FileOperations And IO - 文件操作 与 输入输出 - JavaEE初阶 - 细节狂魔
文章目录
- 认识文件
- 普通文件 与 机械硬盘
- 文件的分类
-
- 如何进行文件种类的判断?
- 关于目录的结构
- 如何去描述一个具体的文件?
-
- 路径这里有两种描述风格
-
- 绝对路径
- 相对路径
- java 中操作文件
-
- 文件系统相关的操作
-
- 属性
- 构造方法
- 方法
- 实践
-
- File 类的构造
- 方法实践
-
- getParent、getName、getPath、getAbsolutePath、getCanonicalPath
- exists、isDirectory、isFile
- createNewFile
- delete
- mkdir、mkdirs
- list 、listFiles
- renameTo
- 小结
- 文件内容相关的操作
-
- 针对字节流对象进行读写操作
-
- 读操作
- 写操作
- 针对字符流对象进行读写操作
-
- 读操作
- 写操作
- 拓展
-
- 利用 Scanner 进行字符读取
- 利用 PrintWriter 找到我们熟悉的方法
- 文件操作案例:
-
- 案例1:扫描指定目录,并找到名称中包含指定字符的所有普通文件(不包含目录),并且后续询问用户是否要删除该文件
- 总程序
- 效果图
- 案例2:进行普通文件的复制
- 案例3:扫描指定目录,并找到名称或者内容中包含指定字符的所有普通文件(不包含目录)
- 在文章的最后,我们再拓展一下
-
- flush
- 结束语
认识文件
平时说的文件一般都是指存储在硬盘上的普通文件。
形如:txt文本、jpg图片、mp4视频、rar压缩包等这些文件都可以认为是普通文件。
它们都是在硬盘上存储的。
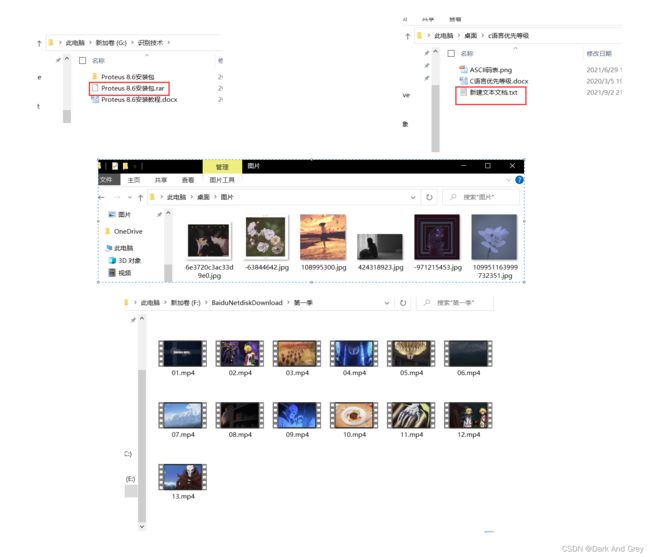
但是站在计算机专业术语的角度上来讲:
在计算机中文件可能是一个广义的概念,就不只是包含普通文件,还可以包含目录(把目录称为目录文件),目录俗称文件夹。
在操作系统中,还会使用文件来描述一些其它的硬件设备或者软件资源。
其实站在操作系统的角度上来看,所谓的文件,其实是一个非常广义的概念。
不仅仅指的是我们日常生活中所说的这些普通文件,也包含目录,还包含一些软硬件资源设备。后面讲网络编程的时候,会讲到一个很重要的设备“网卡”。
网卡,是一个硬件设备。但是在操作系统中就把 网卡 这样的硬件设备也给抽象成了一个文件。
这样的操作,会给我们进行网络编程带来很大便利。
我们要想通过网卡来收数据,直接按照 读文件代码 去写 就可以了。
想通过网卡来发数据,那就按照 写文件代码 去写就行了
这样做带来的好处:简化开发。
通过这种文件的操作,来完成操作网卡的过程。
h除此之外,还有显示器,键盘,这都是硬件设备吧。
操作系统也是把这些设备视为文件。
想从键盘读取数据,其实也是通过类似读文件的方式来进行的。
想往显示器上写一个数据,也是通过类似写文件的方式来进行的。
因此,操作系统谈到的文件,其实是一个更加广泛的概念。它会涉及到各个方面的情况。
当前我们需要讨论的文件,主要还是针对普通文件来讨论的。
后面去学习一些其他的硬件设备对应的文件,其实也是通过类似的代码来实现操作。
因此,我们虽然讨论的是针对普通文件为例来去演示,但实际上这里的一些代码,和后需用到的一些代码,尤其是网络编程的代码,是非常具有共性的。
普通文件 与 机械硬盘
普通文件是保存在硬盘上的。【一般讨论的都是机械硬盘】
机械硬盘一旦通电,里面的盘片就会高速运转,
例如:我们使用的是 7200转/分钟 的家用机械硬盘,那么,每秒就是 120转/秒。
磁头就会在盘片上找到对应的数据。因为盘片上是有一圈圈 磁道的。
然后呢,我们就把数据 去按照这一圈一圈的方式来往上去写。
因为这里面的盘片,其实是一个非常精密的设备。
这里面是可以存储很多数据的。
像这么小的硬盘(大概只有现在手机的一半大小),就可以存储上T的数据。
但是 存储空间的大小,受限于机械硬盘的硬件结构。
盘片转速越高,读写速度也就越快。
但是因为工艺的限制,盘片的转速也不可能无限高。
(现在最好的机械硬盘大概是每分钟 1 万 多 转)
另外,机械硬盘的读写速度,已经有10年 停滞不前了。【技术上无法精进】
现在的机械硬盘都是往大容量的方向发展。
前面的博文也说到过,内存的读写速度 比 现在的硬盘读写速度 快很多!!!
快 3-4 个数量级,大概是上万倍。
后面为了解决这个问题,就有了固态硬盘(SSD)。
固态硬盘的硬件结构 和 机械硬盘 截然不同。
固态硬盘就是一个大号的U盘。
U盘:里面可以存储数据,但是又不需要盘片这些东西。主要是 flash 芯片(闪存),通过这个东西来进行存储数据,而且能获取到更高速率的读写。
所以,固态硬盘的读写速度要比机械硬盘高很多。【高好几倍】
现在最好的固态硬盘,读写速度已经接近十几年前的内存水平了。


