Pytorch中张量讲解 | Pytorch系列(四)
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
文 |AI_study
欢迎回到PyTorch神经网络编程系列。在这篇文章中,我们将通过PyTorch的张量来更深入地探讨PyTorch本身。废话不多说,我们开始吧。

PyTorch中的张量是我们在PyTorch中编程神经网络时会用到的数据结构。
在对神经网络进行编程时,数据预处理通常是整个过程的第一步,数据预处理的一个目标是将原始输入数据转换成张量形式。
引入Pytorch中的张量
torch.Tensor类示例
PyTorch中的张量就是torch.Tensor的Python类的一个实例。我们可以使用类构造函数来创造一个 torch.Tensor 对象,就像这样:
> t = torch.Tensor()
> type(t)
torch.Tensor
这就产生了一个空张量(没有数据的张量),但是我们马上就会把数据添加进去。
一、张量的属性
首先,让我们看看一些张量属性。每一个torch.Tensor有这些属性:
torch.dtypetorch.devicetorch.layout
看看我们的张量 t ,我们可以看到如下的默认属性值:
> print(t.dtype)
> print(t.device)
> print(t.layout)
torch.float32
cpu
torch.strided
(1)张量的 torch.dtype
dtype(也就是这里torch.float32)指定了张量中包含的数据类型。张量包含下面这些类型中的一种(相同类型的)数值数据:
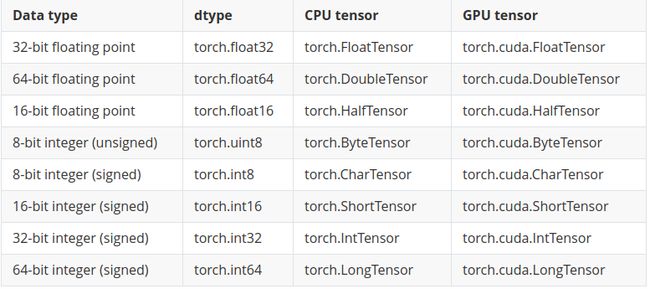
注意每种类型都有一个CPU和GPU版本。关于张量数据类型需要记住的一件事是,张量之间的张量运算必须发生在具有相同数据类型的张量之间。
(2)张量的 torch.device
device(在我们的例子中是cpu)指定分配张量数据的设备(cpu或GPU)。这决定了给定张量的张量计算将在哪里进行。
PyTorch支持多种设备的使用,它们是使用类似这样的索引指定的:
> device = torch.device('cuda:0')
> device
device(type='cuda', index=0)
如果我们有上述设备,我们可以通过设备传递给张量的构造函数在设备上创建张量。使用多个设备时,要记住一件事,张量之间的张量操作必须在同一设备上存在的张量之间进行。
当我们成为“高级”用户时,通常会使用多个设备,所以现在无需担心。
(2)张量的torch.layout
在我们的例子中(torch.strided),layout 指定了张量在内存中的存储方式。要了解更多关于 stride 可以参考这里。
https://en.wikipedia.org/wiki/Stride_of_an_array
现在,我们只需要知道这些。
去掉张量属性
作为神经网络程序员,我们需要注意以下几点:
张量包含统一类型(dtype)的数据。
张量之间的计算取决于 dtype 和 device。
现在让我们看看在PyTorch中使用数据创建张量的常见方法。
使用数据创建张量
这些是在PyTorch中使用数据(类似数组)创建张量对象(torch.Tensor类的实例)的主要方法:
torch.Tensor(data)
torch.tensor(data)
torch.as_tensor(data)
torch.from_numpy(data)
让我们看看其中的每一个。它们都接受某种形式的数据,并为我们提供了torch.Tensor类的实例。有时候,当有多种方法可以达到相同的结果时,事情可能会变得令人困惑,所以让我们来分解一下。
我们首先使用每个选项创建一个张量,然后看看我们得到了什么。我们将从创建一些数据开始。
我们可以使用Python列表或序列,但是numpy.ndarrays将是更常见的选择,因此我们将使用numpy.ndarray,如下所示:
> data = np.array([1,2,3])
> type(data)
numpy.ndarray
这为我们提供了一个简单的numpy.ndarray类型的数据。
现在,让我们用这些选项1-4来创建张量,看看我们得到了什么:
> o1 = torch.Tensor(data)
> o2 = torch.tensor(data)
> o3 = torch.as_tensor(data)
> o4 = torch.from_numpy(data)
> print(o1)
> print(o2)
> print(o3)
> print(o4)
tensor([1., 2., 3.])
tensor([1, 2, 3], dtype=torch.int32)
tensor([1, 2, 3], dtype=torch.int32)
tensor([1, 2, 3], dtype=torch.int32)
除了第一个之外,所有的选项 (o1、o2、o3、o4) 似乎都产生了相同的张量。第一个选项 (o1) 在数字后面有圆点,表示数字是浮点数,而后面三个选项的类型是int32。
// Python code example of what we mean
> type(2.)
float
> type(2)
int
在下一篇文章中,我们将更深入地探讨这一差异以及其他一些隐藏在背后的重要差异。
下一篇文章中的讨论将让我们看到这些选项中哪一个最适合创建张量。现在,让我们看看一些可用于从头创建张量的创建选项,而不需要预先获得任何数据。
无需数据的创建选项
下面是一些可用的其他创建选项。
torch.eye()函数,它返回一个二维张量,对角线上是1,其他地方是0。eye() 这个名称与单位矩阵的思想有关,单位矩阵是一个方阵,主对角线上是1,其他地方都是0。
> print(torch.eye(2))
tensor([
[1., 0.],
[0., 1.]
])
torch.zeros()函数,它用指定形状参数的形状创建一个全部为 0 张量。
> print(torch.zeros([2,2]))
tensor([
[0., 0.],
[0., 0.]
])
类似地,我们有一个torch.ones()函数,它创建了一个全部为 1 的张量。
> print(torch.ones([2,2]))
tensor([
[1., 1.],
[1., 1.]
])
我们还有一个torch.rand()函数,它创建了一个具有指定参数形状的张量,其值是随机的。
> print(torch.rand([2,2]))
tensor([
[0.0465, 0.4557],
[0.6596, 0.0941]
])
这是不需要数据的可用创建函数的一个小子集。查看PyTorch文档以获得完整的列表。
https://pytorch.org/docs/stable/index.html
我希望现在您已经很好地理解了如何使用PyTorch通过使用数据以及不需要数据的内置函数来创建张量。如果我们使用numpy,这个任务就很简单了。ndarrays,所以如果你已经很熟悉NumPy,那么恭喜你。
在下一篇文章中,我们将更深入地研究需要数据的创建选项,我们将发现这些选项之间的差异,并查看哪些选项工作得最好。下节课见!
文章中内容都是经过仔细研究的,本人水平有限,翻译无法做到完美,但是真的是费了很大功夫,希望小伙伴能动动你性感的小手,分享朋友圈或点个“在看”,支持一下我 ^_^
英文原文链接是:
https://deeplizard.com/learn/video/jexkKugTg04



加群交流
 欢迎小伙伴加群交流,目前已有交流群的方向包括:AI学习交流群,目标检测,秋招互助,资料下载等等;加群可扫描并回复感兴趣方向即可(注明:地区+学校/企业+研究方向+昵称)
欢迎小伙伴加群交流,目前已有交流群的方向包括:AI学习交流群,目标检测,秋招互助,资料下载等等;加群可扫描并回复感兴趣方向即可(注明:地区+学校/企业+研究方向+昵称)


我的生活不能没有你! ????