pandas之表连接与高级查询
上期内容:python最最最重要的数据分析工具之pandas
其实上一篇我们已经学习了数据筛选与查询,这里会介绍不一样的高级查询方式;还有一个重要的内容就是表连接。学过数据库的都知道SQL中表连接方式有左连接,右连接,内连接(交集)和全外连接(并集),pandas也可以实现这些表格的连接。
✒️个人主页➡️:进来看看吧
系列专栏:保你不亏的

文章目录
- 一、高级查询
-
- 1.1、query(条件)
- 1.2、文本筛选 str.contains()
- 1.3、截断函数 truncate()
- 二、表连接
-
- 2.1、pandas.concat([表1,表2],axis,join,sort,ignore_index,keys)
- 2.2、df.merge(right, how, on, left_on, right_on,left_index, right_index, sort, suffixes)
- 2.3、df.join([df],on)
一、高级查询
1.1、query(条件)
a、单条件筛选
df = pd.DataFrame({'name':['王一','李二','赵四'],'class':['一班','二班','一班'],'sex':['男','女','女'],'score':[88,98,78]})
# 查询 分数在80分以上的的学生信息
df.query('score >80')

b、多条件筛选
# 查询 性别女 且 分数为78 的学生信息
df.query('sex=="女" and score==78')

1.2、文本筛选 str.contains()
"""
用法:str.contains(pat, case=True, flags=0, na=nan, regex=True)是否包含查找的字符串
参数:
pat : 字符串/正则表达式
case : 布尔值, 默认为True.如果为True则匹配敏感
flags : 整型,默认为0(没有flags)
na : 默认为NaN,替换缺失值.
regex : 布尔值, 默认为True.如果为真则使用re.research,否则使用Python
返回值: 布尔值的序列(series)或数组(array)
"""
df = pd.DataFrame({'name':['王一小','李二池','赵四'],'class':['一班','二班','一班'],'sex':['男','女','女'],'score':[88,98,78]})
# 筛选出姓名为三个字的学生信息
a = df['name'].str.contains('\w{3}') # 返回的是布尔型 True或False \w{3} 正则表达式 代表三个字符
df[a]
# 筛选出 一班 的学生信息
df[df['class'].str.contains('一班')]

1.3、截断函数 truncate()
在使用.truncate()函数对df的某列进行数据筛选之前,需要先使用df = df.set_index('列名'),
将该列设置为索引,再使用df.sort_index()索引升序。.
用法:DataFrame.truncate(before=None, after=None, axis=None, copy=True)
参数 before:date,string,int,是指截断此索引值之后的所有行
after:date,string,int,是指截断此索引值前的所有行
axis:{0或’index’,1或’columns’}(可选),是指轴截断。 默认情况截断索引(行)。
copy:boolean,默认为True,返回截断部分的副本
df = pd.DataFrame({
'date':['1','2','5','4','3'],
'sale_money':[34,56,78,45,35]
})
df = df.set_index('date') .sort_index()
# 筛选索引为2——4的数据
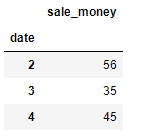
df.truncate(before='2',after='4')
df = pd.DataFrame({
'date':['2022-04-16','2022-04-19','2022-04-18','2022-04-17','2022-04-20'],
'sale_money':[34,56,78,45,35]
})
# 日期列设为索引并按时间升序
df = df.set_index('date') .sort_index()
# 将索引类型设为日期类型
df.index.astype('datetime64[ns]')
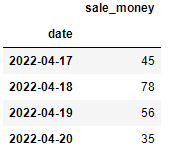
# 筛选2022—04—17之后的数据
df.truncate(before='2022-04-17')
二、表连接
2.1、pandas.concat([表1,表2],axis,join,sort,ignore_index,keys)
| 参数 | 说明 |
|---|---|
| [表1,表2] | 需要连接的表 以元组\列表格式输入 |
| axis | 连接方向:0纵向连接,1横向连接 |
| join | 连接方式:inner内连接(交集) outer全外连接(并集) |
| sort | 数据排序: True默认索引排序,False不排序 默认按照索引排序 |
| ignore_index | 是否忽略原索引 重置索引 一般纵向连接且索引无意义时用 |
| keys | [‘df1’,‘df2’] 分别数据到底属于哪个表格的 |
dic1 = {
'姓名':['王一','李二','赵四'],
'成绩':[78,56,98]
}
dic2 = {
'姓名':['王一','孙三','周六'],
'成绩':[98,88,67]
}
df1 = pd.DataFrame(dic1,index=['a','b','c'])
df2 = pd.DataFrame(dic2,index=['a','d','e'])
# 内连接显示交集,两张表的索引都有a,因此只显示索引为a的行
pd.concat([df1,df2],axis=1,join='inner')
# axis=0 纵向连接,ignore_index=True忽略索引 重置
pd.concat([df1,df2],axis=0,ignore_index=True).T # 为了方便观看, 转置
# 横向连接,并表明那些列属于那个表格的
pd.concat([df1,df2],axis=1,keys=['df1','df2'])


2.2、df.merge(right, how, on, left_on, right_on,left_index, right_index, sort, suffixes)
| 参数 | 说明 |
|---|---|
| right | 需要连接的表 |
| how | 连接方式:inner\outer\left\right |
| on | 有相同列名时,根据哪列连接 |
| left_on\right_on | 若列名不同,根据左\右表的哪个键 |
| left_index\right_index | 左\右表的索引作为连接键 |
| sort | 是否排序 |
| suffixes | 若有相同的列名,给它加后缀,如suffixes=(‘_df1’,‘_df2’)输出:列名_df1,列名_df2 默认_x,_y |
# df1 语文成绩表,df2 数学成绩表
df1 = pd.DataFrame({'name':['王一','李二','赵四'],'score':[88,98,78]})
df2 = pd.DataFrame({'name':['李二','王一','赵四'],'class':['class1','class2','class1'],'score':[86,99,48]})

# 根据索引连接两张表
df1.merge(df2,left_index=True,right_index=True)
# 根据name列连接,同时将score列进行区分(语文成绩、数学成绩)
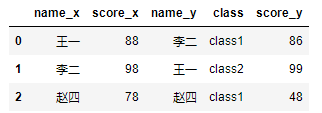
df1.merge(df2,on='name',suffixes=('_chinese','_math'))

2.3、df.join([df],on)
| 参数 | 说明 |
|---|---|
| [df] | 需要连接的表 以列表格式输入 |
| on | 根据哪列连接 |
df1=pd.DataFrame({"A":["A0","A1","A2","A3"],
"B":["B0","B1","B2","B3"],
"key":["K0","K1","K0","K1"]})
df2=pd.DataFrame({"C":["C0","C1"],
"D":["D0","D1"]},
index=["K0","K1"])
df3=pd.DataFrame({"E":["E1","E2"]})
df1.join(df2,on="key") # df1和df2连接, df1的key列和df2的索引相匹配
df1.join([df2,df3]) # 多表连接,没有on选项 根据索引连接
# 由于df2的索引与df1、df3都不同,因此输出的都是NaN, 而df1和df3索引中都有0和1 因此连接了
