人脸识别 (5) 基于MCTNN人脸检测(Pytorch)
参考:FaceDetector/detect_step_by_step.ipynb at master · faciallab/FaceDetector · GitHub
中文翻译:从零开始搭建人脸识别系统(一)MTCNN - 知乎
1、网络结构
mtcnn 算法人脸检测过程分为三个独立的stage,每一个stage对应一个卷积网络,分别为pnet,rnet,onet。网络结构如图所示。
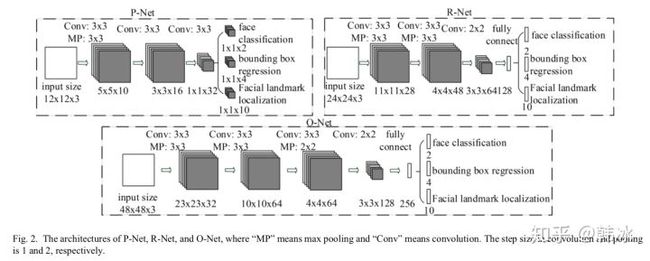
mtcnn三个网络的结构都相对简单,整个网络只包含3*3和2*2的卷积层、2*2的MaxPooling层、Prelu层和全连接层,网络结构比较简单。mtcnn采用级联网络的思想,pnet->rnet->onet网络结构更加复杂,每个网络采用多任务学习分别进行训练。
2、构造网络的三个stages (pnet, rnet, onet)
import os
import numpy as np
import mtcnn.network.mtcnn_pytorch as mtcnn
pnet = mtcnn.PNet()
rnet = mtcnn.RNet()
onet = mtcnn.ONet()
weight_folder = '../output/converted'
pnet.load_caffe_model(
np.load(os.path.join(weight_folder, 'pnet.npy'))[()])
rnet.load_caffe_model(
np.load(os.path.join(weight_folder, 'rnet.npy'))[()])
onet.load_caffe_model(
np.load(os.path.join(weight_folder, 'onet.npy'))[()])
3、三个子网络的实际作用是什么?
首先我们构建 一个虚拟图片,看看这个图片经过三个网络后会什么样子?
3.1 Pnet
import torch
print("Given ten images with shape (500 * 500).")
pnet_data = torch.randn(10, 3, 500, 500)
ret1, ret2, _ = pnet(pnet_data)
print("Pnet output: \n\tTensor shape of ret1 is %s.\n\tTensor shape of ret2 is %s.\n" % (ret1.shape, ret2.shape))
print("Where does '245' come from?")
print("245 = (500-2)/2-2-2 .\nApply 'minus 2' every Conv layer with kernel 3*3. Apply 'divide 2' every max-pooling layer with kenel 2.")给定图片大小是 (500 * 500). Pnet 输出: 张量ret1的维度是torch.Size([10, 2, 245, 245]). 张量ret2的维度是torch.Size([10, 4, 245, 245]). 这个 '245'怎么来的呢? 245 = (500-2)/2-2-2 . Apply 'minus 2' every Conv layer with kernel 3*3. Apply 'divide 2' every max-pooling layer with kenel 2.
