【深度学习实战】行人检测追踪与双向流量计数系统【python源码+Pyqt5界面+数据集+训练代码】YOLOv8、ByteTrack、目标追踪、双向计数、行人检测追踪、过线计数
《博主简介》
小伙伴们好,我是阿旭。专注于人工智能、AIGC、python、计算机视觉相关分享研究。
✌更多学习资源,可关注公-仲-hao:【阿旭算法与机器学习】,共同学习交流~
感谢小伙伴们点赞、关注!
《------往期经典推荐------》
一、AI应用软件开发实战专栏【链接】
| 项目名称 | 项目名称 |
|---|---|
| 1.【人脸识别与管理系统开发】 | 2.【车牌识别与自动收费管理系统开发】 |
| 3.【手势识别系统开发】 | 4.【人脸面部活体检测系统开发】 |
| 5.【图片风格快速迁移软件开发】 | 6.【人脸表表情识别系统】 |
| 7.【YOLOv8多目标识别与自动标注软件开发】 | 8.【基于YOLOv8深度学习的行人跌倒检测系统】 |
| 9.【基于YOLOv8深度学习的PCB板缺陷检测系统】 | 10.【基于YOLOv8深度学习的生活垃圾分类目标检测系统】 |
| 11.【基于YOLOv8深度学习的安全帽目标检测系统】 | 12.【基于YOLOv8深度学习的120种犬类检测与识别系统】 |
| 13.【基于YOLOv8深度学习的路面坑洞检测系统】 | 14.【基于YOLOv8深度学习的火焰烟雾检测系统】 |
| 15.【基于YOLOv8深度学习的钢材表面缺陷检测系统】 | 16.【基于YOLOv8深度学习的舰船目标分类检测系统】 |
| 17.【基于YOLOv8深度学习的西红柿成熟度检测系统】 | 18.【基于YOLOv8深度学习的血细胞检测与计数系统】 |
| 19.【基于YOLOv8深度学习的吸烟/抽烟行为检测系统】 | 20.【基于YOLOv8深度学习的水稻害虫检测与识别系统】 |
| 21.【基于YOLOv8深度学习的高精度车辆行人检测与计数系统】 | 22.【基于YOLOv8深度学习的路面标志线检测与识别系统】 |
| 23.【基于YOLOv8深度学习的智能小麦害虫检测识别系统】 | 24.【基于YOLOv8深度学习的智能玉米害虫检测识别系统】 |
| 25.【基于YOLOv8深度学习的200种鸟类智能检测与识别系统】 | 26.【基于YOLOv8深度学习的45种交通标志智能检测与识别系统】 |
| 27.【基于YOLOv8深度学习的人脸面部表情识别系统】 | 28.【基于YOLOv8深度学习的苹果叶片病害智能诊断系统】 |
| 29.【基于YOLOv8深度学习的智能肺炎诊断系统】 | 30.【基于YOLOv8深度学习的葡萄簇目标检测系统】 |
| 31.【基于YOLOv8深度学习的100种中草药智能识别系统】 | 32.【基于YOLOv8深度学习的102种花卉智能识别系统】 |
| 33.【基于YOLOv8深度学习的100种蝴蝶智能识别系统】 | 34.【基于YOLOv8深度学习的水稻叶片病害智能诊断系统】 |
| 35.【基于YOLOv8与ByteTrack的车辆行人多目标检测与追踪系统】 | 36.【基于YOLOv8深度学习的智能草莓病害检测与分割系统】 |
| 37.【基于YOLOv8深度学习的复杂场景下船舶目标检测系统】 | 38.【基于YOLOv8深度学习的农作物幼苗与杂草检测系统】 |
| 39.【基于YOLOv8深度学习的智能道路裂缝检测与分析系统】 | 40.【基于YOLOv8深度学习的葡萄病害智能诊断与防治系统】 |
| 41.【基于YOLOv8深度学习的遥感地理空间物体检测系统】 | 42.【基于YOLOv8深度学习的无人机视角地面物体检测系统】 |
| 43.【基于YOLOv8深度学习的木薯病害智能诊断与防治系统】 | 44.【基于YOLOv8深度学习的野外火焰烟雾检测系统】 |
