NLP-文本处理:拼写纠错【非词(编辑距离)、真词(编辑距离...)候选词 -> “噪音通道模型”计算候选词错拼成待纠错词的似然概率 -> N-gram模型评估候选词组成的语句合理性】

一、贝叶斯公式

1、单事件
P ( A x ∣ B ) P(A_x|B) P(Ax∣B) = P ( A x B ) P ( B ) = P ( B ∣ A x ) × P ( A x ) P ( B ) = P ( B ∣ A x ) × P ( A x ) ∑ i = 0 n [ P ( B ∣ A i ) ∗ P ( A i ) ] =\frac{P(A_xB)}{P(B)}=\frac{P(B|A_x)×P(A_x)}{P(B)}=\frac{P(B|A_x)×P(A_x)}{\sum_{i=0}^n[P(B|A_i)*P(A_i)]} =P(B)P(AxB)=P(B)P(B∣Ax)×P(Ax)=∑i=0n[P(B∣Ai)∗P(Ai)]P(B∣Ax)×P(Ax)
= A x 条 件 下 B 的 似 然 度 × A x 的 先 验 概 率 事 件 B 的 先 验 概 率 =\frac{A_x条件下B的似然度 × A_x的先验概率}{事件B的先验概率} =事件B的先验概率Ax条件下B的似然度×Ax的先验概率
= A x 条 件 下 B 的 似 然 度 × A x 的 先 验 概 率 ∑ i = 0 n ( A i 条 件 下 B 的 似 然 度 × A i 的 先 验 概 率 ) =\frac{A_x条件下B的似然度 × A_x的先验概率}{\sum_{i=0}^n(A_i条件下B的似然度 × A_i的先验概率)} =∑i=0n(Ai条件下B的似然度×Ai的先验概率)Ax条件下B的似然度×Ax的先验概率
= A x 条 件 下 B 的 似 然 度 × A x 的 先 验 概 率 边 际 似 然 度 =\frac{A_x条件下B的似然度 × A_x的先验概率}{边际似然度} =边际似然度Ax条件下B的似然度×Ax的先验概率
= A x 条 件 下 B 的 似 然 度 × A x 的 先 验 概 率 标 准 化 常 量 =\frac{A_x条件下B的似然度 × A_x的先验概率}{标准化常量} =标准化常量Ax条件下B的似然度×Ax的先验概率
= 标 准 似 然 度 × 先 验 概 率 =标准似然度 × 先验概率 =标准似然度×先验概率
- P ( A x ∣ B ) P(A_x|B) P(Ax∣B)是已知事件 B B B发生的情况下事件 A x A_x Ax发生的概率(条件概率),也由于得自 B B B的取值而被称为 A x A_x Ax的后验概率;
- P ( B ∣ A x ) P(B|A_x) P(B∣Ax)是已知事件 A x A_x Ax发生的情况下事件 B B B发生的概率,称为似然度/似然概率(likehood);
- A 1 A_1 A1, A 2 A_2 A2, …, A i A_i Ai, … , A x A_x Ax, …, A j A_j Aj, …, A n A_n An为完备事件组,即 ⋃ i = 1 n \bigcup_{i=1}^n ⋃i=1n= Ω \Omega Ω, A i A j = ϕ A_iA_j =\phi AiAj=ϕ, P ( A i ) > 0 P(A_i) > 0 P(Ai)>0;
- P ( A x ) P(A_x) P(Ax):先验概率,之所以称为"先验"是因为它为不需要考虑任何事件 B B B方面的因素的情况下事件 A x A_x Ax发生的概率;
- P ( B ) P(B) P(B):边际似然度,当给定 A i A_i Ai时, A i A_i Ai能解释 B B B的可能性,这就反应了事件 B B B的似然性,将所有 A i A_i Ai条件下事件B分别发生的概率相加得到事件 B B B的边际似然概率,它是一个标准化常量;
- P ( B ∣ A x ) P ( B ) \frac{P(B|A_x)}{P(B)} P(B)P(B∣Ax) 称为标准似然度;
- 后验概率 ∝ 似然度 × 先验概率
- 在贝叶斯概率理论中,如果后验概率 P ( A x ∣ B ) P(A_x|B) P(Ax∣B) 与 先验概率 P ( A x ) P(A_x) P(Ax) 满足同样的分布律,则 先验分布与后验分布被叫做“共轭分布”,同时,先验分布叫做似然函数的“共轭先验分布”。
2、联合事件
P [ A x ∣ ( B 1 , B 2 , . . . B i ) ] P[A_x|(B_1, B_2, ...B_i)] P[Ax∣(B1,B2,...Bi)] = P [ ( B 1 , B 2 , . . . B i ) ∣ A x ] × P ( A x ) ∑ i = 0 n { P [ ( B 1 , B 2 , . . . B i ) ∣ A i ] ∗ P ( A i ) } =\frac{P[(B_1, B_2, ...B_i)|A_x]×P(A_x)}{\sum_{i=0}^n\{P[(B_1, B_2, ...B_i)|A_i]*P(A_i)\}} =∑i=0n{P[(B1,B2,...Bi)∣Ai]∗P(Ai)}P[(B1,B2,...Bi)∣Ax]×P(Ax)
= A x 条 件 下 ( B 1 , B 2 , . . . B i ) 的 似 然 度 × A x 的 先 验 概 率 事 件 ( B 1 , B 2 , . . . B i ) 的 先 验 概 率 =\frac{A_x条件下(B_1, B_2, ...B_i)的似然度 × A_x的先验概率}{事件(B_1, B_2, ...B_i)的先验概率} =事件(B1,B2,...Bi)的先验概率Ax条件下(B1,B2,...Bi)的似然度×Ax的先验概率
= A x 条 件 下 ( B 1 , B 2 , . . . B i ) 的 似 然 度 × A x 的 先 验 概 率 ∑ i = 0 n ( A i 条 件 下 ( B 1 , B 2 , . . . B i ) 的 似 然 度 × A i 的 先 验 概 率 ) =\frac{A_x条件下(B_1, B_2, ...B_i)的似然度 × A_x的先验概率}{\sum_{i=0}^n(A_i条件下(B_1, B_2, ...B_i)的似然度 × A_i的先验概率)} =∑i=0n(Ai条件下(B1,B2,...Bi)的似然度×Ai的先验概率)Ax条件下(B1,B2,...Bi)的似然度×Ax的先验概率
= A x 条 件 下 ( B 1 , B 2 , . . . B i ) 的 似 然 度 × A x 的 先 验 概 率 边 际 似 然 度 =\frac{A_x条件下(B_1, B_2, ...B_i)的似然度 × A_x的先验概率}{边际似然度} =边际似然度Ax条件下(B1,B2,...Bi)的似然度×Ax的先验概率
= A x 条 件 下 ( B 1 , B 2 , . . . B i ) 的 似 然 度 × A x 的 先 验 概 率 标 准 化 常 量 =\frac{A_x条件下(B_1, B_2, ...B_i)的似然度 × A_x的先验概率}{标准化常量} =标准化常量Ax条件下(B1,B2,...Bi)的似然度×Ax的先验概率
= 标 准 似 然 度 × 先 验 概 率 =标准似然度 × 先验概率 =标准似然度×先验概率
事件 B 1 , B 2 , . . . B i B_1, B_2, ...B_i B1,B2,...Bi之间有可能是独立的,也可能是相关的。
-
如果 B 1 , B 2 , . . . B i B_1, B_2, ...B_i B1,B2,...Bi之间相互独立,则
P [ ( B 1 , B 2 , . . . B i ) ∣ A x ] = P ( B 1 ∣ A x ) × P ( B 2 ∣ A x ) × . . . P ( B i ∣ A x ) P[(B_1, B_2, ...B_i)|A_x]=P(B_1|A_x)×P(B_2|A_x)×...P(B_i|A_x) P[(B1,B2,...Bi)∣Ax]=P(B1∣Ax)×P(B2∣Ax)×...P(Bi∣Ax)
-
如果 B 1 , B 2 , . . . B i B_1, B_2, ...B_i B1,B2,...Bi之间相关,则
P [ ( B 1 , B 2 , . . . B i ) ∣ A x ≠ P ( B 1 ∣ A x ) × P ( B 2 ∣ A x ) × . . . P ( B i ∣ A x ) P[(B_1, B_2, ...B_i)|A_x≠P(B_1|A_x)×P(B_2|A_x)×...P(B_i|A_x) P[(B1,B2,...Bi)∣Ax=P(B1∣Ax)×P(B2∣Ax)×...P(Bi∣Ax)
3、根据贝叶斯公式计算候选词概率
根据: P ( w i ∣ x j ) ⋅ P ( x j ) = P ( x j ∣ w i ) P ( w i ) P(w_i|x_j)·P(x_j)=P(x_j|w_i)P(w_i) P(wi∣xj)⋅P(xj)=P(xj∣wi)P(wi)
得出以下结论:
w i ^ = arg max w i ∈ V P ( w i ∣ x j ) = 贝 叶 斯 公 式 arg max w i ∈ V P ( x j ∣ w i ) P ( w i ) P ( x j ) = arg max w i ∈ V P ( x j ∣ w i ) P ( w i ) \begin{aligned} \hat{w_i}&=\argmax_{w_i∈V}P(w_i|x_j)\\ &\xlongequal[]{贝叶斯公式}\argmax_{w_i∈V}\cfrac{P(x_j|w_i)P(w_i)}{P(x_j)}\\ &=\argmax_{w_i∈V}P(x_j|w_i)P(w_i) \end{aligned} wi^=wi∈VargmaxP(wi∣xj)贝叶斯公式wi∈VargmaxP(xj)P(xj∣wi)P(wi)=wi∈VargmaxP(xj∣wi)P(wi)
- x j x_j xj:表示 noisy word(即splling error)被看作original word通过noisy channel转换得到;
- P ( x j ∣ w i ) P(x_j|w_i) P(xj∣wi):表示“候选词 w i w_i wi 拼写成 x j x_j xj(“非词”/“真词”)的似然概率”【噪音通道模型】
- 如果 x i x_i xi 是非词,则 x i x_i xi 的候选词 w i w_i wi 集合中不包括 x i x_i xi自身;
- 如果 x i x_i xi 是真词,则 x i x_i xi 的候选词 w i w_i wi 集合中包括 x i x_i xi自身;
- 这些似然概率 p ( x i ∣ w i ) p(x_i|w_i) p(xi∣wi) 组成一个转移概率矩阵【噪音通道模型】,“转移概率矩阵” 可以基于“训练语料库”进行统计后建立(又称error model/错误模型,channel model/噪音通道)得到;
- 如果 x i x_i xi 是非词,则 x i x_i xi 的候选词 w i w_i wi 集合中不包括 x i x_i xi自身;
- P ( w i ) P(w_i) P(wi):表示当前句子中单词 w i w_i wi 的先验概率【N-gram模型】
- 可以基于【训练语料库】建立【语言模型(N-gram模型)】得到;
- P ( w i ) = C ( w i − 1 w i ) C ( w i − 1 ) P(w_i)=\cfrac{C(w_{i-1}w_i)}{C(w_{i-1})} P(wi)=C(wi−1)C(wi−1wi), C ( w i − 1 w i ) C(w_{i-1}w_i) C(wi−1wi)表示语料库中单词序列( w i − 1 w i w_{i-1}w_i wi−1wi)出现的总数量, C ( w i − 1 ) C(w_{i-1}) C(wi−1)表示语料库中单词序列( w i − 1 w_{i-1} wi−1)出现的总数量;
英文拼写纠错一般可以拆分成两个子任务:
- Spelling Error Detection(拼写错误检测):按照错误类型不同,分为:
- Non-word Errors(非词错误):指那些拼写错误后的词本身就不合法,如错误的将“giraffe”写成“graffe”;
- Real-word Errors(真词错误):指那些拼写错误后的词仍然是合法的情况,如将“there”错误拼写为“three”(形近),将“peace”错误拼写为“piece”(同音),将“two”错误拼写为“too”(同音)。
- Spelling Error Correction(拼写错误纠正):自动纠错,如把“hte”自动校正为“the”,或者给出一个最可能的拼写建议,甚至一个拼写建议列表。
三、确认“非词错误”、“真词错误”的候选词
1、确认“非词错误”(Non-word Errors)的候选词
非词错误检测:任何不被词典所包含的word均被当作spelling error,识别准确率依赖词典的规模和质量。因此字典本身越大越好。
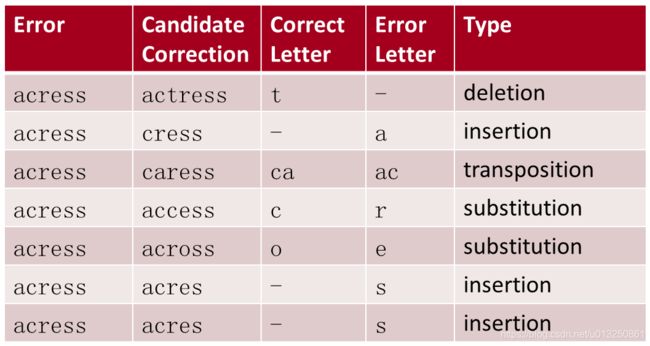
给定拼写错误“acress”,首先通过词典匹配容易确定为“Non-word spelling error”;通过计算 “最小编辑距离” 获取最相似的“候选词”(Candidate Correction)。