每个卷积层(3*3)减2(每次卷积减少2个像素),每个池化层(核为2)除以2,一共三个卷积层一个池化层。
Pnet只有卷积层和relu层没有最后的全连接层,输入一张500*500的图片,输出分别是2*245*245,4*245*245 的feature map。245是怎么来的呢,我们知道原始图片没经过一个n*n的卷积层,输出维度都会减少n-1,每经过一个n*n的pooling 层输出维度都会减少n倍。Pnet的网络结构为 conv33->pooling22->conv33->conv33->conv11,所以最终输出维度为(500-2)/2-2-2 = 245。
由于是多任务学习Pnet输出的第一个feature map为分类结果(该feature map像素点对应的原图像12*12的区域是否包含人脸的分类结果),所以channel的值为2。第二个feature map对应于bounding box左上定点坐标和右下定点坐标的偏移量。与RPN的思想基本相同,避免了使用滑动窗口多次经过网络计算。此网络的作用是产生候选框,保证召回率,减少onet,rnet的计算量。
rnet、onet与pnet不同,由于最后存在全连接层,只能输入固定大小的图像。同样输出分类结果和人脸框坐标回归值,onet完成最后的人脸5个关键点的坐标预测任务。
3.2 Rnet
rnet_data = torch.randn(10, 3, 24, 24)
print("The input tensor of Rnet must be with shape (24 * 24)")
ret1, ret2, _ = rnet(rnet_data)
print("Rnet output: \n\tTensor shape of ret1 is %s.\n\tTensor shape of ret2 is %s.\n" % (ret1.shape, ret2.shape))Rnet输入张量维度必须是(24 * 24)
Rnet 输出:
Tensor shape of ret1 is torch.Size([10, 2]). 分类结果
Tensor shape of ret2 is torch.Size([10, 4]). 坐标回归值
3.3 Onet
onet_data = torch.randn(10, 3, 48, 48)
print("The input tensor of Rnet must be with shape (48 * 48)")
ret1, ret2, ret3 = onet(onet_data)
print("Rnet output: \n\tTensor shape of ret1 is %s.\n\tTensor shape of ret2 is %s.\n\tTensor shape of ret3 is %s." % (ret1.shape, ret2.shape, ret3.shape))
Onet的输入维度是 (48 * 48) Onet输出: Tensor shape of ret1 is torch.Size([10, 2]). 分类结果 Tensor shape of ret2 is torch.Size([10, 4]). 坐标回归值 Tensor shape of ret3 is torch.Size([10, 10]). 五个关键点坐标
4、真实照片测试
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
img = Image.open('../tests/asset/images/office5.jpg')
img_array = np.asarray(img)
plt.imshow(img_array)
plt.show()
4.1 图像金字塔
由于我们的pnet只能生成12*12大小的候选框,不能满足任意大小的人脸检测,所以我们使用原作者称为图像金字塔的方法解决这个问题。比如我们将图像缩小一倍,那么12*12的框就对应于原图像24*24的框。
import math
minsize = 12
factor = 0.707
width = img.size[0]
height = img.size[1]
# Compute valid scales
scales = []
cur_width = width
cur_height = height
cur_factor = 1
while cur_width >= minsize and cur_height >= minsize:
# ensure width and height are even
w = cur_width
h = cur_height
scales.append((w, h, cur_factor))
cur_factor *= factor
cur_width = math.ceil(cur_width * factor)
cur_height = math.ceil(cur_height * factor)
# Resize the image
img_pyramid = img_array.copy()
pyramid_list = []
for w, h, f in scales:
im = img.resize((w, h), Image.BILINEAR)
im = np.asarray(im)
img_pyramid[0:h, 0:w] = im
pyramid_list.append(im)
plt.imshow(img_pyramid)
plt.show() 
4.2 For each resized image in pyramid, pass it into pnet and get classification feature map and bounding box regression feature map.
def preprocess(img):
"""
Convert image from NDArray to torch.FloatTensor.
"""
img = img.transpose(2, 0, 1)
img = torch.FloatTensor(img)
