JAVA进阶——JVM
文章目录
- 1、JVM
-
- 1.1、 JVM与操作系统之间的关系?
- 1.2、 JVM的体系结构?
- 2.2、沙箱安全机制(了解就行)
- 2.3、native关键字
- 2.4、PC寄存器的作用
-
- PC寄存器面试常见问题
- 2.5、方法区
- 2.6、了解栈
-
- 1.栈、堆、方法区存在的交互关系(重点)
- 2.什么是栈溢出StackOverFlowError?怎么分析?
- 2.7、堆
-
- 玩一下JVM(加深理解)
- 1.你遇到过OOM吗?是如何解决的?
- 2.GC 垃圾回收主要发生在哪里?
- 3.什么是OOM,为什么会发生OOM?
- 4. 发生OOM时,GC的执行流程?
- 5.玩一下JProfiler工具,分析OOM原因
- 3、讲一讲GC的几种算法?
-
- 什么是JVM的垃圾回收?
- 一:那些垃圾需要回收?
-
- 1.引用计数算法
- 2.可达性分析算法
- 二:有哪些重要的垃圾回收算法?
-
- 1. 标记-清除算法
- 2.标记-整理算法
- 3.标记-复制算法
- 三、垃圾回收的具体流程是怎样的?
- GC题目
- 4、JMM
1、JVM
现在人们对jvm(Java虚拟机)的探究式越来越深了,如果我们想更了解java,jvm是我们必须要跨过去的一道坎。
学习Java的人对jvm这个词并不陌生,来了解一下java的进阶知识Java虚拟机吧!
学习jvm的方法:
jvm的大多数知识点,我们真正要去实现的并没有几个,很多都是以理论学习为主。善用百度和思维导图(参考别人画好的,非常丰富),通过思维导图或者百度,把一个点一个点搞清楚。
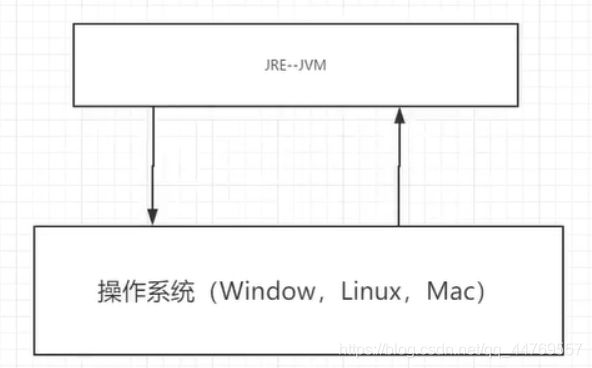
1.1、 JVM与操作系统之间的关系?
jvm是运行在操作系统上的,操作系统是jvm的下一层。
jvm相当于一个软件,它是用c语言写的,jvm和其他运行在操作系统上的软件是并列的(当然,操作系统也是一个软件)。所以我们在计算机上运行的java程序是有地方限制的,只能跑在jvm上,这个环境就叫做jre(Java运行环境),jre包含了jvm。
所以如果我们在另一些平台上,比如linux,只要我们不在上面开发,安装jre就行了。
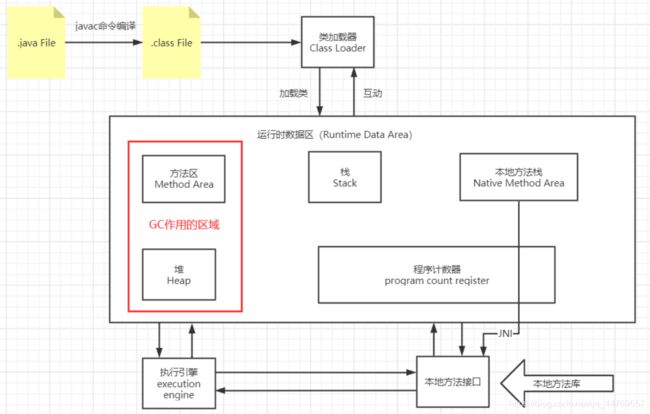
1.2、 JVM的体系结构?
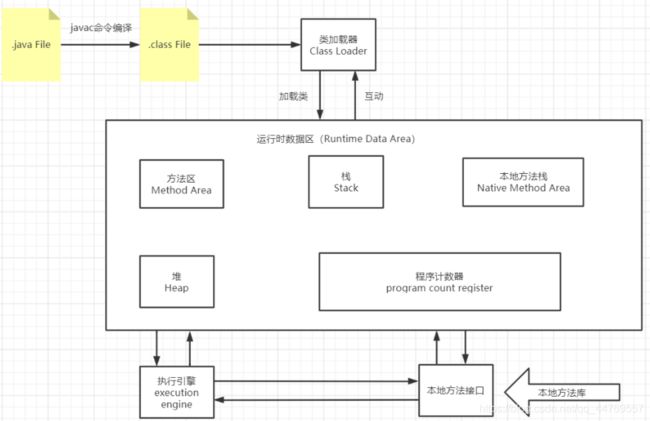
解释:
类加载器和jvm交互;jvm里还有本地方法区,需要访问本地方法,所以在运行时数据区外还有本地方法接口,本地方法接口和本地库相连。
这些东西都少不了执行,所以有个执行引擎。
Runtime Exception一般发生在里。
JVM调优在哪些地方执行
在栈、本地方法栈和程序计数器里面是没有垃圾的,垃圾回收机制执行的地方不会在这三个区域。所以JVM调优是在方法区和堆(主要)里面进行的。

