python数据处理实例之月销售额时序变化及月环比可视化展现
理论基础知识可以看我之前的博客:
1、python之Numpy知识点详细总结
2、python最最最重要的数据分析工具之pandas
3、pandas之表连接与高级查询
也可以进入我的专栏:欢迎订阅哦,持续更新
python数据分析
数据处理分析的两大重要工具Numpy和pandas 常见用法基本上整理的差不多了,以后遇到更好用的方法函数等会继续总结更新。现在我们就用一个简单小栗子来检验一下成果。
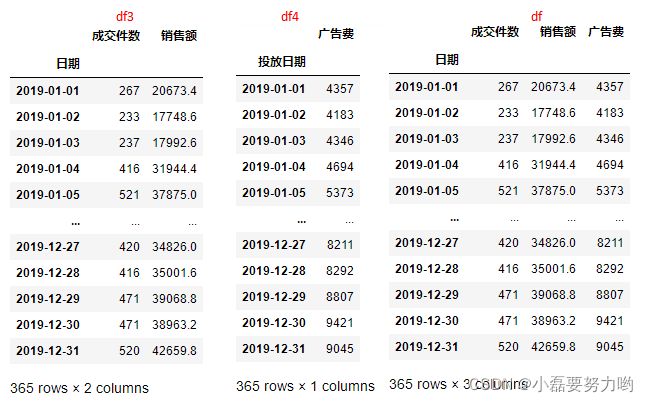
现有两张表格:销售表和广告费表
销售表字段:日期、商品名称、成交件数、销售额
广告费表字段:日期、广告费
需求: 1、分别按天和月分析销售额的变化情况 以及月环比情况
2、分析销售额与广告费的散点图关
0、前期准备
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt # 画图专用库 或者使用seaborn画图风格也好看
plt.style.use('ggplot') # 画图风格使用ggplot风格,美化图用的 ggplot是R语言中的一个包
plt.rcParams['font.sans-serif'] =['Microsoft YaHei'] # 解决画图不显示文字的问题
plt.rcParams['axes.unicode_minus'] = False # 解决画图不显示负号的问题
df1 = pd.read_csv('销售表.csv',encoding='gbk') # 按照gbk解码格式读取,utf-8会出错
df2 = pd.read_csv('广告费.csv',encoding='gbk')
df1.info()
# df1结果如下: non-null没有缺失值
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 11815 entries, 0 to 11814
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 日期 11815 non-null object # 字符串类型
1 商品名称 11815 non-null object # 字符串类型
2 成交件数 11815 non-null int64 # 整数类型
3 销售额 11815 non-null float64 # 浮点数类型
dtypes: float64(1), int64(1), object(2)
memory usage: 369.3+ KB # 数据大小369.3Kb
df2.info()
# df2结果如下:non-null没有缺失值
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 11815 entries, 0 to 11814
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 投放日期 11815 non-null object # 字符串类型
1 广告费 11815 non-null int64 # 整数类型
dtypes: int64(1), object(1)
memory usage: 184.7+ KB # 数据大小
# 将两张表的日期列由字符串类型转为日期类型
df1['日期'] = pd.to_datetime(df1['日期'])
df2['投放日期'] = pd.to_datetime(df2['投放日期'])
# 对销售表:求每天的总成交件数与总销售额
df3 = df1.groupby(by='日期')[['成交件数','销售额']].sum()
# 对广告费表:求每天的投放广告费用支出
df4 = pd.DataFrame(df2.groupby(by='投放日期')['广告费'].sum())
# df3,df4 结果如下:自动将分组字段作为了索引且是日期类型,方便后面计算。
# 将df3和df4横向连接,连接键为索引 所以用left_index和right_index方便
df = df3.merge(df4,left_index=True,right_index=True)
df
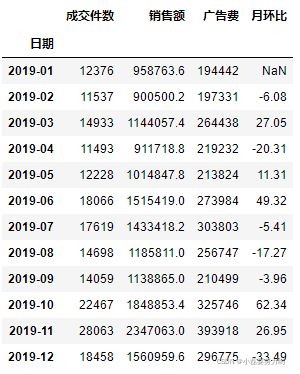
1、按月,按天分析销售额的变化形式 及月环比
"""按月汇总 :这里的resample()重新采样和频率转换函数,参数'M'是month的首字母,
