搜索推荐项目EFLS开源 | 阿里妈妈联邦学习解决方案详解
猜你喜欢
0、京东推荐算法精排技术实践
1、如何搭建一套个性化推荐系统?
2、从零开始搭建创业公司后台技术栈
3、【万字干货】某视频APP推荐详解
4、微博推荐算法实践与机器学习平台演进
5、腾讯PCG推荐系统应用实践
6、强化学习算法在京东广告序列推荐场景的应用
7、飞猪信息流内容推荐探索
8、华为项目管理培训教材
9、美团大脑系列之商品知识图谱的构建和应用
▐ 项目背景
移动互联网时代出于隐私保护和数据安全,APP 之间的开放与互联越来越少,使大量的信息孤岛逐渐形成,限制了信息技术更好地服务广大用户的能力。2016年 Google 提出了以保护终端隐私为前提的机器学习方法——联邦学习[1]。为了将联邦学习理论更好地引入到阿里妈妈业务场景,发挥其隐私保护和算法理论的优势,阿里妈妈算法工程团队 与 阿里妈妈大外投广告算法团队 于近期开源了 Elastic-Federated-Learning-Solution(弹性联邦学习解决方案,以下简称 EFLS)项目。该项目经过阿里妈妈外投广告业务与业界多个合作方深入大规模实践,旨在沉淀归纳出联邦学习场景下通用的解决方案及算法实践经验,希望未来可以对搜推广业务在大规模稀疏场景下的联邦学习应用产生参考价值和加速作用。
本文将对 EFLS 项目的业务价值、核心功能以及关键实现做简要介绍,希望给从事相关工作的同学带来一点启发和帮助,欢迎试用及交流讨论。
GitHub地址:
https://github.com/alibaba/Elastic-Federated-Learning-Solution
▐ 业务应用
业务背景
目前联邦学习技术已经在金融领域大规模应用,在广告搜索推荐这种大规模稀疏场景领域的应用和研究尚处于发展初期。作为 EFLS 的诞生地,阿里妈妈大外投业务具有如下特点:
伴随着外部媒体短视频流量异军突起,商家有从媒体引流电商的需求,而商家在媒体直投存在后链路效果分析成本高、无法同时在多个媒体投放的问题。阿里妈妈大外投能够建立统一的外投能力,服务商家一键投放多个媒体,同时在商家营销服务上可以提供强大的营销效果分析能力解决商家在外部媒体投放的痛点。
不同于淘内广告建模中我们能获取丰富的前链路行为,我们在外投广告中对用户在媒体端的前链路行为一无所知。由于企业数据互为商业机密,媒体不能共享用户的内容偏好,而我们也不能透出用户的电商偏好,外投广告系统无法像内投场景能够形成数据闭环进行全链路优化。
为了更好的服务商家,媒体和阿里妈妈都有通过个性化建模提升商家roi的效果优化诉求,伴随着越来越强的隐私监管,双方的合作必须在更加合规的隐私保护的前提下进行。
应用方案
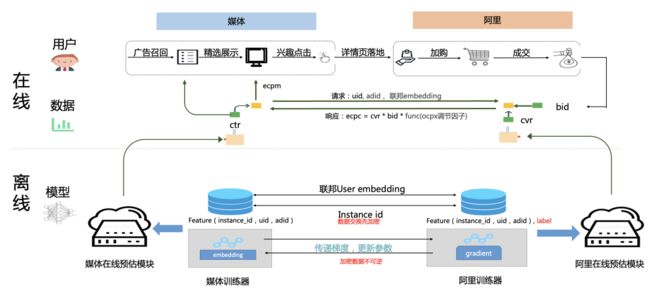
如上图所示(图中术语释义请见附录2),阿里妈妈大外投业务的在线广告投放阶段,媒体方和电商方会在双方严格保护其各自用户隐私的前提下,基于联邦学习训练的点击转化率预估模型和ocpx机制为用户推荐感兴趣的广告,以保证用户体验和商家的广告投放效果。用户根据兴趣点击后,将跳转到电商平台,电商侧会存有商品特征、用户历史特征以及本次点击收藏加购成交等信息。由于隐私数据不能泄漏,从媒体方的广告推荐到电商方的收藏加购整个过程将被使用 instance_id 进行标识。在离线训练阶段,媒体方与电商方将先通过在线模型产生的 log 结合 instance_id、加密设备id、广告id 等生成样本数据,随后双方将采用样本集合求交,通过加密传递instance_id等标签的方式,将样本数据对齐。样本数据对齐后,媒体方与电商方将采用对齐的样本数据,同时进行模型训练。在训练过程中,有 label 的电商一方作为主导方,协同方媒体方会将一个训练的中间结果经过隐私加密之后发送给主导方,主导方在计算反向的梯度之后,将协同方发送来的中间结果对应的梯度经过加密后发送给协同方,完成训练迭代。从而实现在不共享隐私数据的情况下,同时进行媒体方与电商方的模型训练。
业务价值
依托于 EFLS,阿里妈妈 Unidesk 产品已助力珀莱雅、卡姿兰、薇诺娜、花西子、修正等多个企业实现品牌和业务双丰收。其中一些合作品牌在2个月时间内获得品牌 ROI 15% 的提升,经营效果提升明显,且放量也在逐步提高。
EFLS 希望能够为隐私计算领域贡献一份力量,在如今人们越来越注重隐私保护的大背景下,构成在搜推广的大规模稀疏场景下高效隐私计算的完整解决方案。接下来将重点介绍我们从业务中抽象和开源出来的 EFLS 的架构与核心功能。
▐ 项目架构与核心功能
常用的联邦学习主要有纵向联邦学习和横向联邦学习两种。当两个数据集的用户特征重叠较多,而用户重叠较少时,一般采用横向联邦学习,把数据集按照横向(即用户维度)切分,并取出双方用户特征相同而用户不完全相同的部分数据进行训练。当两个数据集的用户重叠较多而用户特征重叠较少时,一般采用纵向联邦学习把数据集按照纵向(即特征维度)切分,并取出双方用户相同而用户特征不完全相同的那部分数据进行训练。[2]
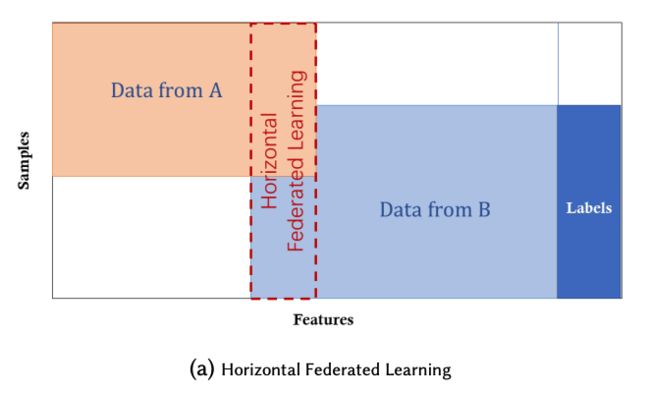
EFLS v0.1 版本主要针对于两方纵向联邦学习场景,即支持两个合作方在特征维度拓展样本,并进行联合训练。在系统部分包含三个主要模块:EFLS-Data(样本集合求交)、EFLS-Train(联邦联合训练)以及 EFLS-Console(产品控制台),在 EFLS-Algo 联邦学习算法包部分提供了两种在联邦场景较为有效的算法模型。EFLS 的使用者可以在此基础上根据自身情况自行生成样本并选择存储方式,根据需要使用或者设计联邦学习算法,并采用提供的 Web 控制台管理与合作方的连接关系,并维护己方的样本集合求交任务和联邦联合训练任务。

