opencv-python学习笔记(十):实现人脸特征转换
引言
本次实验来自实验楼,而实验楼代码的出处为如下GitHub链接,加上一些自己的理解与说明,总结成本文笔记。
https://github.com/matthewearl/faceswap
所需环境
Dlib是一个高级的机器学习库,它是为解决复杂的现实世界问题而创建的。这个库是用C++编程语言创建的,它与C/C++、Python和java一起工作。
本次因为有dlib库需要安装,个人更习惯于Linux系统,所以本次使用环境为个人腾讯云ubuntu 18.04,关于dlib库,它的安装需要cmake与boost,如果没有编译这两个,那么pip install dlib的时候,Building wheel for dlib (setup.py)是会有问题的,即首先需要解决环境问题。
这里安装方式有简便的直接apt-get,也有拉源码重新编译,这里直接参考本篇博客:
linux下openssl、cmake与boost的更新总结
验证安装是否成功,cmake直接通过verison进行查看,boost可以运行如下脚本:
#include 将以上代码保存为test.cpp,然后再进行编译:
g++ -Wall -o test test.cpp
// 106501
// 1_65_1
// linux
// GNU C++ version 7.5.0
// GNU libstdc++ version 20191114
如果出现注释中提示内容,那么基本就没有问题,因为dlib对于boost与cmake没有版本要求,所以在依赖安装没有问题的情况下,可以不使用源码,直接apt-get安装。这里不再介绍,那么下面就能直接通过pip安装dlib与opencv:
pip install opencv-python
pip install dlib
然后原git代码还用了docopt库,我看了下好像跟argparse性质差不多,记得很早之前有总结过argparse的一个demo,总结了它的一些api,画了张思维导图,这里引用一下导图,触类旁通:

Python利用argparse模块图片转字符文件
而关于docopt,可以直接看最上引言中引用的git链接,这也是总的代码,这里指贴出一个测试demo:
"""
faceswap can put facial features from one face onto another.
Usage: faceswap [options]
Options:
-v --version show the version.
-h --help show usage message.
"""
import cv2
import dlib
import numpy as np
from docopt import docopt
__version__ = '1.0'
def main():
arguments = docopt(__doc__, version=__version__)
if __name__ == '__main__':
main()
实验思路
- 借助 dlib 库检测出图像中的脸部特征
- 计算将第二张图像脸部特征对齐到一张图像脸部特征的变换矩阵
- 综合考虑两张照片的面部特征获得合适的面部特征掩码
- 根据第一张图像人脸的肤色修正第二张图像
- 通过面部特征掩码拼接这两张图像
- 保存图像
实验过程
首先需要下载dlib官方提供的模型数据shape_predictor_68_face_landmarks.dat,这里,官方的GitHub链接为:
https://github.com/davisking/dlib-models
如果网速很慢,我上传了百度云盘,能直接下载:
链接:https://pan.baidu.com/s/1RU4li6qiJwEyykwKRfN-Qg?pwd=q4iw
提取码:q4iw
这个dat从名字上就能知道,它提取的是面部耳鼻喉68个特征点的训练模型,而更复杂的128特征点这里不再过多介绍,有了这个模型之后我们就不需要自己再耗费时间去训练模型,直接拿来使用即可。
关于这68个特征点,可以根据 用Python检测人脸特征 中一图表示:

- 颚点= 0–16
- 右眉点= 17–21
- 左眉点= 22–26
- 鼻点= 27–35
- 右眼点= 36–41
- 左眼点= 42–47
- 口角= 48–60
- 嘴唇分数= 61–67
根据上述,用代码如下表示:
FACE_POINTS = list(range(17, 68)) # 脸
MOUTH_POINTS = list(range(48, 61)) # 嘴巴
RIGHT_BROW_POINTS = list(range(17, 22)) # 右眉毛
LEFT_BROW_POINTS = list(range(22, 27)) # 左眉毛
RIGHT_EYE_POINTS = list(range(36, 42)) # 右眼睛
LEFT_EYE_POINTS = list(range(42, 48)) # 左眼睛
NOSE_POINTS = list(range(27, 35)) # 鼻子
JAW_POINTS = list(range(0, 17)) # 下巴
我们也可以直接使用dlib画出这68个特征点:


代码为:
import dlib
import os
import cv2
predictor_path = "shape_predictor_68_face_landmarks.dat"
png_path = "ceshi.png"
detector = dlib.get_frontal_face_detector()
# dlib预测器
predicator = dlib.shape_predictor(predictor_path)
img1 = cv2.imread(png_path)
dets = detector(img1,1) # 人脸数dets
print("Number of faces detected : {}".format(len(dets)))
