Machine learning(ML)常用的几类学习器及Python实现
Machine learning(ML)常用的几种学习器及Python实现
- 一、决策树
-
- 1.函数的参数主要为:
- 2. 决策树的保存
- 二、Boostings
-
- 1、Adaboost
-
- 1.构建训练函数
- 2、引用第三方库(Sklearn)
- 3、参数
- 2、DT(Regression Decision Tree,回归决策树)
- 2、BDT(Boosting Decision Tree,提升决策树)
- 3、GBDT(Gradient Boosting Decision Tree,梯度提升决策树)
-
- 参数(Sklearn):
- 4、XGboost
-
- 代码:
- 参数(Sklearn):
- 5、LightGBM
-
- 1、微软的lightGBM宏包
- 2、Sklearn接口形式的lightGBM
- 3、参数调优
-
- 1、为了更好的拟合
- 2、为了更快的速度
- 3、为了更高的精准率
- 6、Catboost
-
- 1、代码
-
- 1. 二分类
- 2. 多分类
- 2、参数(Classifier和Regress是差不多的)
- 7、基于GBDT的三种分类器对比
-
- 1、CatBoost
- 2、LightGBM
- 3、XGBoost
- 4、区分表格
- 8、所有树(DecisionTree)类的参数大全
- 三、Bagging(装袋集成算法)
-
- 1、随机森林
- 四、回归器(Regressor)
-
- 1、KNN——k近邻分类(k-nearest neighbor classification)
- 2、普通线性回归(linear)
- 3、岭回归(ridge)
- 4、lasso回归
- 5、决策树
- 6、支持向量机SVR
- 7、Logiscic回归
- 五、分类器(Classifier)
-
- 1、KNN——k近邻分类(k-nearest neighbor classification)
- 2、Logiscic回归
- 3、决策树
- 4、高斯分布朴素贝叶斯
- 5、多项式分布朴素贝叶斯
- 6、伯努利分布朴素贝叶斯
- 7、支持向量机SVC
- 六、聚类器(cluster)
-
- 1、K均值(K-means)
- 七、分类器对比(Classifier comparison)
- 八、sklearn中的集成算法模块ensemble
- 九、学习器组合模型
-
- 1、GBDT+LR
-
- Why not RF + LR ? Xgb + LR?
- 基于Sklearn代码
- 十、数据分析的工具
-
- 1、TableOne(表1)
-
- 分析示例
- 2、树的可视化(graphviz)
-
- 1. 安装
- 2.可视化方案
- 参考文章
由于是主要讲算法Python的实现,所有这里只是对这些算法的使用以及参数进行了解释,具体的算法原理可见后续Blog发布的其他文章。

一、决策树
决策树算法的最大优点是可以自学习。在学习的过程中,不需要使用者了解过多知识背景,只需要对训练实例进行较好的标注,就能够进行学习了。
在决策树的算法中,建立决策树的关键,即在当前状态下选择哪个属性作为分类依据。根据不同的目标函数,建立决策树主要有一下三种算法:
- ID3
- C4.5
- CART
主要的区别就是选择的目标函数不同,ID3使用的是信息增益,C4.5使用信息增益率,CART使用的是Gini系数。
DecisionTreeClassifier(criterion='entropy', min_samples_leaf=3)
1.函数的参数主要为:
- criterion:gini或者entropy,前者是基尼系数(对应CART),后者是信息熵(对应ID3,C4.5)。
- splitter:best or random 前者是在所有特征中找最好的切分点 后者是在部分特征中,默认的”best”适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐”random” 。
- max_features:None(所有),log2,sqrt,N 特征小于50的时候一般使用所有的。
- max_depth: int or None, optional (default=None) 设置决策随机森林中的决策树的最大深度,深度越大,越容易过拟合,推荐树的深度为:5-20之间。
- min_samples_split:设置结点的最小样本数量,当样本数量可能小于此值时,结点将不会在划分。
- min_samples_leaf: 这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。
- min_weight_fraction_leaf: 这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝默认是0,就是不考虑权重问题。
- max_leaf_nodes: 通过限制最大叶子节点数,可以防止过拟合,默认是"None”,即不限制最大的叶子节点。
- class_weight: 指定样本各类别的的权重,主要是为了防止训练集某些类别的样本过多导致训练的决策树过于偏向这些类别。这里可以自己指定各个样本的权重,如果使用“balanced”,则算法会自己计算权重,样本量少的类别所对应的样本权重会高。
- min_impurity_split: 这个值限制了决策树的增长,如果某节点的不纯度(基尼系数,信息增益,均方差,绝对差)小于这个阈值则该节点不再生成子节点。即为叶子节点 。
2. 决策树的保存
生成.dot文件,可以通过graphviz工具(见第九节树的可视化)查看树的结构
from sklearn import tree #需要导入的包
f = open('../dataSet/iris_tree.dot', 'w')
tree.export_graphviz(model.get_params('DTC')['DTC'], out_file=f)
二、Boostings
boosting是一种集成学习算法,由一系列基本分类器按照不同的权重组合成为一个强分类器,这些基本分类器之间有依赖关系。
1、Adaboost
通过在训练集上带权的采样来训练不同的弱分类器,根据弱学习的结果反馈适应地调整假设的错误率,所以它并不需要预测先知道假设地错误率下限,从而不需要任何关于弱分类器性能的先验知识,因而它比Boosting更容易应用到实际问题上。
- 提高被弱分类器错分样本的权值,降低正分样本的权值,作为下一轮基本分类器的训练样本。
- 加权多数表决,误差率小的分类器的权值大,使其在表决过程中起较大作用。
- AdaBoost是个二分类算法。
算法:

代码:
1.构建训练函数
Step1:先创建一个树
# Fit a simple decision tree(weak classifier) first
clf_tree = DecisionTreeClassifier(max_depth = 1, random_state = 1)
Step2:训练算法实现
def my_adaboost_clf(Y_train, X_train, Y_test, X_test, M=20, weak_clf=DecisionTreeClassifier(max_depth = 1)):
n_train, n_test = len(X_train), len(X_test)
# Initialize weights
w = np.ones(n_train) / n_train
pred_train, pred_test = [np.zeros(n_train), np.zeros(n_test)]
for i in range(M):
# Fit a classifier with the specific weights
weak_clf.fit(X_train, Y_train, sample_weight = w)
pred_train_i = weak_clf.predict(X_train)
pred_test_i = weak_clf.predict(X_test)
# Indicator function
miss = [int(x) for x in (pred_train_i != Y_train)]
print("weak_clf_%02d train acc: %.4f"
% (i + 1, 1 - sum(miss) / n_train))
# Error
err_m = np.dot(w, miss)
# Alpha
alpha_m = 0.5 * np.log((1 - err_m) / float(err_m))
# New weights
miss2 = [x if x==1 else -1 for x in miss] # -1 * y_i * G(x_i): 1 / -1
w = np.multiply(w, np.exp([float(x) * alpha_m for x in miss2]))
w = w / sum(w)
# Add to prediction
pred_train_i = [1 if x == 1 else -1 for x in pred_train_i]
pred_test_i = [1 if x == 1 else -1 for x in pred_test_i]
pred_train = pred_train + np.multiply(alpha_m, pred_train_i)
pred_test = pred_test + np.multiply(alpha_m, pred_test_i)
pred_train = (pred_train > 0) * 1
pred_test = (pred_test > 0) * 1
print("My AdaBoost clf train accuracy: %.4f" % (sum(pred_train == Y_train) / n_train))
print("My AdaBoost clf test accuracy: %.4f" % (sum(pred_test == Y_test) / n_test
2、引用第三方库(Sklearn)
from sklearn.datasets import make_gaussian_quantiles
from sklearn.ensemble import AdaBoostClassifier
# 生成2维正态分布,生成的数据按分位数分为两类,500个样本,2个样本特征,协方差系数为2
X1, y1 = make_gaussian_quantiles(cov=2.0,n_samples=500, n_features=2,n_classes=2, random_state=1)
# 生成2维正态分布,生成的数据按分位数分为两类,400个样本,2个样本特征均值都为3,协方差系数为2
X2, y2 = make_gaussian_quantiles(mean=(3, 3), cov=1.5,n_samples=400, n_features=2, n_classes=2, random_state=1)