需要特别说明的是,这里的最小编辑距离涉及四种操作:
- Insertion
- Deletion
- Substitution
- Transposition of two adjacent letters
据统计,80%的拼写错误编辑距离为1,几乎所有的拼写错误编辑距离小于等于2,基于此,可以减少大量不必要的计算。
对于非词错误,通过计算 “最小编辑距离” 获取拼写建议候选集 W W W。
2、确认“真词错误”(Real-word Errors)的候选词
Kukich(1992)指出有25%~40%的拼写错误都属于Real-word类型,与Non-word类型相比,纠错难度更大,因为句子中的每个word都被当作待纠错对象。因此我们要对句子中的每一个单词都产生一个候选集,包括:
- 该词本身
- 拼写相似的词(“最小编辑距离” 为1、2的英文单词)
- 跟该词发音相似的词
- 同音异形词
给定一个句子包含一系列单词 ( w 1 , w 2 , w 3 , … , w n ) (w_1,w_2,w_3,…,w_n) (w1,w2,w3,…,wn),对每个单词都生成一系列的候选词(candidate):
C a n d i d a t e ( w 1 ) = { w 1 , w 1 1 , w 1 2 , w 1 3 , . . . } C a n d i d a t e ( w 2 ) = { w 2 , w 2 1 , w 2 2 , w 2 3 , . . . } . . . C a n d i d a t e ( w 1 ) = { w n , w n 1 , w n 2 , w n 3 , . . . } \begin{aligned} Candidate(w_1)=\{w_1,w_1^1,w_1^2,w_1^3,...\}\\ Candidate(w_2)=\{w_2,w_2^1,w_2^2,w_2^3,...\}\\ ...\\ Candidate(w_1)=\{w_n,w_n^1,w_n^2,w_n^3,...\}\\ \end{aligned} Candidate(w1)={w1,w11,w12,w13,...}Candidate(w2)={w2,w21,w22,w23,...}...Candidate(w1)={wn,wn1,wn2,wn3,...}
找到候选词集合 W W W 之后,我们希望选择概率最大的候选词 w i w_i wi 作为最终的拼写建议,需要进一步计算各个候选词的:
- 似然概率 : P ( x j ∣ w i ) P(x_j|w_i) P(xj∣wi)
- 先验概率: P ( w i ) P(w_i) P(wi)
四、噪音通道模型:计算候选词的似然概率 P ( x j ∣ w i ) P(x_j|w_i) P(xj∣wi)
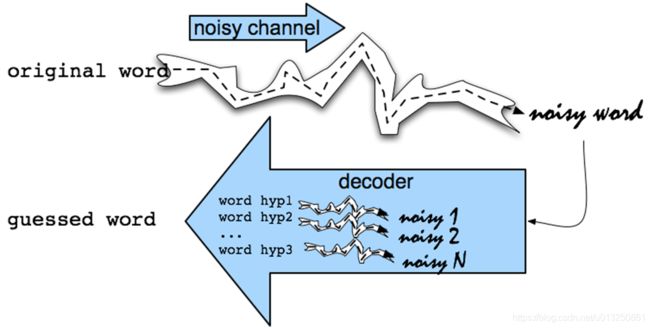
噪音通道模型(Noisy Channel Model):或称信源信道模型,这是一个普适性的模型,被用于语音识别、拼写纠错、机器翻译、中文分词、词性标注、音字转换等众多应用领域。其形式很简单,如下图所示:

噪声信道试图通过带噪声的输出信号恢复输入信号,形式化定义为:
![]()
应用于拼写纠错任务的流程如下:
1、构建 “混淆矩阵”(Confusion Matrix)【第三方机构已有成熟数据】
混淆矩阵(Confusion Matrix)就是基于已有数据统计的各种类型拼写错误(非词错误&真词错误)的似然概率分别的集合:
- del拼写错误的似然概率集合;
- ins拼写错误的似然概率集合;
- sub拼写错误的似然概率集合;
- trans拼写错误的似然概率集合;
基于大量的行业应用中累积下来的 < x i , w i >
可以用下图中的公式计算del、ins、sub和trans四种转移矩阵,然后求得转移概率 P ( x ∣ w ) P(x|w) P(x∣w)

- p ( x ∣ w ) p(x|w) p(x∣w) 从理解上来看,就是:给定一个正确的候选单词 w w w 的条件下,导致错误单词 x x x 的概率有多大;
- 其中的 w i w_i wi、 x i x_i xi 指代的是字母,而不再是单词
噪声通道模型的任务则是模拟人输错单词的过程,从而计算出错词的概率。人输错单词的原因有很多,比如敲键盘的时候手滑,将单词的顺序颠倒或者将a打成了s,也有可能是单词拼写出现偏差将a记成了e。
模型通过大量样本对这些错误进行统计分析,而后根据频率对每种错误的概率赋值。如下图中即是英文26个字母互相输错的频次表。数据显示读音类似的字母尤其容易被记错,这也与我们通常按音节记单词的习惯相合。
构建噪声通道模型(channel model)需要用到日常生活中用到的知识经验,或者行业应用中累积下来的数据(经验)。如果我们收集了足够多的数据,比如观察了很多用户一共输入了(打字)1万次 w w w,其中有10次 输入成了 x x x(打字打成了 x x x),那么 p ( x ∣ w ) = 0.0001 p(x|w)=0.0001 p(x∣w)=0.0001
编辑距离为1的错误可以被分为以下四类:

- d e l [ w i − 1 , w i ] del{[w_{i-1},w_i]} del[wi−1,wi]表示在del转移矩阵中 w i − 1 , w i w_{i-1},w_i wi−1,wi间转移的数量; c o u n t [ w i − 1 , w i ] count[w_{i-1},w_i] count[wi−1,wi]表示 w i − 1 w i w_{i-1}w_i wi−1wi字母串在通过训练集构建的词典中出现的总数量;
- i n s [ w i − 1 , w i ] ins{[w_{i-1},w_i]} ins[wi−1,wi]表示在ins转移矩阵中 w i − 1 , w i w_{i-1},w_i wi−1,wi间转移的数量; c o u n t [ w i − 1 ] count[w_{i-1}] count[wi−1]表示 w i − 1 w_{i-1} wi−1字母在通过训练集构建的词典中出现的总数量;
- s u b [ x i , w i ] sub{[x_i,w_i]} sub[xi,wi]表示在ins转移矩阵中 x i , w i x_i,w_i xi,wi间转移的数量; c o u n t [ w i ] count[w_i] count[wi]表示 w i w_i wi字母在通过训练集构建的词典中出现的总数量;
- t r a n s [ w i , w i + 1 ] trans{[w_i,w_{i+1}]} trans[wi,wi+1]表示在trans转移矩阵中 w i w_i wi 与 w i + 1 w_{i+1} wi+1间交换的数量(将 w i w_i wi 与 w i + 1 w_{i+1} wi+1 交换后,就变成了一个错误的单词了); c o u n t [ w i , w i + 1 ] count[w_i,w_{i+1}] count[wi,wi+1]表示 w i w i + 1 w_iw_{i+1} wiwi+1字母串在通过训练集构建的词典中出现的总数量;
把这些数据统计起来,放在一个表里面,这个表称为:混淆矩阵(Confusion Matrix)。
对这四种编辑公式,我们分别构造混淆矩阵,一共是四个混淆矩阵,形如下图:

- insert转移矩阵

- sub转移矩阵

- del转移矩阵

- trans转移矩阵

比如网站(Corpora of misspellings for download)就有一系列的”错误单词的统计数据“。

那么根据 confusion matrix,就能计算 似然函数的概率了(也即能求解 channel model 了)。
2、根据 “混淆矩阵”(Confusion Matrix)计算候选词的似然概率 P ( x j ∣ w i ) P(x_j|w_i) P(xj∣wi)
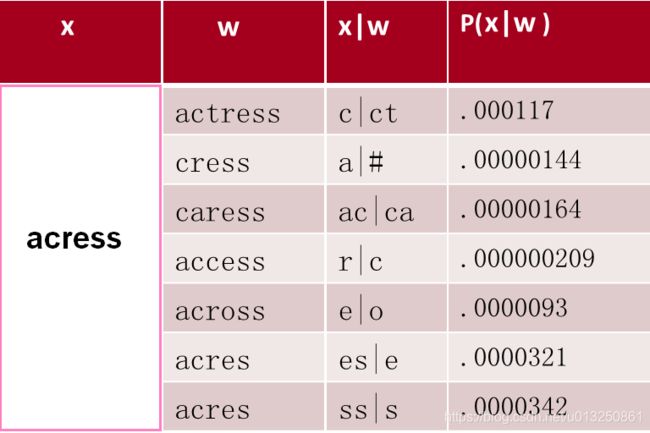
在这句话中“. . . was called a stellar and versatile acress whose combination of sass and glamour has defined her. . .”,有一个错误的单词:acress
通过噪音通道模型计算出来的概率最大的候选词如下:actress, cress, caress, access, across, acres, acres
对于错误的单词 acress,根据下面的7个候选单词计算出来的 似然概率 P ( x ∣ w ) P(x|w) P(x∣w) 如下图:

上图中,第一行表示,其中一个正确的候选单词是 actress,正确的字母是 t,由于某种原因(键盘输入太快了,漏打了t,本来是输入ct 的,结果输入成了c ),统计到的这种情形出现的概率是0.000117 。这种原因,其实就是一个deleteion操作而导致的错误。
五、N-gram模型:计算候选词的先验概率 P ( w i ) P(w_i) P(wi)
通过对语料库计数、平滑等处理可以很容易建立语言模型,即可得到P(w)。N-gram模型给出的候选词的概率 P ( w o r d ) P(word) P(word) 更像是统计学意义下的先验概率。
1、Unigram Model
对于unigram model而言,其中 c ( w 1 , . . , w n ) c(w_1,..,w_n) c(w1,..,wn)表示 n-gram w 1 , . . , w n w_1,..,w_n w1,..,wn 在训练语料中出现的次数, M M M 是语料库中的总字数(例如对于 yes no no no yes 而言, M = 5 M=5 M=5)
P ( w i ) = C ( w i ) M P(w_i)=\cfrac{C(w_i)}{M} P(wi)=MC(wi)
如下表所示,计算Unigram Prior Probability(word总数:404,253,213)
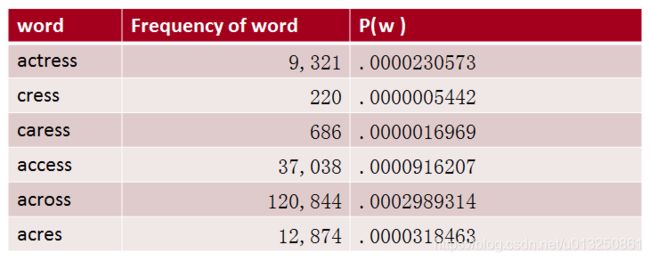
2、Bigram Model
P ( w i ∣ w i − 1 ) = C ( w i − 1 w i ) C ( w i − 1 ) P(w_i|w_{i−1})=\cfrac{C(w_{i−1}w_i)}{C(w_{i−1})} P(wi∣wi−1)=C(wi−1)C(wi−1wi)
假设现在有一个语料库,我们统计了下面一些词出现的数量

下面这个表给出的是基于Bigram模型进行计数之结果

例如,其中第一行,第二列 表示给定前一个词是 “i” 时,当前词为“want”的情况一共出现了827次。因为我们从表1中知道 “i” 一共出现了2533次,而其后出现 “want” 的情况一共有827次,所以:
P ( w a n t ∣ i ) = C ( i w a n t ) C ( i ) = 827 2533 = 0.33 P(want|i)=\cfrac{C(i\ want)}{C(i)}=\cfrac{827}{2533}=0.33 P(want∣i)=C(i)C(i want)=2533827=0.33
据此,我们便可以算得相应的频率分布表如下。

现在设 s 1 s1 s1=“i want english food” ,下面这个概率作为其他一些已知条件给出:
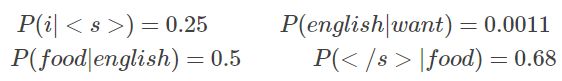
则可以算得

3、Trigram Model
P ( w i ∣ w i − 2 , w i − 1 ) = C ( w i − 2 w i − 1 w i ) C ( w i − 2 w i − 1 ) P(w_i|w_{i−2},w_{i−1})=\cfrac{C(w_{i−2}w_{i−1}w_i)}{C(w_{i−2}w_{i−1})} P(wi∣wi−2,wi−1)=C(wi−2wi−1)C(wi−2wi−1wi)
来看一个具体的例子,假设我们现在有一个语料库如下,其中
下面我们的任务是来评估如下这个句子的概率:
我们来演示利用trigram模型来计算概率的结果
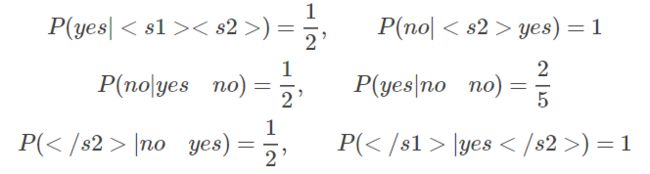
所以我们要求的概率就等于:

4、N-gram Model
P ( w i ∣ w i − n − 1 , ⋯ , w i − 1 ) = C ( w i − n − 1 ⋯ w i ) C ( w i − n − 1 ⋯ w i − 1 ) P(w_i|w_{i−n−1},⋯,w_{i−1})=\cfrac{C(w_{i−n−1}⋯w_i)}{C(w_{i−n−1}⋯w_{i−1})} P(wi∣wi−n−1,⋯,wi−1)=C(wi−n−1⋯wi−1)C(wi−n−1⋯wi)
六、噪音通道模型 & N-gram模型:计算候选词最终概率 P ( x j ∣ w i ) ⋅ P ( w i ) P(x_j|w_i)·P(w_i) P(xj∣wi)⋅P(wi)
1、最终候选词的确定
对于句子( w 1 , w 2 , w 3 , w 4 w_1,w_2,w_3,w_4 w1,w2,w3,w4)中的每一个单词 w i w_i wi(“非词”、“真词” )分别一系列候选单词 W W W,
- 如果 w i w_i wi 为非词错误,则 C a n d i d a t e ( w i ) = { w i 1 , w i 2 , w i 3 , . . . } Candidate(w_i)=\{w_i^1,w_i^2,w_i^3,...\} Candidate(wi)={wi1,wi2,wi3,...},其中的候选词是通过编辑距离确定的;
- 如果 w i w_i wi 为真词,则 C a n d i d a t e ( w i ) = { w i , w i 1 , w i 2 , w i 3 , . . . } Candidate(w_i)=\{w_i,w_i^1,w_i^2,w_i^3,...\} Candidate(wi)={wi,wi1,wi2,wi3,...},其中的候选词包括:该词本身、拼写相似的词(“最小编辑距离” 为1、2的英文单词)、跟该词发音相似的词、同音异形词。

最后确定的每一个单词 w i w_i wi(“非词”、“真词” )的候选词的组合使得整个句子的概率最大。
2、化简版:每个句子一个错误【遍历到当前单词时,假设当前词错误,且句子其他单词都是正确的】