for k,d in enumerate(dets):
print("Detection {} left:{} Top: {} Right {} Bottom {}".format(
k,d.left(),d.top(),d.right(),d.bottom()
))
lanmarks = [[p.x,p.y] for p in predicator(img1,d).parts()] # 获取特征点
for idx,point in enumerate(lanmarks):
# 68点的坐标
point = (point[0],point[1])
cv2.circle(img1,point,5,color=(0,0,255)) # 利用cv2.circle给每个特征点画一个圈,共68个
font = cv2.FONT_HERSHEY_COMPLEX_SMALL
cv2.putText(img1,str(idx),point,font,0.5,(0,255,0),1,cv2.LINE_AA) # 对标记点进行递归;
cv2.namedWindow("img",cv2.WINDOW_NORMAL)
cv2.imshow("img",img1)
cv2.waitKey(0)
"""
Number of faces detected : 1
Detection 0 left:161 Top: 162 Right 546 Bottom 547
"""
如果图片中有多张人脸,并且足够清晰,那么检测到多少张人脸,它就会打印出多少张人脸数与位置,并进行相应标记,只不过标记得会比一张人脸更加密集,有点影响观感,所以可以自行测试。
回归正题,首先我们需要初始化提取器以及定义之前写得特征点以及索引:
# 加载训练模型
PREDICTOR_PATH = "shape_predictor_68_face_landmarks.dat"
# 图像放缩因子
SCALE_FACTOR = 1
FEATHER_AMOUNT = 11
FACE_POINTS = list(range(17, 68)) # 脸
MOUTH_POINTS = list(range(48, 61)) # 嘴巴
RIGHT_BROW_POINTS = list(range(17, 22)) # 右眉毛
LEFT_BROW_POINTS = list(range(22, 27)) # 左眉毛
RIGHT_EYE_POINTS = list(range(36, 42)) # 右眼睛
LEFT_EYE_POINTS = list(range(42, 48)) # 左眼睛
NOSE_POINTS = list(range(27, 35)) # 鼻子
JAW_POINTS = list(range(0, 17)) # 下巴
# 选取了左右眉毛、眼睛、鼻子和嘴巴位置的特征点索引
ALIGN_POINTS = (LEFT_BROW_POINTS + RIGHT_EYE_POINTS + LEFT_EYE_POINTS +
RIGHT_BROW_POINTS + NOSE_POINTS + MOUTH_POINTS)
# 选取用于叠加在第一张脸上的第二张脸的面部特征
# 特征点包括左右眼、眉毛、鼻子和嘴巴
OVERLAY_POINTS = [
LEFT_EYE_POINTS + RIGHT_EYE_POINTS + LEFT_BROW_POINTS + RIGHT_BROW_POINTS,
NOSE_POINTS + MOUTH_POINTS,
]
# 定义用于颜色校正的模糊量,作为瞳孔距离的系数
COLOUR_CORRECT_BLUR_FRAC = 0.6
# 实例化脸部检测器
detector = dlib.get_frontal_face_detector()
# 加载训练模型
# 并实例化特征提取器
predictor = dlib.shape_predictor(PREDICTOR_PATH)
# 定义了两个类处理意外
class TooManyFaces(Exception):
pass
class NoFaces(Exception):
pass
im1, landmarks1 = read_im_and_landmarks("dt.jpg")
im2, landmarks2 = read_im_and_landmarks("hc.jpg")
# 选取两组图像特征矩阵中所需要的面部部位
# 计算转换信息,返回变换矩阵
M = transformation_from_points(landmarks1[ALIGN_POINTS],
landmarks2[ALIGN_POINTS])
然后定义检测人脸特征点的代码,这里省略了画特征点以及一些信息的打印,做了一些限制,为了下一步的矩阵转换:
...
# 获取特征点
def get_landmarks(im):
# detector 是特征检测器
# predictor 是特征提取器
rects = detector(im, 1)
# 如果检测到多张脸
if len(rects) > 1:
raise TooManyFaces
# 如果没有检测到脸
if len(rects) == 0:
raise NoFaces
# 返回一个 n*2 维的矩阵,该矩阵由检测到的脸部特征点坐标组成
return np.matrix([[p.x, p.y] for p in predictor(im, rects[0]).parts()])
# 读取图片文件并获取特征点
def read_im_and_landmarks(fname):
# 以 RGB 模式读取图像
im = cv2.imread(fname, cv2.IMREAD_COLOR)
# 对图像进行适当的缩放
im = cv2.resize(im, (im.shape[1] * SCALE_FACTOR,
im.shape[0] * SCALE_FACTOR))
s = get_landmarks(im)
return im, s
...