#讲两组数据合成一组数据
X = np.concatenate((X1, X2))
y = np.concatenate((y1, - y2 + 1))
bdt = AdaBoostClassifier(DecisionTreeClassifier(max_depth=2, min_samples_split=20, min_samples_leaf=5),
algorithm="SAMME",
n_estimators=200, learning_rate=0.8)
bdt.fit(X, y)
Z = bdt.predict(np.c_[xx.ravel(), yy.ravel()]
3、参数
Adaboost-参数:
- base_estimator:基分类器,默认是决策树,在该分类器基础上进行boosting,理论上可以是任意一个分类器,但是如果是其他分类器时需要指明样本权重。
- n_estimators:基分类器提升(循环)次数,默认是50次,这个值过大,模型容易过拟合;值过小,模型容易欠拟合。
- learning_rate:学习率,表示梯度收敛速度,默认为1,如果过大,容易错过最优值,如果过小,则收敛速度会很慢;该值需要和n_estimators进行一个权衡,当分类器迭代次数较少时,学习率可以小一些,当迭代次数较多时,学习率可以适当放大。
- algorithm:boosting算法,也就是模型提升准则,有两种方式SAMME, 和SAMME.R两种,默认是SAMME.R,两者的区别主要是弱学习器权重的度量,前者是对样本集预测错误的概率进行划分的,后者是对样本集的预测错误的比例,即错分率进行划分的,默认是用的SAMME.R。
- random_state:随机种子设置。
关于Adaboost模型本身的参数并不多,但是我们在实际中除了调整Adaboost模型参数外,还可以调整基分类器的参数,关于基分类的调参,和单模型的调参是完全一样的,比如默认的基分类器是决策树,那么这个分类器的调参和我们之前的Sklearn参数详解——决策树是完全一致。
Adaboost-对象
- estimators_:以列表的形式返回所有的分类器。
- classes_:类别标签
- estimator_weights_:每个分类器权重
- estimator_errors_:每个分类器的错分率,与分类器权重相对应。
- feature_importances_:特征重要性,这个参数使用前提是基分类器也支持这个属性。
Adaboost-方法
- decision_function(X):返回决策函数值(比如svm中的决策距离)
- fit(X,Y):在数据集(X,Y)上训练模型。
- get_parms():获取模型参数
- predict(X):预测数据集X的结果。
- predict_log_proba(X):预测数据集X的对数概率。
- predict_proba(X):预测数据集X的概率值。
- score(X,Y):输出数据集(X,Y)在模型上的准确率。
- staged_decision_function(X):返回每个基分类器的决策函数值
- staged_predict(X):返回每个基分类器的预测数据集X的结果。
- staged_predict_proba(X):返回每个基分类器的预测数据集X的概率结果。
- staged_score(X, Y):返回每个基分类器的预测准确率。
2、DT(Regression Decision Tree,回归决策树)
#1.导入
from sklearn.tree import DecisionTreeRegressor
#2.创建模型
# max_depth 整数类型,决定对多少个数据特征做分裂
tree = DecisionTreeRegressor(max_depth=5)
#3.训练
tree.fit(X_train,y_train)
#4.预测
y_pre= tree.predict(x_test)
2、BDT(Boosting Decision Tree,提升决策树)
利用损失函数的负梯度产生回归问题提升树算法中残差的近似值,并拟合一棵树。
3、GBDT(Gradient Boosting Decision Tree,梯度提升决策树)
分类:
from sklearn import ensemble
clf = ensemble.GradientBoostingClassifier()
gbdt_model = clf.fit(X_train, y_train) # Training model
predicty_x = gbdt_model.predict_proba(test1217_x)[:, 1] # predict: probablity of 1
回归:
from sklearn import ensemble
clf = ensemble.GradientBoostingRegressor(n_estimators=100,
max_depth=3,
loss='ls')
gbdt_model = clf.fit(X_train, y_train) # Training model
y_upper = gbdt_model.predict(X_test) # predict
参数(Sklearn):
boosting框架参数:
- n_estimators:学习器的最大迭代次数,回归树的数量
- max_depth:每棵独立树的深度
- loss:GBDT的损失函数,分类模型和回归模型的损失函数不一样的,(ls为最小二乘函数,用于回归)
- learning_rate:学习速率,较低的学习速率需要更高数量的n_estimators,以达到相同程度的训练集误差–用时间换准确度的。
- subsample:(0,1],子采样。随机森林是有放回的采样,这里是不放回的采样
CART回归树学习器的参数:
- max_features:划分时考虑的最大特征数
- max_depth:决策树的最大深度
- min_samples_split:限制子树继续划分的条件,如果某结点的样本数少于它,就不会再继续划分
- min_samples_leaf:限制叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟结点一起被减掉
- max_laef_nodes:最大叶子结点数,防止过拟合
调参小技巧:
- 根据要解决的问题选择损失函数
- n_estimators尽可能大(如3000)
- 通过grid search(sklearn.grid_search)方法对max_depth, learning_rate, min_samples_leaf, 及max_features进行寻优
- 增加n_estimators,保持其它参数不变,再次对learning_rate调优
4、XGboost
XGBoost(eXtreme Gradient Boosting) 是GBDT的变种,一个可扩展的端到端树增强系统xgboost。稀疏数据稀疏感知算法和近似树学习加权分位数草图。更重要的是,我们提供有关缓存访问模式、数据压缩和切分的见解,以构建可扩展的树提升系统。
特点是特征排序分裂并行、支持线性分类器、低方差、低偏差、二阶泰勒展开损失函数、列抽样、增量训练、正则化减弱单树影响、降低了方差计算速度快,模型表现好,可以用于分类和回归问题中,号称“比赛夺冠的必备杀器”。
Xgboost采用贪心法,每次尝试分裂一个叶节点,计算分裂前后的增益,选择增益最大的。
代码:
from xgboost.sklearn import XGBClassifier
model = XGBClassifier() # 载入模型(模型命名为model)
model.fit(x_train,y_train) # 训练模型(训练集)
y_pred = model.predict(x_test) # 模型预测(测试集),y_pred为预测结果
参数(Sklearn):
性能参数:
booster:所使用的模型,gbtree或gblinearsilent:1则不打印提示信息,0则打印,默认为0nthread:所使用的线程数量,默认为最大可用数量
树参数:
learning_rate:学习率,默认初始化为0.3,经多轮迭代后一般衰减到0.01至0.2min_child_weight:每个子节点所需的最小权重和,默认为1max_depth:树的最大深度,默认为6,一般为3至10max_leaf_nodes:叶结点最大数量,默认为2^6gamma:拆分节点时所需的最小损失衰减,默认为0max_delta_step:默认为0subsample:每棵树采样的样本数量比例,默认为1,一般取0.5至1colsample_bytree:每棵树采样的特征数量比例,默认为1,一般取0.5至1colsample_bylevel:默认为1reg_lambda:L2正则化项,默认为1reg_alpha:L1正则化项,默认为1scale_pos_weight:加快收敛速度,默认为1
任务参数:
objective:目标函数,默认为reg:linear,还可取binary:logistic、multi:softmax、multi:softprobeval_metric:误差函数,回归默认为rmse,分类默认为error,其他可取值包括rmse、mae、logloss、merror、mlogloss、aucseed:随机数种子,默认为0
5、LightGBM
GBDT是受欢迎的机器学习算法,当特征维度很高或数据量很大时,有效性和可拓展性没法满足。LGB主要是对计算速度和数据的稀疏进行了一些改进,针对计算速度问题提出了GOSS(Gradient Boosting Decision Tree);针对数据稀疏问题提出了EFB(Exclusive Feature Bundling)。lightgbm与传统的gbdt在达到相同的精确度时,快20倍。
- Gradient-based One-Side Sampling (Goss):在GBDT中,数据集没有权重,注意到让不同梯度的数据集在计算信息增益时产生不同的作用。根据信息增益的定义,对于有更大梯度(即训练不足的数据集)将产生更多信息增益。于是,当降低数据集的数据量时,通过保持大梯度的数据集,随机丢掉小梯度的数据集,保持信息增益的准确性。GOSS保持所有具有大梯度的数据集,在小梯度数据集上随机采样。为了抵消对数据分布的影响,GOSS小梯度的样本数据在计算信息增益时引入系数(1-a)/b。具体来说:
1. GOSS首先按照数据集的梯度绝对值进行排序,选取最大的a100%数据集保留;
2. 然后从剩余数据集中随机选取b100%;