假设遍历当前句子时,该句子里面只有当前一个单词出现了错误,只对一个单词进行纠正。计算当前单词所有候选词的N-gram概率得分,选择概率最大的那个候选词。然后继续遍历该句中的下一个单词。
计算 P ( w ) ⋅ P ( x ∣ w ) P(w)·P(x|w) P(w)⋅P(x∣w) 如下:
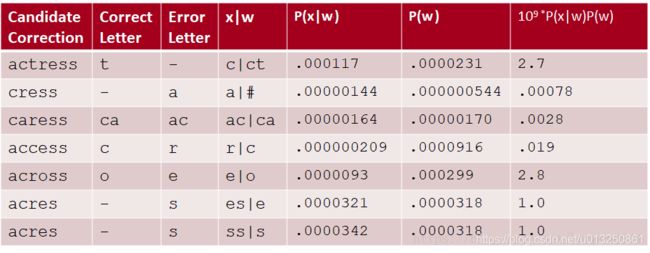
“across”相比其他candidate可能性更大。
上面建立语言模型时采用了unigram,也可以推广到bigram,甚至更高阶,以较好的融入上下文信息。
在这句话中“. . . was called a stellar and versatile acress whose combination of sass and glamour has defined her. . .”
将acress分别替换为候选词actress、across后,计算Bigram为:
P ( a c t r e s s ∣ v e r s a t i l e ) = 0.000021 P(actress|versatile)=0.000021 P(actress∣versatile)=0.000021, P ( w h o s e ∣ a c t r e s s ) = 0.0010 P(whose|actress) = 0.0010 P(whose∣actress)=0.0010
P ( a c r o s s ∣ v e r s a t i l e ) = 0.000021 P(across|versatile) =0.000021 P(across∣versatile)=0.000021, P ( w h o s e ∣ a c r o s s ) = 0.000006 P(whose|across) = 0.000006 P(whose∣across)=0.000006
则联合概率为:
P ( “ v e r s a t i l e a c t r e s s w h o s e ” ) = 0.000021 × 0.0010 = 210 × 1 0 − 10 P(“versatile\ actress\ whose”) = 0.000021×0.0010 = 210 ×10^{-10} P(“versatile actress whose”)=0.000021×0.0010=210×10−10
P ( “ v e r s a t i l e a c r o s s w h o s e ” ) = 0.000021 × 0.000006 = 1 × 1 0 − 10 P(“versatile\ across\ whose”) = 0.000021×0.000006 = 1 ×10^{-10} P(“versatile across whose”)=0.000021×0.000006=1×10−10
“actress”相比“across”可能性更大。
七、英文单词拼写纠错案例
1、英文单词拼写纠错【按词频排序取最大概率的候选词】
vocab.txt
#==== 加载带有概率的词库 ====
word_freq_list = list(set([line.rstrip() for line in open('vocab.txt')])) #用set效率高一些(时间复杂度)
vocab = {}
for word_freq in word_freq_list:
word, freq = word_freq.split("\t")
vocab[word] = int(freq)
# print("vocab_dict = {0}".format(vocab))
# Probability of `word
def P(word, N=sum(vocab.values())):
return vocab[word] / N
# 生成单词的所有候选集合【给定输入(错误地输入)的单词,由编辑距离的4种操作(insert, delete, replace,transposes),返回该单词所有候选集合。返回所有(valid)候选集合】
def edits1(word): # word: 给定的输入(错误的输入)
# 生成编辑距离不大于1的单词
# 1.insert 2. delete 3. replace 4. transposes
# appl: replace: bppl, cppl, aapl, abpl...
# insert: bappl, cappl, abppl, acppl....
# delete: ppl, apl, app
# transposes:papl
letters = 'abcdefghijklmnopqrstuvwxyz' # 假设使用26个字符
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)] # 将单词在不同的位置拆分成2个字符串,然后分别进行insert,delete你replace操作,拆分形式为:[('', 'apple'), ('a', 'pple'), ('ap', 'ple'), ('app', 'le'), ('appl', 'e'), ('apple', '')]
inserts = [L + c + R for L, R in splits for c in letters] # insert操作
deletes = [L + R[1:] for L, R in splits if R] # delete操作:判断分割后的字符串R是否为空,不为空,删除R的第一个字符即R[1:]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters] # replace操作:替换R的第一个字符,即c+R[1:]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R) > 1] # transposes操作:交换R的第一个字符与第二个字符
edit1_words = list(set(inserts + deletes + replaces + transposes))
return edit1_words
# 给定一个字符串,生成编辑距离不大于2的字符串【在生成的与正确单词编辑距离不大于1的单词的基础上,再次进行insert, delete, replace操作,从而生成编辑距离不大于2的所有候选集合】
def edits2(word):
edit2_words = [e2 for e1 in edits1(word) for e2 in edits1(e1)]
return edit2_words
# 检查单词是否是单词库中的拼写正确的单词【过滤掉不存在于词典库里面的单词】
def known(edit_words):
return list(set(edit_word for edit_word in edit_words if edit_word in vocab))
#==== 根据编辑距离为1返回候选词【在单词库中存在的】 ====
def candidates_1(word):
original_word = [word] # 原单词
edit1_words = edits1(word) # 编辑距离为1的候选字符串
known_original_word = known(original_word) # 过滤掉不存在于词典库里面的单词
known_edit1_words = known(edit1_words) # 过滤掉不存在于词典库里面的单词
candidates = known_original_word + known_edit1_words
# print("len(original_word) = {0}----original_word = {1}".format(len(original_word), original_word))
# print("len(edit1_words) = {0}----edit1_words = {1}".format(len(edit1_words), edit1_words))
# print("len(known_original_word) = {0}----known_original_word = {1}".format(len(known_original_word), known_original_word))
print("len(known_edit1_words) = {0}----known_edit1_words = {1}".format(len(known_edit1_words), known_edit1_words))
return candidates
#==== 根据编辑距离为1、2返回候选词【在单词库中存在的】 ====
def candidates_1_2(word):
original_word = [word] # 原单词
edit1_words = edits1(word) # 编辑距离为1的候选字符串
edit2_words = edits2(word) # 编辑距离为2的候选字符串
known_original_word = known(original_word) # 过滤掉不存在于词典库里面的单词
known_edit1_words = known(edit1_words) # 过滤掉不存在于词典库里面的单词
known_edit2_words = known(edit2_words) # 过滤掉不存在于词典库里面的单词
candidates = known_original_word + known_edit1_words + known_edit2_words
# print("len(original_word) = {0}----original_word = {1}".format(len(original_word), original_word))
# print("len(edit1_words) = {0}----edit1_words = {1}".format(len(edit1_words), edit1_words))
# print("len(edit2_words) = {0}----edit2_words = {1}".format(len(edit2_words), edit2_words))
# print("len(known_original_word) = {0}----known_original_word = {1}".format(len(known_original_word), known_original_word))
print("len(known_edit1_words) = {0}----known_edit1_words = {1}".format(len(known_edit1_words), known_edit1_words))
print("len(known_edit2_words) = {0}----known_edit2_words = {1}".format(len(known_edit2_words), known_edit2_words))
return candidates
#==== 输出概率最大的纠正词 ====
def correction(word,distance=None): # distance为编辑距离参数
if distance==1:
candidates_words = candidates_1(word)
print("candidates_words = {}".format(candidates_words))
else:
candidates_words = candidates_1_2(word)
print("candidates_words = {}".format(candidates_words))
return max(candidates_words, key=P) # "Most probable spelling correction for word."
if __name__=="__main__":
word = "speling"
print("-"*30,"根据编辑距离为1进行纠错","-"*30)
correction_1_result = correction(word=word, distance=1)
print('word = {0}----根据词典库词频顺序取最大可能性的候选词:correction_1_result = {1}'.format(word, correction_1_result))
print("-" * 30, "根据编辑距离为1&2进行纠错", "-" * 30)
correction_1_result = correction(word=word, distance=2)
print('word = {0}----根据词典库词频顺序取最大可能性的候选词:correction_1_result = {1}'.format(word, correction_1_result))
输出结果:
------------------------------ 根据编辑距离为1进行纠错 ------------------------------
len(known_edit1_words) = 3----known_edit1_words = ['spelling', 'spewing', 'sperling']
candidates_words = ['spelling', 'spewing', 'sperling']
word = speling----根据词典库词频顺序取最大可能性的候选词:correction_1_result = spelling
------------------------------ 根据编辑距离为1&2进行纠错 ------------------------------
len(known_edit1_words) = 3----known_edit1_words = ['spelling', 'spewing', 'sperling']
len(known_edit2_words) = 69----known_edit2_words = ['aveling', 'spacing', 'spiking', 'selig', 'paling', 'shewing', 'pealing', 'styling', 'spelling', 'spoiling', 'skewing', 'smiling', 'spilling', 'spying', 'spalding', 'selling', 'snelling', 'sapling', 'smelling', 'opening', 'splint', 'heeling', 'sewing', 'selina', 'spearing', 'spending', 'dueling', 'reeling', 'fueling', 'scaling', 'spellings', 'speaking', 'peking', 'poling', 'seeding', 'spline', 'sailing', 'pelting', 'swelling', 'stewing', 'spalling', 'sealing', 'sparing', 'seedling', 'sibling', 'seeing', 'pelling', 'piling', 'peeling', 'feeling', 'seeking', 'stealing', 'sterling', 'sieving', 'soiling', 'shelving', 'shelling', 'ebeling', 'sexing', 'spedding', 'seeming', 'sling', 'seeping', 'keeling', 'spewing', 'smelting', 'spring', 'speeding', 'sperling']
candidates_words = ['spelling', 'spewing', 'sperling', 'aveling', 'spacing', 'spiking', 'selig', 'paling', 'shewing', 'pealing', 'styling', 'spelling', 'spoiling', 'skewing', 'smiling', 'spilling', 'spying', 'spalding', 'selling', 'snelling', 'sapling', 'smelling', 'opening', 'splint', 'heeling', 'sewing', 'selina', 'spearing', 'spending', 'dueling', 'reeling', 'fueling', 'scaling', 'spellings', 'speaking', 'peking', 'poling', 'seeding', 'spline', 'sailing', 'pelting', 'swelling', 'stewing', 'spalling', 'sealing', 'sparing', 'seedling', 'sibling', 'seeing', 'pelling', 'piling', 'peeling', 'feeling', 'seeking', 'stealing', 'sterling', 'sieving', 'soiling', 'shelving', 'shelling', 'ebeling', 'sexing', 'spedding', 'seeming', 'sling', 'seeping', 'keeling', 'spewing', 'smelting', 'spring', 'speeding', 'sperling']
word = speling----根据词典库词频顺序取最大可能性的候选词:correction_1_result = feeling
Process finished with exit code 0
2-1、英文单词拼写纠错【N-Gram模型概率+“用户常见错词表概率”】01
spell-errors.txt
import math
import nltk
nltk.download('reuters') # 下载训练数据集【位置:C:\Users\surface\AppData\Roaming\nltk_data】
nltk.download('punkt') # 下载训练数据集【位置:C:\Users\surface\AppData\Roaming\nltk_data】
from nltk.corpus import reuters # reuters路透社语料库
# 读取语料库
categories = reuters.categories() # 路透社语料库的类别
print("len(categories) = {}----categories[:5] = {}".format(len(categories), categories[:5]))
corpus = reuters.sents(categories=categories) # sents()指定分类中的句子
print("len(corpus) = {}----corpus[:5] = {}".format(len(corpus), corpus[:5]))
#==== 加载带有概率的词库 ====
word_freq_list = list(set([line.rstrip() for line in open('vocab.txt')])) #用set效率高一些(时间复杂度)
vocab = {}
for word_freq in word_freq_list:
word, freq = word_freq.split("\t")
vocab[word.strip()] = int(freq)
print("list(vocab.items())[:10] = {0}".format(list(vocab.items())[:10]))
# 生成单词的所有候选集合【给定输入(错误地输入)的单词,由编辑距离的4种操作(insert, delete, replace,transposes),返回该单词所有候选集合。返回所有(valid)候选集合】
def edits1(word): # word: 给定的输入(错误的输入)
# 生成编辑距离不大于1的单词
# 1.insert 2. delete 3. replace 4. transposes
# appl: replace: bppl, cppl, aapl, abpl...
# insert: bappl, cappl, abppl, acppl....
# delete: ppl, apl, app
# transposes:papl
letters = 'abcdefghijklmnopqrstuvwxyz' # 假设使用26个字符
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)] # 将单词在不同的位置拆分成2个字符串,然后分别进行insert,delete你replace操作,拆分形式为:[('', 'apple'), ('a', 'pple'), ('ap', 'ple'), ('app', 'le'), ('appl', 'e'), ('apple', '')]
inserts = [L + c + R for L, R in splits for c in letters] # insert操作