上面的是jvm的简图,详细图如下。接下来的学习,就是围绕这些点去展开。


解释:
-
在java文件编译成class文件之后,类加载器将class加载到jvm。
-
Class Loader(类加载器)将Class文件加载到内存,并初始化,可以把这个class类当成是一个模板(抽象的),以后new 的对象(具体的)都是以这个模板来进行的。
-
用该模板new 来创建一个实例对象,比如car1、car2、car3,这三个对象都是不一样的(下面代码验证)
-
把一个对象变回一个Class,使用getClass方法,得到的模板只有一个。
class Car {
public static void main(String[] args) {
//类是模板,对象是具体的
//创建三个对象,发现他们的哈希值并不相同
Car car1 = new Car();
Car car2 = new Car();
Car car3 = new Car();
System.out.println(car1.hashCode());//460141958
System.out.println(car2.hashCode());//1163157884
System.out.println(car3.hashCode());//1956725890
//这三个对象调用getClass方法,发现得到的是同一个Class
Class c1 = car1.getClass();
Class c2 = car2.getClass();
Class c3 = car3.getClass();
System.out.println(c1.hashCode());//685325104
System.out.println(c2.hashCode());//685325104
System.out.println(c3.hashCode());//685325104
}
}
也可以通过Class的getClassLoader方法获得它是被哪个加载器加载的。
ClassLoader classLoader = c1.getClassLoader();
ClassLoader parent = classLoader.getParent();//获取加载器的父级加载器
ClassLoader parent1 = parent.getParent();
System.out.println(classLoader);//AppClassLoader 应用类加载器,也叫系统类加载器
System.out.println(parent);//ExtClassLoader 扩展类加载器
System.out.println(parent1);//null 根加载器,c语言写的,java获取不到。
说到类加载器,会想到双亲委派机制。
简单了解三个加载器和双清委派机制(需要熟悉,面试大概率会问):Java基础——注解和反射 或者百度
2.2、沙箱安全机制(了解就行)
一般我们听到比较多的是双亲委派,这个机制会比较少一点。这个是源于Java基础到现在一步一步演化过来的。
java中的安全模型(沙箱机制)
组成沙箱的基本组件:
-
字节码校验器)(bytecode verifier):确保ava类文件遵循ava语言规范。这样可以帮助Java程序实现内存保护。但并不是所有的类文件都会经过字节码校验,比如核心类。
-
类装载器(class loader) :其中类装载器在3个方面对Java沙箱起作用
- 它防止恶意代码去干涉善意的代码; //双亲委派机制
- 它守护了被信任的类库边界;
- 它将代码归入保护域,确定了代码可以进行哪些操作。
虚拟机为不同的类加载器载入的类提供不同的命名空间,命名空间由一系列唯一的名称组成,每一个被装载的类将有一个名字,这个命名空间是由Java虚拟机为每一个类装载器维护的,它们互相之间甚至不可见。
类装载器采用的机制是双亲委派模式。
1.从最内层VM自带类加载器开始加载,外层恶意同名类得不到加载从而无法使用;
2由于严格通过包来区分了访问域,外层恶意的类通过内置代码也无法获得权限访问到内层类,破坏代码就自然无法生效。
存取控制器(access controller)∶存取控制器可以控制核心API对操作系统的存取权限,而这个控制的策略设定,可以由用户指定。安全管理器(security manager)︰是核心API和操作系统之间的主要接口。实现权限控制,比存取控制器优先级高。- 安全软件包(security package) : java.security下的类和扩展包下的类,允许用户为自己的应用增加新的安全特性,包括:
- 安全提供者。
- 消息摘要
- 数字签名 (keytool、https)
- 加密
- 鉴别
2.3、native关键字
相信很多人都没有见过 java中的native关键字。
初见native,是在Thread中。来看这个例子:
java是启动一个线程
public class Test02 {
public static void main(String[] args) {
new Thread().start(); //启动线程
}
}
点进start查看源码,发现该方法调用了一个start0()的方法
public synchronized void start() {
...
try {
start0();//执行后线程启动
started = true;
}
...
//start0
private native void start0();
发现start0()方法并没有方法体。这不是我们在interface类里面写接口才这么写的吗。它只有被native 修饰。
如果我们在普通类里面这么写,编译是会报错的