本篇博文主要讨论的是 以机械硬盘为主。
因为当前企业中使用的服务器还是以机械硬盘为主。因为 SSD 的成本 是 机械硬盘的好几倍。(4-5倍)
文件的分类
站在程序员的角度,主要把文件分成两类:
1、文本文件:里面存储的是字符
2、二进制文件:里面存储的是字节
针对这两种文件,在编程的时候会存在差异。有的人可能会有疑问:字符不也是字节构成的吗?
是的,确实如此。文本文件本质上也是存字节的。
但是文本文件中,相邻的字节在一起正好能构成一个个的字符。
所以,我们所说的存储单位是 字符,其实意思就是:相邻的这些字节之间 是存在关联关系的,不是毫不相干的!
而二进制文件里面存储的字节,相互之间是完全没有关系。
如何进行文件种类的判断?
我们判定一个文件是文本 ,还是 二进制文件,有一个简单直接的方法。
就是 把一个文件直接用记事本打开,如果是乱码就是 二进制文件,如果不是乱码就是文本。

关于目录的结构
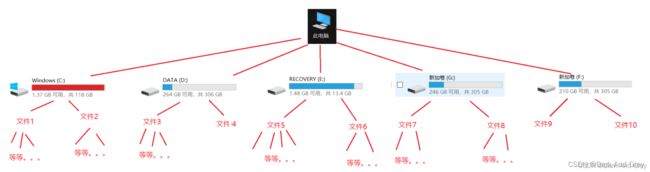
计算机里,保存管理文件,是通过 操作系统 中的“文件系统” 这样的模块来负责的。
在文件系统中,一般是通过“树形”结构来组织硬盘上的目录和文件的。【N叉树】
这个我在二叉树俩面讲到过。
上图中的文件,可能是目录文件,也可能是文本文件。
也就是说普通文件,一定是树的叶子结点。
目录文件,就可以看作是一个子树,也就是非叶子节点。
如何去描述一个具体的文件?
在操作系统中,就通过“路径” 这样的概念,来描述一个具体 文件/目录 的位置。
路径这里有两种描述风格
绝对路径
以盘符开头的。【以 C、D、E、F等等,盘名开头的】
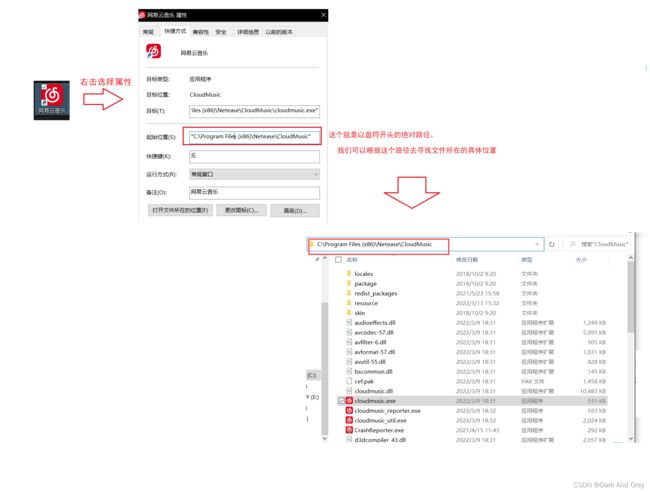
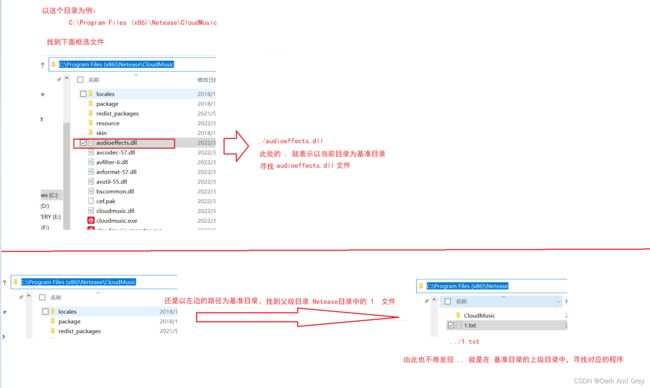
相对路径
以 . 或者 … 开头的文件路径。
其中 . 表示当前路径, … 表示当前路径的父目录(上级路径)。谈到相对路径,必须要有一个基准目录。
对于路径就是从基准目录出发,按照一个什么样的路径找到的对应文件。
注意!即使是定位到同一个文件,如果基准路径不同,此时的相对路径也就不同
绝对路径 和 相对路径 的概念非常重要!!!!
虽然面试不考,但是我们在后面的编程中,需要频繁的和这些路径打交道。、