deletes = [L + R[1:] for L, R in splits if R] # delete操作:判断分割后的字符串R是否为空,不为空,删除R的第一个字符即R[1:]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters] # replace操作:替换R的第一个字符,即c+R[1:]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R) > 1] # transposes操作:交换R的第一个字符与第二个字符
edit1_words = list(set(inserts + deletes + replaces + transposes))
return edit1_words
# 给定一个字符串,生成编辑距离不大于2的字符串【在生成的与正确单词编辑距离不大于1的单词的基础上,再次进行insert, delete, replace操作,从而生成编辑距离不大于2的所有候选集合】
def edits2(word):
edit2_words = [e2 for e1 in edits1(word) for e2 in edits1(e1)]
return edit2_words
# 检查单词是否是单词库中的拼写正确的单词【过滤掉不存在于词典库里面的单词】
def known(edit_words):
return list(set(edit_word for edit_word in edit_words if edit_word in vocab))
#==== 根据编辑距离为1返回候选词【在单词库中存在的】 ====
def candidates_1(word):
original_word = [word] # 原单词
edit1_words = edits1(word) # 编辑距离为1的候选字符串
known_original_word = known(original_word) # 过滤掉不存在于词典库里面的单词
known_edit1_words = known(edit1_words) # 过滤掉不存在于词典库里面的单词
candidates = known_original_word + known_edit1_words
# print("len(original_word) = {0}----original_word = {1}".format(len(original_word), original_word))
# print("len(edit1_words) = {0}----edit1_words = {1}".format(len(edit1_words), edit1_words))
# print("len(known_original_word) = {0}----known_original_word = {1}".format(len(known_original_word), known_original_word))
print("len(known_edit1_words) = {0}----known_edit1_words = {1}".format(len(known_edit1_words), known_edit1_words))
return candidates
#==== 根据编辑距离为1、2返回候选词【在单词库中存在的】 ====
def candidates_1_2(word):
original_word = [word] # 原单词
edit1_words = edits1(word) # 编辑距离为1的候选字符串
edit2_words = edits2(word) # 编辑距离为2的候选字符串
known_original_word = known(original_word) # 过滤掉不存在于词典库里面的单词
known_edit1_words = known(edit1_words) # 过滤掉不存在于词典库里面的单词
known_edit2_words = known(edit2_words) # 过滤掉不存在于词典库里面的单词
candidates = list(set(known_original_word + known_edit1_words + known_edit2_words))
# print("len(original_word) = {0}----original_word = {1}".format(len(original_word), original_word))
# print("len(edit1_words) = {0}----edit1_words = {1}".format(len(edit1_words), edit1_words))
# print("len(edit2_words) = {0}----edit2_words = {1}".format(len(edit2_words), edit2_words))
# print("len(known_original_word) = {0}----known_original_word = {1}".format(len(known_original_word), known_original_word))
print("len(known_edit1_words) = {0}----known_edit1_words = {1}".format(len(known_edit1_words), known_edit1_words))
print("len(known_edit2_words) = {0}----known_edit2_words = {1}".format(len(known_edit2_words), known_edit2_words))
return candidates
#==== 输出概率最大的纠正词 ====
def correction(error_word=None,distance=None): # distance为编辑距离参数
if distance==1:
candidates_words = candidates_1(error_word)
print("candidates_words = {}".format(candidates_words))
else:
candidates_words = candidates_1_2(error_word)
print("candidates_words = {}".format(candidates_words))
return candidates_words
# =====================================用户打错的概率统计 - channel probability=====================================
# 该文件记录了很多用户写错的单词和对应正确的单词,可以通过该文件确定每个正确的单词所对应的错误拼写方式,并计算出每个错误拼写方式出现的概率
channel_prob = {}
def chann_prob():
for line in open('./spell-errors.txt'):
items = line.split(":")
correct = items[0].strip()
mistakes = [item.strip() for item in items[1].strip().split(",")]
channel_prob[correct] = {}
for mis in mistakes:
channel_prob[correct][mis] = math.log(1.0/len(mistakes))
print("len(channel_prob) = {0}----list(channel_prob.items())[:10]= {1}".format(len(channel_prob), list(channel_prob.items())[:10]))
# =====================================构建语言模型:unigram、bigram(方式:保存所有训练数据集中的单个单词、相邻2个单词在一起的数量,用于计算条件概率p(a,b|a))=====================================
unigram_count = {}
bigram_count = {}
def build_bigram_model():
for doc in corpus:
doc = [''] + doc # ''表示开头
for i in range(0, len(doc) - 1):
term = doc[i] # term是doc中第i个单词
bigram = doc[i:i + 2] # bigram为第i,i+1个单词组成的 [i,i+1]
if term in unigram_count:
unigram_count[term] += 1 # 如果term存在unigram_count中,则加1
else:
unigram_count[term] = 1 # 如果不存在,则添加,置为1
bigram = ' '.join(bigram)
if bigram in bigram_count:
bigram_count[bigram] += 1
else:
bigram_count[bigram] = 1
print("len(unigram_count) = {0}----举例:list(unigram_count.items())[:10] = {1}".format(len(unigram_count), list(unigram_count.items())[:10]))
print("len(bigram_count) = {0}----举例:list(bigram_count.items())[:10]= {1}".format(len(bigram_count), list(bigram_count.items())[:10]))
if __name__=="__main__":
chann_prob() # 构建 用户写错的单词和对应正确的单词 数据模型,保存位置:channel_prob.txt
build_bigram_model() # 构建 N-Gram 数据模型,保存位置:unigram_count.txt、bigram_count.txt
# 测试单个单词的拼写纠错功能
# word = "foreigh"
# print("-"*30,"根据编辑距离为1进行纠错","-"*30)
# correction_1_result = correction(word=word, distance=1)
# print('word = {0}----根据词典库词频顺序取最大可能性的候选词:correction_1_result = {1}'.format(word, correction_1_result))
# print("-" * 30, "根据编辑距离为1&2进行纠错", "-" * 30)
# correction_1_result = correction(word=word, distance=2)
# print('word = {0}----根据词典库词频顺序取最大可能性的候选词:correction_1_result = {1}'.format(word, correction_1_result))
# 测试一句话的单词拼写功能
V = len(unigram_count.keys())
line = ['In', 'China', 'English', 'is', 'taken', ' to', ' be', ' a', 'foreigh', ' language ', 'which ', 'many ', 'students ', 'choose ', 'to ', 'learn']
j = 0
for word in line:
if vocab.get(word.strip().lower()) is None:
error_word = word
print("\n","="*40, "当前单词拼写错误(不在给定的vocab词典库中):{}".format(error_word), "="*40)
# 需要替换error_word成正确的单词
# Step1: 生成所有的(valid)候选集合
candidates = correction(error_word=error_word, distance=2)
print("生成所有的(valid)候选集合---->candidates = {0}".format(candidates))
if len(candidates) < 1:
continue
candi_probs = []
# 对于每一个candidate, 计算它的概率值score,返回score最大的candidate 【score = p(correct)*p(mistake|correct) = log p(correct) + log p(mistake|correct)】
for candidate in candidates:
print("-"*30, "candidate = {}".format(candidate), "-"*30)
candi_prob = 0 # 初始化当前候选词的概率
# 1、计算候选词的 channel probability概率,并加入到prob中【如果在spell-errors.txt文件中当前候选词的拼写错误列表中有当前的拼写错误word,则当前候选词加上其概率值】
if candidate in channel_prob and word in channel_prob[candidate]: # candidate: freight; channel_prob[candidate]= frieght, foreign
print("candidate = {0}----channel_prob[candidate] = {1}----channel_prob[candidate][word]={2}".format(candidate, str(channel_prob[candidate]), channel_prob[candidate][word]))
chann_prob = channel_prob[candidate][word]
print("candidate = {0}----chann_prob = {1}".format(candidate, chann_prob))
candi_prob += chann_prob
else:
candi_prob += math.log(0.0001)
# 2、计算候选词的语言模型的概率
# 2.1 考虑前一个词【比如:候选词word=freight,此时计算“a freight”出现的概率】
if j > 0:
forward_word = line[j - 1] + " " + candidate # 考虑前一个单词,出现like playing的概率
print("forward_word = {0}----line[j - 1] = {1}".format(forward_word, line[j - 1]))
if forward_word in bigram_count and line[j - 1] in unigram_count:
forward_prob = math.log((bigram_count[forward_word] + 1.0) / (unigram_count[line[j - 1]] + V)) # 加1平滑计算:在word出现的情况下,forward_word出现的概率。
print("candidate = {0}----forward_prob = {1}".format(candidate, forward_prob))
candi_prob += forward_prob
else:
candi_prob += math.log(1.0 / V)
# 2.2 考虑后一个单词【比如:候选词word=freight,此时计算“freight language”出现的概率】
if j + 1 < len(line):
word_backward = candidate + " " + line[j + 1]
print("word_backward = {0}----line[j + 1] = {1}".format(word_backward, line[j + 1]))
if word_backward in bigram_count and candidate in unigram_count:
backward_prob = math.log((bigram_count[word_backward] + 1.0) / (unigram_count[candidate] + V)) # 加1平滑计算:在word出现的情况下,word_backward出现的概率。
print("candidate = {0}----backward_prob = {1}".format(candidate, backward_prob))
candi_prob += backward_prob
else:
candi_prob += math.log(1.0 / V)
print("该候选词的最终得分:candi_prob = {}".format(candi_prob))
candi_probs.append(candi_prob) # 将当前候选词的得分加入到 candi_probs 列表
print("\n\n所有候选词的最终得分:candi_probs = {}".format(candi_probs))
max_idx = candi_probs.index(max(candi_probs))
print("error_word = {0}----最佳候选词:candidates[max_idx] = {1}".format(error_word, candidates[max_idx]))
j += 1
打印结果:
[nltk_data] Downloading package reuters to
[nltk_data] C:\Users\surface\AppData\Roaming\nltk_data...
[nltk_data] Package reuters is already up-to-date!
[nltk_data] Downloading package punkt to
[nltk_data] C:\Users\surface\AppData\Roaming\nltk_data...
[nltk_data] Package punkt is already up-to-date!
len(categories) = 90----categories[:5] = ['acq', 'alum', 'barley', 'bop', 'carcass']
len(corpus) = 54716----corpus[:5] = [['ASIAN', 'EXPORTERS', 'FEAR', 'DAMAGE', 'FROM', 'U', '.', 'S', '.-', 'JAPAN', 'RIFT', 'Mounting', 'trade', 'friction', 'between', 'the', 'U', '.', 'S', '.', 'And', 'Japan', 'has', 'raised', 'fears', 'among', 'many', 'of', 'Asia', "'", 's', 'exporting', 'nations', 'that', 'the', 'row', 'could', 'inflict', 'far', '-', 'reaching', 'economic', 'damage', ',', 'businessmen', 'and', 'officials', 'said', '.'], ['They', 'told', 'Reuter', 'correspondents', 'in', 'Asian', 'capitals', 'a', 'U', '.', 'S', '.', 'Move', 'against', 'Japan', 'might', 'boost', 'protectionist', 'sentiment', 'in', 'the', 'U', '.', 'S', '.', 'And', 'lead', 'to', 'curbs', 'on', 'American', 'imports', 'of', 'their', 'products', '.'], ['But', 'some', 'exporters', 'said', 'that', 'while', 'the', 'conflict', 'would', 'hurt', 'them', 'in', 'the', 'long', '-', 'run', ',', 'in', 'the', 'short', '-', 'term', 'Tokyo', "'", 's', 'loss', 'might', 'be', 'their', 'gain', '.'], ['The', 'U', '.', 'S', '.', 'Has', 'said', 'it', 'will', 'impose', '300', 'mln', 'dlrs', 'of', 'tariffs', 'on', 'imports', 'of', 'Japanese', 'electronics', 'goods', 'on', 'April', '17', ',', 'in', 'retaliation', 'for', 'Japan', "'", 's', 'alleged', 'failure', 'to', 'stick', 'to', 'a', 'pact', 'not', 'to', 'sell', 'semiconductors', 'on', 'world', 'markets', 'at', 'below', 'cost', '.'], ['Unofficial', 'Japanese', 'estimates', 'put', 'the', 'impact', 'of', 'the', 'tariffs', 'at', '10', 'billion', 'dlrs', 'and', 'spokesmen', 'for', 'major', 'electronics', 'firms', 'said', 'they', 'would', 'virtually', 'halt', 'exports', 'of', 'products', 'hit', 'by', 'the', 'new', 'taxes', '.']]