| 45.【基于YOLOv8深度学习的脑肿瘤智能检测系统】 | 46.【基于YOLOv8深度学习的玉米叶片病害智能诊断与防治系统】 |
| 47.【基于YOLOv8深度学习的橙子病害智能诊断与防治系统】 | 48.【车辆检测追踪与流量计数系统】 |
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
基本功能演示
摘要:
行人检测追踪与流量计数系统在城市规划、公共安全和商业分析等多个领域扮演着重要角色。该系统的实施能够提供高精准的行人流量数据,从而帮助城市管理者更好地理解和分析人流动态,预测拥挤情况,并采取适当措施以改善公共空间的使用效率和安全。本文基于YOLOv8深度学习框架,通过10000张图片,训练了一个行人的目标检测模型,可检测行人1个类别;然后结合ByteTrack多目标跟踪算法,实现了目标的追踪效果,最终可以通过自行绘制任意线段实现追踪目标的双向过线计数效果,可分别统计通过线段的两个方向目标数量。基于以上内容开发了一款带UI界面的行人检测追踪与双向流量计数系统,可用于实时检测场景中的行人检测追踪与任意方向过线计数。该系统是基于python与PyQT5开发的,支持视频以及摄像头进行行人检测追踪与过线计数。本文提供了完整的Python代码和使用教程,给感兴趣的小伙伴参考学习,完整的代码资源文件获取方式见文末。
文章目录
- 基本功能演示
- 前言
- 一、软件核心功能介绍及效果演示
-
- 软件主要功能
- 界面参数设置说明
- (1)视频检测演示
- (2)摄像头检测演示
- 二、目标检测模型的训练、评估与推理
-
- 1.YOLOv8的基本原理
- 2. 数据集准备与训练
- 3. 训练结果评估
- 4. 使用模型进行检测
- 三、使用ByteTrack进行目标追踪
-
- ByteTrack算法简介
- 使用方法
- 四、过线计数判断方式
-
- 定义过线线段
- 判断过线方法
- 判断是否通过线段
- 过线效果展示
- 【获取方式】
- 结束语
点击跳转至文末《完整相关文件及源码》获取
前言
行人检测追踪与流量计数系统在城市规划、公共安全和商业分析等多个领域扮演着重要角色。该系统的实施能够提供高精准的行人流量数据,从而帮助城市管理者更好地理解和分析人流动态,预测拥挤情况,并采取适当措施以改善公共空间的使用效率和安全。利用最新的YOLOv8图像识别和ByteTrack跟踪算法,该系统在复杂的城市环境中也能准确地追踪行人流动,并进行有效计数。
行人检测追踪与流量计数系统的
应用场景包括:
城市交通管理:监测交叉口或街道的行人流量和流向,为信号灯控制提供依据。
零售店铺客流分析:统计进出店铺的顾客人数,分析高峰时段,优化店铺运营。
公共活动的人流组织:在体育赛事、音乐节等活动中监控人群密度,确保公共安全。
旅游区域管理:评估热门旅游点的人流量,便于资源配备和管制措施的实施。
公共交通站点规划:分析城市交通枢纽的人流模式,指导站点的设计和改造。
紧急疏散计划:在紧急情况下快速评估撤离行人数,帮助制定疏散方案。
总之,行人检测追踪与流量计数系统对于实现现代城市的智能化管理具有重大的实践和理论价值。它为行人流量的监测与分析提供了一种自动化、高效与精确的方法,能够帮助决策者作出更为科学合理的规划和应对策略,提高城市公共空间的运营质量和居民的生活便利性。随着人工智能技术的进一步发展,这类系统未来的应用潜力将会更加广泛。
博主通过搜集行人的相关数据图片,根据YOLOv8的目标检测与ByteTrack多目标追踪技术,并且可以自行绘制任意方向线段进行过线计数统计。最终基于python与Pyqt5开发了一款界面简洁的行人检测追踪与双向流量计数系统,可支持视频以及摄像头检测。本文详细的介绍了此系统的核心功能以及所使用到的技术原理与制作流程。
软件初始界面如下图所示:

检测结果界面如下:
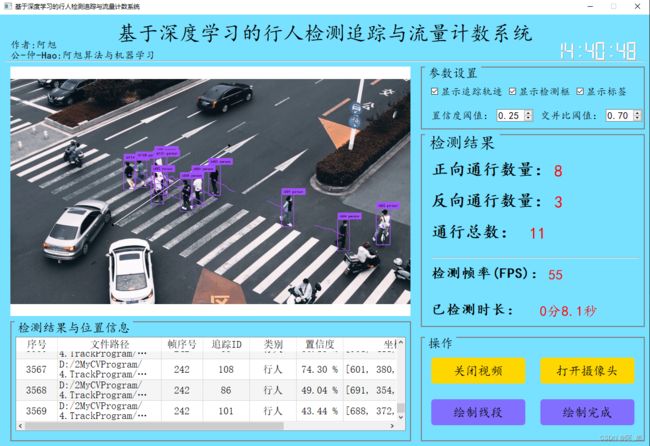
一、软件核心功能介绍及效果演示
软件主要功能
1. 支持视频与摄像头中的行人多目标检测追踪;
2. 可自行绘制任意方向线段,实现双向的过线计数统计,默认从下到上、从左向右为正向,另一个方向为反向;
3. 界面可实时显示双向过线数量、通行总数、检测帧率、检测时长等信息;
4. 可选择画面中是否显示追踪轨迹、显示检测框与显示检测标签。
注:本系统过线计数是依据目标中心点是否过线为判断依据的。
界面参数设置说明

显示追踪轨迹:用于设置检测的视频中是否显示目标追踪轨迹,默认勾选:表示显示追踪轨迹,不勾选则不显示追踪轨迹;显示检测框:用于设置检测的视频中是否显示目标检测框,默认勾选:表示显示检测框,不勾选则不显示检测框;显示标签:用于设置检测的视频中是否显示目标标签,默认勾选:表示显示检测标签,不勾选则不显示检测标签;置信度阈值:也就是目标检测时的conf参数,只有检测出的目标置信度大于该值,结果才会显示;交并比阈值:也就是目标检测时的iou参数,只有目标检测框的交并比大于该值,结果才会显示;
显示追踪轨迹、显示检测框与显示标签选项的功能效果如下:
(1)视频检测演示
1.点击打开视频图标,打开选择需要检测的视频,就会自动显示检测结果。再次点击该按钮,会关闭视频。
2.打开视频后,点击绘制线段,用鼠标左键在显示的界面上分别点两个点,用于绘制用于过线计数的线段;
3.两个点绘制完成后,点击绘制完成按钮,即可实现对视频中过线目标的双向计数与统计。
注:此时界面中显示的检测时长:表示当前已经检测的视频时间长度【与检测速度有关】,不是现实中已经过去的时间
(2)摄像头检测演示
1.点击打开摄像头图标,可以打开摄像头,可以实时进行检测,再次点击该按钮,可关闭摄像头。
2.打开摄像头后,点击绘制线段,用鼠标左键在显示的界面上分别点两个点,用于绘制用于过线计数的线段;
3.两个点绘制完成后,点击绘制完成按钮,即可实现对视频中过线目标的双向计数与统计。
注:此时界面中显示的检测时长:表示当前已经检测的视频时间长度【与检测速度有关】,不是现实中已经过去的时间
二、目标检测模型的训练、评估与推理
1.YOLOv8的基本原理
YOLOv8是一种前沿的深度学习技术,它基于先前YOLO版本在目标检测任务上的成功,进一步提升了性能和灵活性,在精度和速度方面都具有尖端性能。在之前YOLO 版本的基础上,YOLOv8 引入了新的功能和优化,使其成为广泛应用中各种物体检测任务的理想选择。主要的创新点包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。
YOLO各版本性能对比:

Yolov8主要创新点
Yolov8主要借鉴了Yolov5、Yolov6、YoloX等模型的设计优点,其本身创新点不多,偏重在工程实践上,具体创新如下:
- 提供了一个全新的SOTA模型(包括P5 640和P6 1280分辨率的目标检测网络和基于YOLACT的实例分割模型)。并且,基于缩放系数提供了N/S/M/L/X不同尺度的模型,以满足不同部署平台和应用场景的需求。
- Backbone:同样借鉴了CSP模块思想,不过将Yolov5中的C3模块替换成了C2f模块,实现了进一步轻量化,同时沿用Yolov5中的SPPF模块,并对不同尺度的模型进行精心微调,不再是无脑式一套参数用于所有模型,大幅提升了模型性能。
- Neck:继续使用PAN的思想,但是通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8移除了1*1降采样层。
- Head部分相比YOLOv5改动较大,Yolov8换成了目前主流的解耦头结构(Decoupled-Head),将分类和检测头分离,同时也从Anchor-Based换成了Anchor-Free。