3. 最后,GOSS对于小梯度乘以常数(1-a)/b放大了样本数据。这样做,我们能不改变原始数据的分布,集中注意力在训练不足的数据上。 - Exclusive Feature Bundling(EFB). 高维数据通常非常稀疏。特征空间的稀疏性为我们提供了一个设计一种几乎无损的方法来减少特征数量的可能性。具体地说,在一个稀疏的特征空间,许多特征是互斥的,即:它们从不同时取非零值。我们可以安全地将互斥特征捆绑到一个单一的特征中(称之为互斥特征束)。通过精心设计的特征扫描算法,我们可以构建与个体特征类似的基于特征束的特征直方图。这样,直方图构建的复杂性从 O ( d a t a ∗ f e a t u r e ) O(data*feature) O(data∗feature)到 O ( d a t a ∗ b u n d l e ) O(data*bundle) O(data∗bundle),其中 O ( b u n d l e < < f e a t u r e ) O(bundle<
LightGBM(Light Gradient Boosting Machine)的训练速度和效率更快、使用的内存更低、准确率更高、并且支持并行化学习与处理大规模数据。
1、微软的lightGBM宏包
import lightgbm as lgb
from sklearn.metrics import mean_squared_error
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据
iris = load_iris()
data = iris.data
target = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
print("Train data length:", len(X_train))
print("Test data length:", len(X_test))
# 转换为Dataset数据格式
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
# 参数
params = {
'task': 'train',
'boosting_type': 'gbdt', # 设置提升类型
'objective': 'regression', # 目标函数
'metric': {'l2', 'auc'}, # 评估函数
'num_leaves': 31, # 叶子节点数
'learning_rate': 0.05, # 学习速率
'feature_fraction': 0.9, # 建树的特征选择比例
'bagging_fraction': 0.8, # 建树的样本采样比例
'bagging_freq': 5, # k 意味着每 k 次迭代执行bagging
'verbose': 1 # <0 显示致命的, =0 显示错误 (警告), >0 显示信息
}
# 模型训练
gbm = lgb.train(params, lgb_train, num_boost_round=20, valid_sets=lgb_eval, early_stopping_rounds=5)
# 模型保存
gbm.save_model('model.txt')
# 模型加载
gbm = lgb.Booster(model_file='model.txt')
# 模型预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration)
# 模型评估
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)
2、Sklearn接口形式的lightGBM
from lightgbm import LGBMRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.externals import joblib
# 加载数据
iris = load_iris()
data = iris.data
target = iris.target
# 划分训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
# 模型训练
gbm = LGBMRegressor(objective='regression', num_leaves=31, learning_rate=0.05, n_estimators=20)
gbm.fit(X_train, y_train, eval_set=[(X_test, y_test)], eval_metric='l1', early_stopping_rounds=5)
# 模型存储
joblib.dump(gbm, 'loan_model.pkl')
# 模型加载
gbm = joblib.load('loan_model.pkl')
# 模型预测
y_pred = gbm.predict(X_test, num_iteration=gbm.best_iteration_)
# 模型评估
print('The rmse of prediction is:', mean_squared_error(y_test, y_pred) ** 0.5)
# 特征重要度
print('Feature importances:', list(gbm.feature_importances_))
# 网格搜索,参数优化
estimator = LGBMRegressor(num_leaves=31)
param_grid = {
'learning_rate': [0.01, 0.1, 1],
'n_estimators': [20, 40]
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(X_train, y_train)
print('Best parameters found by grid search are:', gbm.best_params_)
3、参数调优
1、为了更好的拟合
- num_leaves:这个参数是用来设置组成每棵树的叶子的数量。num_leaves 和 max_depth理论上的联系是: num_leaves = 2(max_depth)。然而,但是如果使用LightGBM的情况下,这种估计就不正确了:因为它使用了leaf_wise而不是depth_wise分裂叶子节点。因此,num_leaves必须设置为一个小于2(max_depth)的值。否则,他将可能会导致过拟合。LightGBM的num_leave和max_depth这两个参数之间没有直接的联系。因此,我们一定不要把两者联系在一起。
- min_data_in_leaf : 它也是一个用来解决过拟合的非常重要的参数。把它的值设置的特别小可能会导致过拟合,因此,我们需要对其进行相应的设置。因此,对于大数据集来说,我们应该把它的值设置为几百到几千。
- max_depth: 它指定了每棵树的最大深度或者它能够生长的层数上限。
2、为了更快的速度
-
bagging_fraction : 它被用来执行更快的结果装袋;
-
feature_fraction : 设置每一次迭代所使用的特征子集;
-
max_bin : max_bin的值越小越能够节省更多的时间:当它将特征值分桶装进不同的桶中的时候,这在计算上是很便宜的。
3、为了更高的精准率
-
使用更大的训练数据集;
-
num_leaves : 把它设置得过大会使得树的深度更高、准确率也随之提升,但是这会导致过拟合。因此它的值被设置地过高不好。
-
max_bin : 该值设置地越高导致的效果和num_leaves的增长效果是相似的,并且会导致我们的训练过程变得缓慢。
6、Catboost
Catboost( Categorical Features+Gradient Boosting)采用的策略在降低过拟合的同时保证所有数据集都可用于学习。性能卓越、鲁棒性与通用性更好、易于使用而且更实用。据其介绍 Catboost 的性能可以匹敌任何先进的机器学习算法。优点:
- 无需调参即可获得较高的模型质量,采用默认参数就可以获得非常好的结果,减少在调参上面花的时间
- 支持类别型变量,无需对非数值型特征进行预处理
- 快速、可扩展的GPU版本,可以用基于GPU的梯度提升算法实现来训练你的模型,支持多卡并行
- 提高准确性,提出一种全新的梯度提升机制来构建模型以减少过拟合
- 快速预测,即便应对延时非常苛刻的任务也能够快速高效部署模型
CatBoost的主要算法原理可以参照以下两篇论文:
- Anna Veronika Dorogush, Andrey Gulin, Gleb Gusev, Nikita Kazeev, Liudmila Ostroumova Prokhorenkova, Aleksandr Vorobev “Fighting biases with dynamic boosting”. arXiv:1706.09516, 2017
- Anna Veronika Dorogush, Vasily Ershov, Andrey Gulin “CatBoost: gradient boosting with categorical features support”. Workshop on ML Systems at NIPS 2017
1、代码
1. 二分类
from catboost import CatBoostClassifier
# Initialize data
cat_features = [0,1,2]
train_data = [["a","b",1,4,5,6],["a","b",4,5,6,7],["c","d",30,40,50,60]]
train_labels = [1,1,-1]
test_data = [["a","b",2,4,6,8],["a","d",1,4,50,60]]
# Initialize CatBoostClassifier
model = CatBoostClassifier(
iterations=2,
learning_rate=1,
depth=2, loss_function='Logloss')
# Fit model
model.fit(train_data, train_labels, cat_features)
# Get predicted classes
preds_class = model.predict(test_data)
# Get predicted probabilities for each class
preds_proba = model.predict_proba(test_data)
# Get predicted RawFormulaVal
preds_raw = model.predict(test_data, prediction_type='RawFormulaVal')
2. 多分类
from catboost import Pool, CatBoostClassifier
TRAIN_FILE = '../data/cloudness_small/train_small'
TEST_FILE = '../data/cloudness_small/test_small'
CD_FILE = '../data/cloudness_small/train.cd'
# Load data from files to Pool
train_pool = Pool(TRAIN_FILE, column_description=CD_FILE)