而加上native修饰就不会报错了,为什么?
总结:
- 这种现象我们不难得出它的核心并不是start0,而是native。
- 凡是带了native关键字的,说明java的作用域达不到了,这是去调用底层c语言的库
- 结合上面的1.2的图,在jvm体系结构中,有一个本地方法库和本地方法接口(JNI :java native interface)。
- 使用native 会进入本地方法栈。本地方法栈里面登记了本地方法。 当我们调用本地方法接口(JNI)的时候,java执行不到,本地方法接口去调用本地方法库,然后去执行库里面的方法。
- JNI(本地方法接口)的作用:扩展了Java的使用、融合了不同编程语言为Java所用。
- 背景(题外话):java诞生之初,c和c++横行,java想要立足,那么它必须要有调用c、c++的程序。
- 它在内存区域中开辟了一块标记区域(本地方法栈):用来登记native method、
- 在最终执行的时候,通过JNI加载本地方法库。
一般我们也很少去接触底层,比较常见的可能就只有java驱动打印机,管理系统。如果面试的时候你有机会谈这些,嘿嘿嘿 可能面试官会开心。(唬住了就准备要50k,没唬住就要5k )
2.4、PC寄存器的作用
PC寄存器(Program Counter Register)用来存储指向下一条指令的地址,也是将要执行的指令代码。由执行引擎读取下一条指令。
1.它是一块很小的内存空间,几乎可以忽略不计。也是运行速度最快的存储区域
2.在jvm规范中,每个线程都有它自己的程序计数器,是线程私有的,生命周期与线程的生命周期保持一致
3.任何时间一个线程都只有一个方法在执行,也就是所谓的当前方法。程序计数器会存储当前线程正在执行的java方法的JVM指令地址;如果是在执行native方法,则是未指定值(undefined),因为程序计数器不负责本地方法栈。
4.它是程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成
5.字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令
6.它是唯一一个在java虚拟机规范中没有规定任何OOM(Out Of Memery)情况的区域,而且没有垃圾回收
PC寄存器面试常见问题
1.使用PC寄存器存储字节码指令地址有什么用呢(为什么使用PC寄存器记录当前线程的执行地址呢)
(1)多线程宏观上是并行(多个事件在同一时刻同时发生)的,但实际上是并发交替执行的
(2)因为CPU需要不停的切换各个线程,这时候切换回来以后,就得知道接着从哪开始继续执行
(3)JVM的字节码解释器就需要通过改变PC寄存器的值来明确下一条应该执行什么样的字节码指令
所以,众多线程在并发执行过程中,任何一个确定的时刻,一个处理器或者多核处理器中的一个内核,只会执行某个线程中的一条指令。这样必然导致经常中断或恢复,如何保证分毫无差呢?每个线程在创建后,都会产生自己的程序计数器和栈帧,程序计数器在各个线程之间互不影响。
2.PC寄存器为什么会设定为线程私有?
(1)我们都知道所谓的多线程在一个特定的时间段内只会执行其中某一个线程的方法,CPU会不停滴做任务切换,这样必然会导致经常中断或恢复,如何保证分毫无差呢?
(2)为了能够准确地记录各个线程正在执行的当前字节码指令地址,最好的办法自然是为每一个线程都分配一个PC寄存器,这样一来各个线程之间便可以进行独立计算,从而不会出现相互干扰的情况。
2.5、方法区
Method Area 方法区
方法区是被所有线程共享,所有字段和方法字节码(区分方法),以及一些特殊方法,如构造函数,接口代码也在此定义,简单说,所有定义的方法的信息都保存在该区域,此区域属于共享区间;
静态变量(static)、常量(final)、类(Class)信息(构造方法、接口定义)、运行时的常量池存在方法区中,但是实例变量存在堆内存中,和方法区无关
助记:
比如说有一个test类
public class Test02 {
private int a;
private String name ;
private static final int TE = 0;
public static void main(String[] args) {
Test02 testA = new Test02();
testA.a=1;
testA.name="张三";
}
}
它的存储情况

面试官可能会给你个类,让你画这个存储区间。
2.6、了解栈
栈:是一种数据结构
程序=数据结构+算法。
栈特点:先进后出,后进先出。
队列特点:先进先出(FIFO)
为什么main方法最先执行,最后结束?
执行main方法,会将它压栈,那他就在栈底,main方法中调用了其他方法(test1),会将其他的方法也压进来,然后等当前执行的其他方法结束后,会从栈中弹出,最后到main方法,main方法结束,程序运行结束。这保证了程序执行的有序性。线程结束,栈内存也就释放。 对于栈来说,不存在垃圾回收问题。