目前开源项目的核心功能主要有:
基于workflow的抽象开发的可视化web界面,便于进行用户、任务、数据和权限的管控,缩短开发周期。
基于Flink on K8S[4][5]云原生实现方案的样本集合求交方案,方便资源按需调度和水平扩展,最大能够支持百亿规模样本数据求交。
轻型的样本求交客户端方案,适用于服务端搭建好后,快速测试Flink on K8S集群公网连通情况,以及数据量小的客户端在不配置Flink环境的情况下快速部署与服务端进行样本集合求交任务。
采用简化协议、全C++通信实现的联邦联合训练框架,尽可能的提升训练性能。并实现了更精细的数据状态恢复与模型加载校验机制,能够保证任务恢复的模型一致性与数据的零损失。
针对纵向联邦场景,业内首次开源了基于水平聚合的联邦学习方法和基于层次聚合的联邦学习方法两种算法模型,通过设计更高效的特征融合方法,充分发挥联邦框架的算法能力。
▐ 技术详解

整个系统架构从业务处理流程角度分为三个模块: Data Store(样本生成与存储)、EFLS-Data(样本集合求交)和EFLS-Train(联邦联合训练)。三个模块基于云上基础设施(OSS等)进行数据读取与存储,采用开源框架(Flink)实现分布式处理,整体运行在Kubernetes上。为方便用户使用,采用WebConsole对接K8S服务接口,实现用户管理,数据、模型和作业的可视化管控。
样本集合求交
样本生成后,需要将样本根据标签求交对齐后,才能用于模型训练。
常规的流程分为样本分桶、对应桶样本求交和结果检验三步:
当求交任务到达时,常驻的Master会按需调度资源。在样本分桶流程中,Master调出n个worker,并行读入样本,将每个样本根据其哈希值分入到m个桶中。
整个样本集合求交任务被分治为了相应桶之间的样本集合求交任务。Master再次调度出m个worker,客户端第i个桶的worker与服务端第i个桶的worker进行连接并采取gRPC远程通信求交。
求交完成后,客户端与服务端分别计算各自求交结果的checksum值,并通过gRPC通信传输进行比较。

另外在一些业务场景中,可能需要使用诸如用户昵称等敏感字段作为关联键进行样本集合求交,为避免此类隐私字段泄漏给联邦合作方,EFLS支持了经典的 Blind RSA-based PSI 协议[3],即在gRPC数据传输前通过RSA加密等秘钥方法,使得集合求交过程中联邦双方不能获悉对方的原始信息。
联邦模型训练

对于一个传统的深度学习模型来说,训练方持有全部的训练所需要的特征和模型,可独自完成前后向计算、更新梯度完成一次训练迭代。而在纵向联邦学习的场景下,训练所需要的数据特征和模型分别由两个联邦计算方持有,不对对方泄露。在训练过程中协同方会将一个训练的中间结果经过隐私加密之后发送给主导方,主导方在计算反向的梯度之后,除了更新本方的参数,还需将协同方发送来的中间结果对应的梯度经过加密后发送给协同方,协同方使用该梯度进行自身的参数更新。
EFLS-Train 基于社区 Tensorflow1.15 版本开发,通过扩展的方式实现了一套完整的联邦学习训练方案。整个训练框架主要包括数据协同(联邦Dataset),安全通信层(gRPC),隐私加密(保护前后向交互数据)和高层训练API几个部分。在保证数据安全的基础上,我们还着重考虑了联邦训练的性能和稳定性,在数据交互协议、通信层和分布式容灾等方面进行了多项优化,保证联邦训练任务能够高效稳定的运行。
EFLS-Train 各核心模块的主要功能如下:
数据协同:提供一套标准的联邦Dataset接口,封装主从双方的数据读取及协同逻辑,保证双方训练样本的一致性。通过记录样本读取进度,在发生错误的情况下,训练任务能够以最小的代价恢复到最近的状态。
