强化学习自动驾驶论文阅读(五)
(一)paper传送门
Explanation Augmented Feedback in Human-in-the-Loop Reinforcement Learning
(二)背景知识
强化学习(RL)-------------------------------------------------《Reinforcement Learning:An Introduction》第二版
Human-in-the-loop reinforcement learning(HRL)------https://ieeexplore.ieee.org/document/8243575
Large Margin Classification-----------------------------------https://blog.csdn.net/mike112223/article/details/76224728
SARFA-------------------------------------------------------------https://arxiv.org/abs/1912.12191
DQN-TAMER-----------------------------------------------------https://arxiv.org/abs/1810.11748v1
高斯扰动----------------------------------------------------------https://www.zhihu.com/question/26847935
Taxi(gym)---------------------------------------------------------https://www.lizenghai.com/archives/44605.html
(三)摘要
HRL(必须指出,这里不是分层强化学习)将人类对于交互中元组(s,a)的评价:好、坏(二元反馈),引入传统的强化学习中来提高样本效率。但是,也存在weak supervision 和 poor efficiency in leveraging human feedback的问题,因此,作者提出一种EXPAND (Explanation Augmented Feedback)的方法,不仅可以得到人类的反馈,并且利用人类的显著性映射来解释反馈,并且在Taxi和Atari-Pong上与其他的相关算法进行比较,证明是SOTA的。其实,类似于注意力机制,解释就是指从人类那里得到关于agent在观察图像以完成给定任务时应该关注哪些区域,方法就是增加扰动忽略不相关区域。
(四)内容
1 问题
很直觉,加上human的一些评估信息,RL的样本效率会大大提高,其中,一种方法就是Human-in-the-loop reinforcement learning(HRL),引入人类评估好坏虽然一定程度有效,但是,因为缺乏人类对评价好坏的解释,agent无法领会。在可解释的强化学习研究中,显著性映射已经被证明是人类评估主体内部表征的一种方法。本文扩展了该方法,对不相关区域应用多重扰动,从而用一组构造的扰动状态来补充每个显著性反馈,其思想是区分相关和不相关区域,来更新agent的Q值(其实就是通过扰动不相关区域来放大显著反馈(Saliency Feedback),期望Q-value approximator在计算Q值时忽略这些扰动,也就是与原始Q值相同)。
2 主体
很直觉,循环中,agent通过采样轨迹向human查询,然后,human分别给出对动作二元反馈的和对状态的显著性标注。扰动模块(perturbation Module)通过扰动不相关区域来补充显著性解释,反馈被agent用于更新策略参数。
1> Interaction
式中,k=4,表示连续4帧图片(observations)为当前时刻状态(state),其他关于RL的基础知识这里就不赘述了(交互中的奖励、状态、动作、策略等等),本文在此基础上,添加了新的过程量:![]()
H为human给出的一系列反馈,式中:![]()
![]()
式中,bth∈{-1,1},分别表示根据动作at得到的二元反馈:坏、好。Boxi是xt上的矩形区域Annotations(相关区域),由一个元组(x,y,w,h)表示,x,y分别代表左上角的坐标,w,h分别表示矩形区域的宽、高。很直觉,通过这几个值,可以定位不同的矩形区域。ht很重要,后面的loss都是基于这个。
2> Perturb Observations
对Observations扰动是为了分离相关区域和不相关区域,作者在这些不相关的区域上使用高斯扰动,本质上模糊它们,并促使agent更多地关注相关区域,目的就像前面说的,具有扰动不相关区域的状态的Q值在理想情况下应该与原始状态的Q值相同。