java 中操作文件
Java中操作文件,主要是包含两类操作
1、文件系统相关的操作
2、文件内容相关的操作
关于 文件操作,这个在C语言里面也讲过。
虽然 Java中的文件操作 和 C 语言中的操作,差别还是蛮大的。
但是基本的思路是一样的。
文件系统相关的操作
这个是C语言中没有的操作。C语言标准库不支持这个操作。
文件系统相关的操作:指的是通过“文件资源管理器” 能够完成的一些功能
它具有的功能
1、列出目录中有哪些文件
2、创建文件(直接右键点击菜单创建,就可以创建了)
3、创建 目录/文件夹
4、删除文件
5、重命名文件
…
这些都是文件资源管理器所能够完成的功能。
简单来说 文件资源管理器 能做什么,我们的文件系统相关操作的代码就能做什么。
在Java中提供了一个 File 类,通过这个类来完成上述操作。
首先,这个File类就描述了一个文件/目录。
基于这个对象就可以实现上面的功能。
属性
| 修饰符及类型 | 属性 | 说明 |
|---|---|---|
| static String | pathSeparator | 依赖于系统的路径分隔符,String 类型的表示 |
| static char | pathSeparator | 依赖于系统的路径分隔符,char 类型的表示 |
构造方法
| 签名 | 说明 |
|---|---|
| File(File parent, Stringchild) | 根据父目录 + 孩子文件路径,创建一个新的 File 实例 |
| File(String pathname) | 根据文件路径创建一个新的 File 实例,路径可以是绝对路径或者相对路径 |
| File(String parent, Stringchild) | 根据父目录 + 孩子文件路径,创建一个新的 File 实例,父目录用路径表示 |
File 的构造方法,能够传入一个路径,来指定一个文件。
这个路径可以是绝对路径,也可以是相对路径。
方法
构造好对象之后,就可以通过这些方法,来完成一些具体的功能了。
| 修饰符及返回值类型 | 方法签名 | 说明 |
|---|---|---|
| String | getParent() | 返回 File 对象的父目录文件路径 |
| String | getName() | 返回 FIle 对象的纯文件名称 |
| String | getPath() | 返回 File 对象的文件路径 |
| String | getAbsolutePath() | 返回 File 对象的绝对路径 |
| String | getCanonicalPath() | 返回 File 对象的修饰过的绝对路径 |
| boolean | exists() | 判断 File 对象描述的文件是否真实存在 |
| boolean | isDirectory() | 判断 File 对象代表的文件是否是一个目录 |
| boolean | isFile() | 判断 File 对象代表的文件是否是一个普通文件 |
| boolean | createNewFile() | 根据 File 对象,自动创建一个空文件。成功创建后返回 true |
| boolean | delete() | 根据 File 对象,删除该文件。成功删除后返回 true |
| void | deleteOnExit() | 根据 File 对象,标注文件将被删除,删除动作会到。JVM 运行结束时才会进行 |
| String[] | list() | 返回 File 对象代表的目录下的所有文件名 |
| File[] | listFiles() | 返回 File 对象代表的目录下的所有文件,以 File 对象表示 |
| boolean | mkdir() | 创建 File 对象代表的目录 |
| boolean | mkdirs() | 创建 File 对象代表的目录,如果必要,会创建中间目录 |
| boolean | renameTo(Filedest) | 进行文件改名,也可以视为我们平时的剪切、粘贴操作 |
| boolean | canRead() | 判断用户是否对文件有可读权限 |
| boolean | canWrite() | 判断用户是否对文件有可写权限 |
实践
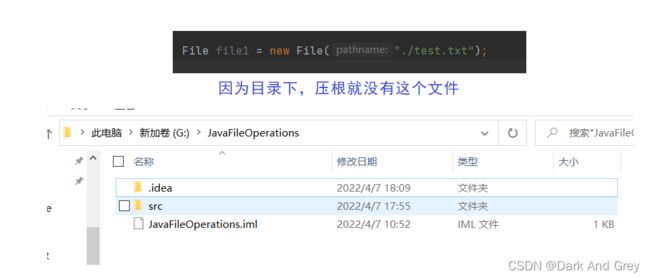
File 类的构造

另外此时下面这个代码,是找不到指定的 test.txt 文件的。
方法实践
getParent、getName、getPath、getAbsolutePath、getCanonicalPath
public class TestDemo1 {
public static void main(String[] args) throws IOException {
File file = new File("d:/test.txt");
System.out.println(file.getParent());// 获取到文件的父目录文件路径
System.out.println(file.getName());// 获取到文件名
System.out.println(file.getPath());// 获取到文件路径(构造 file 的时候指定的路径)
System.out.println(file.getAbsolutePath());// 获取到绝对路径
System.out.println(file.getCanonicalPath());// 获取到绝对路径.[需要处理异常]
System.out.println("====================");
File file1 = new File("./test.txt");
System.out.println(file1.getParent());// 获取到文件的父目录文件路径
System.out.println(file1.getName());// 获取到文件名
System.out.println(file1.getPath());// 获取到文件路径(构造 file 的时候指定的路径)
System.out.println(file1.getAbsolutePath());// 获取到绝对路径
System.out.println(file1.getCanonicalPath());// 获取到绝对路径.[需要处理异常]
}
}

exists、isDirectory、isFile
import java.io.File;
public class TestDemo2 {
public static void main(String[] args) {
File file = new File("d:/test.txt");
System.out.println(file.exists());//判断文件是否真实存在
System.out.println(file.isDirectory());//判断文件是否是一个目录
System.out.println(file.isFile());//判断文件是否是一个普通文件
System.out.println("==========");
File file1 = new File("./test.txt");
System.out.println(file1.exists());//判断文件是否真实存在
System.out.println(file1.isDirectory());//判断文件是否是一个目录
System.out.println(file1.isFile());//判断文件是否是一个普通文件
}
}
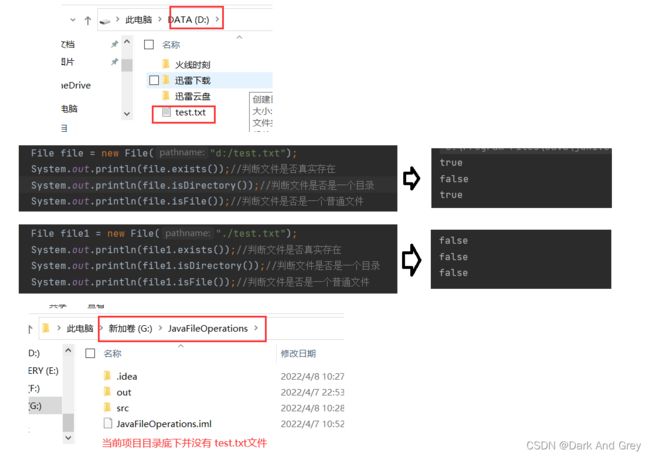
createNewFile
public class TestDemo3 {
public static void main(String[] args) throws IOException {
File file = new File("./test.txt");
System.out.println(file.exists());//判断文件是否真实存在
file.createNewFile();// 创建文件
System.out.println(file.exists());
}
}
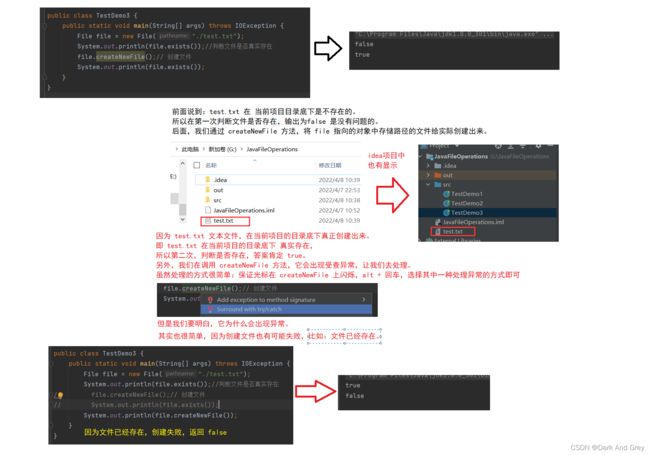
delete
import java.io.File;
public class TestDemo4 {
public static void main(String[] args) {
File file = new File("./test.txt");
System.out.println(file.exists());
file.delete();// 删除文件
System.out.println(file.exists());
}
}
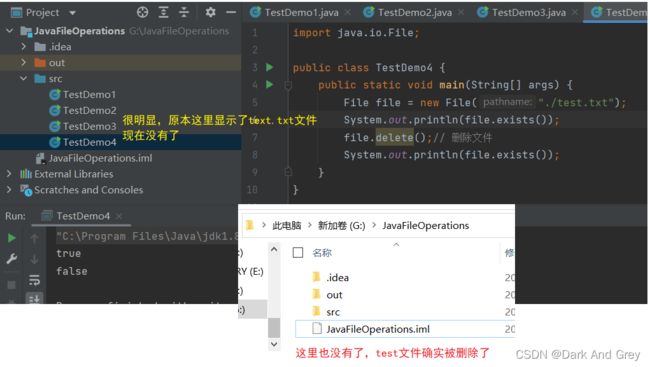
mkdir、mkdirs
public class TestDemo5 {
public static void main(String[] args) {
//在当前项目底下创建一个 aaa 目录
File file = new File("./aaa");
System.out.println(file.isDirectory());
file.mkdir();// mkdir 方法 只能创建一级目录
System.out.println(file.isDirectory());
}
}