list(vocab.items())[:10] = [('mistletoe', 488055), ('zal', 125039), ('atwood', 828552), ('outdistanced', 141900), ('jes', 457827), ('fathomless', 233620), ('conjugate', 2103565), ('sighing', 1382024), ('silenus', 180905), ('endurable', 279838)]
len(unigram_count) = 41559----举例:list(unigram_count.items())[:10] = [('', 54716), ('ASIAN', 12), ('EXPORTERS', 46), ('FEAR', 2), ('DAMAGE', 13), ('FROM', 208), ('U', 6388), ('.', 45900), ('S', 6382), ('.-', 167)]
len(bigram_count) = 397935----举例:list(bigram_count.items())[:10]= [(' ASIAN', 4), ('ASIAN EXPORTERS', 1), ('EXPORTERS FEAR', 1), ('FEAR DAMAGE', 1), ('DAMAGE FROM', 2), ('FROM U', 4), ('U .', 6350), ('. S', 5809), ('S .-', 120), ('.- JAPAN', 8)]
len(channel_prob) = 7841----list(channel_prob.items())[:10]= [('raining', {'rainning': -0.6931471805599453, 'raning': -0.6931471805599453}), ('writings', {'writtings': 0.0}), ('disparagingly', {'disparingly': 0.0}), ('yellow', {'yello': 0.0}), ('four', {'forer': -1.6094379124341003, 'fours': -1.6094379124341003, 'fuore': -1.6094379124341003, 'fore*5': -1.6094379124341003, 'for*4': -1.6094379124341003}), ('woods', {'woodes': 0.0}), ('hanging', {'haing': 0.0}), ('aggression', {'agression': 0.0}), ('looking', {'loking': -2.3025850929940455, 'begining': -2.3025850929940455, 'luing': -2.3025850929940455, 'look*2': -2.3025850929940455, 'locking': -2.3025850929940455, 'lucking': -2.3025850929940455, 'louk': -2.3025850929940455, 'looing': -2.3025850929940455, 'lookin': -2.3025850929940455, 'liking': -2.3025850929940455}), ('eligible', {'eligble': -1.0986122886681098, 'elegable': -1.0986122886681098, 'eligable': -1.0986122886681098})]
======================================== 当前单词拼写错误(不在给定的vocab词典库中):foreigh ========================================
len(known_edit1_words) = 1----known_edit1_words = ['foreign']
len(known_edit2_words) = 5----known_edit2_words = ['forego', 'freight', 'foreach', 'foreign', 'foresight']
candidates_words = ['forego', 'freight', 'foreach', 'foreign', 'foresight']
生成所有的(valid)候选集合---->candidates = ['forego', 'freight', 'foreach', 'foreign', 'foresight']
------------------------------ candidate = forego ------------------------------
forward_word = a forego----line[j - 1] = a
word_backward = forego language ----line[j + 1] = language
该候选词的最终得分:candi_prob = -30.48007913862816
------------------------------ candidate = freight ------------------------------
forward_word = a freight----line[j - 1] = a
word_backward = freight language ----line[j + 1] = language
该候选词的最终得分:candi_prob = -30.48007913862816
------------------------------ candidate = foreach ------------------------------
forward_word = a foreach----line[j - 1] = a
word_backward = foreach language ----line[j + 1] = language
该候选词的最终得分:candi_prob = -30.48007913862816
------------------------------ candidate = foreign ------------------------------
candidate = foreign----channel_prob[candidate] = {'forien': -1.3862943611198906, 'forein': -1.3862943611198906, 'foriegn*2': -1.3862943611198906, 'foreigh': -1.3862943611198906}----channel_prob[candidate][word]=-1.3862943611198906
candidate = foreign----chann_prob = -1.3862943611198906
forward_word = a foreign----line[j - 1] = a
word_backward = foreign language ----line[j + 1] = language
该候选词的最终得分:candi_prob = -22.656033127771867
------------------------------ candidate = foresight ------------------------------
forward_word = a foresight----line[j - 1] = a
word_backward = foresight language ----line[j + 1] = language
该候选词的最终得分:candi_prob = -30.48007913862816
所有候选词的最终得分:candi_probs = [-30.48007913862816, -30.48007913862816, -30.48007913862816, -22.656033127771867, -30.48007913862816]
error_word = foreigh----最佳候选词:candidates[max_idx] = foreign
Process finished with exit code 0
2-2、英文单词拼写纠错【N-Gram模型概率+“用户常见错词表概率”】02
import math
import nltk
nltk.download('reuters') # 下载训练数据集【位置:C:\Users\surface\AppData\Roaming\nltk_data】
nltk.download('punkt') # 下载训练数据集【位置:C:\Users\surface\AppData\Roaming\nltk_data】
from nltk.corpus import reuters # reuters路透社语料库
# 读取语料库
categories = reuters.categories() # 路透社语料库的类别
print("len(categories) = {}----categories[:5] = {}".format(len(categories), categories[:5]))
corpus = reuters.sents(categories=categories) # sents()指定分类中的句子
print("len(corpus) = {}----corpus[:5] = {}".format(len(corpus), corpus[:5]))
# ==== 加载带有概率的词库 ====
word_freq_list = list(set([line.rstrip() for line in open('vocab.txt')])) # 用set效率高一些(时间复杂度)
vocab = {}
for word_freq in word_freq_list:
word, freq = word_freq.split("\t")
vocab[word.strip()] = int(freq)
print("list(vocab.items())[:10] = {0}".format(list(vocab.items())[:10]))
# 生成单词的所有候选集合【给定输入(错误地输入)的单词,由编辑距离的4种操作(insert, delete, replace,transposes),返回该单词所有候选集合。返回所有(valid)候选集合】
def edits1(word): # word: 给定的输入(错误的输入)
# 生成编辑距离不大于1的单词
# 1.insert 2. delete 3. replace 4. transposes
# appl: replace: bppl, cppl, aapl, abpl...
# insert: bappl, cappl, abppl, acppl....
# delete: ppl, apl, app
# transposes:papl
letters = 'abcdefghijklmnopqrstuvwxyz' # 假设使用26个字符
splits = [(word[:i], word[i:]) for i in range(len(word) + 1)] # 将单词在不同的位置拆分成2个字符串,然后分别进行insert,delete你replace操作,拆分形式为:[('', 'apple'), ('a', 'pple'), ('ap', 'ple'), ('app', 'le'), ('appl', 'e'), ('apple', '')]
inserts = [L + c + R for L, R in splits for c in letters] # insert操作
deletes = [L + R[1:] for L, R in splits if R] # delete操作:判断分割后的字符串R是否为空,不为空,删除R的第一个字符即R[1:]
replaces = [L + c + R[1:] for L, R in splits if R for c in letters] # replace操作:替换R的第一个字符,即c+R[1:]
transposes = [L + R[1] + R[0] + R[2:] for L, R in splits if len(R) > 1] # transposes操作:交换R的第一个字符与第二个字符
edit1_words = list(set(inserts + deletes + replaces + transposes))
# print('len(edit1_words) = ', len(edit1_words))
return edit1_words
# 给定一个字符串,生成编辑距离不大于2的字符串【在生成的与正确单词编辑距离不大于1的单词的基础上,再次进行insert, delete, replace操作,从而生成编辑距离不大于2的所有候选集合】
def edits2(word):
edit2_words = [e2 for e1 in edits1(word) for e2 in edits1(e1)]
print('len(edit2_words) = ', len(edit2_words))
return edit2_words
# 给定一个字符串,生成编辑距离不大于3的字符串【在生成的与正确单词编辑距离不大于2的单词的基础上,再次进行insert, delete, replace操作,从而生成编辑距离不大于3的所有候选集合】
def edits3(word):
edit3_words = [e3 for e1 in edits1(word) for e2 in edits1(e1) for e3 in edits1(e2)]
print('len(edit3_words) = ', len(edit3_words))
return edit3_words
# 检查单词是否是单词库中的拼写正确的单词【过滤掉不存在于词典库里面的单词】
def known(edit_words):
return list(set(edit_word for edit_word in edit_words if edit_word in vocab))
# ==== 根据编辑距离为1返回候选词【在单词库中存在的】 ====
def candidates_1(word):
original_word = [word] # 原单词
edit1_words = edits1(word) # 编辑距离为1的候选字符串
known_original_word = known(original_word) # 过滤掉不存在于词典库里面的单词
known_edit1_words = known(edit1_words) # 过滤掉不存在于词典库里面的单词
candidates = known_original_word + known_edit1_words
print("len(original_word) = {0}----original_word = {1}".format(len(original_word), original_word))
print("len(edit1_words) = {0}----edit1_words = {1}".format(len(edit1_words), edit1_words))
print("len(known_original_word) = {0}----known_original_word = {1}".format(len(known_original_word), known_original_word))
print("len(known_edit1_words) = {0}----known_edit1_words = {1}".format(len(known_edit1_words), known_edit1_words))
return candidates
# ==== 根据编辑距离为1、2返回候选词【在单词库中存在的】 ====
def candidates_1_2(word):
original_word = [word] # 原单词
edit1_words = edits1(word) # 编辑距离为1的候选字符串
edit2_words = edits2(word) # 编辑距离为2的候选字符串
known_original_word = known(original_word) # 过滤掉不存在于词典库里面的单词
known_edit1_words = known(edit1_words) # 过滤掉不存在于词典库里面的单词
known_edit2_words = known(edit2_words) # 过滤掉不存在于词典库里面的单词
candidates = list(set(known_original_word + known_edit1_words + known_edit2_words))
# print("len(original_word) = {0}----original_word = {1}".format(len(original_word), original_word))
# print("len(edit1_words) = {0}----edit1_words = {1}".format(len(edit1_words), edit1_words))
# print("len(edit2_words) = {0}----edit2_words = {1}".format(len(edit2_words), edit2_words))
# print("len(known_original_word) = {0}----known_original_word = {1}".format(len(known_original_word), known_original_word))
print("len(known_edit1_words) = {0}----known_edit1_words = {1}".format(len(known_edit1_words), known_edit1_words))
print("len(known_edit2_words) = {0}----known_edit2_words = {1}".format(len(known_edit2_words), known_edit2_words))
return candidates
# ==== 根据编辑距离为1、2返回候选词【在单词库中存在的】 ====
def candidates_1_2_3(word):
original_word = [word] # 原单词
edit1_words = edits1(word) # 编辑距离为1的候选字符串(不一定是真词)
edit2_words = edits2(word) # 编辑距离为2的候选字符串(不一定是真词)
edit3_words = edits3(word) # 编辑距离为3的候选字符串(不一定是真词)
known_original_word = known(original_word) # 过滤掉不存在于词典库里面的单词
known_edit1_words = known(edit1_words) # 过滤掉不存在于词典库里面的单词
known_edit2_words = known(edit2_words) # 过滤掉不存在于词典库里面的单词
known_edit3_words = known(edit3_words) # 过滤掉不存在于词典库里面的单词
candidates = list(set(known_original_word + known_edit1_words + known_edit2_words + known_edit3_words))