# The input of pnet must be normalized.
img = (img - 127.5) * 0.0078125
img = torch.unsqueeze(img, 0)
return img
for (w, h, f), im in zip(scales, pyramid_list):
im = preprocess(im)
p_distribution, box_regs, _ = pnet(im)
score = p_distribution[:, 1]
print("Input shape: %s.\n\t-->Score shape %s.\n\t-->Box regression shpae %s.\n" % (im.shape, score.shape, box_regs.shape))
执行结果
Input shape: torch.Size([1, 3, 375, 500]). -->Score shape torch.Size([1, 183, 245]). -->Box regression shpae torch.Size([1, 4, 183, 245]). Input shape: torch.Size([1, 3, 266, 354]). -->Score shape torch.Size([1, 128, 172]). -->Box regression shpae torch.Size([1, 4, 128, 172]). Input shape: torch.Size([1, 3, 189, 251]). -->Score shape torch.Size([1, 90, 121]). -->Box regression shpae torch.Size([1, 4, 90, 121]). Input shape: torch.Size([1, 3, 134, 178]). -->Score shape torch.Size([1, 62, 84]). -->Box regression shpae torch.Size([1, 4, 62, 84]). Input shape: torch.Size([1, 3, 95, 126]). -->Score shape torch.Size([1, 43, 58]). -->Box regression shpae torch.Size([1, 4, 43, 58]). Input shape: torch.Size([1, 3, 68, 90]). -->Score shape torch.Size([1, 29, 40]). -->Box regression shpae torch.Size([1, 4, 29, 40]). Input shape: torch.Size([1, 3, 49, 64]). -->Score shape torch.Size([1, 20, 27]). -->Box regression shpae torch.Size([1, 4, 20, 27]). Input shape: torch.Size([1, 3, 35, 46]). -->Score shape torch.Size([1, 13, 18]). -->Box regression shpae torch.Size([1, 4, 13, 18]). Input shape: torch.Size([1, 3, 25, 33]). -->Score shape torch.Size([1, 8, 12]). -->Box regression shpae torch.Size([1, 4, 8, 12]). Input shape: torch.Size([1, 3, 18, 24]). -->Score shape torch.Size([1, 4, 7]). -->Box regression shpae torch.Size([1, 4, 4, 7]). Input shape: torch.Size([1, 3, 13, 17]). -->Score shape torch.Size([1, 2, 4]). -->Box regression shpae torch.Size([1, 4, 2, 4]).
4.3 特征如何映射到原始图片中的位置?以金字塔第五个图片为例
import matplotlib.patches as patches
w, h, f = scales[5]
im = pyramid_list[5].copy()
# Create figure and axes
fig, ax = plt.subplots(1)
# Display the image
ax.imshow(im)
# Create a Rectangle patch
rect = patches.Rectangle((0,0),12,12,linewidth=1,edgecolor='r',facecolor='none')
# Add the patch to the Axes
ax.add_patch(rect)
# Create a Rectangle patch
rect = patches.Rectangle((51,51),12,12,linewidth=1,edgecolor='b',facecolor='none')
# Add the patch to the Axes
ax.add_patch(rect)
plt.imshow(im)
plt.show()
print("We caculate Correspondence by this fomula: \n\tx1 = x1_map * 2 + 1, \n\ty1 = y1_map * 2 + 1, \n\tx2 = x1_map * 2 + 1 + 12, \n\ty2 = y2_map * 2 + 1 + 12.")
print("So the axis of Red box in original image is (1, 1, 13, 13), which Correspond to (0, 0) in feature map.")
print("The axis of blue box in original image is (51, 51, 63, 63), which correspond to (25, 25) in feature map.mro")
We caculate Correspondence by this fomula: x1 = x1_map * 2 + 1, y1 = y1_map * 2 + 1, x2 = x1_map * 2 + 1 + 12, y2 = y2_map * 2 + 1 + 12. Red box在原图中位置为(1, 1, 13, 13),特征图上位置为 (0, 0). blue box在原图中位置为(51, 51, 63, 63), 特征图上位置为 (25, 25)
4.4 通过pnet计算feature map,并建立feature map中每一个正样本点到原始图片区域的映射关系
def generate_bboxes(probs, offsets, scale, threshold):
"""Generate bounding boxes at places
where there is probably a face.
Arguments:
probs: a FloatTensor of shape [1, 2, n, m].
offsets: a FloatTensor array of shape [1, 4, n, m].
scale: a float number,
width and height of the image were scaled by this number.
threshold: a float number.
Returns:
boxes: LongTensor with shape [x, 4].
score: FloatTensor with shape [x].
