【机器视觉案例】(13) 脸部和摄像机间的距离测量,自适应文本大小,附python完整代码
各位同学好,今天和大家分享一下如何使用 opencv+Mediapipe 测量人脸和摄像机镜头之间的距离,并创建一块根据人脸距离变化的文本框。先放张图看效果。
左图是视频图像,显示人脸和摄像机之间的距离distance;右图是文本框,人脸和相机之间距离越近,则字体和行距越小,距离越远,字体和行距越大。

1. 安装工具包
pip install opencv_python==4.2.0.34 # 安装opencv
pip install mediapipe # 安装mediapipe
# pip install mediapipe --user #有user报错的话试试这个
pip install cvzone # 安装cvzone
# 导入工具包
import cv2
import cvzone
from cvzone.FaceMeshModule import FaceMeshDetector # 脸部关键点检测方法
import numpy as np # 用来创建文本框
2. 脸部关键点检测
(1)cvzone.FaceMeshModule.FaceMeshDetector() 人脸关键点检测方法
参数:
staticMode: 默认为 False,将输入图像视为视频流。它将尝试在第一个输入图像中检测人脸,并在成功检测后进一步定位468个关键点的坐标。在随后的图像中,一旦检测到所有 maxFaces 张脸并定位了相应的关键点的坐标,它就会跟踪这些坐标,而不会调用另一个检测,直到它失去对任何一张脸的跟踪。这减少了延迟,非常适合处理视频帧。如果设置为 True,则在每个输入图像上运行脸部检测,用于处理一批静态的、可能不相关的图像。
maxFaces: 最多检测几张脸,默认为 2
minDetectionCon=0.5: 脸部关键点检测模型的最小置信值(0-1之间),超过阈值则检测成功。默认为 0.5
minTrackCon=0.5: 关键点坐标跟踪模型的最小置信值 (0-1之间),用于将手部坐标视为成功跟踪,不成功则在下一个输入图像上自动调用手部检测。将其设置为更高的值可以提高解决方案的稳健性,但代价是更高的延迟。如果 mode 为 True,则忽略这个参数,手部检测将在每个图像上运行。默认为 0.5
(2)cvzone.FaceMeshModule.FaceMeshDetector.findFaceMesh() 找到人脸关键点
参数:
img: 需要检测关键点的帧图像,格式为BGR
draw: 是否需要在原图像上绘制关键点及连线
返回值:
img: 返回绘制了关键点及连线后的图像
faces: 检测到的脸部信息,三维列表,包含每张脸的468个关键点。
(3)距离测量方法
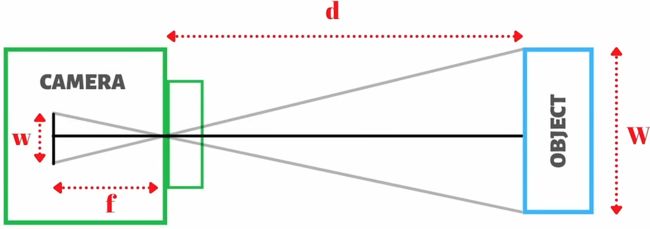
由下图距离测量公式可知,现在要求实际距离 d,可通过相似三角形,利用人脸两眼之间的距离来推算人脸距离摄像机的实际距离。
人两眼之间的实际距离为W=63mm,相机视角下图像上人眼的两个关键点之间的距离w。
在求实时距离 d 之前我们需要知道相机焦距 f,又因为相机焦距 f 是固定不变的,那么我们先以固定的人脸和相机距离计算出 f ,取各个帧 f 的平均值,得到相机焦距
焦距计算公式:![]() ,这里的d是一个固定值
,这里的d是一个固定值
实际距离计算公式:![]() ,使用估算出的焦距的平均值用来计算实时的距离
,使用估算出的焦距的平均值用来计算实时的距离
代码如下:
import cv2
import cvzone
from cvzone.FaceMeshModule import FaceMeshDetector # 脸部关键点检测方法
#(1)读取视频图像
filepath = 'D:/deeplearning/video/eyes.mp4' # 视频文件位置
cap = cv2.VideoCapture(filepath) # 参数填0代表电脑自带摄像头
#(2)脸部关键点检测方法
detector = FaceMeshDetector(maxFaces=1) # 最多检测一张脸
#(3)处理视频图像
while True:
# 图像是否读取成功success,读入的帧图像img
success, img = cap.read() # 每次读取一帧
# 检测脸部关键点,返回绘制关键点后的图像img和脸部关键点坐标faces
img, faces = detector.findFaceMesh(img, draw=False) # 不绘制关键点
print(faces)
#(4)处理关键点
if faces: # 如果检测到了,那就接下去执行
face = faces[0] # faces是三维列表,我们只需要第一张脸的所有关键点
pointLeft = tuple(face[145]) # 左眼关键点坐标
pointRight = tuple(face[374]) # 右眼坐标
# 绘制两个关键点之间的连线
cv2.line(img, pointLeft, pointRight, (0,255,0), 3)
# 在关键点坐标上绘制圆。注意圆心坐标是元组类型tuple
cv2.circle(img, pointLeft, 5, (0,255,255), cv2.FILLED)
cv2.circle(img, pointRight, 5, (0,255,255), cv2.FILLED)
# 计算两点之间的线段距离w,相当于勾股定理求距离
w, _ = detector.findDistance(pointRight, pointLeft) # 返回线段距离和线段信息(两端点和中点的坐标)
#print(w)
# 计算焦距
W = 6.3 # 人脸两眼之间的平均距离是6.3cm
d = 40 # 当前人脸距屏幕的距离
f = (w*d)/W # 根据公式计算焦距