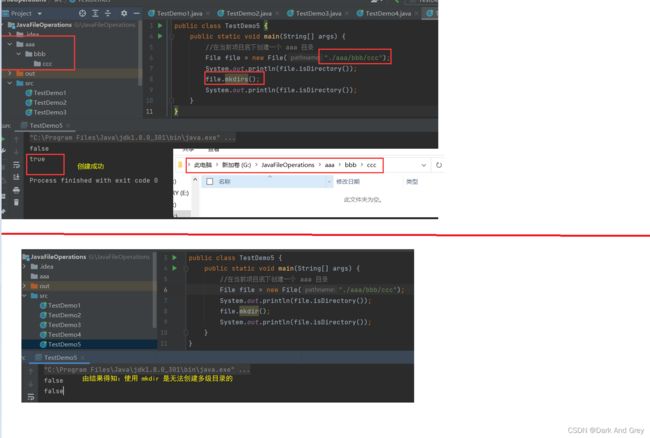
与mkdir方法,相似的方法还有一个 mkdirs 方法,
意思创建多级目录。
public class TestDemo5 {
public static void main(String[] args) {
//在当前项目底下创建一个 aaa 目录
File file = new File("./aaa/bbb/ccc");
System.out.println(file.isDirectory());
file.mkdirs();
System.out.println(file.isDirectory());
}
}
list 、listFiles
public class TestDemo6 {
public static void main(String[] args) {
File file = new File("./aaa");
System.out.println(file.list());
// 这个操作就是把 aaa目录里面的内容列举出来
System.out.println(Arrays.toString(file.list()));
}
}
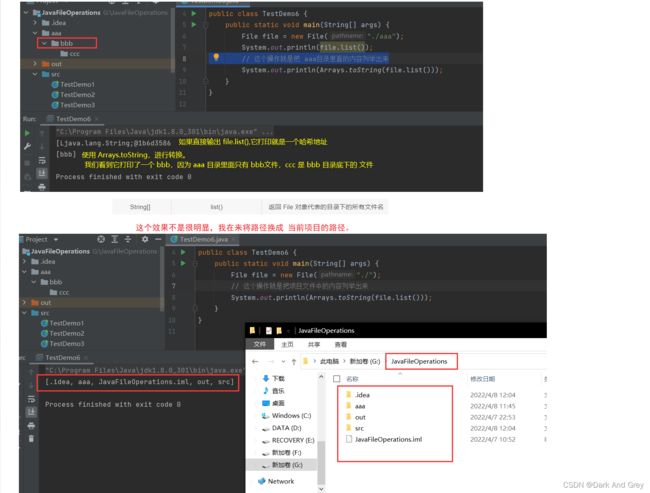
再来看listFiles。
listFiles 方法 和 list 方法差不多,只是返回的类型不同。
listFiles 返回是 File 类型的数组。
list 返回的是 字符串数组。不然我们也不可能通过数组的方法,来输出结果。


renameTo

小结
目前上述操作,都是针对文件系统的操作。
主要还是 增删改查 的一些操作。
但是呢,这些操作只是作用于文件表面,并没有对文件的内容做出实质性的改变。
文件内容相关的操作
1、打开文件
2、读文件
3、写文件
4、关闭文件
针对文件内容的读写,Java提供了一组类来完成上述操作 。
在操作文件内容之前,我们首先要明白操作的文件,是二进制文件,还是文本文件、
辨别方法,在前面已经说了,这里就不再赘述。

