Python+scrcpy+pyminitouch实现自动化(四)——实现语音识别自动打卡机器人
首先要去网上下载一个想要实现自动化的软件,下载对应的apk后拖拉到虚拟器的页面即可实现自动下载。
以上是对于AS打开的模拟器进行的下载安装,由于我找不到关于x86的企业微信,所以我就换了逍遥模拟器,对于AS的模拟器只能是基于Google Play或者是Google APIS的。具体可参考这篇博客:android studio中AVD模拟器添加APK文件的方法_xuzhimolol的博客-CSDN博客_android studio 虚拟机安装apk。
-
下载逍遥模拟器:【逍遥安卓模拟器】安卓模拟器电脑版_安卓模拟器哪个好用_逍遥安卓模拟器下载官网
-
安装想要安装的软件

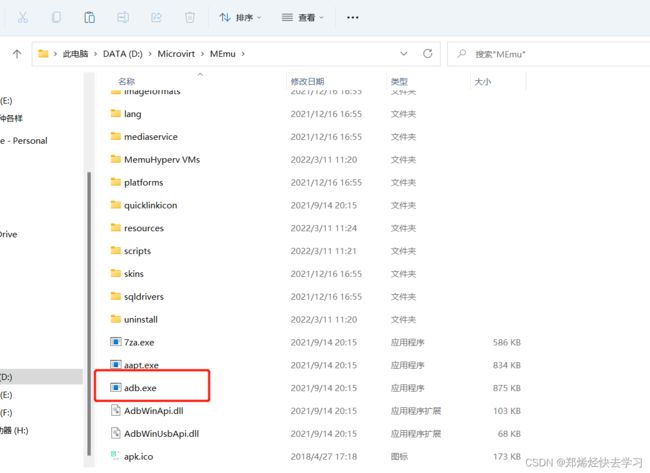
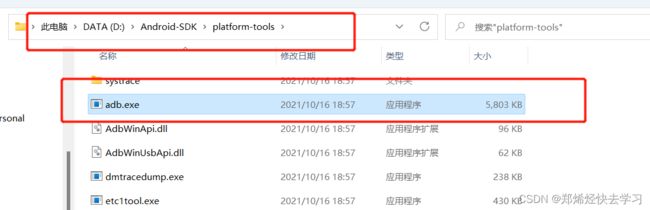
- 打开上一次下载的platform-tools,将adb.exe进行复制到逍遥的安装目录中,覆盖掉原本的adb.exe:
- 之后打开cmd执行
adb connect 127.0.0.1:21503
- 查看是否与adb链接成功
adb devices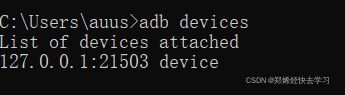
- 可以按照以前调试真机的方式调试了
可以使用pyminitouch得到设备的x与y,也可以通过appium进行得知要点击的位置。为了方便我就使用的Appium。