栈可以存放:八大基本类型,对象引用,实例的方法。
栈运行原理:使用栈帧来连接方法。程序正在执行的方法,一定在栈的顶部。

1.栈、堆、方法区存在的交互关系(重点)
举例:对象在内存中是如何实例化的,先看代码,再看图解。
下面这段代码定义了一个Studnet类,有两个成员变量name,age,和一个公有方法method。
执行main方法,定义了两个局部变量。new实例化了一个Student对象,给它的属性赋值,调用对象的公有方法,然后main方法执行结束。
public class Student {
//类的成员变量
private String name;
private int age;
//类的方法
public void method(){
System.out.println("姓名:"+this.name+" 年龄:"+this.age);
}
public static void main(String[] args) {
//定义局部变量
int number;
String sex;
//实例化对象
Student student = new Student();
//赋值
student.name = "赵子龙";
student.age = 18;
student.method();//调用对象的方法
}
}
内存变化过程
1.加载类,首先main和类中的成员变量进入到方法区
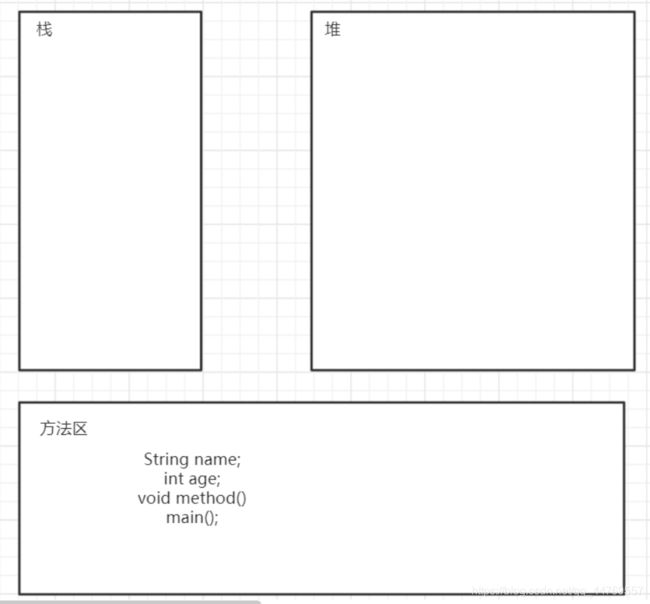
2.程序执行到main方法,main方法进入栈区(压栈);
main方法中定义了一个Student对象,此时还没有轮到局变量

3.程序执行到new Studen(),会在堆内存中开辟一块区间,用来存放该实例对象,然后才是将实例变量和成员方法(取地址的值)放在该内存中

4.然后给对象的成员变量赋值 student.name = "赵子龙";student.age = 18;,会先在栈中找到student,根据地址找到实例对象,进行赋值操作。

然后程序执行到student.method()方法时,先将该方法压栈,然后到栈区找到引用变量student,根据地址在堆中找到对象实例进行方法调用,最后调用方法执行完会立马从栈中弹出(出栈)
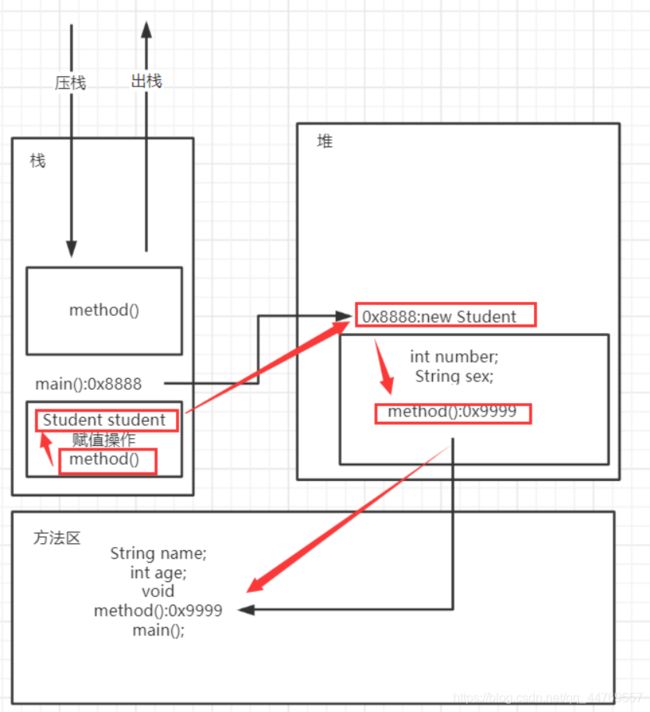
最后,当main方法执行完后,main也会出栈,程序结束,这块内存也被回收。
2.什么是栈溢出StackOverFlowError?怎么分析?
StackOverflowError代表的是,当栈深度超过虚拟机分配给线程的栈大小时就会出现此error。
无限递归:
public class Test03 {
public static void main(String[] args) {
dfs();
}
public static void dfs(){
dfs();
}
}/*StackOverflowError 栈溢出错误*/
注意:是递归的错误,才出现Stack满的情况,而无限循环一般不会占用更多的内存或者具体的Stack,只是占cpu而已,所以不会抛此错误。无限循环可能会OOM
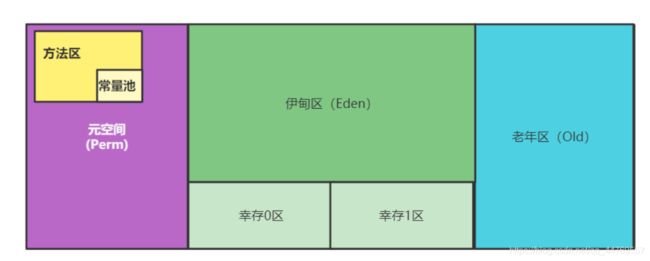
2.7、堆
堆(Heap):
一个JVM只有一个堆内存,堆内存的大小是可以调节的。
类加载器读取了类文件后,一般会把什么东西放到堆中?
类、方法、常量、变量,和保存了我们引用类型的真实对象。
堆内存还细分为三个区域:
- 新生区(Eden/Young)
- 老年区(old)
- 永久区 (Perm,JDK8及以后的版本改了,叫元空间)