test_pool = Pool(TEST_FILE, column_description=CD_FILE)
# Initialize CatBoostClassifier
model = CatBoostClassifier(
iterations=2,
learning_rate=1,
depth=2,
loss_function='MultiClass')
# Fit model
model.fit(train_pool)
# Get predicted classes
preds_class = model.predict(test_pool)
# Get predicted probabilities for each class
preds_proba = model.predict_proba(test_pool)
# Get predicted RawFormulaVal
preds_raw = model.predict(test_pool, prediction_type='RawFormulaVal')
2、参数(Classifier和Regress是差不多的)
-
iterations: 迭代次数, 解决机器学习问题能够构建的最大树的数目,default=1000
-
learning_rate: 学习率,default=0.03
-
depth: 树的深度,default=6
-
l2_leaf_reg: L 2 L_2 L2正则化数,default=3.0
-
model_size_reg:模型大小正则化系数,数值越到,模型越小,仅在有类别型变量的时候起作用,取值范围从0到 + ∞ +\infty +∞,GPU计算时不可用, default=None
-
rsm: =None,
-
loss_function: 损失函数,字符串 (分类任务,default=Logloss,回归任务,default=RMSE)
-
border_count: 数值型变量的分箱个数
- CPU:1~65535的整数,default=254
- GPU:1~255的整数,default=128
-
feature_border_type: 数值型变量分箱个数的初始量化模式, default=GreedyLogSum
- Median
- Uniform
- UniformAndQuantiles
- MaxLogSum
- MinEntropy
- GreedyLogSum
-
per_float_feature_quantization: 指定特定特征的分箱个数,default=None,
-
input_borders=None,
-
output_borders=None,
-
fold_permutation_block: 对数据集进行随机排列之前分组的block大小,default=1
-
od_pval: 过拟合检测阈值,数值越大,越早检测到过拟合,default=0
-
od_wait: 达成优化目标以后继续迭代的次数,default=20
-
od_type: 过拟合检测类型,default=IncToDec
- IncToDec
- Iter
-
nan_mode: 缺失值的预处理方法,字符串类型,default=Min
- Forbidden: 不支持缺失值
- Min: 缺失值赋值为最小值
- Max: 缺失值赋值为最大值
-
counter_calc_method: 计算Counter CTR类型的方法,default=None
-
leaf_estimation_iterations: 计算叶子节点值时候的迭代次数,default=None,
-
leaf_estimation_method: 计算叶子节点值的方法,default=Gradient
- Newton
- Gradient
-
thread_count: 训练期间的进程数,default=-1,进程数与部件的核心数相同
-
random_seed: 随机数种子,default=0
-
use_best_model: 如果有设置eval_set设置了验证集的话可以设为True,否则为False
-
verbose: 是否显示详细信息,default=1
-
logging_level: 打印的日志级别,default=None
-
metric_period: 计算优化评估值的频率,default=1
-
ctr_leaf_count_limit: 类别型特征最大叶子数,default=None
-
store_all_simple_ctr: 是否忽略类别型特征,default=False
-
max_ctr_complexity: 最大特征组合数,default=4
-
has_time: 是否采用输入数据的顺序,default=False
-
allow_const_label: 使用它为所有对象用具有相同标签值的数据集训练模型,default=None
-
classes_count: 多分类当中类别数目上限,defalut=None
-
class_weights: 类别权重,default=None
-
one_hot_max_size: one-hot编码最大规模,默认值根据数据和训练环境的不同而不同
-
random_strength: 树结构确定以后为分裂点进行打分的时候的随机强度,default=1
-
name: 在可视化工具当中需要显示的实验名字
-
ignored_features: 在训练当中需要排除的特征名称或者索引,default=None
-
train_dir: 训练过程当中文件保存的目录
-
custom_loss: 用户自定义的损失函数
-
custom_metric: 自定义训练过程当中输出的评估指标,default=None
-
eval_metric: 过拟合检测或者最优模型选择的评估指标
- loss-functions
-
bagging_temperature: 贝叶斯bootstrap强度设置,default=1
-
save_snapshot: 训练中断情况下保存快照文件
-
snapshot_file: 训练过程信息保存的文件名字
-
snapshot_interval: 快照保存间隔时间,单位秒
-
fold_len_multiplier: 改变fold长度的系数,default=2
-
used_ram_limit: 类别型特征使用内存限制,default=None
-
gpu_ram_part: GPU内存使用率,default=0.95
-
allow_writing_files: 训练过程当中允许写入分析和快照文件,default=True
-
final_ctr_computation_mode: Final CTR计算模式
-
Vapprox_on_full_history: 计算近似值的原则,default=False
-
boosting_type: 提升模式
- Ordered
- Plain
-
simple_ctr: 单一类别型特征的量化设置
- CtrType
- TargetBorderCount
- TargetBorderType
- CtrBorderCount
- CtrBorderType
- Prior
-
combinations_ctr: 组合类别型特征的量化设置
- CtrType
- TargetBorderCount
- TargetBorderType
- CtrBorderCount
- CtrBorderType
- Prior
-
per_feature_ctr: 以上几个参数的设置具体可以细看下面的文档
- Categorical features
-
task_type: 任务类型,CPU或者GPU,default=CPU
-
device_config: =None
-
devices: 用来训练的GPU设备号,default=NULL
-
bootstrap_type: 自采样类型,default=Bayesian
- Bayesian
- Bernoulli
- MVS
- Poisson
- No
-
subsample: bagging的采样率,default=0.66
-
ampling_unit: 采样模式,default=Object
- Object
- Group
-
dev_score_calc_obj_block_size: =None,
-
max_depth: 树的最大深度
-
n_estimators: 迭代次数
-
num_boost_round: 迭代轮数
-
num_trees: 树的数目
-
colsample_bylevel: 按层抽样比例,default=None
-
random_state: 随机数状态
-
reg_lambda: 损失函数 L 2 L_2 L2范数,default=3.0
-
objective: =同损失函数
-
eta: 学习率
-
max_bin: =同border_coucnt
-
scale_pos_weight: 二分类任务当中1类的权重,default=1.0
-
gpu_cat_features_storage: GPU训练时类别型特征的存储方式,default=GpuRam
- CpuPinnedMemory
- GpuRam
-
data_partition: 分布式训练时数据划分方法
- 特征并行
- 样本并行
-
metadata: =None
-
early_stopping_rounds: 早停轮次,default=False
-
cat_features: =指定类别型特征的名称或者索引
-
grow_policy: 树的生长策略
-
min_data_in_leaf: 叶子节点最小样本数,default=1
-
min_child_samples: 叶子节点最小样本数,default=1
-
max_leaves: 最大叶子数,default=31
-
num_leaves: 叶子数
-
score_function: 建树过程当中的打分函数
-
leaf_estimation_backtracking: 梯度下降时回溯类型
-
ctr_history_unit: =None
-
monotone_constraints: =None
7、基于GBDT的三种分类器对比
1、CatBoost
(1)CatBoost: 提供了比 XGBoost 更高的准确性和和更短的训练时间;
(2)支持即用的分类特征,因此我们不需要对分类特征进行预处理(例如,通过 LabelEncoding 或 OneHotEncoding)。事实上,CatBoost 的文档明确地说明不要在预处理期间使用热编码,因为“这会影响训练速度和最终的效果”;
(3)通过执行有序地增强操作,可以更好地处理过度拟合,尤其体现在小数据集上;
(4)支持即用的 GPU 训练(只需设置参数task_type =“GPU”);
(5)可以处理缺失的值;
2、LightGBM
(1)LightGBM 也能提供比 XGBoost 更高的准确性和更短的训练时间;
(2)支持并行的树增强操作,即使在大型数据集上(相比于 XGBoost)也能提供更快的训练速度;