安全通信层:负责两个联邦计算方之间的通信,核心部分采用C++实现,通过gRPC的SSL接口保证了通信安全。
隐私加密模块:同时支持对前向数据和后向梯度进行加密保护,其中差分隐私加密方案允许用户自定义加密程度,可以灵活的在安全和性能两个方面进行取舍
联邦训练API:提供了类似Keras的高层API封装,尽可能对用户屏蔽了联邦训练和普通训练的实现差异,让用户更容易上手使用。
CTR = efl.FederalModel()
CTR.input_fn(input_fn)
CTR.loss_fn(model_fn)
CTR.optimizer_fn(efl.optimizer_fn.optimizer_setter(tf.train.GradientDescentOptimizer(0.001)))
CTR.compile()
CTR.fit(efl.procedure_fn.train(), log_step=1, project_name="train")联邦算法创新
在外投广告场景中,融合电商侧和媒体侧各自的特征优势,将媒体侧学习到的用户兴趣引入到电商侧模型中,可以充分发挥双方特征优势来提升电商侧模型预估效果。双方的用户原始数据出于保护用户隐私的目的不能互传。因此,在互不透出自身原始数据的情况下,我们希望利用媒体侧学习到的特征表示来媒体侧包含用户丰富的媒体侧特征,包括媒体兴趣标签、转发/点赞等社交行为,电商侧包括用户购买兴趣、电商行为等。如果能够提升电商侧模型预估能力,联邦学习为这一诉求提供了解决方案,媒体侧发送其模型学习到的能够反映用户在媒体侧偏好的低维特征向量(而非原始特征)到电商侧,电商侧融合该特征向量后给出预估结果,并将梯度发送给媒体侧来更新特征表示。在这个过程中,每一方仅拥有自身的用户原始数据和模型参数,而不能获取对方的信息。
我们将电商特征和媒体特征融合问题定义为 Cross Domain 预估问题。一种直接的方法是将媒体侧发送过来的特征向量拼接到电商侧特征向量的方式进行整合,该方法显然难以充分挖掘双方特征的潜力。EFLS针对纵向联邦场景,业内首次开源了两种算法模型,通过设计更高效的特征融合方法,充分发挥联邦框架的算法能力。
基于水平聚合的联邦学习方法: 传统的纵向联邦通常将媒体侧和广告主侧特征简单进行拼接,该方法难以充分挖掘双方特征潜力。我们提出基于注意力机制的方法,将媒体侧发送过来的特征向量与电商侧模型的特征 进行融合。注意力机制,是一种能让模型对重要信息重点关注并充分学习吸收的方法。我们将电商侧用户、广告、场景 Embedding ,与媒体侧发送过来的特征向量通过多层感知机方式计算注意力权重,然后加权求和计算得到基于注意力的融合特征向量。通过上述水平融合方式,我们能够直接令模型从 low-level 部分就开始吸收媒体特征,进而充分融合来给出预估结果。
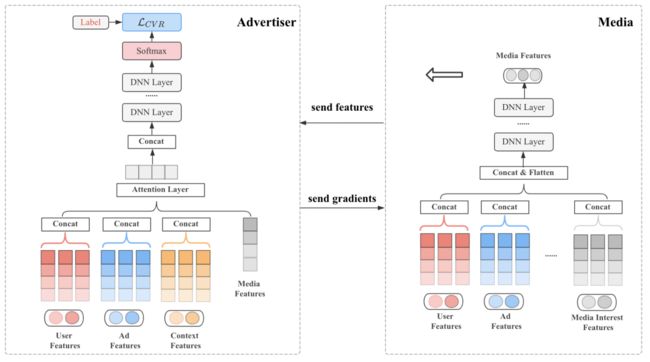
基于层次聚合的联邦学习方法:为进一步吸收媒体侧模型的表征,我们提出基于层次表示自动聚合的联邦学习(AutoHERI)[7]方法。将媒体侧特征向量层次化地聚合连接到电商侧预估模型的中间层,以提升模型的特征学习能力。由于聚合连接的组合方式随着网络层数增长而指数级增加,我们通过神经网络架构搜索技术,自动搜索最优的连接组合,使电商侧模型学习到有效的特征聚合模式,整合不同域空间信息。通过高维空间融合方式,我们能够从模型 high-level 部分自动学习特征聚合,进而通过利用更丰富的媒体侧特征向量来给出更好的预估结果。