针对字节流对象进行读写操作
读操作
先拿 FileInputStream来进行演示
知识点:异常 和 知识点:继承

import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
public class TestDemo8 {
public static void main(String[] args) {
// FileInputStream 的 构造方法 需要制定打开文件的路径
// 这路的路径可以是绝对路径,相对路径,还可以是 File 对象
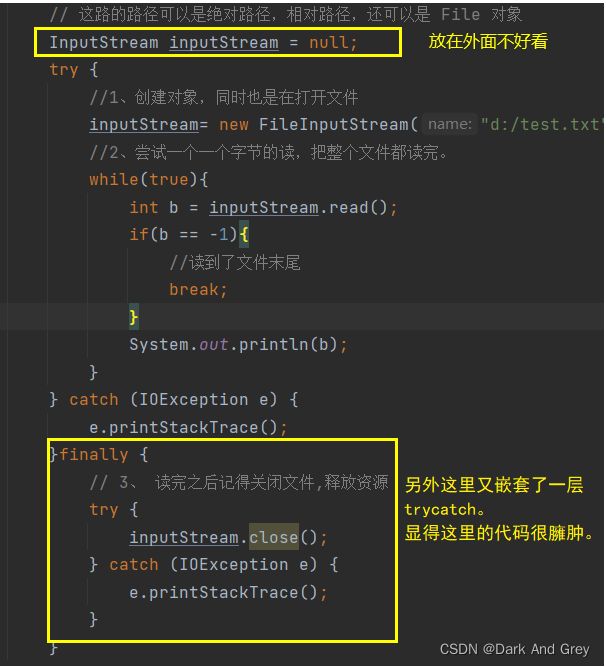
InputStream inputStream = null;
try {
//1、创建对象,同时也是在打开文件
inputStream= new FileInputStream("d:/test.txt");
//2、尝试一个一个字节的读,把整个文件都读完。
while(true){
int b = inputStream.read();
if(b == -1){
//读到了文件末尾
break;
}
System.out.println(b);
}
} catch (IOException e) {
e.printStackTrace();
}finally {
// 3、 读完之后记得关闭文件,释放资源
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
代码是写出来,问题也都解决了。
但是!你们不觉这个代码太啰嗦了吗?
这里就可以使用到一个 Java中提供的一个语法:try with resources。
就是 try 后面加一个小括号:try()
将 创建 FIleInputStream 对象的代码,作为参数放在 try括号
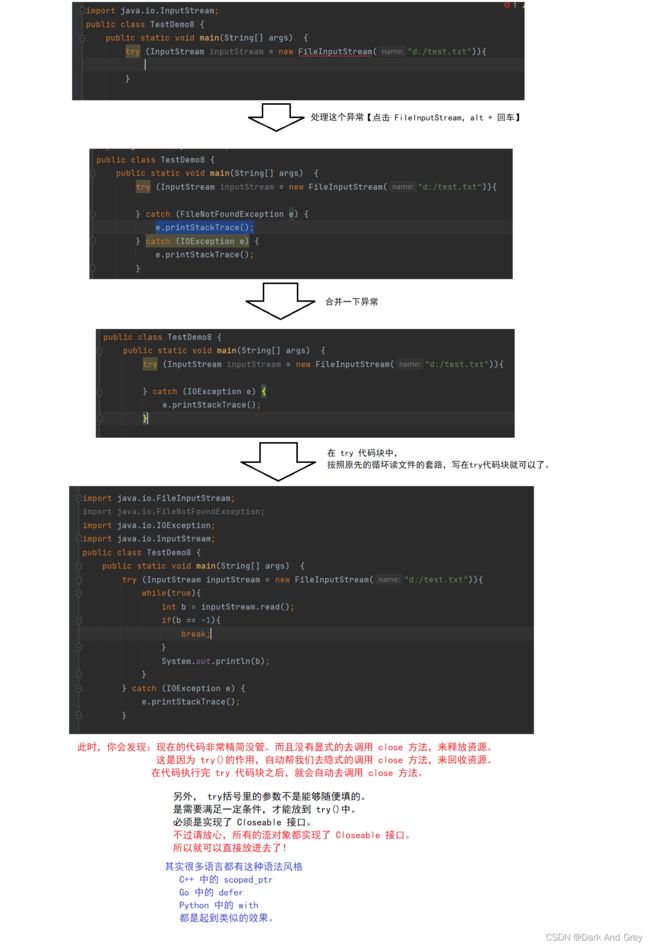
import java.io.*;
public class TestDemo8 {
public static void main(String[] args) {
try (InputStream inputStream = new FileInputStream("d:/test.txt")){
while(true){
int b = inputStream.read();
if(b == -1){
break;
}
System.out.println(b);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
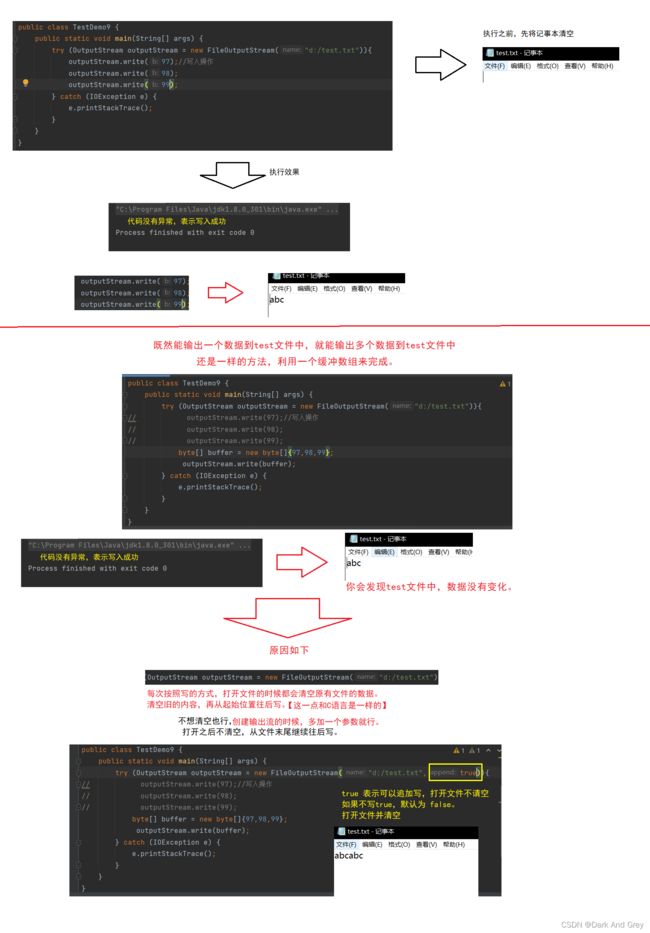
下面我们来一次读取多个字节
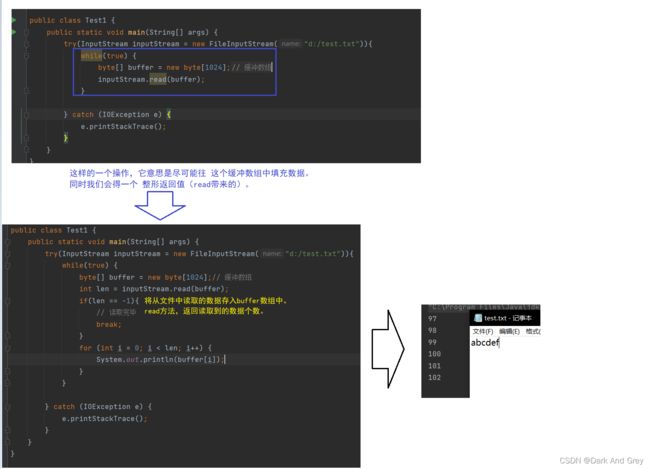
这个操作是把读出来的结果放到 buffer这个数组中。
相当于是使用 参数 来表示方法的返回值。
这种做法称为“输出型参数”
这种操作,在Java中比较少见,C++ 中遍地都是举个例子
我们去食堂打饭,因为我们肩负着一个寝室里那些垂死挣扎的儿子们 活下去的希望。
我们得带一个盆去打饭。
把盆交给打饭的阿姨,人家阿姨看见这架势,恨不得跟你来一波盆互换。
在看到你后面的人,她也只能按照规定给几勺饭 和 菜。
我们盆拿回来的时候,盆里面是阿姨对我们满满的爱。
这就跟上面的情况是一样的。
你要一次读几个数据。
你得先有容器来存储。
要不然数据放哪里?
这种一次读几个的操作,在日常开发中是非常常见的。
相比上面的一次只读取一个,更加高效。
第三个版本我们不去讲,用得少。
写操作
和上面的读操作一样,差别不大。
只是把输入流(InputStream),换成了输出流(OutputStream)
针对字符流对象进行读写操作
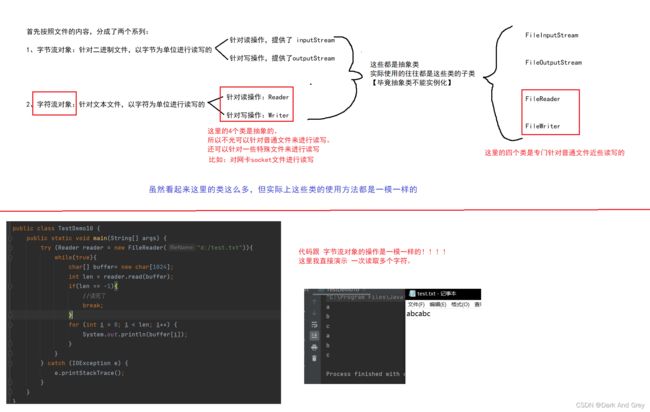
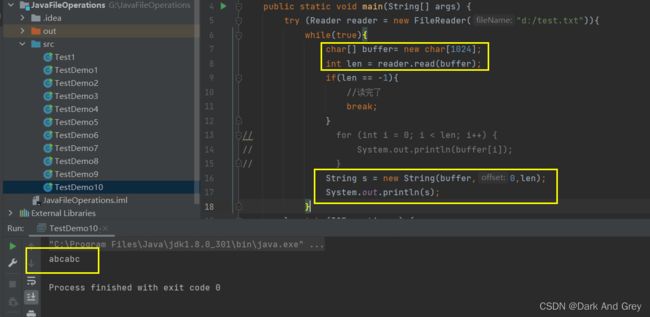
读操作
还有一种输出方式
细节