print(f'foucus:{f}') # 打印所有焦距,取平均值,作为模型的焦距
#(5)图像展示
cv2.imshow('img', img)
k = cv2.waitKey(10) # 每帧延迟1毫秒后消失
if k & 0xFF == 27: # 键盘上的ESC键退出循环
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()效果图如下:左图是detector.findFaceMesh(img, draw=True)时检测出的人脸关键点和连线,我们只需要用到两眼之间的距离。如右图,设置参数draw=True,不绘制人脸网,只绘制两眼之间的连线。
3. 距离测量,制作自适应文本框
在上一节中我们以实际距离d=40cm,计算出了每一帧图像的相机焦距,取其平均值 f=700 作为相机焦距计算实时的人脸距离 ![]() 。使用 cvzone.putTextRect() 函数将距离值显示在人脸额头部位。
。使用 cvzone.putTextRect() 函数将距离值显示在人脸额头部位。
接下来创建一个和帧图像相同size的,像素值全为0(黑色)的图像 np.zeros_like(img),作为显示文本的底板。
如下面代码中的第(4)步,singleHeight = 50 + int(d/2) 每行文本初始距离为50,根据人脸距离实时变化。scale = 1 + int(d/20) 文本字体的大小初始是1,根据人脸距离动态调整
在上述代码中补充:
import cv2
import cvzone
from cvzone.FaceMeshModule import FaceMeshDetector # 脸部关键点检测方法
import numpy as np # 用来创建文本框
#(1)读取视频图像
filepath = 'D:/deeplearning/video/eyes.mp4' # 视频文件位置
cap = cv2.VideoCapture(filepath) # 参数填0代表电脑自带摄像头
#(2)配置
# 脸部检测方法
detector = FaceMeshDetector(maxFaces=1) # 最多检测一张脸
# 文本框中的内容
textList = ['anukbcxasxxa4525',
'xnsailcnau22222',
'xbuikuysalbxsalb',
'cinaxsabkcnaskmc',
'4861581816158151']
#(3)处理视频图像
while True:
# 图像是否读取成功success,读入的帧图像img
success, img = cap.read() # 每次读取一帧
# 创建文本图像,一张黑板
imgText = np.zeros_like(img) # 创建一个size和img相同的黑色图像
# 检测脸部关键点,返回绘制关键点后的图像img和脸部关键点坐标faces
img, faces = detector.findFaceMesh(img, draw=False) # 不绘制关键点
#(4)处理关键点
if faces: # 如果检测到了,那就接下去执行
face = faces[0] # faces是三维列表,我们只需要第一张脸的所有关键点
pointLeft = tuple(face[145]) # 左眼关键点坐标
pointRight = tuple(face[374]) # 右眼坐标
# 计算两点之间的线段距离w,相当于勾股定理求距离
w, _ = detector.findDistance(pointRight, pointLeft) # 返回线段距离和线段信息(两端点和中点的坐标)
W = 6.3 # 人脸两眼之间的实际平均距离是6.3cm
f = 700 # 上一节的代码求焦距,估计一个平均值,作为当前的焦距
# 计算人脸距离屏幕的距离
d = (W*f)/w
print('distance face to screen:', d)
# 将距离显示在屏幕上,face[10]代表额头的坐标点,scale矩形框大小,thickness文字大小
cvzone.putTextRect(img, f'distace:{int(d)}cm', (face[10][0]-100,face[10][1]),
scale=2, thickness=3, colorR=(255,255,0), colorT=(0,0,0))
#(4)编写文本
for i, text in enumerate(textList):
singleHeight = 50 + int(d/2) # 动态调整文本每行之间的距离
scale = 1 + int(d/20) # 根据脸和摄像机之间的距离调整字体大小
# 控制每条文本之间的行间距i*singleHeight,scale动态改变字体大小
cv2.putText(imgText, text, (50,100+i*singleHeight),
cv2.FONT_ITALIC, scale, (255,255,255), 2)
#(5)图像展示
img = cv2.resize(img, (800,450))
imgText = cv2.resize(imgText, (800,450))
# 将两张图像组合在一起,排2列,组合后size不变
imgStacked = cvzone.stackImages([img, imgText], cols=2, scale=1)
cv2.imshow('imgStacked', imgStacked)
k = cv2.waitKey(20) # 每帧延迟1毫秒后消失
if k & 0xFF == 27: # 键盘上的ESC键退出循环
break
# 释放视频资源
cap.release()
cv2.destroyAllWindows()效果图如下,人脸距离摄像机越近,则文本越小;人脸距离摄像机越远,则字体越大。