print("len(original_word) = {0}----original_word = {1}".format(len(original_word), original_word))
print("编辑距离为1的候选字符串(不一定是真词):len(edit1_words) = {0}".format(len(edit1_words)))
print("编辑距离为2的候选字符串(不一定是真词):len(edit2_words) = {0}".format(len(edit2_words)))
print("编辑距离为3的候选字符串(不一定是真词):len(edit3_words) = {0}".format(len(edit3_words)))
print("len(known_original_word) = {0}----known_original_word = {1}".format(len(known_original_word), known_original_word))
print("len(known_edit1_words) = {0}----known_edit1_words = {1}".format(len(known_edit1_words), known_edit1_words))
print("len(known_edit2_words) = {0}----known_edit2_words = {1}".format(len(known_edit2_words), known_edit2_words))
print("len(known_edit3_words) = {0}----known_edit3_words = {1}".format(len(known_edit3_words), known_edit3_words))
return candidates
# ==== 输出概率最大的纠正词 ====
def correction(error_word=None, distance=None): # distance为编辑距离参数
if distance == 1:
print("生成error_word({0})编辑距离为1的候选词:".format(error_word))
candidates_words = candidates_1(error_word)
print("candidates_words = {}".format(candidates_words))
elif distance == 2:
print("生成error_word({0})编辑距离为1与2的候选词:".format(error_word))
candidates_words = candidates_1_2(error_word)
print("candidates_words = {}".format(candidates_words))
else:
print("生成error_word({0})编辑距离为1与2与3的候选词:".format(error_word))
candidates_words = candidates_1_2_3(error_word)
print("candidates_words = {}".format(candidates_words))
return candidates_words
# =====================================构建语言模型:unigram、bigram(方式:保存所有训练数据集中的单个单词、相邻2个单词在一起的数量,用于计算条件概率p(a,b|a))=====================================
unigram_count = {}
bigram_count = {}
def build_bigram_model():
for doc in corpus:
doc = [''] + doc # ''表示开头
for i in range(0, len(doc) - 1):
term = doc[i] # term是doc中第i个单词
bigram = doc[i:i + 2] # bigram为第i,i+1个单词组成的 [i,i+1]
if term in unigram_count:
unigram_count[term] += 1 # 如果term存在unigram_count中,则加1
else:
unigram_count[term] = 1 # 如果不存在,则添加,置为1
bigram = ' '.join(bigram)
if bigram in bigram_count:
bigram_count[bigram] += 1
else:
bigram_count[bigram] = 1
print("len(unigram_count) = {0}----举例:list(unigram_count.items())[:10] = {1}".format(len(unigram_count), list(unigram_count.items())[:10]))
print("len(bigram_count) = {0}----举例:list(bigram_count.items())[:10]= {1}".format(len(bigram_count), list(bigram_count.items())[:10]))
# =====================================用户打错的概率统计 - channel probability=====================================
# 该文件记录了很多用户写错的单词和对应正确的单词,可以通过该文件确定每个正确的单词所对应的错误拼写方式,并计算出每个错误拼写方式出现的概率
channel_prob = {}
def chann_prob():
for line in open('./spell-errors.txt'):
items = line.split(":")
correct = items[0].strip()
mistakes = [item.strip() for item in items[1].strip().split(",")]
channel_prob[correct] = {}
for mis in mistakes:
channel_prob[correct][mis] = math.log(1.0 / len(mistakes))
print("len(channel_prob) = {0}----list(channel_prob.items())[:3]= {1}".format(len(channel_prob), list(channel_prob.items())[:3]))
if __name__ == "__main__":
build_bigram_model() # 构建 N-Gram 数据模型,保存位置:unigram_count.txt、bigram_count.txt
chann_prob() # 构建 用户写错的单词和对应正确的单词 数据模型,保存位置:channel_prob.txt
# 测试单个单词的拼写纠错功能
# word = "foreigh"
# print("-"*30,"根据编辑距离为1进行纠错","-"*30)
# correction_1_result = correction(word=word, distance=1)
# print('word = {0}----根据词典库词频顺序取最大可能性的候选词:correction_1_result = {1}'.format(word, correction_1_result))
# print("-" * 30, "根据编辑距离为1&2进行纠错", "-" * 30)
# correction_1_result = correction(word=word, distance=2)
# print('word = {0}----根据词典库词频顺序取最大可能性的候选词:correction_1_result = {1}'.format(word, correction_1_result))
# 测试一句话的单词拼写功能
V = len(unigram_count.keys())
line = ['English', 'is', 'taken', ' to', ' be', ' a', 'foreigh', ' language ', 'which ', 'many ', 'students ', 'choose ', 'to ', 'learn']
j = 0
for word in line:
if vocab.get(word.strip().lower()) is None:
error_word = word
print("\n", "=" * 40, "当前单词拼写错误(不在给定的vocab词典库中):{}".format(error_word), "=" * 40)
# 需要替换error_word成正确的单词
# Step1: 生成所有的(valid)候选集合
candidates = correction(error_word=error_word, distance=3)
print("生成所有的(valid)候选集合---->len(candidates) = {0}----candidates = {0}".format(len(candidates), candidates))
if len(candidates) < 1:
continue
candi_probs = []
# 对于每一个candidate, 计算它的概率值score,返回score最大的candidate 【score = p(correct)*p(mistake|correct) = log p(correct) + log p(mistake|correct)】
for candidate in candidates:
print("-" * 30, "candidate = {}".format(candidate), "-" * 30)
candi_prob = 0 # 初始化当前候选词的概率
# 1、计算候选词的 channel probability 概率,并加入到prob中【如果在spell-errors.txt文件中当前候选词的拼写错误列表中有当前的拼写错误word,则当前候选词加上其概率值】
if candidate in channel_prob and error_word in channel_prob[candidate]: # candidate: freight; channel_prob[candidate]= frieght, foreign
print("candidate = {0}----channel_prob[candidate] = {1}----channel_prob[candidate][error_word]={2}".format(candidate, str(channel_prob[candidate]), channel_prob[candidate][error_word]))
chann_prob = channel_prob[candidate][error_word]
print("candidate = {0}----chann_prob = {1}".format(candidate, chann_prob))
candi_prob += chann_prob
else:
candi_prob += math.log(0.0001)
# 2、计算候选词的语言模型的概率
# 2.1 考虑前一个词【比如:候选词 word=freight,此时计算“a freight”出现的概率】
if j > 0:
forward_word = line[j - 1] + " " + candidate # 考虑前一个单词,出现like playing的概率
print("forward_word = {0}----line[j - 1] = {1}".format(forward_word, line[j - 1]))
if forward_word in bigram_count and line[j - 1] in unigram_count:
forward_prob = math.log((bigram_count[forward_word] + 1.0) / (unigram_count[line[j - 1]] + V)) # 加1平滑计算:在word出现的情况下,forward_word出现的概率。
print("candidate = {0}----forward_prob = {1}".format(candidate, forward_prob))
candi_prob += forward_prob
else:
candi_prob += math.log(1.0 / V)
# 2.2 考虑后一个单词【比如:候选词word=freight,此时计算“freight language”出现的概率】
if j + 1 < len(line):
word_backward = candidate + " " + line[j + 1]
print("word_backward = {0}----line[j + 1] = {1}".format(word_backward, line[j + 1]))
if word_backward in bigram_count and candidate in unigram_count:
backward_prob = math.log((bigram_count[word_backward] + 1.0) / (unigram_count[candidate] + V)) # 加1平滑计算:在word出现的情况下,word_backward出现的概率。
print("candidate = {0}----backward_prob = {1}".format(candidate, backward_prob))
candi_prob += backward_prob
else:
candi_prob += math.log(1.0 / V)
print("该候选词的最终得分:candi_prob = {}".format(candi_prob))
candi_probs.append(candi_prob) # 将当前候选词的得分加入到 candi_probs 列表
print("\n\n所有候选词的最终得分:candi_probs = {}".format(candi_probs))
max_idx = candi_probs.index(max(candi_probs))
print("error_word = {0}----最佳候选词:candidates[max_idx] = {1}".format(error_word, candidates[max_idx]))
j += 1
3、英文单词拼写纠错【Noisy Channel Model模型、N-Gram模型概率】
w i ^ = arg max w i ∈ V P ( x j ∣ w i ) P ( w i ) \begin{aligned}\hat{w_i}=\argmax_{w_i∈V}P(x_j|w_i)P(w_i)\end{aligned} wi^=wi∈VargmaxP(xj∣wi)P(wi)
# -*- coding: utf-8 -*-
"""
Created on Tue Aug 18 14:27:56 2020
@author: USER
"""
import re
from collections import Counter
import numpy as np
import pandas as pd
import math
import random
import numpy as np
import pandas as pd
import nltk
import Candidates
import OOV
import Ngram
import ErrorModel
# 读取训练数据集
with open("./data/514-8.txt", "r", encoding="utf-8") as f:
data = f.read()
# 预处理文件
data = re.sub(r'[^A-Za-z\.\?!\']+', ' ', data) # remove special character
data = re.sub(r'[A-Z]{3,}[a-z]+', ' ', data) # remove words with more than 3 Capital letters
sentences = re.split(r'[\.\?!]+[ \n]+', data) # split data into sentences
sentences = [s.strip() for s in sentences] # Remove leading & trailing spaces
sentences = [s for s in sentences if len(s) > 0] # Remove whitespace
# 读取所有句子
tokenized_sentences = []
for sentence in sentences:
sentence = sentence.lower() # 转为小写 >>> cards and supper were over but the visitors had not yet dispersed
tokenized_sentence = nltk.word_tokenize(sentence) # 转为列表 >>> ['jo', 'run', 'to', 'the', 'rooms', 'and', 'tell', 'mrs']
tokenized_sentences.append(tokenized_sentence) # append the list of wtokenized_sentencesto the list of lists
print("句子总数量:len(tokenized_sentences) = {0}".format(len(tokenized_sentences)))
# 构建词典库
vocabulary = list(set(OOV.get_nplus_words(tokenized_sentences, 2)))
vocabulary = vocabulary + [''] + ['' ]
print("词典库大小:len(vocabulary) = {0}".format(len(vocabulary)))
# 将低频单词换成:' )
else:
backward_n_words.append(w)
for w in forward_n_words_i:
if w not in vocabulary: # Convert to UNK if word not in vocab
forward_n_words.append('' )
else:
forward_n_words.append(w)
# 查找与“当前词”编辑距离为1、2的所有真词【Suggestions include input word only if the input word in vocab】
if word in vocabulary:
suggestions = [word] + list(Candidates.edit_one_letter(word).intersection(vocabulary)) or list(Candidates.edit_two_letters(word).intersection(vocabulary))
else:
suggestions = list(Candidates.edit_one_letter(word).intersection(vocabulary)) or list(Candidates.edit_two_letters(word).intersection(vocabulary))
print("SpellCorrector.py---->get_corrections---->word = {0}----backward_n_words_i = {1}----backward_n_words = {2}----forward_n_words_i = {3}----forward_n_words = {4}".format(word, backward_n_words_i, backward_n_words, forward_n_words_i, forward_n_words))
print("SpellCorrector.py---->get_corrections---->entered word = {0}----suggestions = {1}".format(word, suggestions))
words_prob = {} # 所有候选词的概率字典
print("SpellCorrector.py---->get_corrections---->开始遍历单词 {} 的suggestions中的候选词:".format(word))
for w in suggestions: # 遍历所有候选词
print("\n\tSpellCorrector.py---->get_corrections---->候选词---->w = {0}".format(w))