- Loss计算:使用VFL Loss作为分类损失(实际训练中使用BCE Loss);使用DFL Loss+CIOU Loss作为回归损失。
标签分配:Yolov8抛弃了以往的IoU分配或者单边比例的分配方式,而是采用Task-Aligned Assigner正负样本分配策略。
其主要网络结构如下:
2. 数据集准备与训练
通过网络上搜集关于行人的各类图片,并使用LabelImg标注工具对每张图片中的目标边框(Bounding Box)及类别进行标注。一共包含10000张图片,其中训练集包含8000张图片,验证集包含2000张图片,部分图像及标注如下图所示。


图片数据的存放格式如下,在项目目录中新建datasets目录,同时将检测的图片分为训练集与验证集放入Data目录下。
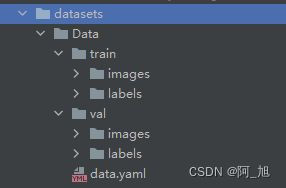
同时我们需要新建一个data.yaml文件,用于存储训练数据的路径及模型需要进行检测的类别。YOLOv8在进行模型训练时,会读取该文件的信息,用于进行模型的训练与验证。data.yaml的具体内容如下:
train: E:\MyCVProgram\PersonDetection\datasets\Data\images\train
val: E:\MyCVProgram\PersonDetection\datasets\Data\images\val
# number of classes
nc: 1
# class names
names: ['person']
注:train与val后面表示需要训练图片的路径,建议直接写自己文件的绝对路径。
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,batch参数用于调整训练的批次大小【根据内存大小调整,最小为1】,代码如下:
#coding:utf-8
from ultralytics import YOLO
import matplotlib
matplotlib.use('TkAgg')
if __name__ == '__main__':
# 模型配置文件路径
model_yaml_path = 'ultralytics/cfg/models/v8/yolov8.yaml'
# 加载模型配置文件
model = YOLO(model_yaml_path)
# 加载官方预训练模型
model.load('yolov8n.pt')
# 训练模型
print("开始训练模型...")
results = model.train(data='datasets/Data/data.yaml',
epochs=150,
batch=4)
3. 训练结果评估
在模型训练结束后,可以在runs/目录下找到训练过程及结果文件,如下所示:
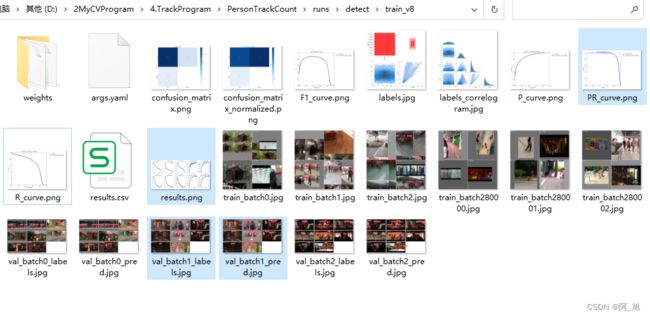
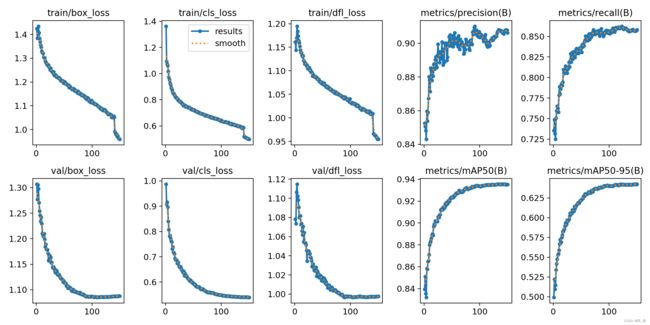
在深度学习中,我们通常用损失函数下降的曲线来观察模型训练的情况。YOLOv8在训练时主要包含三个方面的损失:定位损失(box_loss)、分类损失(cls_loss)和动态特征损失(dfl_loss)。
各损失函数作用说明:
定位损失box_loss:预测框与标定框之间的误差(GIoU),越小定位得越准;
分类损失cls_loss:计算锚框与对应的标定分类是否正确,越小分类得越准;
动态特征损失(dfl_loss):DFLLoss是一种用于回归预测框与目标框之间距离的损失函数。在计算损失时,目标框需要缩放到特征图尺度,即除以相应的stride,并与预测的边界框计算Ciou Loss,同时与预测的anchors中心点到各边的距离计算回归DFLLoss。这个过程是YOLOv8训练流程中的一部分,通过计算DFLLoss可以更准确地调整预测框的位置,提高目标检测的准确性。