要得到以下的密钥:具体如何获得可以参考以前的博客:Python + Appium 自动化测试(二):实战_Alkaid2000的博客-CSDN博客

最后我得到的:
{
"platformName": "Android",
"platformVersion": "7.1.2",
"deviceName": "TAS-AN00",
"appPackage": " com.tencent.wework",
"appActivity": ".launch.WwMainActivity",
"noReset": "True"
}- 打开appium
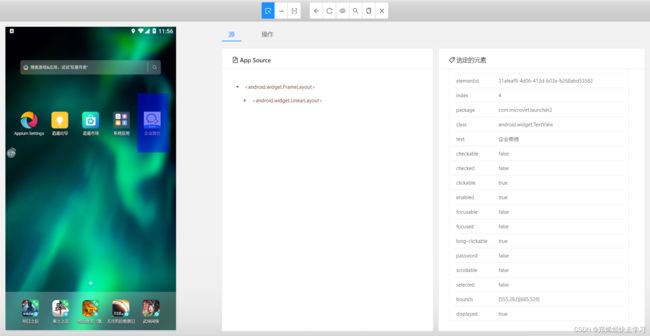
- 了解手机坐标
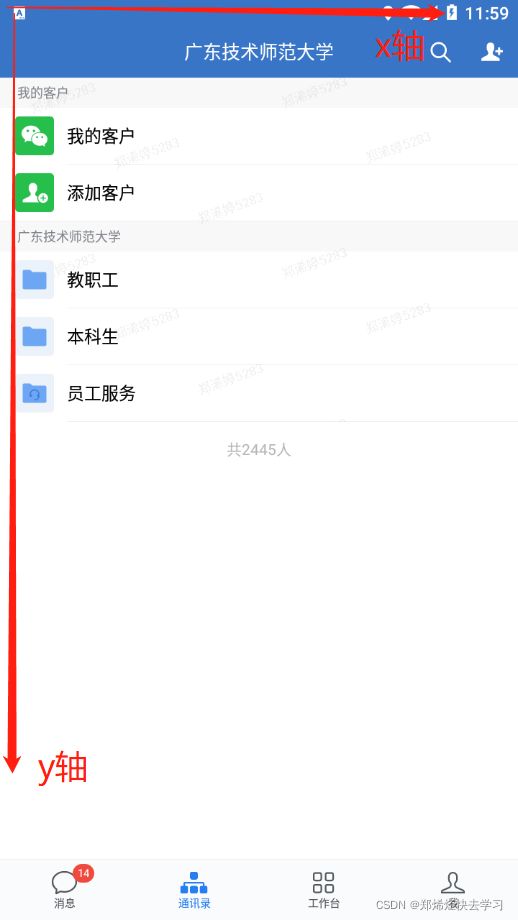
相当于是数学象限的第四象限,x为横轴,y为纵轴。为什么要以这样的坐标设计,其实也挺好理解的,从用户角度看,我们滑动都是向下翻阅(向上滑动),或者是向右翻阅(向左滑动)。那既然是向下和向右,那么自然原点设置在左上角了。
那回头看appium中的bounds元素:
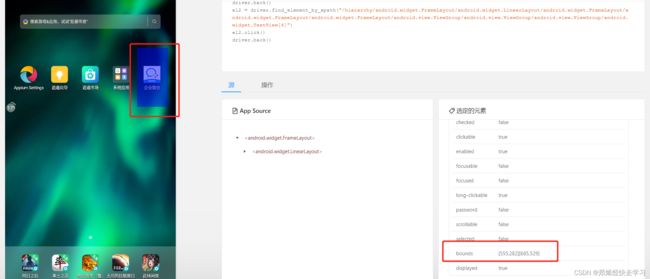
我们可以从中得到我们所要点击的坐标为555~685,而y轴是685~529。从而可以给我们pyminitouch提供点击坐标。
-
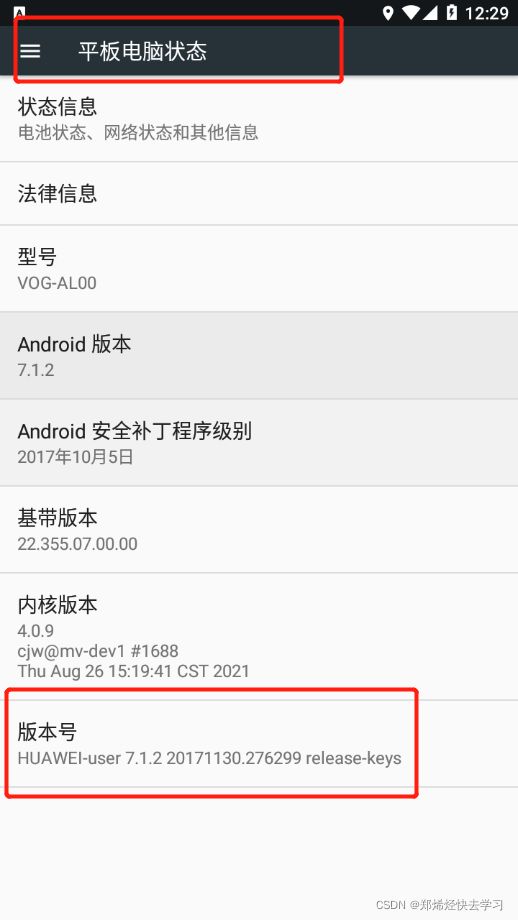
启动开发者模式!!