_, min_edits = Candidates.min_edit_distance(word, w) # 计算候选词与当前词的最短编辑距离
print("\t\tSpellCorrector.py---->get_corrections---->候选词 w 与 当前词 word 之间的最短编辑距离---->min_edits = {0}".format(min_edits))
error_prob = 1
if True: # use error model only when it is non word error【if not word in vocabulary】
if min_edits <= 2: # To make sure all suggestions is within edit distance of 2
edit = ErrorModel.editType(w, word) # 查看编辑类型
print("\t\tSpellCorrector.py---->get_corrections---->候选词 w 与 当前词 word 之间的编辑类型---->edit = {0}".format(edit))
if edit: # Some word cannot find edit
if edit[0] == "Insertion":
error_prob = ErrorModel.channelModel(edit[3][0], edit[3][1], 'add', corpus) # 根据编辑错误类型,计算噪音通道模型概率 P(x|w)(Noisy Channel Model)
if edit[0] == 'Deletion':
error_prob = ErrorModel.channelModel(edit[4][0], edit[4][1], 'del', corpus) # 根据编辑错误类型,计算噪音通道模型概率 P(x|w)(Noisy Channel Model)
if edit[0] == 'Reversal':
error_prob = ErrorModel.channelModel(edit[4][0], edit[4][1], 'rev', corpus) # 根据编辑错误类型,计算噪音通道模型概率 P(x|w)(Noisy Channel Model)
if edit[0] == 'Substitution':
error_prob = ErrorModel.channelModel(edit[3], edit[4], 'sub', corpus) # 根据编辑错误类型,计算噪音通道模型概率 P(x|w)(Noisy Channel Model)
language_prob = get_probability(backward_n_words, w, forward_n_words, unigram_counts, bigram_counts, len(vocabulary), k=1.0) # N-gram语言模型的概率 p(w)
w_total_prob = error_prob * language_prob # 计算最终概率 p = p(x|w)*p(w)
print("\t\t候选词:{0}----Noisy Channel模型概率:language_prob = {1}----N-gram模型概率:language_prob = {2}----最终概率:w_total_prob = {3}".format(w, error_prob, language_prob, w_total_prob))
words_prob[w] = w_total_prob
n_best = Counter(words_prob).most_common(n)
print("SpellCorrector.py---->get_corrections---->entered word = {0}----n_best = {1}".format(word, n_best))
return n_best
# GUI CREATION THROUGH PYTHON'S TKINTER LIBRARY
from tkinter import *
# creates a base GUI window
root = Tk()
# creating fixed geometry of the tkinter window with dimensions 700x900
root.geometry("705x780")
root.configure(background="gray76")
root.title("NLP Spell Checker") # Adding a title to the GUI window.
Label(root, text="Project by Group One", fg="navy", bg="gray", font="Arial 11 bold italic", height=3, width=200).pack()
# function to retrieve the sentence typed by a user & pass the input through get_corrections() to check spellings
tokenized_sentence = []
non_real_word = []
clicked = StringVar()
# 例句:English is took to be a foreigh language which students choose to learn.
def getInput():
global tokenized_sentence
# 预处理输入文本【Preprocess the original text input to get clean input】
sentenceValues = entredSentence.get('1.0', '50.0')
sentenceValues = sentenceValues.lower().replace(",", "").replace(".", "") # 去除标点符号
outputSentence.delete(0.0, 'end')
outputSentence.insert(END, sentenceValues)
# 英文句子分词成单词列表【tokenize the sentence and save the values to tokenized Words variable】
tokenized_sentence = nltk.word_tokenize(sentenceValues)
tokenized_sentence = [''] + tokenized_sentence + ['']
print("句子分词后:tokenized_sentence = {}".format(tokenized_sentence))
not_in_corpus = [] # 非词错误
real_word_error = [] # 真词错误
for word in tokenized_sentence[1:-1]: # 遍历句子中的所有单词
if word not in vocabulary: # 如果当前单词不属于单词表,则为非词错误
not_in_corpus.append(word) # 保存非词到 not_in_corpus 列表【Saving non real word to not_in_corpus list.】
else: # 真词
index = tokenized_sentence.index(word)
candidate_words = get_corrections([tokenized_sentence[index - 1]], word, [tokenized_sentence[index + 1]], vocabulary, n=1) # 获取当前真词的候选集
print("index = {0}----word = {1}----candidate_words = {2}".format(index, word, candidate_words))
if candidate_words[0][0] != word: # 如果当前真词的候选集里的概率得分最高者不是当前词,则说明当前词为真词错误
real_word_error.append(word) # 保存真词错误到 real_word_error【saving a real & existing word to real_word_error】
print("非词错误---->not_in_corpus = {}".format(not_in_corpus))
print("真词错误---->real_word_error = {}".format(real_word_error))
print("Suitable candidate words are:")
# ===================================================显示”非词错误&真词错误“:开始===================================================
# Checking for non_word errors from the input sentence typed by a user
options = []
print("-" * 50, "开始处理非词错误&真词错误", "-" * 50)
for word in not_in_corpus:
print("非词错误---->word = {0}".format(word))
offset = '+%dc' % len(word) # +5c (5 chars)
print("offset = {0}".format(offset))
pos_start = entredSentence.search(word, '1.0', END) # search word from first char (1.0) to the end of text (END)
# check if the word has been found
while pos_start:
pos_end = pos_start + offset # create end position by adding (as string "+5c") number of chars in searched word
entredSentence.tag_add('red_tag', pos_start, pos_end) # add tag
pos_start = entredSentence.search(word, pos_end, END) # search again from pos_end to the end of text (END)
options.append(word)
print("options = {0}".format(options))
# checking for real word error from the input sentence by a user
for word in real_word_error:
print("真词错误---->word = {0}".format(word))
offset = '+%dc' % len(word) # +5c (5 chars)
print("offset = {0}".format(offset))
pos_start = entredSentence.search(word, '1.0', END) # search word from first char (1.0) to the end of text (END)
# check if the word has been found
while pos_start:
pos_end = pos_start + offset # create end position by adding (as string "+5c") number of chars in searched word
entredSentence.tag_add('blue_tag', pos_start, pos_end) # add tag
pos_start = entredSentence.search(word, pos_end, END) # search again from pos_end to the end of text (END)
options.append(word)
print("options = {0}".format(options))
# Creating a drop down menu to display the misspelled words.
# From this drop down list, a user selects the misspelled word that they need suggestions for.
drop = OptionMenu(root, clicked, *options)
drop.configure(font=("Arial", 10))
drop.pack()
drop.place(x=305, y=350)
# ===================================================显示”非词错误&真词错误“:结束===================================================
# ===================================================显示建议的“替换单词”:开始===================================================
# Function to display a list of the suggested words
def showSuggestions():
print("\n\n\n", "-" * 50, "显示建议的'替换单词'", "-" * 50)
suggestedWords.delete(0, END)
options = []
word_to_replace = clicked.get()
print("word_to_replace = {0}".format(word_to_replace))
index = tokenized_sentence.index(word_to_replace)
print("index = {0}".format(index))
candidate_words = get_corrections([tokenized_sentence[index - 1]], word_to_replace, [tokenized_sentence[index + 1]], vocabulary, n=3) # 显示前3个候选词
print("candidate_words = {0}".format(candidate_words))
for i in range(len(candidate_words)):
suggestedWords.insert(END, candidate_words[i][0])
# ===================================================显示建议的“替换单词”:结束===================================================
# Function to replace a misspelled word with the correct word from a list of suggested words
def replace_word():
word_to_replace = clicked.get()
selected_word = suggestedWords.get(ANCHOR)
offset = '+%dc' % len(word_to_replace) # +5c (5 chars)
idx = '1.0'
# searches for desried string from index 1
idx = outputSentence.search(word_to_replace, idx, nocase=1, stopindex=END)
# last index sum of current index and
# length of text
lastidx = '% s+% dc' % (idx, len(word_to_replace))
outputSentence.delete(idx, lastidx)
outputSentence.insert(idx, selected_word)
lastidx = '% s+% dc' % (idx, len(selected_word))
# Input widget for sentence to be entred by user
Label(text="Enter sentence here (Max Words: 50)", font="Arial 11 bold").place(x=15, y=80)
entredSentence = Text(root, height=10, width=60)
entredSentence.configure(font=("Arial", 11))
entredSentence.place(x=15, y=110)
submit_btn = Button(root, height=1, width=10, text="Submit", command=getInput).place(x=585, y=110)
entredSentence.tag_config("red_tag", foreground="red", underline=1)
entredSentence.tag_config("blue_tag", foreground="blue", underline=1)
# Creating a suggestions widget for the suggested words to correct the mispelled word
Label(text="List of suggested words to replace misspelled word:", font="Arial 11 bold").place(x=15, y=320)
suggestedWords = Listbox(root, height=10, width=30)
suggestedWords.configure(font=("Arial", 11))
# suggestedWords.config(state = "disabled")
suggestedWords.place(x=15, y=350)
sugg_btn = Button(root, text="Show suggestions", command=showSuggestions).place(x=305, y=380)
replace_btn = Button(root, text="Replace Word", command=replace_word).place(x=305, y=410)
# Output widget for the sentence entered and open for correcting mispelled words
Label(text="Corrected Input Sentence by User:", font="Arial 11 bold").place(x=15, y=560)
outputSentence = Text(root, height=10, width=60, wrap=WORD)
outputSentence.configure(font=("Arial", 11))
# outputSentence.config(state = "disabled")
outputSentence.place(x=15, y=590)
# Activating the GUI
root.mainloop()
输入文本:
English is took to be a foreigh language which students choose to learn.
打印结果:
在这里插入代码片
八、Noisy Channel Model(噪音通道模型)应用场景
1、拼写纠错
下图中的 P ( 正 确 的 写 法 ) P(正确的写法) P(正确的写法) 就是根据训练集语料库构建的N-gram语言模型。即:构建unigram、bigram 字典库({字符串:在语料库中出现的次数})

2、机器翻译

3、语音识别

4、密码破解

5、OCR
九、第三方库
- 中文文本纠错:PyCorrector
参考资料:
斯坦福大学-自然语言处理入门 笔记 第五课 拼写纠正与噪音通道(Noisy Channel)
Noisy Channel模型纠正单词拼写错误
NLP-拼写纠错(spell correction)实战
中英文拼写纠错开源框架梳理
英文单词拼写纠错
【NLP】单词纠错——python小练习
How to Write a Spelling Corrector
结合N-gram模型与句法分析的语法纠错
【深度学习】PyCorrector中文文本纠错实战
自然语言处理-错字识别(基于Python)kenlm、pycorrector
拼写纠错与相关模型