本文训练结果如下:
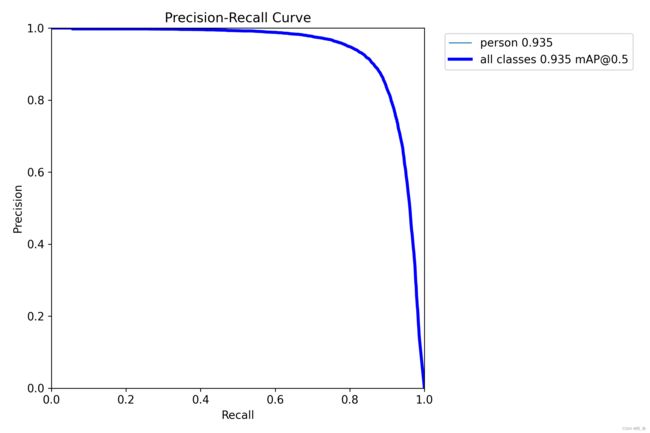
我们通常用PR曲线来体现精确率和召回率的关系,本文训练结果的PR曲线如下。mAP表示Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值。[email protected]:表示阈值大于0.5的平均mAP,可以看到本文模型两类目标检测的[email protected]平均值为0.934,结果还是非常不错的。
4. 使用模型进行检测
模型训练完成后,我们可以得到一个最佳的训练结果模型best.pt文件,在runs/trian/weights目录下。我们可以使用该文件进行后续的推理检测。
图片检测代码如下:
#coding:utf-8
from ultralytics import YOLO
import cv2
# 所需加载的模型目录
path = 'models/best.pt'
# 需要检测的图片地址
img_path = "TestFiles/s107.jpg"
# 加载预训练模型
model = YOLO(path, task='detect')
# 检测图片
results = model(img_path)
print(results)
res = results[0].plot()
# res = cv2.resize(res,dsize=None,fx=2,fy=2,interpolation=cv2.INTER_LINEAR)
cv2.imshow("YOLOv8 Detection", res)
cv2.waitKey(0)
执行上述代码后,会将检测的结果直接标注在图片上,结果如下:

三、使用ByteTrack进行目标追踪
ByteTrack算法简介
论文地址:https://arxiv.org/abs/2110.06864
源码地址:https://github.com/ifzhang/ByteTrack
ByteTrack算法是一种十分强大且高效的追踪算法,和其他非ReID的算法一样,仅仅使用目标追踪所得到的bbox进行追踪。追踪算法使用了卡尔曼滤波预测边界框,然后使用匈牙利算法进行目标和轨迹间的匹配。
ByteTrack算法的最大创新点就是对低分框的使用,作者认为低分框可能是对物体遮挡时产生的框,直接对低分框抛弃会影响性能,所以作者使用低分框对追踪算法进行了二次匹配,有效优化了追踪过程中因为遮挡造成换id的问题。
- 没有使用ReID特征计算外观相似度
- 非深度方法,不需要训练
- 利用高分框和低分框之间的区别和匹配,有效解决遮挡问题
ByteTrack与其他追踪算法的对比如下图所示,可以看到ByteTrack的性能还是相当不错的。

ByteTrack的实现代码如下:
class ByteTrack:
"""
Initialize the ByteTrack object.
Parameters:
track_thresh (float, optional): Detection confidence threshold
for track activation.
track_buffer (int, optional): Number of frames to buffer when a track is lost.
match_thresh (float, optional): Threshold for matching tracks with detections.
frame_rate (int, optional): The frame rate of the video.