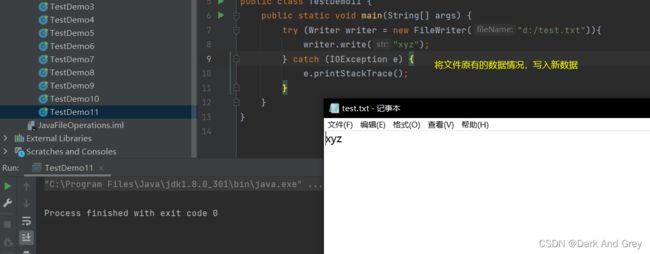
写操作

拓展
利用 Scanner 进行字符读取
上述例子中,我们看到了对字节类型直接使用 InputStream 进行读取是非常麻烦且困难的,所以,我们使用一种我们之前比较熟悉的类来完成该工作,就是 Scanner 类。
import java.io.*;
import java.util.*;
// 需要先在项目目录下准备好一个 hello.txt 的文件,里面填充 "你好中国" 的内容
public class Main {
public static void main(String[] args) throws IOException {
try (InputStream is = new FileInputStream("hello.txt")) {
try (Scanner scanner = new Scanner(is, "UTF-8")) {
while (scanner.hasNext()) {
String s = scanner.next();
System.out.print(s);
}
}
}
}
}
利用 PrintWriter 找到我们熟悉的方法
我们接来下将 OutputStream 处理下,使用
PrintWriter 类来完成输出,因为PrintWriter 类中提供了我们熟悉的 print/println/printf 方法
import java.io.*;
public class Main {
public static void main(String[] args) throws IOException {
try (OutputStream os = new FileOutputStream("output.txt")) {
try (OutputStreamWriter osWriter = new OutputStreamWriter(os,"UTF-8")) {
try (PrintWriter writer = new PrintWriter(osWriter)) {
writer.println("我是第一行");
writer.print("我的第二行\r\n");
writer.printf("%d: 我的第三行\r\n", 1 + 1);
writer.flush();
}
}
}
}
}
文件操作案例:
案例1:扫描指定目录,并找到名称中包含指定字符的所有普通文件(不包含目录),并且后续询问用户是否要删除该文件
意思就是:
用户输入一个目录
再输入一个要删除的文件名
找到名称中包含指定字符的所有普通文件
询问用户是否要删除该文件
、