(3)使用 histogram-esquealgorithm,将连续的特征转化为离散的特征,从而实现了极快的训练速度和较低的内存使用率;
(4)通过使用垂直拆分(leaf-wise split)而不是水平拆分(level-wise split)来获得极高的准确性,这会导致非常快速的聚合现象,并在非常复杂的树结构中能捕获训练数据的底层模式。可以通过使用 num_leaves 和 max_depth 这两个超参数来控制过度拟合;
3、XGBoost
(1)支持并行的树增强操作;
(2)使用规则化来遏制过度拟合;
(3)支持用户自定义的评估指标;
(4)处理缺失的值;
(5)XGBoost 比传统的梯度增强方法(如 AdaBoost)要快得多;
4、区分表格
8、所有树(DecisionTree)类的参数大全

除了这些参数要注意以外,其他在调参时的注意点有:
- 当样本少数量但是样本特征非常多的时候,决策树很容易过拟合,一般来说,样本数比特征数多一些会比较容易建立健壮的模型
- 如果样本数量少但是样本特征非常多,在拟合决策树模型前,推荐先做维度规约,比如主成分分析(PCA),特征选择(Losso)或者独立成分分析(ICA)。这样特征的维度会大大减小。再来拟合决策树模型效果会好。
- 推荐多用决策树的可视化(下节会讲),同时先限制决策树的深度(比如最多3层),这样可以先观察下生成的决策树里数据的初步拟合情况,然后再决定是否要增加深度。
- 在训练模型先,注意观察样本的类别情况(主要指分类树),如果类别分布非常不均匀,就要考虑用class_weight来限制模型过于偏向样本多的类别。
- 决策树的数组使用的是numpy的float32类型,如果训练数据不是这样的格式,算法会先做copy再运行。
- 如果输入的样本矩阵是稀疏的,推荐在拟合前调用csc_matrix稀疏化,在预测前调用csr_matrix稀疏化。
三、Bagging(装袋集成算法)
1、随机森林
随机森林是非常具有代表性的Bagging集成算法,它的所有基评估器都是决策树,分类树组成的森林就叫做随机森林分类器,回归树所集成的森林就叫做随机森林回归器。
重要参数:
class sklearn.ensemble.RandomForestClassifier (n_estimators=’10’, criterion=’gini’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’,
max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False,
n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None
| 控制基评估器的参数 | 含义 |
|---|---|
| criterion | 不纯度的衡量指标,有gini系数和信息熵两种选择 |
| max_depth | 树的最大深度,超过最大深度的树枝都会被剪掉 |
| min_samples_split | 一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则分枝就不会发生 |
| min_samples_leaf | 一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生 |
| max_features | max_features限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃,默认值为总特征个数开平方取整 |
| min_impurity_split | 限制信息增益的大小,信息增益小于设定数值的分枝不会发生 |
代码示意:
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
clf = DecisionTreeClassifier(random_state=0)
rfc = RandomForestClassifier(random_state=0)
clf = clf.fit(Xtrain,Ytrain)
rfc = rfc.fit(Xtrain,Ytrain)
score_c = clf.score(Xtest,Ytest)
score_r = rfc.score(Xtest,Ytest)
print("Single Tree:{}".format(score_c)
,"Random Forest:{}".format(score_r))
随机森林的本质是一种装袋集成算法(bagging),装袋集成算法是对基评估器的预测结果进行平均或用多数表决原则来决定集成评估器的结果。
随机森林中其实也有random_state,用法和分类树中相似,只不过在分类树中,一个random_state只控制生成一棵树,而随机森林中的random_state控制的是生成森林的模式,而非让一个森林中只有一棵树。
import numpy as np
from scipy.special import comb
np.array([comb(25,i)*(0.2**i)*((1-0.2)**(25-i)) for i in range(13,26)]).sum()
rfc = RandomForestClassifier(n_estimators=20,random_state=2)
rfc = rfc.fit(Xtrain, Ytrain)
#随机森林的重要属性之一:estimators,查看森林中树的状况
rfc.estimators_[0].random_state
for i in range(len(rfc.estimators_)):
print(rfc.estimators_[i].random_state)
四、回归器(Regressor)
1、KNN——k近邻分类(k-nearest neighbor classification)
#1.导入
from sklearn.neighbors import KNeighborsRegressor
#2.创建模型
knnrgr = KNeighborsRegressor(n_neighbors=3)
#3.训练
knnclf.fit(X_train,y_train)
#4.预测
y_pre = knnclf.predict(x_test)
2、普通线性回归(linear)
#1.导入
from sklearn.linear_model import LinearRegression
#2.创建模型
line = LinearRegression()
#3.训练
line.fit(X_train,y_train)
#4.预测
y_pre= line.predict(x_test)
3、岭回归(ridge)
#1.导入
from sklearn.linear_model import Ridge
#2.创建模型
# alpha就是缩减系数lambda
# 如果把alpha设置为0,就是普通线性回归
ridge = Ridge(alpha=0)
#3.训练
ridge.fit(X_train,y_train)
#4.预测
y_pre= ridge.predict(x_test)
4、lasso回归
#1.导入
from sklearn.linear_model import Lasso
#2.创建模型
las = Lasso(alpha=0.0001)
#3.训练
las.fit(X_train,y_train)
#4.预测
y_pre= las.predict(x_test)
5、决策树
#1.导入
from sklearn.tree import DecisionTreeRegressor
#2.创建模型
# max_depth 整数类型,决定对多少个数据特征做分裂
tree = DecisionTreeRegressor(max_depth=5)
#3.训练
tree.fit(X_train,y_train)
#4.预测
y_pre= tree.predict(x_test)
6、支持向量机SVR
#1.导入
from sklearn.svm import SVR
#2.创建模型(回归时使用SVR)
svr = SVR(kernel='linear')
svr = SVR(kernel='rbf')
svr = SVR(kernel='poly')
#3.训练
svr_linear.fit(X_train,y_train)
svr_rbf.fit(X_train,y_train)
svr_poly.fit(X_train,y_train)
#4.预测
linear_y_ = svr_linear.predict(x_test)
rbf_y_ = svr_rbf.predict(x_test)
poly_y_ = svr_poly.predict(x_test)
7、Logiscic回归
#1.导入
from sklearn.linear_model import LogisticRegression
#2.创建模型
logistic = LogisticRegression(solver='lbfgs')
#solver参数的选择:
“liblinear”:小数量级的数据集
“lbfgs”, “sag” or “newton-cg”:大数量级的数据集以及多分类问题
“sag”:极大的数据集
#3.训练
logistic.fit(X_train,y_train)
#4.预测
y_pre= logistic.predict(x_test)
五、分类器(Classifier)
1、KNN——k近邻分类(k-nearest neighbor classification)
from sklearn.neighbors import KNeighborsClassifier
knnclf = KNeighborsClassifier(n_neighbors=5)
knnclf.fit(X_train,y_train)
y_pre = knnclf.predict(x_test)
2、Logiscic回归
from sklearn.linear_model import LogisticRegression
3、决策树
#1.导入
from sklearn.tree import DecisionTreeClassifier
#2.创建模型
# max_depth 整数类型,决定对多少个数据特征做分裂
tree = DecisionTreeClassifier(max_depth=5)
#3.训练
tree.fit(X_train,y_train)
#4.预测
y_pre= tree.predict(x_test)
4、高斯分布朴素贝叶斯
#1.导入
from sklearn.naive_bayes import GaussianNB
#2.创建模型
gNB = GaussianNB()
#3.训练
gNB.fit(data,target)
#4.预测
y_pre = gNB.predict(x_test)
5、多项式分布朴素贝叶斯
#1.导入
