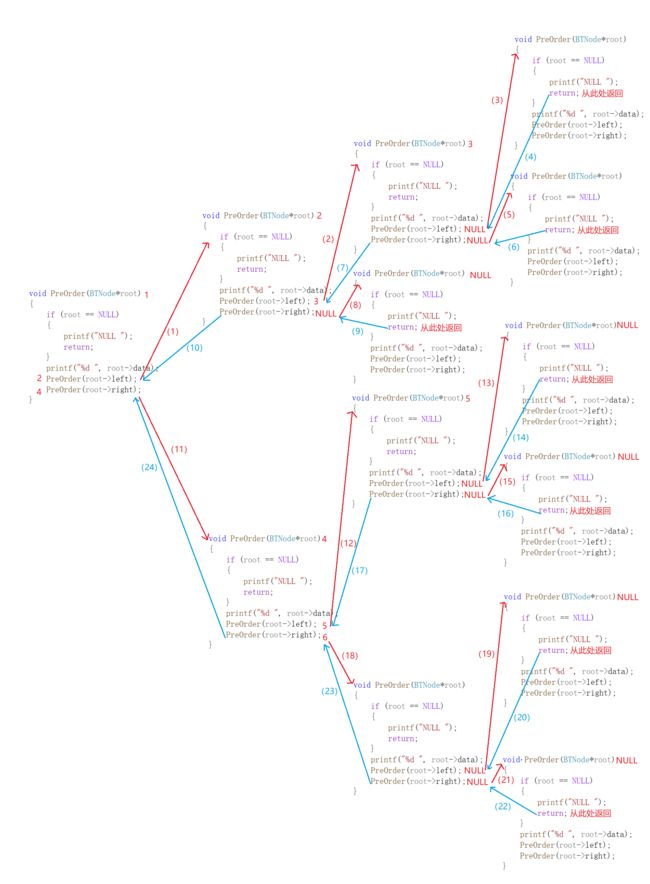
2.2.2 中序遍历的实现
代码实现:
void InOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
InOrder(root->left);
printf("%d ", root->data);
InOrder(root->right);
}
图示:

2.2.3 后序遍历的实现
代码实现:
void PostOrder(BTNode* root)
{
if (root == NULL)
{
printf("NULL ");
return;
}
InOrder(root->left);
InOrder(root->right);
printf("%d ", root->data);
}
2.3 层序遍历(广度优先遍历(BFS))
层序遍历——直接一层一层的进行遍历即可,从头节点开始逐个向后进行遍历。上图中的遍历顺序为:1—2—4—3—5—6
思路:
- 先把根入队列,借助队列先进先出的性质
- 上一层的节点出的时候,带下一层的左右子节点进去
图示:

实现:
注意:使用Queue.c和Queue.h两个文件,同时把队列中存储的数据类型定义为BinaryTreeNode*,注意头文件的包含问题和在Queue文件中的结构体的声明!
Queue.h文件中的修改:
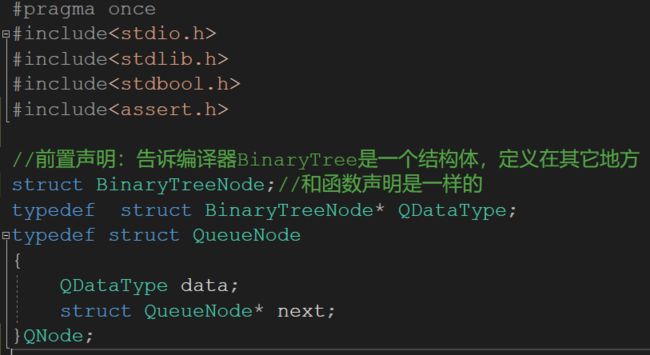
Test.c文件中的修改

代码:
void LevelOrder(BTNode* root)
{
Queue q;//队列的创建
QueueInit(&q);
if (root)//判断是否为空二叉树
{
QueuePush(&q, root);//将root节点push到队列中
}
while (!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);//拿到队列首元素
QueuePop(&q);//将出队列的节点从队列中删掉
if (front->left)
{
QueuePush(&q, front->left);//将左子节点push到队列中
}
if (front->right)
{
QueuePush(&q, front->right);//将右子节点push到队列中
}
printf("%d ", front->data);//打印出队列的数据
}
//对列的销毁
QueueDestory(&q);
}
2.4 层序遍历的应用----完全二叉树的判断
思路:
- 层序遍历,空节点也进队列。注意:在进队列之前,检查一下front是否为空,否则会出现对空指针进行解引用的错误。
- 出到空节点以后,出队列中所有的数据,如果全是空,就是完全二叉树,如果有非空,就不是。
图示:

代码:
//判断一个二叉树是否是完全二叉树
bool BTreeComplete(BTNode* root)
{
Queue q;//队列的创建
QueueInit(&q);
if (root)//判断是否为空二叉树
QueuePush(&q, root);//将root节点push到队列中
while (!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);
QueuePop(&q);
if (front == NULL)//出到空的时候退出,后面再进行判断
{
break;
}
//为什么要放到后面push呢?为了防止对空指针进行解引用
QueuePush(&q, front->left);//此时front一定不为空
QueuePush(&q, front->right);
}
while (!QueueEmpty(&q))
{
BTNode* front = QueueFront(&q);
//空后面出现非空,就说明不是完全二叉树
if (front)
{
return false;
}
QueuePop(&q);
}
//队列的销毁
QueueDestory(&q);
return true;
}
注意:考虑下面这一种情况:
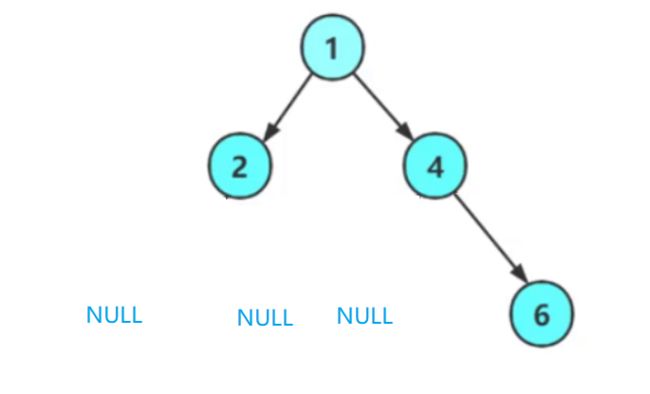
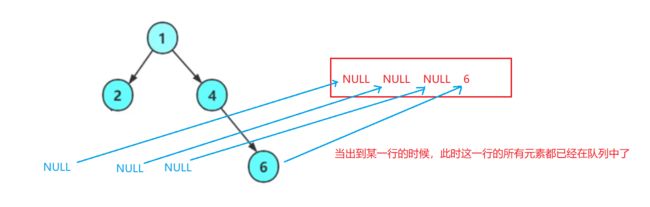
3. 节点个数以及高度等
3.1 二叉树节点个数
两种方法:
方法一
思路:遍历+计数
代码:
int count = 0;
void BTreeSize(BTNode* root)
{
if (root == NULL)
{
return;
}
count++;
BTreeSize(root->left);
BTreeSize(root->right);
}
当然也可以用局部静态变量来存储节点个数但是不推荐,代码如下:
int BTreeSize(BTNode* root)
{
static int count = 0;//只会在第一次进入时初始化一次
if (root == NULL)
{
return count;
}
count++;
BTreeSize(root->left);
BTreeSize(root->right);
return count;
}
当然,上面这两种方法都不好,都没有充分利用链式二叉树递归定义的结构性质,所以上面的两种方法都不推荐。上面的两种方法中第二种尤其不好,特别是在多次计算元素个数的时候,第二次计算如果count没有进行重新初始化操作将会仍然保留上一次计算的值,如果是用的全局变量的话还能每一次计数完之后重新进行赋值,但是第二种方法完全无法改变上一次计数后的残余值。
全局变量在进行多线程时会出现问题,比如在多线程的情况下就会出现问题:多个线程同时使用count这个全局变量,此时就会出现线程安全问题。
当然,也可以在调用函数中定义一个count变量,然后在调用的时候传入count的地址,那么BTreeSize函数必须这样进行定义:
int BTreeSize(BTNode* root,size_t *count)
{
static int count = 0;//只会在第一次进入时初始化一次
if (root == NULL)
{
return count;
}
(*count)++;
BTreeSize(root->left);
BTreeSize(root->right);
return count;
}
方法二(推荐使用)
(递归法)
思路:子问题
1、空树,最小规模子问题,节点数返回0
2、非空,左子树节点个数 + 右子树节点个数 + 1(自己)
代码:
int BTreeSize(BTNode* root)
{
return root==NULL ? 0 :
BTreeSize(root->left) +
BTreeSize(root->right) + 1;//1在最前面就是前序,在中间就是中序,在最后就是后序
}
这种方法充分利用了链式二叉树递归定义的结构性质,因为链式二叉树的本质就是由根节点和两个子树构成,求整个子树就是求根节点的节点数1加上左右子树的节点个数。
如图所示:
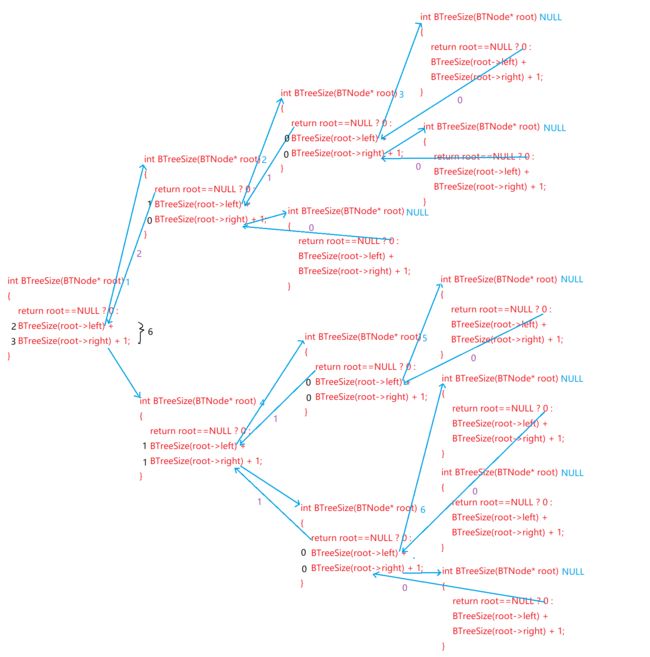
注意:图中紫色数字代表返回值,黑色数字代表相应函数的返回的值。
运用的算法思想:分治
分治:把复杂的问题,分成更小规模的子问题,子问题再分成更小规模的子问题······直到子问题不可再分割,直接能得出结果。
3.2 二叉树叶子节点的个数
方法一
思路:(遍历+计数)
和上面的思路基本一致,只是在count++的前面加上一个叶子节点的判断条件,进而达到对叶子节计数的目的。
代码:
int count = 0;
void BTreeLeafSize(BTNode* root)
{
if (root == NULL)
return 0;
if (root->left == NULL&&root->right==NULL)
{
count++;
}
BTreeLeafSize(root->left);
BTreeLeafSize(root->right);
}
方法二
思路:采用分治的思想。
代码:
int BTreeLeafSize(BTNode* root)
{
if (root == NULL)
return 0;
if (root->left == NULL&&root->right==NULL)
{
return 1;
}
else
return BTreeLeafSize(root->left) + BTreeLeafSize(root->right);
}
当然,上面的代码可以简写为下面的代码:
int BTreeLeafSize(BTNode* root)
{
if (root == NULL)
{
return 0;
}
return root->left == NULL && root->right == NULL ?
1 + BTreeLeafSize(root->left)+ BTreeLeafSize(root->right) :
0 + BTreeLeafSize(root->left) + BTreeLeafSize(root->right);
}
不过相对来说,更推荐没有简化过的,因为那个更好理解。
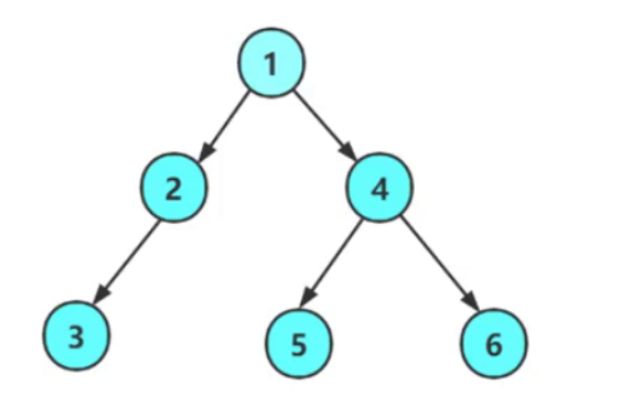
3.3 二叉树第k层节点个数
注意:k>=1
思想:
- 空树,返回0
- 非空,返回1
- 非空,且k > 1,转换成求左子树的k-1层的节点个数+右子树的k-1层的节点个数。
int BTreeKLevelSize(BTNode* root,int k)
{
assert(k >= 1);
if (root == NULL||k<)
{
return 0;
}
if (k == 1)
{
return 1;
}
return BTreeKLevelSize(root->left, k - 1) +
BTreeKLevelSize(root->left, k - 1);
}
图示:

3.4 二叉树的深度
思路:分治的思想
二叉树的高度 = 左子树的高度和右子树的高度,大的那个+1。
int BTreeDepth(BTNode* root)
{
if (root == NULL)
{
return 0;
}
int leftDepth = BTreeDepth(root->left);//左子树的深度
int rightDepth = BTreeDepth(root->right);//y
return leftDepth > rightDepth ? leftDepth + 1 : rightDepth + 1;//1是因为根节点本身也算作是一层
}
3.5 二叉树查找值为x的节点
思路:分治 二叉树 = 根节点+左子树+右子树
- 判断当前根节点是否为空
- 判断当前节点是否是我们要找的值
- 判断左子树中是否存在我们要找的节点
- 判断右子树中是否存在我们要找的节点
- 当前二叉树中不存在我们要找的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{
//节点为空的情况:直接返回NULL
if (root == NULL)
{
return NULL;
}
//当前节点就是我们要查找的节点:返回当前节点的地址
if (root->data == x)
{
return root;
}
//左子树
BTNode* leftRet = BinaryTreeFind(root->left, x);
if (leftRet)
{
return leftRet;
}
//右子树
BTNode* rightRet = BinaryTreeFind(root->right, x);
if (rightRet)
{
return rightRet;
}
//都找不到的情况下返回NULL,就是说当前二叉树中不存在存储该值的节点
return NULL;
}