说到堆,不得不了解垃圾回收机制 漫画:什么是JVM的垃圾回收?
新生区
- 是类诞生成长的地方、甚至死亡
- 伊甸园,所有的对象都是在伊甸区new出来的
- 幸村区(0,1),经过Minor GC后,存活的对象会放在这里
经过研究,99%的对象都是临时对象
老年区
经过Full GC (大概15次),存活下来的,放在这里
永久区
这个区域常驻于内存。用来存放JDK自身携带的Class对象,包括一些Interface元数据,存储的是Java运行时的一些环境或类信息。**这个区域不存在垃圾回收!**关闭JVM就会释放这个区域的内存。
- JDK1.6之前:存在永久代,常量池是在方法区
- JDK1.7 :存在永久代,但是慢慢退化了,
去永久代,常量池在堆中。 - JDK1.8之后:无永久代(叫元空间),常量池在远空间
-
方法区里面东西的可以被所有线程共享。
-
元空间它比较特别,有些人也会称元空间为非堆,为了能和堆区分开,但是它实际上还是堆。
-
元空间逻辑上存在,物理上不存在
-
方法区在元空间里占一小块内存,常量池在方法区中占更小的一块内存。
一个启动类,加载了大量的第三方jar包。Tomcat部署了太多应用,大量动态生成了的反射类(在方法区),不断被加载,直到内存满,就会出现OOM。
玩一下JVM(加深理解)
接下来可以用代码和控制台来查看堆里划分这些区的情况。
1.查看JVM使用内存的情况
public class Test04 {
public static void main(String[] args) {
//返回JVM试图使用的最大内存
long max = Runtime.getRuntime().maxMemory();
//返回JVM的初始总内存
long total = Runtime.getRuntime().totalMemory();
System.out.println("max="+ max + "字节"+max/(double)(1024*1024)+"MB");
System.out.println("total="+ total + "字节"+total/(double)(1024*1024)+"MB");
/**
* max=1862270976字节 1776.0MB
* total=126877696字节 121.0MB
*
* 博主机子的运行内存为 8G,实际为 7.8G~7987MB
* 计算:1776/7987~ 1/4
* 121/7987 ~ 1/64
*/
}
}
得出结论:默认情况下,JVM分配的总内存是电脑内存的1/4,初始化内存是1/64. 不过可以调。
2.调节JVM的内存分配,分析
使用的是Itellij IDEA
1.点击Edit
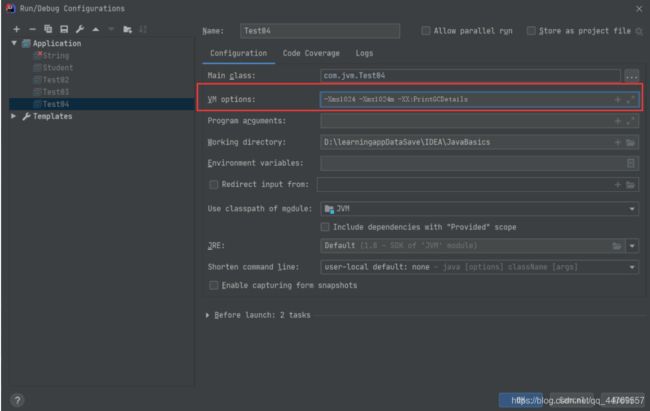
在这里面输入-Xms1024m -Xmx1024m -XX:+PrintGCDetails,PrintGCDetails表示打印出GC的一些信息,点击保存。然后运行
发现内存分配已经变了,我们调节成功,虽然不是1024M,这是精度问题。
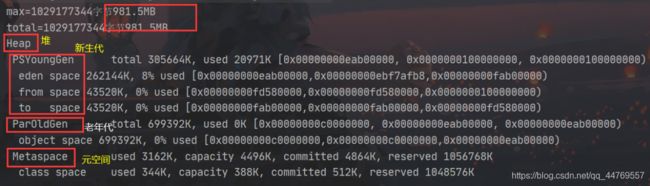
分析数据:
新生代的内存加上老年代的内存:305664K+699392K = 1005056K~ 981.5M,即元空间的大小并不算在里面。
验证了上面的一点元空间逻辑上存在,物理上不存在.
1.你遇到过OOM吗?是如何解决的?
遇到OOM的时候,可以先尝试扩大堆内存,看结果。如果仍然OOM,说明我们的程序有问题,可能那里在无限循环。分析内存,看一下哪里出了问题。
2.GC 垃圾回收主要发生在哪里?
在伊甸园区和老年区,因为新创建的对象大多数情况都会是在伊甸园区创建,大的对象则直接进入老年区。这里面的产生的垃圾会比较多。
3.什么是OOM,为什么会发生OOM?
OOM:Out Of Memory(内存不足)。
大家都知道在java中String字符串是可以无限的,但内存不是有限的。来复现这个错误,运行下面这段代码会OOM
public class Test03 {
public static void main(String[] args) {
String s = "abceegdfsa";
while(true){
s += s+"fldshkafksdhlaskfadjh";
}
}
}
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space //堆空间内存不足
在我们创建的对象过大,或者无限递归等等,都会发生OOM。
按照上面的方法 分配内存-Xms1024m -Xmx1024m -XX:+PrintGCDetails,然后运行来查看GC的执行情况
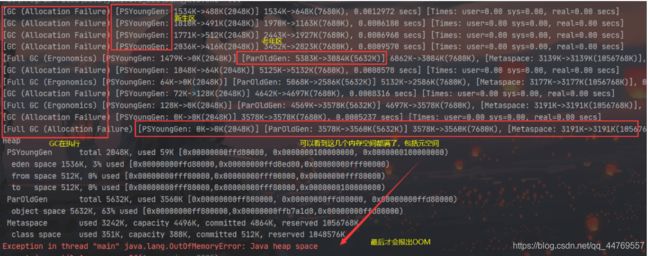
4. 发生OOM时,GC的执行流程?
1.比如说创建一个很大的对象或者数组,会首先在Eden尝试创建,如果Eden区内存不够了,创建不了,则触发Minor GC(轻量级垃圾清理)清理Eden
2.Minor GC完成后继续尝试在Eden创建,发现仍然放不下;
3.则尝试在老年代创建,发现仍然放不下,触发Full GC(重量级垃圾清理);
4.Full GC完后继续尝试在老年代创建。发现依然放不下。
6.OOM
5.玩一下JProfiler工具,分析OOM原因
问题:在一个项目中,突然出现了OOM故障,那么该如何排除?
带你如何研究为什么出错。
我们在发生OOM时,如果使用Debug一行一行分析代码的话,效率明显不高。实际工作中,如果是在线上项目,也不支持我们这样做。我们最希望看到的是程序代码里的第几行出错。
能够看到代码第几行出错,使用内存快照分析工具:MAT(Eclipse的)、Jprofiler(接下来使用该工具)。
MAT、Jprofiler的作用
- 分析Dump内存文件,快速定位内存泄漏
- 获得堆中的数据
- 获得大的对象
- …
在IDEA中安装Jprofiler