产品控制台
联邦学习过程中有多方参与,流程相对复杂,因此对隐私和权限管控要求较高,需要参与方频繁协调。因此为了降低用户使用成本,我们设计了一套联邦学过程的抽象,在此基础上开发了Web产品控制台,支持使用者可视化地进行用户、任务、数据和权限的管控,提升联邦学习样本模型实验的迭代效率,缩短开发周期。
▐ 未来规划
接下来 EFLS 计划在系统功能方面支持可扩展性更强的多方联邦能力、自动弹性伸缩能力以及面向高效隐私加密的性能优化,同时在算法方面将考虑通过多方联邦、联邦图学习等算法创新挖掘多场景异质数据源中蕴含的知识,并尝试图学习与加密算法高效融合的方法,确保在数据安全用户隐私保护前提下,建立适用于搜推广的召回、精排等模块的预训练模型,探索研究针对样本不足情况下,进一步加强预训练阶段对于外投广告投放场景的感知能力。
「 更多干货,更多收获 」

推荐系统工程师技能树
【免费下载】2021年9月份热门报告盘点
美团大脑系列之:商品知识图谱的构建及应用
【干货】2021社群运营策划方案.pptx大数据驱动的因果建模在滴滴的应用实践
联邦学习在腾讯微视广告投放中的实践如何搭建一个好的指标体系?如何打造标准化的数据治理评估体系?【干货】小米用户画像实践.pdf(附下载链接)
推荐系统解构.pdf(附下载链接)
短视频爆粉表现指南手册.pdf(附下载链接)
推荐系统架构与算法流程详解如何搭建一套个性化推荐系统?某视频APP推荐策略详细拆解(万字长文)2021年轻人性生活报告
关注我们
智能推荐 个性化推荐技术与产品社区 |
长按并识别关注
|

您的「在看」,我的动力