总程序
import java.io.File;
import java.io.IOException;
import java.util.Scanner;
// 案例1:实现查找文件并删除胡
public class TestDemo12 {
public static void main(String[] args) {
//1、先输入要扫描的目录,以及要删除的文件名
Scanner sc = new Scanner(System.in);
System.out.println("请输入要扫描的路径:");
String rootDirectoryPath = sc.next();
System.out.println("请输入要删除的文件类:");
String DeleteFileName = sc.next();
// 以 rootDirectoryPath 的路径,创建一个 File 对象
File rootDirectory = new File(rootDirectoryPath);
if(!rootDirectory.isDirectory()){
//判断输入路径是否正确/存在
//如果不存在,执行下面内容
System.out.println("输入的扫描路径有误");
return;
}
// 2、遍历目录,把指定目录中的所有文件 和 子目录 都遍历一遍,从而要找删除的文件。
//通过scannerDirectory方法来实现递归遍历,并删除的功能
scannerDirectory(rootDirectory,DeleteFileName);
}
private static void scannerDirectory(File rootDirectory,String DeleteFileName){
// 1、 先列出 rootDirectory 中都有哪些内容
File[] files = rootDirectory.listFiles();
if(files == null){
// rootDirectory 是一个空目录,即 files 就是一个空数组
return;
}
//2、遍历当前列出的这些内容,如果是普通文件
// 检测文件名 是否是 要删除的文件。【不要求名字完全一样,只要文件名包含了关键字,即可删除】
// 如果是目录,就递归的进行遍历
for (File f:files) {
//判断是否是普通文件
if(f.isFile()){
if(f.getName().contains(DeleteFileName)){
//进行删除操作
deleteFile(f);
}// 判断是否是目录
}else if(f.isDirectory()){
// 目录 就递归的进行遍历
scannerDirectory(f,DeleteFileName);
}
}
}
private static void deleteFile(File f){
try {
System.out.println("确认要删除"+f.getCanonicalPath() + "?" +" (Yes Or No)");
Scanner sc = new Scanner(System.in);
String choice = sc.next();
if(choice.equals("Yes") || choice.equals("No")){
f.delete();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
知识点:二叉树的层序遍历

效果图
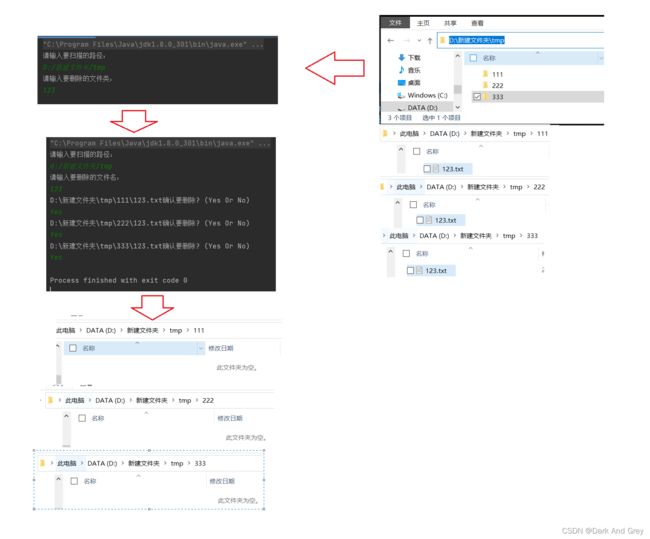
案例2:进行普通文件的复制
文件复制,其实说白了:就是将文件给拷贝一个副本。
我们需要让用户指定两个文件路径。
一个是原路径(被复制的文件)
一个是目标路径(复制之后生成的文件)
从哪里复制到哪里,从哪里来到哪来去。
我们需要描述清楚 起点 和 终点。
然后,我们就可以在这个基础上进行具体复制操作
我们要做的事很简单。
打开源路径文件,读取里面的内容,并写入到目标文件中,
import java.io.*;
import java.util.Scanner;
public class TestDemo13 {
public static void main(String[] args) {
//1、输入两个路径
Scanner sc = new Scanner(System.in);
System.out.println("请输入要拷贝的源路径:");
String source = sc.next();
System.out.println("请输入要拷贝的目标路径:");
String destination = sc.next();
File file = new File(source);
if(!file.isFile()){
System.out.println("输入的源路径不正确!");
return;
}
// 此处不太需要检查目标文件是否存在,OutputStream 写文件的时候,能够自动创建不存在的文件。
//2、读取源文件,拷贝到目标路径
try(InputStream inputStream = new FileInputStream(source)){
try(OutputStream outputStream= new FileOutputStream(destination)){
// 把 inputStream 的数据 读出来,写到 outputStream
byte[] buffer= new byte[1024];
while(true){
// 从 source 文件读取到的元素个数
int len = inputStream.read(buffer);
if(len == -1){
// 文件读完了
break;
}
// 写入的时候,不能把整个buffer 都写进入。
// 毕竟 buffer 可能只有一部分才是有效数据。【数组可能没存满】
outputStream.write(buffer,0,len);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
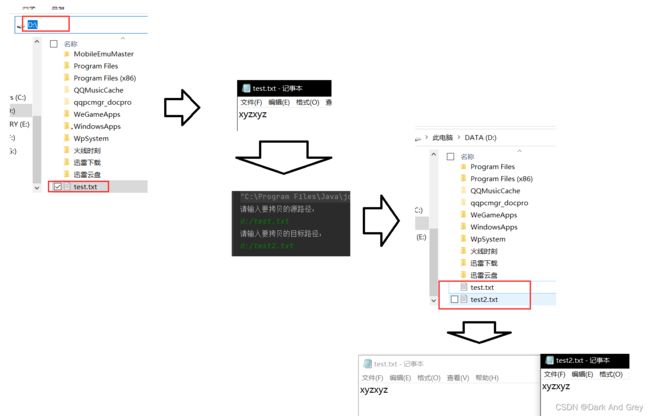
注意可以复制文件的,不止文本文件。只要是普通文件就行。
【jpg图片、mp4视频、rar压缩包等】
案例3:扫描指定目录,并找到名称或者内容中包含指定字符的所有普通文件(不包含目录)
进行文件内容的查找
1、输入一个路径
2、再输入一个要查找文件的 关键字
3、递归的遍历文件,找到看哪个文件里的内容包含了那些关键词,就把对应的文件路径打印出来。
思路和案例1一样,先递归遍历文件,针对每个文件都打开,并读取内容,再进行字符串查找即可。
import java.io.*;
import java.util.Scanner;
public class TestDemo14 {
public static void main(String[] args) throws IOException {
Scanner sc = new Scanner(System.in);
System.out.println("输入要扫描的路径:");
String rootDirectoryPath = sc.next();
System.out.println("输入要查询的文件名关键字:");
String keyword = sc.next();
File file = new File(rootDirectoryPath);
if(!file.isDirectory()){
// 此路径不存在
System.out.println("输入的扫描路径错误!");
return;
}
//3、进行递归遍历
scannerDirectory(file,keyword);
}
private static void scannerDirectory(File file,String keyword) throws IOException {
// 1、先列出 file 中 有哪些内容
File[] files = file.listFiles();
if(files == null){
return;
}
for (File f: files) {
if(f.isFile()){
// 针对普通文件的内容,进行判断,是否满足查询条件【文件内容 是否包含 关键字keyword】
if(containsKeyword(f,keyword)){
System.out.println(f.getCanonicalPath());
}
}else if(f.isDirectory()){
// 针对目录进行递归
scannerDirectory(f,keyword);
}
}
}
private static boolean containsKeyword(File f,String keyword){
//把 f 中的内容 都读出来,进行遍历,放到一个 StringBuilder 中
StringBuilder stringBuilder = new StringBuilder();
try (Reader reader = new FileReader(f)){
char[] buffer = new char[1024];
while(true){
int len = reader.read(buffer);
if(len == -1){
break;
}
// 把这一段读到的结果,放到 StringBuilder中
stringBuilder.append(buffer,0,len);
}
} catch (IOException e) {
e.printStackTrace();
}
// indexOf 返回的是子串(keyword)的下标,如果 word 在 stringBuilder中不存在,则返回 -1。
return stringBuilder.indexOf(keyword) != -1;
}
}
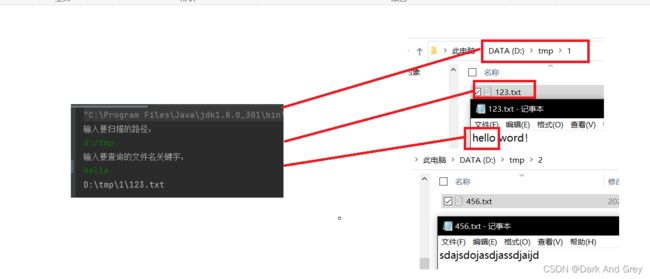
另外,说一下:目前我们写的代码是很低效的。
低效就体现在 它需要把我们所有的文件都遍历一次。
如果我们 以 D 盘 为扫描路径,由于D盘文件很多,因此遍历会变得非常耗时!
不信,你们可以将上面的程序,拷贝下来执行一下就知道了。
作者的D盘用了37G,你们估计更大,试想一下,搜索上百G的数据,zz。。。
要想实现更高效的检索,需要 倒排索引 这样的数据结构。
【想知道哦具体,自己去拓展。】
除了上述方法之外,还可以使用多线程,这样做也可以提高效率。可以创建一个线程池,每次遍历到一个文件,就把这个文件交给线程池,由线程池来负责打开文件,读文件,indexOf 的操作。
但是还是 倒排索引的方式,效率更高。
理论上时间复杂度可达到O(1).