点击安装,安装好后重启IDEA。
官网下载jprofiler客户端,下载好后安装**,安装路径下不要有空格和中文(唯一要求)** JProfiler12 使用教程
建议使用10天就行。反正是来玩一玩。
在IDEA里配置好路径,完成。
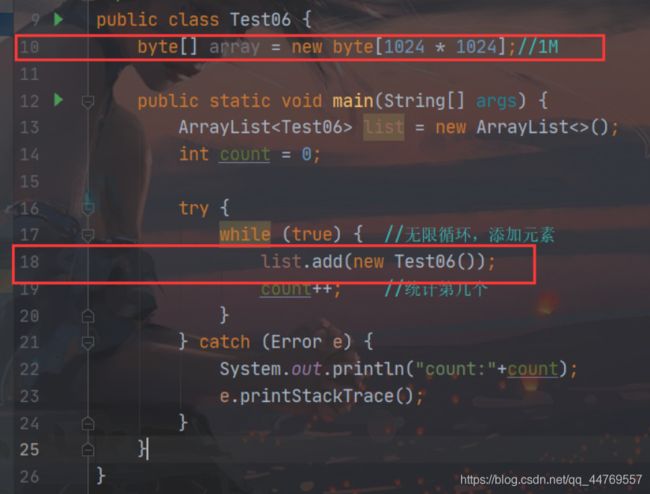
复现OOM
import java.util.ArrayList;
public class Test06 {
byte[] array = new byte[1024 * 1024];//1M
public static void main(String[] args) {
ArrayList<Test06> list = new ArrayList<>();
int count = 0;
try {
while (true) { //无限循环,添加元素
list.add(new Test06());
count++; //统计第几个
}
} catch (Error e) {
System.out.println("count:"+count);
e.printStackTrace();
}
}
}
科普一下,Dump文件:Dump文件是进程的内存镜像。可以把程序的执行状态通过调试器保存到dump文件中。
接下来,调节分配内存使它更快的能OOM(不然它要占用1个多G内存,不调也是可以的)
按照上面的步骤来调节,-Xms8m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
解释-XX:+HeapDumpOnOutOfMemoryError:如果出现了OutOfMemoryError异常,就把文件Dump出来
运行,控制台输出