使用模拟器也是需要打开开发者模式的,打开设置,点击关于平板电脑,连续单击版本号,开启开发者模式。
- 编程
写了一个测试案例,但是也是出现了一个服务器被占用的错误:
from pyminitouch import safe_connection, safe_device, MNTDevice, CommandBuilder
_DEVICE_ID = '127.0.0.1:21503'
device = MNTDevice(_DEVICE_ID)
# print the maximum x and Y coordinates
print("max x:", device.connection.max_x)
print("max y:", device.connection.max_y)
# single-tap
device.tap([(620, 570)])Note: hard-limiting maximum number of contacts to 10
binding socket: Address already in use
Unable to start server on minitouch
解决问题:
在cmd中输入:
netstat -ano找到我们端口所在运行的程序:
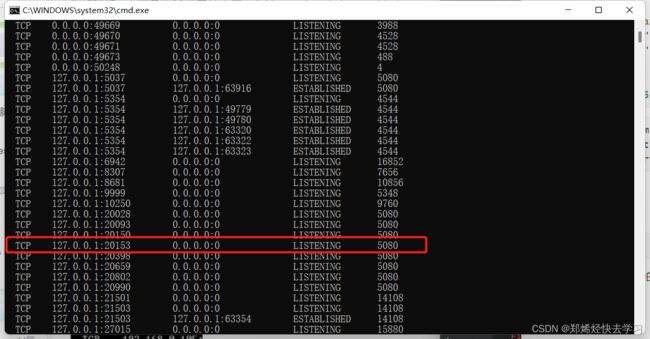
输入命令:
tasklist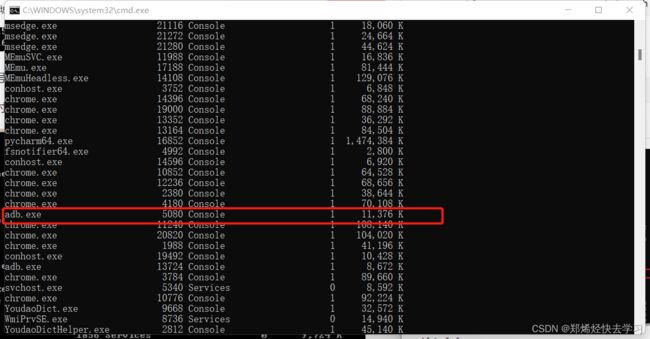
找到对应占用的程序,直接使用任务管理器结束掉这个程序。
或者使用adb shell进行点击也是可行的:
adb shell input x yfrom pyminitouch import safe_connection, safe_device, MNTDevice, CommandBuilder
import time
_DEVICE_ID = '127.0.0.1:21503'
device = MNTDevice(_DEVICE_ID)
# print the maximum x and Y coordinates
print("max x:", device.connection.max_x)
print("max y:", device.connection.max_y)
# single-tap
device.tap([(640, 300)])
time.sleep(10)
device.tap([(480, 1250)])
time.sleep(3)
device.tap([(150, 300)])
time.sleep(5)
device.stop()再融入百度的语音识别sdk:
import time
import speech_recognition as sr
import os
import pyttsx3
from aip import AipSpeech
from appium import webdriver
from pyminitouch import MNTDevice
_DEVICE_ID = '127.0.0.1:21503'
APP_ID = '25751234'
API_KEY = 'Ia1pGYSvwe3iWfOr012345'
SECRET_KEY = 'fUSMXOcnZZGtlv99ONIn7MAE12345'
device = MNTDevice(_DEVICE_ID)
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
# 用于录音speech_recognition
def grow_audio(rate=16000):
# 用于读取麦克风
r = sr.Recognizer()
with sr.Microphone(sample_rate=rate) as source:
print("他在等你讲话...")
# 动态调整能量阈值以解决环境噪音
r.adjust_for_ambient_noise(source)
# 限制录音时长位30s
audio = r.listen(source, phrase_time_limit=30)
print('okk!')
# 将音频写入
with open('voice.wav', 'wb') as f:
f.write(audio.get_wav_data())
# 读取文件
def get_file_content(filePath):
cmd_str = "ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm" % (filePath, filePath)
os.system(cmd_str) # 调用系统命令ffmpeg,传入音频文件名
with open(filePath + ".pcm", 'rb')as fp:
return fp.read()
# 识别文件 使用百度API
def pcm2text():
pcm_audio = get_file_content('voice.wav')
text = client.asr(pcm_audio, 'pcm', 16000, {'dev_pid': 1537, })
print(text['result'])
return text['result']
def say_hi():
engine.say('嘿,你来找我玩啦!')
# 本句话是没有声音的,如果要调用say()函数,每次调用都要加上这句
engine.runAndWait()
def headlth_update_2():
engine.say('正在健康上报')
engine.runAndWait()
# single-tap
device.tap([(640, 300)])
time.sleep(10)
device.tap([(480, 1250)])
time.sleep(3)
device.tap([(150, 300)])
time.sleep(5)
device.stop()
engine.say('健康上报完成')
if __name__ == "__main__":
# 初始化
engine = pyttsx3.init()
say_hi()
while True:
grow_audio()
output = pcm2text()
if '企业微信进行健康上报' or '打开' or '微信' or '健康上报' in output:
engine.say('好的')
engine.runAndWait()
headlth_update_2()