from sklearn.naive_bayes import MultinomialNB
#2.创建模型
mNB = MultinomialNB()
#3.字符集转换为词频
from sklearn.feature_extraction.text import TfidfVectorizer
#先构建TfidfVectorizer对象
tf = TfidfVectorizer()
#使用要转换的数据集和标签集对tf对象进行训练
tf.fit(X_train,y_train)
#文本集 ----> 词频集
X_train_tf = tf.transform(X_train)
#4.使用词频集对机器学习模型进行训练
mNB.fit(X_train_tf,y_train)
#5.预测
#将字符集转化为词频集
x_test = tf.transform(test_str)
#预测
mNB.predict(x_test)
6、伯努利分布朴素贝叶斯
#1.导入
from sklearn.naive_bayes import BernoulliNB
#2.创建模型
bNB = BernoulliNB()
#3.将字符集转词频集
from sklearn.feature_extraction.text import TfidfVectorizer
tf = TfidfVectorizer()
tf.fit(X_train,y_train)
X_train_tf = tf.transform(X_train)
#4.训练
bNB.fit(X_train_tf,y_train)
#5.预测
#将字符集转化为词频集
x_test = tf.transform(test_str)
#预测
bNB.predict(x_test)
7、支持向量机SVC
#1.导入
from sklearn.svm import SVC(区分SVR)
#2.创建模型(回归时使用SVR)
svc = SVC(kernel='linear')
# svc = SVC(kernel='rbf')
# svc = SVC(kernel='poly')
#3.训练
svc_linear.fit(X_train,y_train)
# svc_rbf.fit(X_train,y_train)
# svc_poly.fit(X_train,y_train)
#4.预测
linear_y_ = svc_linear.predict(x_test)
# rbf_y_ = svc_rbf.predict(x_test)
# poly_y_ = svc_poly.predict(x_test)
六、聚类器(cluster)
1、K均值(K-means)
#1.导入
from sklearn.cluster import KMeans
#2.创建模型
# 构建机器学习对象kemans,指定要分类的个数
kmean = KMeans(n_clusters=2)
#3.训练数据
# 注意:聚类算法是没有y_train的
kmean.fit(X_train)
#4.预测数据
y_pre = kmean.predict(X_train)
七、分类器对比(Classifier comparison)
对常见的几类分类器进行比较。
代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
=====================
Classifier comparison
=====================
A comparison of a several classifiers in scikit-learn on synthetic datasets.
The point of this example is to illustrate the nature of decision boundaries
of different classifiers.
与其他的机器学习的分类的算法在合成数据方面相比较,本示例为了说明不同算法边界的性质。
This should be taken with a grain of salt, as the intuition conveyed by
these examples does not necessarily carry over to real datasets.
Particularly in high-dimensional spaces, data can more easily be separated
linearly and the simplicity of classifiers such as naive Bayes and linear SVMs
might lead to better generalization than is achieved by other classifiers.
The plots show training points in solid colors and testing points
semi-transparent. The lower right shows the classification accuracy on the test
set.
"""
print(__doc__)
# Code source: Gaël Varoquaux
# Andreas Müller
# Modified for documentation by Jaques Grobler
# License: BSD 3 clause
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import make_moons, make_circles, make_classification
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis
h = .02 # step size in the mesh
names = ["Nearest Neighbors", "Linear SVM", "RBF SVM", "Gaussian Process",
"Decision Tree", "Random Forest", "Neural Net", "AdaBoost",
"Naive Bayes", "QDA"]
classifiers = [
KNeighborsClassifier(3),
SVC(kernel="linear", C=0.025),
SVC(gamma=2, C=1),
GaussianProcessClassifier(1.0 * RBF(1.0), warm_start=True),
DecisionTreeClassifier(max_depth=5),
RandomForestClassifier(max_depth=5, n_estimators=10, max_features=1),
MLPClassifier(alpha=1),
AdaBoostClassifier(),
GaussianNB(),
QuadraticDiscriminantAnalysis()]
X, y = make_classification(n_features=2, n_redundant=0, n_informative=2,
random_state=1, n_clusters_per_class=1)
#print X
#print len(y)
rng = np.random.RandomState(2)
#print X.shape
X+= 2 * rng.uniform(size=X.shape)
#print X
linearly_separable = (X, y)
datasets = [make_moons(noise=0.3, random_state=0),
make_circles(noise=0.2, factor=0.5, random_state=1),
linearly_separable
]
figure = plt.figure(figsize=(27, 9))
i = 1
# iterate over datasets
for ds_cnt, ds in enumerate(datasets):
'''
上面的循环 ds_cnt是从0-datasets的长度变换
ds 代表datasets的每个值,在这里相当于每个数据生成方法的返回值
'''
# preprocess dataset, split into training and test part
'''
将 ds 的返回值赋值给X,y
'''
X, y = ds
'''
标准化,均值去除和按方差比例缩放数据集的标准化:
当个体特征太过或明显不遵从高斯正态分布时,标准化表现的效果较差。
实际操作中,经常忽略特征数据的分布形状,移除每个特征均值,划分离散特征的标准差,从而等级化,进而实现数据中心化。
通过删除平均值和缩放到单位方差来标准化特征
'''
X = StandardScaler().fit_transform(X)
'''
定义了四个变量
'''
'''
利用数据分割函数将数据分为训练数据集和测试数据集
以及训练数据集和测试数据集对应的整数标签
'''
X_train, X_test, y_train, y_test =train_test_split(X, y, test_size=.4, random_state=42)
'''
'''
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
#print X[:, 0]
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
# just plot the dataset first
cm = plt.cm.RdBu
'''
红色和蓝色
'''
cm_bright = ListedColormap(['#FF0000', '#0000FF'])
ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
if ds_cnt == 0:
ax.set_title("Input data")
# Plot the training points
'''
scatter函数绘制散列图:
'''
'''
深红色和深蓝色是划分出来的训练数据
'''
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright)
# and testing points
'''
浅红色和浅蓝色是划分出来的测试数据
这样就形成了四种颜色的数据
'''
ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
i += 1
# iterate over classifiers
for name, clf in zip(names, classifiers):
ax = plt.subplot(len(datasets), len(classifiers) + 1, i)