然后是transformation_from_points 人脸对齐程序,这里的原理是因为我们拿到的特征点的脸型是第一张上面的,如果需要transform到第二张,我们就必须对特征点进行调整,如旋转、平移、缩放,这里参照的公式是:
∑ i = 1 68 ∥ s R p i T + T − q i T ∥ 2 \sum_{i=1}^{68}\left\|s R p_{i}^{T}+T-q_{i}^{T}\right\|^{2} i=1∑68∥∥sRpiT+T−qiT∥∥2
其中,旋转R,平移T,缩放S,第一个人脸关键点是 q i ( i = 1 , 2 , . . . , 68 ) q_{i}(i=1,2,...,68) qi(i=1,2,...,68),第二个人脸关键点是 p i ( i = 1 , 2 , . . . , 68 ) p_{i}(i=1,2,...,68) pi(i=1,2,...,68),关于旋转、平移与缩放,可以看上一篇关于仿射变换的实例,以及作者引用的wiki:
python-opencv学习笔记(九):图像的仿射变换与应用实例
Ordinary Procrustes Analysis
后面这篇需要梯子,它很好的阐述了仿射变换的性质:
The shape of an object can be considered as a member of an equivalence class formed by removing the translational, rotational and uniform scaling components.
并建议当对象是三维时,使用奇异值分解求解找到最佳的旋转R值(see the solution for the constrained orthogonal Procrustes problem, subject to det® = 1),而为什么用奇异值分解,这里可以参考:
奇异值分解总结 (Summary on SVD)
当然也可以不用svd,我看有资料提到了直接使用opencv做透视变换,但效果并不是很好,所以这里不再引述。那么transformer的代码为:
# 计算转换信息,返回矩阵
def transformation_from_points(points1, points2):
points1 = points1.astype(np.float64)
points2 = points2.astype(np.float64)
c1 = np.mean(points1, axis=0)
c2 = np.mean(points2, axis=0)
points1 -= c1
points2 -= c2
s1 = np.std(points1)
s2 = np.std(points2)
points1 /= s1
points2 /= s2
U, S, Vt = np.linalg.svd(points1.T * points2)
R = (U * Vt).T
return np.vstack([np.hstack(((s2 / s1) * R,
c2.T - (s2 / s1) * R * c1.T)),
np.matrix([0., 0., 1.])])
在仿射变换得到矩阵后,我们还需要提取第一张图片需要替换部分的掩膜,并同样进行仿射变换,这里找了半天没找到啥比较好的图,在B站秉着学习的思想逛了一圈舞蹈区,虽然是找到很多,但是当我把两张熟悉的图转换后,我发现还是挺羞耻的,emmm。。。所以与原实验一样,选择Trump:
(4/24修改:川普和佩议长算违规图?那我赶紧拿出了我的偶像练习生与明星图,这应该不会违规了。)


获取右图的脸部掩码,并进行变化,使其和左图相符:
# 绘制凸多边形
def draw_convex_hull(im, points, color):
points = cv2.convexHull(points)
cv2.fillConvexPoly(im, points, color=color)
# 获取面部的掩码
def get_face_mask(im, landmarks):
im = np.zeros(im.shape[:2], dtype=np.float64)
for group in OVERLAY_POINTS:
draw_convex_hull(im,
landmarks[group],
color=1)
im = np.array([im, im, im]).transpose((1, 2, 0))
# 应用高斯模糊
im = (cv2.GaussianBlur(im, (FEATHER_AMOUNT, FEATHER_AMOUNT), 0) > 0) * 1.0
im = cv2.GaussianBlur(im, (FEATHER_AMOUNT, FEATHER_AMOUNT), 0)
return im
...