"""
# applying P-Net is equivalent, in some sense, to
# moving 12x12 window with stride 2
stride = 2
cell_size = 12
# extract positive probability and resize it as [n, m] dim tensor.
probs = probs[0, 1, :, :]
# indices of boxes where there is probably a face
inds = (probs > threshold).nonzero()
if inds.shape[0] == 0:
return torch.empty((0, 4), dtype=torch.int32), torch.empty(0, dtype=torch.float32), torch.empty((0, 4), dtype=torch.float32)
# transformations of bounding boxes
tx1, ty1, tx2, ty2 = [offsets[0, i, inds[:, 0], inds[:, 1]]
for i in range(4)]
# they are defined as:
# w = x2 - x1 + 1
# h = y2 - y1 + 1
# x1_true = x1 + tx1*w
# x2_true = x2 + tx2*w
# y1_true = y1 + ty1*h
# y2_true = y2 + ty2*h
offsets = torch.stack([tx1, ty1, tx2, ty2], 1)
score = probs[inds[:, 0], inds[:, 1]]
# P-Net is applied to scaled images
# so we need to rescale bounding boxes back
bounding_boxes = torch.stack([
stride*inds[:, 1] + 1.0,
stride*inds[:, 0] + 1.0,
stride*inds[:, 1] + 1.0 + cell_size,
(stride*inds[:, 0] + 1.0 + cell_size),
], 0).transpose(0, 1).float()
bounding_boxes = torch.round(bounding_boxes / scale).int()
return bounding_boxes, score, offsets
candidate_boxes = torch.empty((0, 4), dtype=torch.int32)
candidate_scores = torch.empty((0))
candidate_offsets = torch.empty((0, 4), dtype=torch.float32)
for (w, h, f), im in zip(scales, pyramid_list):
im = preprocess(im)
p_distribution, box_regs, _ = pnet(im)
# we set filter threshold 0.6 here
candidate, scores, offsets = generate_bboxes(p_distribution, box_regs, f, 0.6)
candidate_boxes = torch.cat([candidate_boxes, candidate])
candidate_scores = torch.cat([candidate_scores, scores])
candidate_offsets = torch.cat([candidate_offsets, offsets])显示pnet给出的候选框
img_origin = img_array.copy()
def show_boxes(img, boxes):
# Create figure and axes
fig, ax = plt.subplots(1)
# Display the image
ax.imshow(img)
for box in boxes:
# Create a Rectangle patch
rect = patches.Rectangle((box[0],box[1]),box[2]-box[0],box[3]-box[1],linewidth=1,edgecolor='r',facecolor='none')
# Add the patch to the Axes
ax.add_patch(rect)
plt.show()
show_boxes(img_origin, candidate_boxes)
print("It seems that there are many boxes around regions with face. Pretty good!")
print("There are olso many redundant box here and the axis is olso inaccurate. Don't worry about it.") 
候选框很多而且不是很准对不对,没关系,上面说了第一阶段网络只保证召回率就可以了。接下来我们需要使用box regression的回归值对坐标形状位置进行调整。并进行nms(非极大抑制)操作过滤重合度过高的候选框。最后将候选框重新refine为正方形(防止进入下一层网络进行resize操作时图像变形)
4.4 Accurately adjust coordinates,nms and re-convert boxes to square.
def calibrate_box(bboxes, offsets):
"""Transform bounding boxes to be more like true bounding boxes.
'offsets' is one of the outputs of the nets.
Arguments:
bboxes: a IntTensor of shape [n, 4].
offsets: a IntTensor of shape [n, 4].
Returns:
a IntTensor of shape [n, 4].
"""
x1, y1, x2, y2 = [bboxes[:, i] for i in range(4)]
w = x2 - x1 + 1.0
h = y2 - y1 + 1.0
w = torch.unsqueeze(w, 1)
h = torch.unsqueeze(h, 1)
translation = torch.cat([w, h, w, h], 1).float() * offsets
bboxes += torch.round(translation).int()
return bboxes
def convert_to_square(bboxes):
"""Convert bounding boxes to a square form.
Arguments:
bboxes: a IntTensor of shape [n, 4].
Returns:
a IntTensor of shape [n, 4],
squared bounding boxes.