在文章的最后,我们再拓展一下
flush
flush 叫做 “刷新缓冲区”
缓冲区
举例:嗑瓜子
嗑瓜子,就一定会产生瓜子壳。【狠人,你可以开始骄傲了。】
瓜子壳,这东西肯定不能乱吐,容易引起母亲的愤怒值,导致有生命危险!
我们要吐到垃圾桶里。
假设垃圾桶被你妈拿到厨房去了,我们得走过去吐。
走过去肯定是要花时间的。
吐完之后,回来坐着继续磕。
磕完全再去厨房吐,来回几趟。
突然,我们意识这是一种呆子行为,父母投过来的目光,充满轻蔑。
正确行为:
手里叠几层卫生纸,嗑完的瓜子壳,直接吐在手中的纸上。
磕得差不多了,再去一把丢了,这样效率就大大提升了。
【不要问,为什么不直接拿垃圾桶过来。因为这会影响到你妈呼吸到空气,从而对你进行定位打击】
此时,我们托着瓜子壳的手,就是一个“缓冲区”。
缓冲区存在的意义就是为了提高效率。
在计算机中尤其重要。
CPU 在读取内存的速度是大于硬盘的。例如 :
需要写数据到硬盘上,与其一次写一点,分多次写,不如把一些数据攒一堆,一次性写完。
读操作也是同理,与其一次读一点,分多次读,不如一次性读一堆,然后再慢慢消化。
这一堆数据就是在内存中保存的,这块内存就叫做缓冲区。
回过头,我们再来理解一下 “刷新缓冲区”
例如:
写数据的时候,需要把数据先写到缓冲区里,然后再统一写入硬盘。
如果当前缓冲区已经写满了,就直接触发写硬盘操作。
如果当前缓冲区还没写满,想提前将数据写入到硬盘里,这时就可以通过 flush 来手动“刷新缓冲区”。就是瓜子磕到一半,突然不想磕了。寡人累了。。。
于是,就将手里还没有装满的瓜子壳,直接全丢了。
我们前面的代码,没有涉及到 flush。
是因为当前的代码并没有涉及到很多数据,很快就执行完了 try 代码。
而 try 代码块结束的一瞬间,就会自动帮我们隐式调用 close操作。
close操作,就会触发 缓冲区刷新。
所以前面的代码,并没有必要去刷新内存。
在日常开发中,也很少会涉及到 flush操作。
所以,大家只要了解有这个东西即可。
结束语
IO 流 这里,还有很多的知识点,包括流对象也有很多中。
学海无涯,施主请停止内卷,不要继续深入文件操作,很多操作是平常压根涉及不到的。我这里讲的都是平常最长用的东西。
前面讲synchronized,可以保证 内存可见性 和 禁止指令重排序,这个说法并不准确,经不起推敲。看到这里朋友,可以折回去看一下。我已经做出修改了。
文章多线程基础篇
由于指令重排序不好讲。
但是我还是在这里将这个问题拿出来讲。
问题出在 单例模式 - 懒汉模式中
此处的 volatile 是能够让其他线程修改了这里的instance 之后,保证后面的线程能够及时感知到修改。
这里的逻辑不是很融洽。
其他线程再调用 单例线程的时候,也是加了 synchronized 的。
从一方面来说,保证了 内存可见性。
照理说 volatile 是不需要的,但是问了一位专业人士,说这里的 volatile 仍然是需要的。
这里的 volatile 最大用处是 禁止 指令重排序。
在这里,我深感抱歉。