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
# Plot the decision boundary. For that, we will assign a color to each
# point in the mesh [x_min, x_max]x[y_min, y_max].
if hasattr(clf, "decision_function"):
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
else:
Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1]
# Put the result into a color plot
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=cm, alpha=.8)
# Plot also the training points
ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright)
# and testing points
ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright,
alpha=0.6)
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
if ds_cnt == 0:
ax.set_title(name)
ax.text(xx.max() - .3, yy.min() + .3, ('%.2f' % score).lstrip('0'),
size=15, horizontalalignment='right')
i += 1
plt.tight_layout()
plt.show()
Result:

虽说这图看起来好像这些分类器还真有个孰重孰优,但实际上应该考虑到Databases的缘由,分类器的参数选取也是不同的,所以效果不一定代表分类器本身的效果,换句西瓜书上的话来讲就是(机器学习的效果是人为设定的,所以如果不掺杂人的主观思想而言,分类器的效果都是一样好的)
八、sklearn中的集成算法模块ensemble
ensemble.AdaBoostClassifier : AdaBoost分类
ensemble.AdaBoostRegressor :Adaboost回归
ensemble.BaggingClassifier :装袋分类器
ensemble.BaggingRegressor :装袋回归器
ensemble.ExtraTreesClassifier :Extra-trees分类(超树,极端随机树)
ensemble.ExtraTreesRegressor : Extra-trees回归
ensemble.GradientBoostingClassifier : 梯度提升分类
ensemble.GradientBoostingRegressor :梯度提升回归
ensemble.IsolationForest :隔离森林
**ensemble.RandomForestClassifier :随机森林分类
ensemble.RandomForestRegressor : 随机森林回归**
ensemble.RandomTreesEmbedding :完全随机树的集成
ensemble.VotingClassifier :用于不合适估算器的软投票/多数规则分类
九、学习器组合模型
1、GBDT+LR
正如它的名字一样,GBDT+LR 由两部分组成,其中GBDT用来对训练集提取特征作为新的训练输入数据,LR作为新训练输入数据的分类器。
具体来讲,有以下几个步骤:
-
GBDT首先对原始训练数据做训练,得到一个二分类器,当然这里也需要利用网格搜索寻找最佳参数组合。
-
与通常做法不同的是,当GBDT训练好做预测的时候,输出的并不是最终的二分类概率值,而是要把模型中的每棵树计算得到的预测概率值所属的叶子结点位置记为1,这样,就构造出了新的训练数据。
举个例子,下图是一个GBDT+LR 模型结构,设GBDT有两个弱分类器,分别以蓝色和红色部分表示,其中蓝色弱分类器的叶子结点个数为3,红色弱分类器的叶子结点个数为2,并且蓝色弱分类器中对0-1 的预测结果落到了第二个叶子结点上,红色弱分类器中对0-1 的预测结果也落到了第二个叶子结点上。那么我们就记蓝色弱分类器的预测结果为[0 1 0],红色弱分类器的预测结果为[0 1],综合起来看,GBDT的输出为这些弱分类器的组合[0 1 0 0 1] ,或者一个稀疏向量(数组)。
这里的思想与One-hot独热编码类似,事实上,在用GBDT构造新的训练数据时,采用的也正是One-hot方法。并且由于每一弱分类器有且只有一个叶子节点输出预测结果,所以在一个具有n个弱分类器、共计m个叶子结点的GBDT中,每一条训练数据都会被转换为1*m维稀疏向量,且有n个元素为1,其余m-n 个元素全为0。
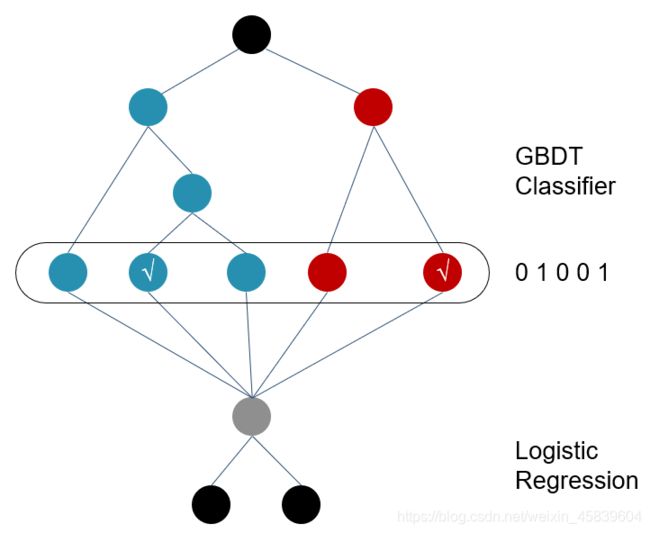
-
新的训练数据构造完成后,下一步就要与原始的训练数据中的label(输出)数据一并输入到Logistic Regression分类器中进行最终分类器的训练。思考一下,在对原始数据进行GBDT提取为新的数据这一操作之后,数据不仅变得稀疏,而且由于弱分类器个数,叶子结点个数的影响,可能会导致新的训练数据特征维度过大的问题,因此,在Logistic Regression这一层中,可使用正则化来减少过拟合的风险,在Facebook的论文中采用的是L1正则化。
Why not RF + LR ? Xgb + LR?
