mysql中undo、redo日志,以及分布式事务的解决方式
私聊互关,也可在评论区评论一下undo日志和redo日志
在数据库系统中,既有存放数据的文件,也有存放日志的文件。日志在内存中也是有缓存Log buffer,也有磁盘文件log file。MySQL中的日志文件,有这么两种与事务有关:undo日志与redo日志。
undo日志
数据库事务具备原子性(Atomicity),如果事务执行失败,需要把数据回滚。
原子性可以利用undo日志来实现。Undo Log的原理很简单,为了满足事务的原子性,在操作任何数据之前,首先将数据备份到Undo Log。然后进行数据的修改。如果出现了错误或者用户执行了ROLLBACK语句,系统可以利用Undo Log中的备份将数据恢复到事务开始之前的状态。数据库写入数据到磁盘之前,会把数据先缓存在内存中,事务提交时才会写入磁盘中。用Undo Log实现原子性和持久化的事务的简化过程:
假设有A、B两个数据,值分别为1,2。 A. 事务开始. B. 记录A=1到undo log. C. 修改A=3. D. 记录B=2到undo log. E. 修改B=4. F. 将undo log写到磁盘。 G. 将数据写到磁盘。 H. 事务提交
如何保证持久性?
事务提交前,会把修改数据到磁盘前,也就是说只要事务提交了,数据肯定持久化
如何保证原子性?
每次对数据库修改,都会把修改前数据记录在undo log,那么需要回滚时,可以读取undo log,恢复数据。
若系统在G和H之间崩溃
此时事务并未提交,需要回滚。而undo log已经被持久化,可以根据undo log来恢复数据
若系统在G之前崩溃
此时数据并未持久化到硬盘,依然保持在事务之前的状态缺陷:每个事务提交前将数据和Undo Log写入磁盘,这样会导致大量的磁盘IO,因此性能很低。
如果能够将数据缓存一段时间,就能减少IO提高性能。但是这样就会丧失事务的持久性。因此引入了另外一种机制来实现持久化,即Redo Log.
和Undo Log相反,Redo Log记录的是新数据的备份。在事务提交前,只要将Redo Log持久化即可,不需要将数据持久化,减少了IO的次数。
假设有A、B两个数据,值分别为1,2
A. 事务开始. B. 记录A=1到undo log buffer. C. 修改A=3. D. 记录A=3到redo log buffer. E. 记录B=2到undo log buffer. F. 修改B=4. G. 记录B=4到redo log buffer. H. 将undo log写入磁盘 I. 将redo log写入磁盘 J. 事务提交
- 如何保证原子性?
如果在事务提交前故障,通过undo log日志恢复数据。如果undo log都还没写入,那么数据就尚未持久化,无需回滚
- 如何保证持久化?
大家会发现,这里并没有出现数据的持久化。因为数据已经写入redo log,而redo log持久化到了硬盘,因此只要到了步骤`I`以后,事务是可以提交的。
- 内存中的数据库数据何时持久化到磁盘?
因为redo log已经持久化,因此数据库数据写入磁盘与否影响不大,不过为了避免出现脏数据(内存中与磁盘不一致),事务提交后也会将内存数据刷入磁盘(也可以按照固设定的频率刷新内存数据到磁盘中)。
- redo log何时写入磁盘
redo log会在事务提交之前,或者redo log buffer满了的时候写入磁盘
为什么要使用redo log
- 数据库数据写入是随机IO,性能很差
- redo log在初始化时会开辟一段连续的空间,写入是顺序IO,性能很好
- 实际上undo log并不是直接写入磁盘,而是先写入到redo log buffer中,当redo log持久化时,undo log就同时持久化到硬盘了,因此事务提交前,只需要对redo log持久化即可
-redo log中记录的数据,有可能包含尚未提交事务,如果此时数据库崩溃,那么如何完成数据恢复?