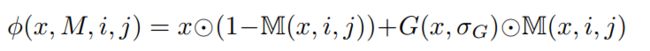
这里,需要指出,上面的高斯扰动实现了将原始状态s转换为相关区域上扰动的状态srt和不相关区域上扰动的状态~srt,具体的可以看前面提到的blog。
3> Algorithm
作者这里使用DQN作为策略网络,将二元反馈建模为行动最优性的标签,从而将人的反馈与动作的优势值直接联系起来。这里可以看到,系数的更新有两次,一次是传统的TD误差,另一次是本文提出的反馈误差(LF)。
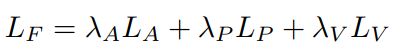
4> Loss
作者采用四种loss进行更新参数。
<1> TD Loss
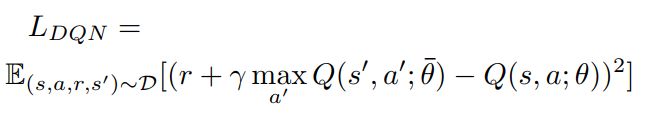
TD误差以及DQN用到的一些tricks这里就不赘述了
<2> Binary Feedback Loss
二元反馈误差,基于前面提到的五元元组ht。
作者这里先定义了一个优势值: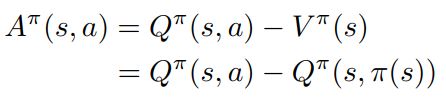
其实就是value-based算法向AC算法数学推导过程中括号中的值,也就是我们说的C(critic)。这个很直觉,当在状态s下选择的动作,human给出的二元反馈是1(好)时,目标优势值等于0,反之,目标优势值大于0(也就是实际优势值小于0),但是,对于定量计算的loss过程,优势值必须为确定值,作者这里采用Large Margin Classification loss(具体看前面提到的blog),下边值lm。因此:

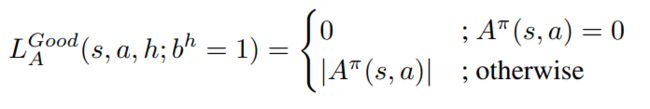

<3> Policy Invariant Loss
这个很直觉,人类对不相关区域扰动的解释中,好的动作永远是好的,坏的永远是坏的:
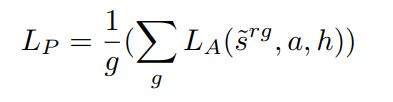
作者对每次的扰动进行了加权平均操作。
<4> Value Invariant Loss
前面提到,作者期望agent学习一个只捕捉图像观测状态相关区域的内部表示,对不相关区域不敏感。因此,原始状态的Q值应该与具有扰动无关区域的状态的Q值相似(理想相同):

3 Experimental Evaluation
作者这里引入了一种评估saliency score 方式:
具体的训练细节可以看原文,我想大家对这块也没兴趣,就直接看结果就好了。
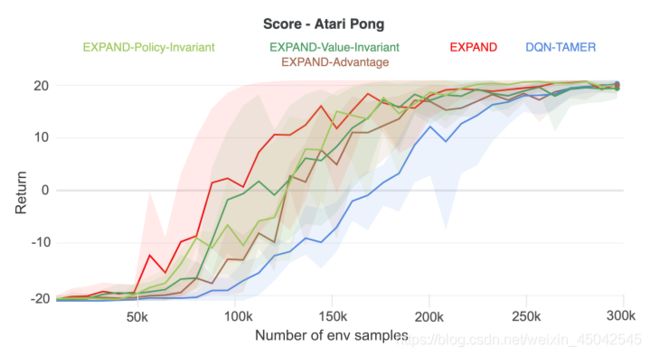
1> Results
两种模拟环境return:
saliency score:
作者这里对上面的三张图有具体的解释,感兴趣得可以看原文。
Taxi扰动的例子:
2> Additional Experiment Result

作者对每个状态中所需的扰动数量进行了实验,以获得最佳性能。很直觉,增加干扰可能只会带来轻微的性能提升,因此将干扰的数量设置为5就可以了。
(五)结论
这篇文章来自亚利桑那州立大学,提出一种EXPAND (Explanation Augmented Feedback)的方法,将二元反馈与显著性反馈结合,取得了良好的效果。另外,作者也指出本文的方法增加人力成本支出,而且,将“扰动”限制为状态图像的高斯模糊,未来的工作可以是实验不同类型的扰动(甚至是涉及对象操作的依赖于状态的扰动)。
本文感觉参考了模仿学习与注意力机制的思想,并将其有效结合起来。这篇文章虽然是对二维环境某种角度来说实现自动驾驶,但是,其方法对更逼真的模拟环境乃至显示环境自动驾驶具有指导意义,毕竟是可解释性的。