"""
def __init__(
self,
track_thresh: float = 0.25,
track_buffer: int = 30,
match_thresh: float = 0.8,
frame_rate: int = 30,
):
self.track_thresh = track_thresh
self.match_thresh = match_thresh
self.frame_id = 0
self.det_thresh = self.track_thresh + 0.1
self.max_time_lost = int(frame_rate / 30.0 * track_buffer)
self.kalman_filter = KalmanFilter()
self.tracked_tracks: List[STrack] = []
self.lost_tracks: List[STrack] = []
self.removed_tracks: List[STrack] = []
def update_with_detections(self, detections: Detections) -> Detections:
"""
Updates the tracker with the provided detections and
returns the updated detection results.
Parameters:
detections: The new detections to update with.
Returns:
Detection: The updated detection results that now include tracking IDs.
"""
tracks = self.update_with_tensors(
tensors=detections2boxes(detections=detections)
)
detections = Detections.empty()
if len(tracks) > 0:
detections.xyxy = np.array(
[track.tlbr for track in tracks], dtype=np.float32
)
detections.class_id = np.array(
[int(t.class_ids) for t in tracks], dtype=int
)
detections.tracker_id = np.array(
[int(t.track_id) for t in tracks], dtype=int
)
detections.confidence = np.array(
[t.score for t in tracks], dtype=np.float32
)
else:
detections.tracker_id = np.array([], dtype=int)
return detections
def update_with_tensors(self, tensors: np.ndarray) -> List[STrack]:
"""
Updates the tracker with the provided tensors and returns the updated tracks.
Parameters:
tensors: The new tensors to update with.
Returns:
List[STrack]: Updated tracks.
"""
self.frame_id += 1
activated_starcks = []
refind_stracks = []
lost_stracks = []
removed_stracks = []
class_ids = tensors[:, 5]
scores = tensors[:, 4]
bboxes = tensors[:, :4]
remain_inds = scores > self.track_thresh
inds_low = scores > 0.1
inds_high = scores < self.track_thresh
inds_second = np.logical_and(inds_low, inds_high)
dets_second = bboxes[inds_second]
dets = bboxes[remain_inds]
scores_keep = scores[remain_inds]
scores_second = scores[inds_second]
class_ids_keep = class_ids[remain_inds]
class_ids_second = class_ids[inds_second]
if len(dets) > 0:
"""Detections"""
detections = [
STrack(STrack.tlbr_to_tlwh(tlbr), s, c)
for (tlbr, s, c) in zip(dets, scores_keep, class_ids_keep)
]
else:
detections = []
""" Add newly detected tracklets to tracked_stracks"""
unconfirmed = []
tracked_stracks = [] # type: list[STrack]
for track in self.tracked_tracks:
if not track.is_activated:
unconfirmed.append(track)
else:
tracked_stracks.append(track)
""" Step 2: First association, with high score detection boxes"""
strack_pool = joint_tracks(tracked_stracks, self.lost_tracks)
# Predict the current location with KF
STrack.multi_predict(strack_pool)
dists = matching.iou_distance(strack_pool, detections)
dists = matching.fuse_score(dists, detections)
matches, u_track, u_detection = matching.linear_assignment(
dists, thresh=self.match_thresh
)
for itracked, idet in matches:
track = strack_pool[itracked]
det = detections[idet]