数据恢复有两种策略:
恢复时,只重做已经提交了的事务
恢复时,重做所有事务包括未提交的事务和回滚了的事务。然后通过Undo Log回滚那些未提交的事务
Inodb引擎采用的是第二种方案,因此undo log要在 redo log前持久化分布式事务
在数据库水平拆分、服务垂直拆分之后,一个业务操作通常要跨多个数据库、服务才能完成。在分布式网络环境下,我们无法保障所有服务、数据库都百分百可用,一定会出现部分服务、数据库执行成功,另一部分执行失败的问题。当出现部分业务操作成功、部分业务操作失败时,业务数据就会出现不一致。
例如:付款表与库存表在不同数据库,用户购买时扣减金额失败了,付款表回滚,但是库存表因为没有与商品表在同一个数据库中,并不会发生回滚。
解决分布式事务的思路
CAP定理和BASE理论可以参考之前文章
解决思路一:分阶段提交
1994 年,X/Open 组织(即现在的 Open Group )定义了分布式事务处理的DTP 模型。该模型包括这样几个角色:
应用程序( AP ):我们的微服务
事务管理器( TM ):全局事务管理者
资源管理器( RM ):一般是数据库
通信资源管理器( CRM ):是TM和RM间的通信中间件
在该模型中,一个分布式事务(全局事务)可以被拆分成许多个本地事务,运行在不同的AP和RM上。每个本地事务的ACID很好实现,但是全局事务必须保证其中包含的每一个本地事务都能同时成功,若有一个本地事务失败,则所有其它事务都必须回滚。但问题是,本地事务处理过程中,并不知道其它事务的运行状态。因此,就需要通过CRM来通知各个本地事务,同步事务执行的状态。
二阶段提交
阶段一:准备阶段,各个本地事务完成本地事务的准备工作
阶段二:执行阶段,各个本地事务根据上一阶段执行结果,进行提交或回滚
这个过程中需要一个协调者(coordinator),还有事务的参与者(voter)

投票阶段:协调组询问各个事务参与者,是否可以执行事务。每个事务参与者执行事务,写入redo和undo日志,然后反馈事务执行成功的信息(agree),若失败返回disagree
提交阶段:协调组发现每个参与者都可以执行事务(agree),于是向各个事务参与者发出commit指令,各个事务参与者提交事务,否则回滚。
缺陷:
单点故障问题:协调组若挂掉,那么将无法判断接下来是提交还是回滚
阻塞问题:在准备阶段、提交阶段,每个事物参与者都会锁定本地资源,并等待其它事务的执行结果,阻塞时间较长,资源锁定时间太久,因此执行的效率就比较低了。
解决思路二:TCC模式
它本质是一种补偿的思路。事务运行过程包括三个方法,
Try:资源的检测和预留;
Confirm:执行的业务操作提交;要求 Try 成功 Confirm 一定要能成功;
Cancel:预留资源释放。
执行分两个阶段:
准备阶段(try):资源的检测和预留;
执行阶段(confirm/cancel):根据上一步结果,判断下面的执行方法。如果上一步中所有事务参与者都成功,则这里执行confirm。反之,执行cancel
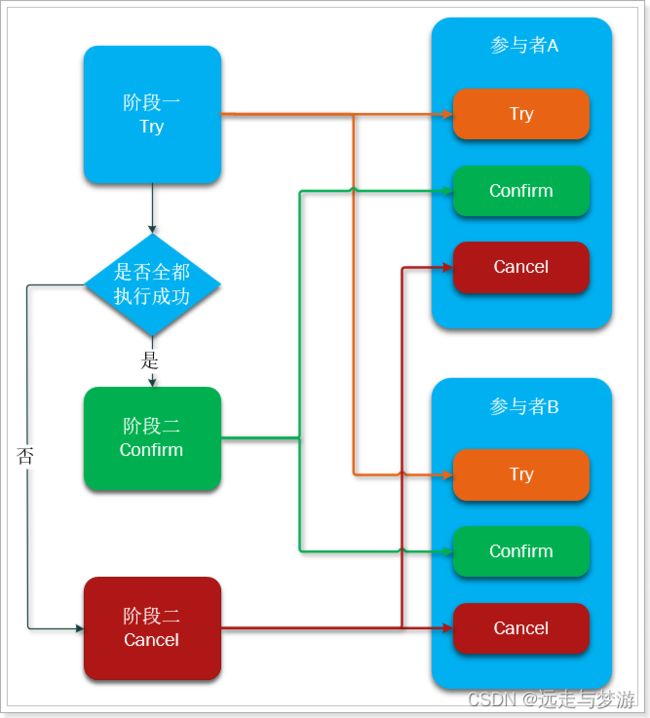
try、confirm、cancel都是独立的事务,不受其它参与者的影响,不会阻塞等待它人
例如:假设账户A原来余额是100,需要余额扣减30元。

缺点:需要人为编写代码实现try、confirm、cancel,代码侵入较多,同时增大了开发复杂度。同时cancel动作如果执行失败,资源就无法释放,需要引入重试机制,而重试可能导致重复执行,还要考虑重试时的幂等问题
解决思路三:使用MQ
事务发起者A执行本地事务,通过MQ将需要执行的事务信息发送给事务参与者B,事务参与者B接收到消息后执行本地事务。利用mq的消息可靠性实现,同时事务参与者B必须确保消息最终一定能消费,如果失败需要多次重试
缺点:依赖于MQ的可靠性、消息发起者可以回滚,但是消息参与者无法引起事务回滚、事务时效性差,取决于MQ消息发送是否及时
解决思路四:AT模式
类似于TCC模式,都是分为两个阶段,但是不需要自己编写第二阶段代码,通过Seata实现。
在一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后获取全局行锁,提交事务。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
这里的before image和after image类似于数据库的undo和redo日志,但其实是用数据库模拟的。
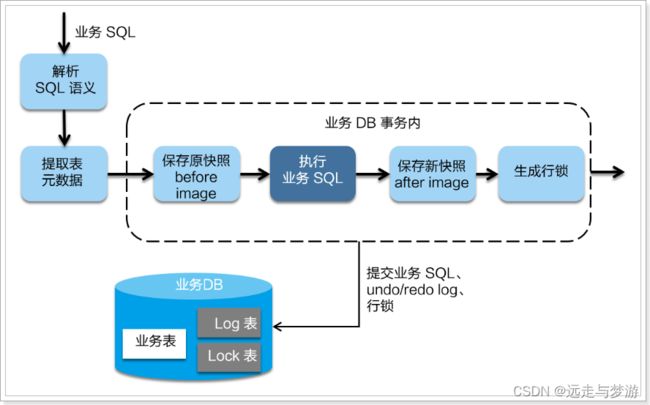
二阶段如果是提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。回滚方式便是用“before image”还原业务数据。