我们去找到这个文件,右键该模块,打开文件夹

然后双击直接打开该文件(安装好了JProfiler工具前提下)

然后我们可以点击 最大对象 ,发现ArrayList占了很大的内存,我们可以一下子得出原因,是它炸的内存。

正常我们看出问题应该是线程再跑,虽然我们知道这个ArrayList出问题了,但是我们看不出他哪一行出问题。
接下来分析它是哪一行出问题了
点击左边的线程存储,看到所有的线程,系统线程不用管。那我们只有一个main线程,点击main线程

就可以知道问题出现在哪一行了,这里是在第10行初始化,问题在18行,然后我们就可以回到代码中定位到。确实是这样
有同学有疑问,说控制台不也是打印出来了吗?

是这样的,但是在一个大项目中,控制台可能会打印出非常多的东西,日志和一些其他的。让你看都不想看,更别说去找。善于利用工具。
举一反三:
如果是其他的异常,比如StackOverFlowError栈溢出异常,那么我们只需要将配置参数修改为+HeapDumpOnStackOverFlowError
-Xms 设置初始化内存分配大小 1/64
-Xmx 设置最大分配内存,默认1/4
-XX:+PrintGCDetails 打印GC垃圾回收信息
现在明白为什么栈里面没有垃圾,99%的垃圾都是出现在堆里面了吧?
3、讲一讲GC的几种算法?
GC的作用区域:方法区、堆
什么是JVM的垃圾回收?
顾名思义就是释放垃圾占用的空间,防止内存泄露。有效的使用可以使用的内存,对内存堆中已经死亡的或者长时间没有使用的对象进行清除和回收。
垃圾回收技术是一项不断改进与优化的技术,要想理清垃圾回收的机制,需要搞清楚下面这三个问题。
一:那些垃圾需要回收?
判断对象需要回收有两种算法。一种是引用计数算法,一种是可达性分析算法。
1.引用计数算法
给对象的引用进行计数(统计),它通过记录对象被引用的次数从而判断该对象的重要程度。
每当有一个地方引用它时,计数器就加1,当引用失效时,计数器就减1;当某个对象的引用计数为0,说明该对象没有被使用,从而被JVM当成垃圾,对它进行回收。
不过引用计数算法也存在着一定的问题
当两个对象相互引用时,由于他们的相互引用对方所以计数器不为零,就会导致这两个对象无法被回收。
所以JVM采用了另一种机制来判断对象是否存活,那就是可达性分析算法。
2.可达性分析算法
确定对象哪些还“存活”着(通过任何途径都无法使用的对象)。
首先确定一系列的根对象(GC Roots),并从根对象为起点,根据对象中的引用关系搜索出一条引用链(Reference Chain),在引用链中的对象就存活,不在的就被认定位可回收的对象。
可以作为根对象的有下面这几种(看不懂不要背,以后再回来看。)
①虚拟机栈中的引用对象(正在运行的方法使用到的变量,参数等)
②方法区中静态属性引用对象(static关键字声明的字段)
③方法区中常量引用的对象(final关键字声明的字段)
④本地方法栈中引用的对象(native方法)
⑤Java虚拟机内部的引用。(系统内部的东西当然能作为根)
二:有哪些重要的垃圾回收算法?
1. 标记-清除算法
分两个步骤:
• 标记
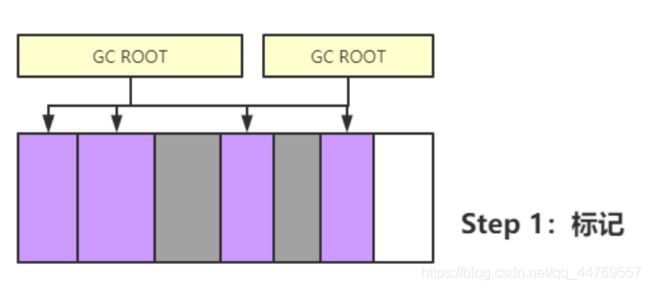
没有在引用链(GC ROOT)中的对象会被标记(灰色),这些对象会被判定为需要被回收。
• 清除