"""
square_bboxes = torch.zeros_like(bboxes, dtype=torch.float32)
x1, y1, x2, y2 = [bboxes[:, i].float() for i in range(4)]
h = y2 - y1 + 1.0
w = x2 - x1 + 1.0
max_side = torch.max(h, w)
square_bboxes[:, 0] = x1 + w*0.5 - max_side*0.5
square_bboxes[:, 1] = y1 + h*0.5 - max_side*0.5
square_bboxes[:, 2] = square_bboxes[:, 0] + max_side - 1.0
square_bboxes[:, 3] = square_bboxes[:, 1] + max_side - 1.0
square_bboxes = torch.ceil(square_bboxes + 1).int()
return square_bboxes
def refine_boxes(bboxes, w, h):
"""
Avoid coordinates beyond image size
"""
bboxes = torch.max(torch.zeros_like(bboxes), bboxes)
sizes = torch.IntTensor([[w, h, w, h]] * bboxes.shape[0])
bboxes = torch.min(bboxes, sizes)
return bboxes
def nms(dets, scores, thresh, mode="Union"):
"""
greedily select boxes with high confidence
keep boxes overlap <= thresh
rule out overlap > thresh
:param dets: [[x1, y1, x2, y2 score]]
:param thresh: retain overlap <= thresh
:return: indexes to keep
"""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = scores
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
if mode == "Union":
ovr = inter / (areas[i] + areas[order[1:]] - inter)
elif mode == "Minimum":
ovr = inter / np.minimum(areas[i], areas[order[1:]])
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
return np.array(keep)
candidate_boxes = calibrate_box(candidate_boxes, candidate_offsets)
candidate_boxes = convert_to_square(candidate_boxes)
candidate_boxes = refine_boxes(candidate_boxes, width, height)
keep = nms(candidate_boxes.cpu().detach().numpy(), candidate_scores.cpu().detach().numpy(), 0.7)
candidate_boxes = candidate_boxes[keep]
show_boxes(img_array.copy(), candidate_boxes)

5、Stage 2 Rnet
对pnet所有输出的候选框进行resize操作,全部变成24*24的大小,送入rnet网络进行分类,并预测框坐标回归值。与pnet一样,做坐标调整、nms、重新调整为正方形的操作。
boxes = candidate_boxes
# Step one: crop and resize the images and pre-process them.
stage_two_imgs = []
for box in boxes:
im = img_array[box[1]: box[3], box[0]: box[2]]
im = Image.fromarray(im)
im = im.resize((24, 24), Image.BILINEAR)
im = np.asarray(im)
im = preprocess(im)
stage_two_imgs.append(im)
stage_two_imgs = torch.cat(stage_two_imgs)
# Step two: filter the boxes by scores given by rnet
p_distribution, box_regs, _ = rnet(stage_two_imgs) # rnet forward pass
scores = p_distribution[:, 1]
mask = (scores >= 0.7)
boxes = boxes[mask]
box_regs = box_regs[mask]
scores = scores[mask]
boxes = calibrate_box(boxes, box_regs)
boxes = convert_to_square(boxes)
boxes = refine_boxes(boxes, width, height)
# nms
keep = nms(boxes.cpu().detach().numpy(), scores.cpu().detach().numpy(), 0.7)
boxes = boxes[keep]show_boxes(img_array.copy(), boxes)

6、Stage 3 Onet
# Step one: crop and resize the images and pre-process them.
stage_three_imgs = []
for box in boxes:
im = img_array[box[1]: box[3], box[0]: box[2]]
im = Image.fromarray(im)
im = im.resize((48, 48), Image.BILINEAR)
im = np.asarray(im)
im = preprocess(im)
stage_three_imgs.append(im)
stage_two_imgs = torch.cat(stage_three_imgs)
# Step two: filter the boxes by scores given by rnet
p_distribution, box_regs, _ = onet(stage_two_imgs) # rnet forward pass
scores = p_distribution[:, 1]
mask = (scores >= 0.6)
boxes = boxes[mask]
box_regs = box_regs[mask]
scores = scores[mask]
boxes = calibrate_box(boxes, box_regs)
boxes = refine_boxes(boxes, width, height)
# nms
keep = nms(boxes.cpu().detach().numpy(), scores.cpu().detach().numpy(), 0.3)
boxes = boxes[keep]
show_boxes(img_array.copy(), boxes)