if track.state == TrackState.Tracked:
track.update(detections[idet], self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
""" Step 3: Second association, with low score detection boxes"""
# association the untrack to the low score detections
if len(dets_second) > 0:
"""Detections"""
detections_second = [
STrack(STrack.tlbr_to_tlwh(tlbr), s, c)
for (tlbr, s, c) in zip(dets_second, scores_second, class_ids_second)
]
else:
detections_second = []
r_tracked_stracks = [
strack_pool[i]
for i in u_track
if strack_pool[i].state == TrackState.Tracked
]
dists = matching.iou_distance(r_tracked_stracks, detections_second)
matches, u_track, u_detection_second = matching.linear_assignment(
dists, thresh=0.5
)
for itracked, idet in matches:
track = r_tracked_stracks[itracked]
det = detections_second[idet]
if track.state == TrackState.Tracked:
track.update(det, self.frame_id)
activated_starcks.append(track)
else:
track.re_activate(det, self.frame_id, new_id=False)
refind_stracks.append(track)
for it in u_track:
track = r_tracked_stracks[it]
if not track.state == TrackState.Lost:
track.mark_lost()
lost_stracks.append(track)
"""Deal with unconfirmed tracks, usually tracks with only one beginning frame"""
detections = [detections[i] for i in u_detection]
dists = matching.iou_distance(unconfirmed, detections)
dists = matching.fuse_score(dists, detections)
matches, u_unconfirmed, u_detection = matching.linear_assignment(
dists, thresh=0.7
)
for itracked, idet in matches:
unconfirmed[itracked].update(detections[idet], self.frame_id)
activated_starcks.append(unconfirmed[itracked])
for it in u_unconfirmed:
track = unconfirmed[it]
track.mark_removed()
removed_stracks.append(track)
""" Step 4: Init new stracks"""
for inew in u_detection:
track = detections[inew]
if track.score < self.det_thresh:
continue
track.activate(self.kalman_filter, self.frame_id)
activated_starcks.append(track)
""" Step 5: Update state"""
for track in self.lost_tracks:
if self.frame_id - track.end_frame > self.max_time_lost:
track.mark_removed()
removed_stracks.append(track)
self.tracked_tracks = [
t for t in self.tracked_tracks if t.state == TrackState.Tracked
]
self.tracked_tracks = joint_tracks(self.tracked_tracks, activated_starcks)
self.tracked_tracks = joint_tracks(self.tracked_tracks, refind_stracks)
self.lost_tracks = sub_tracks(self.lost_tracks, self.tracked_tracks)
self.lost_tracks.extend(lost_stracks)
self.lost_tracks = sub_tracks(self.lost_tracks, self.removed_tracks)
self.removed_tracks.extend(removed_stracks)
self.tracked_tracks, self.lost_tracks = remove_duplicate_tracks(
self.tracked_tracks, self.lost_tracks
)
output_stracks = [track for track in self.tracked_tracks if track.is_activated]
return output_stracks
使用方法
1.创建ByteTrack跟踪器
# 创建跟踪器
byte_tracker = sv.ByteTrack(track_thresh=0.25, track_buffer=30, match_thresh=0.8, frame_rate=30)
2.对YOLOv8的目标检测结果进行追踪
model = YOLO(path)
results = model(frame)[0]
detections = sv.Detections.from_ultralytics(results)