将被标记(灰色)的对象清除。
需要注意的是:所谓的清除,并不需要真正地把整个内存的字节进行清零操作,只是把空闲对象的起始结束地址记录下来放入空闲列表里,表示这段内存是空闲的。
优点: 速度快,只需要做个标记就能知道哪一块需要被回收,不需要额外空间。
缺点:
一是执行效率不稳定。
二是会涉及到内存碎片化的问题。标记清除之后会产生大量不连续的内存碎片,当程序在运行过程中需要分配较大对象时,无法找到足够的连续内存而造成内存空间浪费。
解决该问题:
标记复制算法和标记整理算法,都是对标记清除算法缺点的改进。
2.标记-整理算法
标记整理算法与标记清除算法很相似,但显著的区别是:标记清除算法仅对不存活的对象进行处理,剩余存活对象不做任何处理,这就造成了内存碎片的问题;而标记整理算法不仅对不存活的对象进行清除,还对存活的对象进行重新整理,因此不会产生内存不连续的现象。


标记-整理算法弊端:涉及到了对象的移动,在整理阶段,由于移动了可用对象,需要去更新引用。效率会变低。
3.标记-复制算法
标记-复制算法,相比前面的比较不同,他将内存空间分为两块,在垃圾回收时将正在使用的内存中的存活对象复制到未被使用的内存块中,然后再清除正在使用的内存块中的所有对象。最后再交换两个内存的角色,最后完成垃圾回收
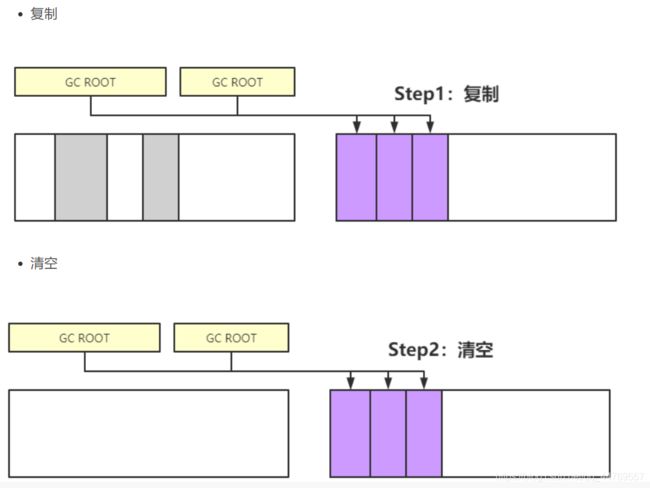

优点: 标记复制算法提升了效率,也不会参数碎片问题。
缺点: 标记复制算法的缺点也是十分明显的,它需要双倍空间。
三、垃圾回收的具体流程是怎样的?
参考博客:
https://blog.csdn.net/bjweimengshu/article/details/117677385?utm_source=app&app_version=4.9.3&code=app_1562916241&uLinkId=usr1mkqgl919blen
总结:
从三个维度来思考
内存效率:标记复制算法>标记清除算法>标记整理(压缩清理)算法
内存整齐度:标记复制算法=标记清除算法>标记整理(压缩清理)算法
内存利用率:标记整理(压缩清理)算法>标记清除算法>标记复制算法
难道没有最优算法吗?
没有,只有最合适的算法。JVM不会只采用一种算法,每种算法都有优点,JVM会结合三种算法协同工作,JVM的分代垃圾回收机制就是具体的实现。在JVM中,堆内存划会划分区域:新生代、老年代,根据年代的特点选择合适的算法。
年轻代:
- 存活率低
- 复制算法
老年代:
- 区域大、存活率高
- 标记清除(碎片不是太多的时候)+标记压缩混合实现
所谓JVM调优,就是在调这些东西。比如说调成先清除多少次,才去压缩。而不是每次都去压缩。
GC题目
- JVM的内存模型和分区~详细到每个区放什么?
- 堆里面的分区有哪些?Eden,form,to,老年区,说说他们的特点!
- GC的算法有哪些?(标记清除法,标记压缩,复制算法,引用计数器),怎么用的?
- 轻GC(Minor GC)和重GC(Full GC)分别在什么时候触发
- 垃圾回收的具体流程是怎样的?
4、JMM
JMM:Java Memory M odel(java内存模型)
1、什么是JMM?
2、它是用来干嘛的?
作用:缓存一致性协议,用来定义数据读写的规则
JMM的详细答案都可以在这篇文章里寻找
[Java并发编程:第一、三点(好文推荐)
-
JMM
- 1.原子性
- 2.可见性
- 3.有序性
8条原则摘自《深入理解Java虚拟机》
-
程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
-
锁定规则:一个unLock操作先行发生于后面对同一个锁额lock操作
-
volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作
-
传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作
-
线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作
-
线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
-
线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
-
对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
前4条规则是比较重要的,后4条规则都是显而易见的。
-
volatile
- 可见性
- 有序性(指令重排)