有心的同学应该会思考一个问题,既然GBDT可以做新训练样本的构造,那么其它基于树的模型,例如Random Forest以及Xgboost等是并不是也可以按类似的方式来构造新的训练样本呢?没错,所有这些基于树的模型都可以和Logistic Regression分类器组合。至于效果孰优孰劣,我个人觉得效果都还可以,但是之间没有可比性,因为超参数的不同会对模型评估产生较大的影响。下图是RF+LR、GBT+LR、Xgb、LR、Xgb+LR 模型效果对比图,然而这只能做个参考,因为模型超参数的值的选择这一前提条件都各不相同。
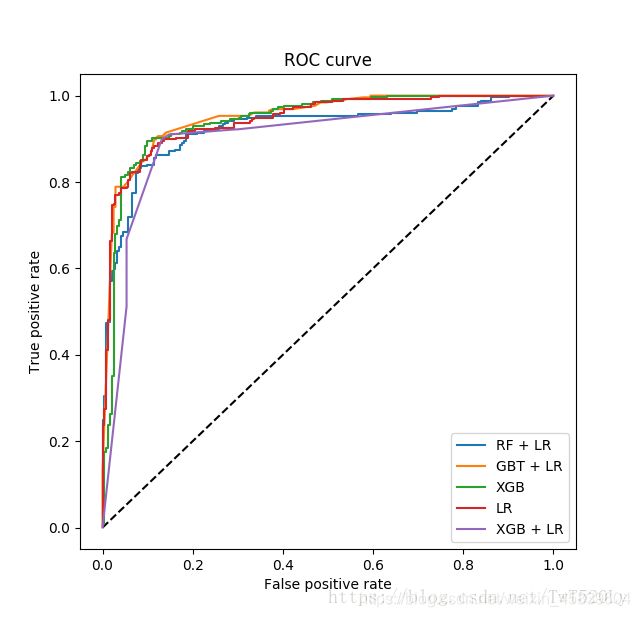

顺便来讲,RF也是多棵树,但从效果上有实践证明不如GBDT。且GBDT前面的树,特征分裂主要体现对多数样本有区分度的特征;后面的树,主要体现的是经过前N颗树,残差仍然较大的少数样本。优先选用在整体上有区分度的特征,再选用针对少数样本有区分度的特征,思路更加合理,这应该也是用GBDT的原因。
基于Sklearn代码
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import GradientBoostingClassifier
gbm1 = GradientBoostingClassifier(n_estimators=50, random_state=10, subsample=0.6, max_depth=7,
min_samples_split=900)
gbm1.fit(X_train, Y_train)
train_new_feature = gbm1.apply(X_train)
train_new_feature = train_new_feature.reshape(-1, 50)
enc = OneHotEncoder()
enc.fit(train_new_feature)
# # 每一个属性的最大取值数目
# print('每一个特征的最大取值数目:', enc.n_values_)
# print('所有特征的取值数目总和:', enc.n_values_.sum())
train_new_feature2 = np.array(enc.transform(train_new_feature).toarray())
参数:
**OneHotEncoder():**首先fit() 过待转换的数据后,再次transform() 待转换的数据,就可实现对这些数据的所有特征进行One-hot 操作。
由于transform() 后的数据格式不能直接使用,所以最后需要使用.toarray() 将其转换为我们能够使用的数组结构。
enc.transform(train_new_feature).toarray()
十、数据分析的工具
1、TableOne(表1)
前面学习了统计描述和统计假设的Python方法,分析数据表时,需要先确定因变量Y,然后对自变量X逐一分析,最后将结果组织成数据表作为输出,还是比较麻烦,使用TableOne工具可以简化这一过程。
TableOne是生成统计表的工具,常用于生成论文中的表格,TableOne底层也基于scipy和statsmodels模块实现,其代码主要实现了根据数据类型调用不同统计工具,以及组织统计结果的功能。它支持Python和R两种语言,可使用以下方法安装:
pip install tableone
## 也可参照GitHub上的开源项目
git clone https://github.com/tompollard/tableone
分析示例
下例中分析了96年美国大选数据,用groupby参数指定了其因变量,categorical参数指定了自变量中的分类型变量,使用pval=True指定了需要计算假设检验结果,程序最后将结果保存到excel文件中。
import statsmodels as sm
import tableone
data = sm.datasets.anes96.load_pandas().data
categorical = ['TVnews', 'selfLR', 'ClinLR', 'educ', 'income']
groupby = 'vote'
mytable = tableone.TableOne(data, categorical=categorical,
groupby=groupby, pval=True)
mytable.to_excel("a.xlsx")
# from xieyan jianshu blog
表列出了程序的部分输出结果,对于连续变量popul,在统计检验中,用两样本T检验方法计算出p值,在统计描述中,计算出popul的均值和标准差;对于分类变量TWnews,使用卡方检验计算出其p值,并统计出其各分类的例数及占比;表中还展示出对于因变量各类别的记数,空值个数,离群点,以及非正态变量的统计结果。
对于分类型因变量,使用groupby指定其变量名,对于连续型因变量,一般不指定groupby值,TableOne只进行统计描述。
作为小工具,TableOne也有它的局限性,比如它只能对分类型的因变量Y做统计假设,又如它只能按数据类型自动匹配检验方法,不能手动指定具体的假设检验方法,不支持多变量分析等等,可能解决不了所有数据统计问题。但它使用方便,大大简化了分析流程,能在分析初期展示出数据的概况,尤其对于不太熟悉数据分析方法的编程者给出了较好的统计结果。
2、树的可视化(graphviz)
1. 安装
cikit-learn中决策树的可视化一般需要安装graphviz。主要包括graphviz的安装和python的graphviz插件的安装。
第一步是安装graphviz。下载地址在:http://www.graphviz.org/。如果你是linux,可以用apt-get或者yum的方法安装。如果是windows,就在官网下载msi文件安装。无论是linux还是windows,装完后都要设置环境变量,将graphviz的bin目录加到PATH,比如我是windows,将C:/Program Files (x86)/Graphviz2.38/bin/加入了PATH
第二步是安装python插件graphviz: pip install graphviz
第三步是安装python插件pydotplus。这个没有什么好说的: pip install pydotplus
这样环境就搭好了,有时候python会很笨,仍然找不到graphviz,这时,可以在代码里面加入这一行:
os.environ[“PATH”] += os.pathsep + ‘C:/Program Files (x86)/Graphviz2.38/bin/’
注意后面的路径是你自己的graphviz的bin目录。
2.可视化方案
Loading数据:
from sklearn.datasets import load_iris
from sklearn import tree
import sys
import os
os.environ["PATH"] += os.pathsep + 'C:/Program Files (x86)/Graphviz2.38/bin/'
iris = load_iris()
clf = tree.DecisionTreeClassifier()
clf = clf.fit(iris.data, iris.target)
with open("iris.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file=f)
Plot1:graphviz的dot命令生成决策树的可视化文件
#注意,这个命令在命令行执行
dot -Tpdf iris.dot -o iris.pdf
Plot2:pydotplus生成iris.pdf
import pydotplus
dot_data = tree.export_graphviz(clf, out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("iris.pdf")
Plot3:把图产生在ipython的notebook
from IPython.display import Image
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
Image(graph.create_png())
参考文章
[1] CSDN,TableOne数据分析工具:https://blog.csdn.net/xieyan0811/article/details/88768757
[2] CSDN,机器学习算法比拼:https://www.cnblogs.com/ncut/p/6004236.html
[3] CSDN,catboost和xgboost_算法竞赛开挂神器:XGBoost、LightGBM和Catboost一决高低 | 程序员硬核算法评测…:https://blog.csdn.net/weixin_39982269/article/details/112938602?utm_medium=distribute.pc_relevant.none-task-blog-OPENSEARCH-10.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-OPENSEARCH-10.control
[4] CSDN,决策树、随机森林、GBDT、xgboost、lightgbm、CatBoost相关分析:https://blog.csdn.net/u014033218/article/details/88917953?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.control
[5] scikit-learn决策树算法类库使用小结:https://www.cnblogs.com/pinard/p/6056319.html
[6] CSDN,AdaBoostClassifier参数:https://blog.csdn.net/weixin_30335575/article/details/96930839?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.control
[7] LightGBM两种使用方式:https://www.cnblogs.com/chenxiangzhen/p/10894306.html
[8] CatBoost算法梳理:https://zhuanlan.zhihu.com/p/80060646
[9]sklearn随机森林-分类参数详解:https://blog.csdn.net/R18830287035/article/details/89257857?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.control