detections = byte_tracker.update_with_detections(detections)
3.显示追踪结果ID、检测框及标签信息
labels = [
f"id{tracker_id} {model.model.names[class_id]}"
for _, _, confidence, class_id, tracker_id
in detections
]
annotated_frame = frame.copy()
annotated_frame = box_annotator.annotate(
scene=annotated_frame,
detections=detections,
labels=labels)
最终检测效果如下:
四、过线计数判断方式
定义过线线段
定义用于统计过线的线段,代码如下:
cap = cv2.VideoCapture(video_path)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
point_A = [10, int(height/5*4)]
point_B = [width-10, int(height/5)]
# 定义过线使用的线段点
LINE_START = sv.Point(point_A[0], point_A[1])
LINE_END = sv.Point(point_B[0], point_B[1])
line_zone = MyLineZone(start=LINE_START, end=LINE_END)
判断过线方法
使用目标中心点判断是否过线,核心代码如下:
for i, (xyxy, _, confidence, class_id, tracker_id) in enumerate(detections):
if tracker_id is None:
continue
# 使用中心点判断是否过线
x1, y1, x2, y2 = xyxy
center_x = int((x1 + x2) / 2)
center_y = int((y1 + y2) / 2)
center_point = Point(x=center_x, y=center_y)
triggers = [self.vector.is_in(point=center_point)]
上述通过目标框坐标计算出目标中心点坐标center_x ,center_y ,然后通过is_in函数判断过线状态,其中is_in函数定义如下:
def is_in(self, point: Point) -> bool:
v1 = Vector(self.start, self.end)
v2 = Vector(self.start, point)
cross_product = (v1.end.x - v1.start.x) * (v2.end.y - v2.start.y) - (
v1.end.y - v1.start.y
) * (v2.end.x - v2.start.x)
return cross_product < 0
函数首先根据线段的起点和终点构造两个向量v1和v2,分别表示线段和待判断的点与线段起点的向量。然后计算两个向量的叉积,并判断叉积的正负来确定点的位置关系。若叉积小于0,则点在线段的左侧;若叉积大于0,则点在线段的右侧;若叉积等于0,则点在线段上。根据题设,函数返回的是点在线段不同侧的状态,即当叉积小于0时返回True,否则返回False。
判断是否通过线段
上述判断方式只能用于判断目标是否通过线段所在直线,并不是在线段内通过。如果想判断在线段内通过,需要另外加上过线时的判断条件,核心代码如下:
def point_in_line(self, center_point):
# 判断点是否在线段之间通过
# 计算向量 AP 与向量 AB 的点积(也称为“标量积”)
# 点积的绝对值应在 0(包括端点)与向量 AB 的模长平方之间,且方向应与 AB 相同(即点积为正)
point_A, point_B = self.get_line_points(self.vector)
xA, yA = point_A
xB, yB = point_B
xP, yP = center_point
AB = (xB - xA, yB - yA)
AP = (xP - xA, yP - yA)
# 计算向量 AP 与向量 AB 的点积
dot_product = AB[0] * AP[0] + AB[1] * AP[1]
# 计算向量 AB 模长的平方
AB_length_squared = AB[0] ** 2 + AB[1] ** 2
# 判断标准:点积的绝对值应在 0(包括端点)与向量 AB 的模长平方之间,且方向应与 AB 相同(即点积为正)
if 0 <= dot_product <= AB_length_squared and dot_product >= 0:
within_segment = True
else:
within_segment = False
return within_segment
判断点是否在线段之间通过,通过计算向量 AP 与向量 AB的点积(也称为“标量积”)来进行判断。其中P表示目标中心点,AB表示目标需要通过的线段。
判断标准:点积的绝对值应在 0(包括端点)与向量 AB 的模长平方之间,且方向应与 AB 相同(即点积为正),则表示在线段内通过。
过线效果展示
过线效果展示如下:
以上便是关于此款行人检测追踪与双向流量计数系统的原理与代码介绍。基于以上内容,博主用python与Pyqt5开发了一个带界面的软件系统,即文中第二部分的演示内容,能够很好的通过视频及摄像头进行检测追踪,以及自定义过线计数。
关于该系统涉及到的完整源码、UI界面代码、数据集、训练代码、环境配置说明文档等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
【获取方式】
关注下方名片G-Z-H:【阿旭算法与机器学习】,发送【源码】即可获取下载方式
本文涉及到的完整全部程序文件:包括python源码、数据集、训练代码、UI界面源码、环境配置说明文档等(见下图),获取方式见文末:
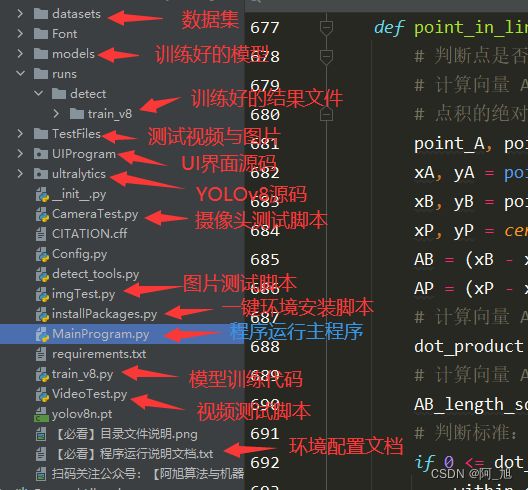
注意:该代码基于Python3.9开发,运行界面的主程序为
MainProgram.py,其他测试脚本说明见上图。为确保程序顺利运行,请按照程序运行说明文档txt配置软件运行所需环境。
关注下方名片GZH:【阿旭算法与机器学习】,发送【源码】即可获取下载方式
结束语
以上便是博主开发的行人检测追踪与双向流量计数系统的全部内容,由于博主能力有限,难免有疏漏之处,希望小伙伴能批评指正。
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!
觉得不错的小伙伴,感谢点赞、关注加收藏哦!