因此表示将原日期以天数为单位转换为以月为最小单位的日期(但输出格式为xxxx-xx-31日为每月的最后一天);
.sum()就相当于按照月分组后对列进行求和;
to_period('M') 是将xxxx-xx-31中的日彻底去掉,变成xxxx-xx
"""
month_sum = df.resample('M').sum().to_period('M')
# 求月环比:pct_change()是特别重要环比函数:相对于该行照比上一行的值增加或减少了多少(0,1)间,这里*100转为以百分号为单位
month_sum['月环比'] = round(month_sum['销售额'].pct_change()*100,2)
month_sum
# 第一行月环比为NaN 因为它是第一行,前面没有可比的数字 你也可以通过fillna(0) 填充为0
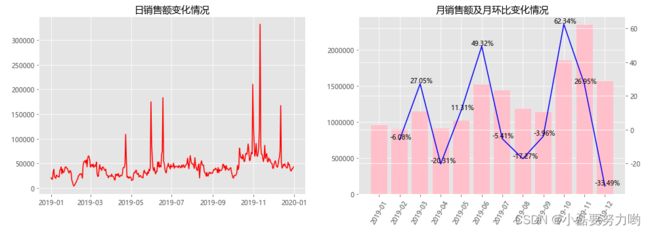
# 创建长宽(16,5)的画布
fig = plt.figure(figsize=(16,5))
# 将画布分为两部分 1行2列 这里是第一个子图
ax1 = fig.add_subplot(121)
ax1.plot(df.index,df['销售额'],c='r') # 折线图plot(x轴数值,y轴数值,c线条颜色)
plt.title('日销售额变化情况') # 子图1标题
# 第二个子图
ax2 = fig.add_subplot(122)
ax2.bar(range(12),month_sum['销售额'],color='pink') # 柱状图bar(x轴,y轴,color颜色) color不可缩写为c x轴只能传入数字
plt.title('月销售额及月环比变化情况') # 子图2标题
plt.xticks(range(12),month_sum.index,rotation=60) # 设置x轴刻度格式,将数字变为日期 rotationx轴文字旋转角度
ax3 = ax2.twinx() # 还是第二个子图,只是两张图画共用x轴
ax3.plot(range(12),month_sum['月环比'],c='b')
for i,j in enumerate(month_sum['月环比']): # enumerate()函数输出的是索引及其值 如enumerate([1,2,3]) 1的索引为0 所以会输出i=0,j=1
plt.text(i-0.5,j+0.5,str(j)+'%') # text(x,y,text),在(x,y)上显示text
plt.show() # 显示图画
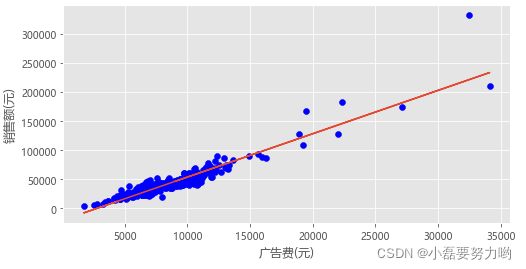
2、销售额与广告费的散点图关系
from sklearn.linear_model import LinearRegression # sklearn机器学习库 导入线性回归模型
from sklearn.metrics import r2_score # sklearn.metrics是检查模型的各种分数,r2_score是拟合优度
lr = LinearRegression() # 创建线性回归实例
lr.fit(np.array(df['广告费']).reshape(-1,1),df['销售额']) # fit(x,y)拟合 x必须是二维的,reshape(-1,1)转化
y_pre = lr.coef_ * np.array(df['广告费']) + lr.intercept_ # 对原数据进行预测
print('线性回归系数:{%.4f}' % lr.coef_)
print('截距:{%.4f}' % lr.intercept_)
print(r2_score(df['销售额'],y_pre)) # r2_score(原y值,预测的y值) R^2
plt.figure(figsize=(8,4))
plt.scatter(df['广告费'],df['销售额'],c='b') # 广告费和销售额散点图
plt.plot(df['广告费'],y) # 折线图 预测后的销售额 与 广告费 的直线关系
plt.xlabel('广告费(元)') # x轴标签
plt.ylabel('销售额(元)') # y轴标签
plt.show()
处理数据时遇到了新函数resample()之前没有总结的,因此下篇文章我会单独讲解该函数及其他重要日期函数(索引为日期函数时处理方便)
pandas日期处理函数之date_range()、resample()与to_period()