# 获取 im2 的面部掩码
mask = get_face_mask(im2, landmarks2)
plt.imshow(mask)
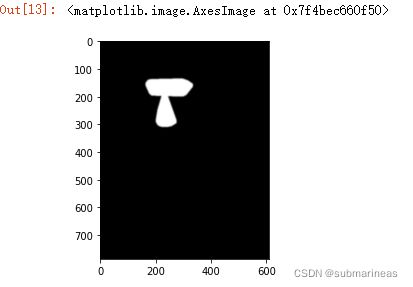
图像掩码作用于原图之后,原图中对应掩码部分为白色的部分才能显示出来,黑色的部分则不予显示,因此通过图像掩码我们就能实现对图像“裁剪”。
由 get_face_mask 获得的图像掩码还不能直接使用,因为一般来讲用户提供的两张图像的分辨率大小很可能不一样,而且即便分辨率一样,图像中的人脸由于拍摄角度和距离等原因也会呈现出不同的大小以及角度,所以如果不能只是简单地把第二个人的面部特征抠下来直接放在第一个人脸上,我们还需要根据两者计算所得的面部特征区域进行匹配变换,使得二者的面部特征尽可能重合。
...
# 变换图像
def warp_im(im, M, dshape):
output_im = np.zeros(dshape, dtype=im.dtype)
# 仿射函数,能对图像进行几何变换
# 三个主要参数,第一个输入图像,第二个变换矩阵 np.float32 类型,第三个变换之后图像的宽高
cv2.warpAffine(im,
M[:2],
(dshape[1], dshape[0]),
dst=output_im,
borderMode=cv2.BORDER_TRANSPARENT,
flags=cv2.WARP_INVERSE_MAP)
return output_im
warped_mask = warp_im(mask, M, im1.shape)
combined_mask = np.max([get_face_mask(im1, landmarks1), warped_mask],
axis=0)
plt.imshow(combined_mask)
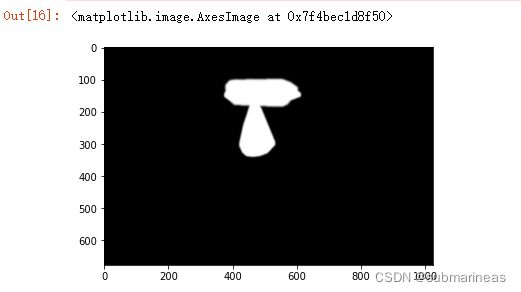
这里将第二幅图根据第一幅图同样做仿射变换,使两张人脸对齐,而我们还可以利用numpy里的multiply方法,将上述得到的掩膜作用于仿射后结果,得到掩膜下的耳鼻喉图:
warped_im2 = warp_im(im2, M, im1.shape)
plt.figure(figsize=[16,16])
plt.subplot(121)
plt.imshow(cv2.cvtColor(warped_im2,cv2.COLOR_BGR2RGB))
plt.subplot(122)
plt.imshow(np.multiply(warped_im2,combined_mask).astype('uint8')[...,::-1])
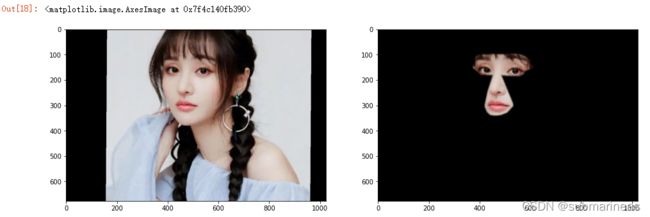
最后我们还需要修改皮肤颜色,使两张图片在拼接时候显得更加自然:
# 修正颜色
def correct_colours(im1, im2, landmarks1):
blur_amount = COLOUR_CORRECT_BLUR_FRAC * np.linalg.norm(
np.mean(landmarks1[LEFT_EYE_POINTS], axis=0) -
np.mean(landmarks1[RIGHT_EYE_POINTS], axis=0))
blur_amount = int(blur_amount)
if blur_amount % 2 == 0:
blur_amount += 1
im1_blur = cv2.GaussianBlur(im1, (blur_amount, blur_amount), 0)
im2_blur = cv2.GaussianBlur(im2, (blur_amount, blur_amount), 0)
# 避免出现 0 除
im2_blur += (128 * (im2_blur <= 1.0)).astype(im2_blur.dtype)
return (im2.astype(np.float64) * im1_blur.astype(np.float64) /
im2_blur.astype(np.float64))
warped_corrected_im2 = correct_colours(im1, warped_im2, landmarks1)
output_im = im1 * (1.0 - combined_mask) + warped_corrected_im2 * combined_mask

emmm,虽然还是很鬼畜,但至少违和感不强了,因为B站之前看过太多建国的视频,本文只是基于特征变换做的一个小demo,需要了解的东西依然还有很多,完整的代码是在开头的GitHub中,运行方式为:
$ python3 face_swap.py <image1> <image2>
之后会考虑深入了解一下人脸识别,以及之前很火的一些人脸GitHub项目,最近发现确实挺有意思的。