共享内存 设计原理-shm
-
POSIX的
shm_open()在/dev/shm/下打开一个文件,用mmap()映射到进程自己的内存地址 -
System V的
shmget()得到一个共享内存对象的id,用shmat()映射到进程自己的内存地址
目前这里主要看 System V的设计
这里先说一说设计思路!!
进程A和进程B 由于地址空间是隔离的!!那么进程A怎样和进程B 能够相互访问同一个资源呢??
此时就要考虑到进程的控制块PCB其访问的“”内核空间“”是相同的,也就是说如果内核空间申请一款资源 其地址可以被进程A 进程B的PCB 同时访问,然后进程A/B 通过用户空间映射到内核空间;这样就完成了进程间的访问!!
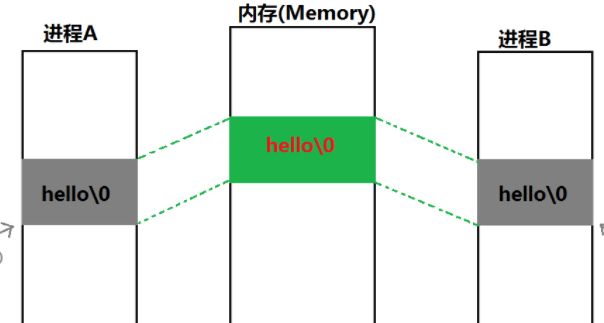
现在问题来了?? 假如进程A申请了一款内存,那进程B 怎样知道呢??进程B怎样知道进程A申请的内存的地址呢?
我们知道linux 的设计哲学是一切皆文件,文件的inode 的是唯一的;所以进程A申请一块内存时关联到文件SYS_XXX,然后进程B通过文件SYS_XXX 来访问这块内存!!!
所以共享内存第一步就是获取一个key 唯一的!!!
通过的方法就是open一个文件得到文件唯一的inode或者通过某种算法生成一个唯一的key值!!
来看下shmxxx 函数是怎样处理的!!
#include#include int shmget(key_t key, size_t size, int shmflg); sys_shmget(key_t key, size_t size, int flag);
- 参数key: 是一个键值,用来标识一段全局唯一的共享内存。多个进程通过它来访问同一个共享内存,其中有个特殊值IPC_PRIVATE,用于创建当前进程的私有共享内存
- 参数size :用来指定共享内存的大小,单位是字节。若创建的是新的共享内存,则size值必须被指定;若是获取已经存在的共享内存,则可以将size参数设置为0.
- 参数shmflgshmflg:权限位标志,和open函数的权限位标志类似,通常使用八进制来表示,同时可以与IPC_CREAT做或操作;
- 返回值:shmget函数成功的时候,返回一个int正整数值,它是共享内存的标识符。失败时返回:-1并且设置errno;
void *shmat(int shmid, const void *shmaddr, int shmflg);
参数shmid:是由shmget函数调用之后返回的共享内存标识符;
参数shm_addr:指定将共享内存关联到进程的哪块地址空间,但是最终的效果还会收到shmflg参数的SHM_RND的影响;
(1) 若shm_addr为NULL,则被关联的地址由操作系统(内核)选择。这也是推荐使用的做法,以确保代码的可移植性。该参数选项类似于mmap函数(内存映射文件方法);
(2) 若shm_addr非空,并且SHM_RND标志未被设置,则共享内存被关联到addr指定的地址处。
参数 shmflg:除了SHM_RND标志外,shmflg参数还支持如下的标志:
· SHM_RDONLY:表示进程仅能够读取共享内存中的内容。(类似于open中的flag权限设置);若没有指定该标志,表示进程能够对共享内存进行读写的操作(需要在创建共享内存的时候指定其读写的权限);
· SHM_REMAP:若地址shmaddr已经被关联到了一段共享内存上,则重新关联;
· SHM_EXEC: 它指定对共享内存段的执行权限,对共享内存而言,所谓的执行权限实际上和读权限是一样的;
shmat函数成功的时候,返回共享内存被关联到的地址;失败则返回:(void *)-1并且设置errno。shmat成功时,将会修改内核数据结构shmid_ds的部分字段,如下:
· 将shm_nattach加1
· 将shm_lpid设置为调用进程的PID
· 将shm_atime设置为当前的时间
int shmdt(const void *shmaddr);
参数shmaddr: 为shmat函数的返回值,即共享内存被关联到的地址;
shmdt函数成功时:返回0,失败返回-1;shmdt函数在被成功的调用的时候也同样会去修改内核的数据结构shmid_ds的部分字段,如下:
· 将shm_nattach减1
· 将shm_lpid设置为调用进程的PID
· 将shm_dtime设置为当前的时间
基本结构体:
/* Obsolete, used only for backwards compatibility and libc5 compiles */
struct shmid_ds {
struct ipc_perm shm_perm; /* operation perms 共享内存的操作权限*/
int shm_segsz; /* size of segment (bytes) 共享内存的大小、单位是字节*/
__kernel_time_t shm_atime; /* last attach time 对这段内存最后一次调用shmat的时间*/
__kernel_time_t shm_dtime; /* last detach time 对这段内存最后一次调用shmdt的时间*/
__kernel_time_t shm_ctime; /* last change time 对这段内存最后一次调用shmctl的时间*/
__kernel_ipc_pid_t shm_cpid; /* pid of creator 创建者的pid*/
__kernel_ipc_pid_t shm_lpid; /* pid of last operator 最后一次执行shmat或shmdt操作的进程的PID*/
unsigned short shm_nattch; /* no. of current attaches目前关联到此共享内存的进程的数量 */
unsigned short shm_unused; /* compatibility */
void *shm_unused2; /* ditto - used by DIPC */
void *shm_unused3; /* unused */
};
shmget系统调用:
SYSCALL_DEFINE3(shmget, key_t, key, size_t, size, int, shmflg)
{
struct ipc_namespace *ns;
static const struct ipc_ops shm_ops = {
.getnew = newseg,
.associate = shm_security,
.more_checks = shm_more_checks,
};
struct ipc_params shm_params;
ns = current->nsproxy->ipc_ns;
shm_params.key = key;
shm_params.flg = shmflg;
shm_params.u.size = size;
return ipcget(ns, &shm_ids(ns), &shm_ops, &shm_params);
}
![]()
命令空间:共享内存这些进程间通信的数据结构是全局的,但有时候需要把他们隔离开,即某一组进程并不知道另外的进程的共享内存,它们只希望在组内共用这些东西,这样就不会与其他进程冲突。于是就煞费苦心在内核中加了一个namespace;目前有很多命令空间比如:网络命名空间 命名空间最直观的体现就是docker;就是一种资源隔离!!!
ns = current->nsproxy->ipc_ns;
#define sem_ids(ns) ((ns)->ids[IPC_SEM_IDS])
#define msg_ids(ns) ((ns)->ids[IPC_MSG_IDS])
#define shm_ids(ns) ((ns)->ids[IPC_SHM_IDS])
/* “核心”,每个数组元素对应一种 IPC 机制:信号量、消息队列、共享内存 */
/*
from ipc/util.h
#define IPC_SEM_IDS 0 信号量
#define IPC_MSG_IDS 1 消息队列
#define IPC_SHM_IDS 2 共享内存
*/
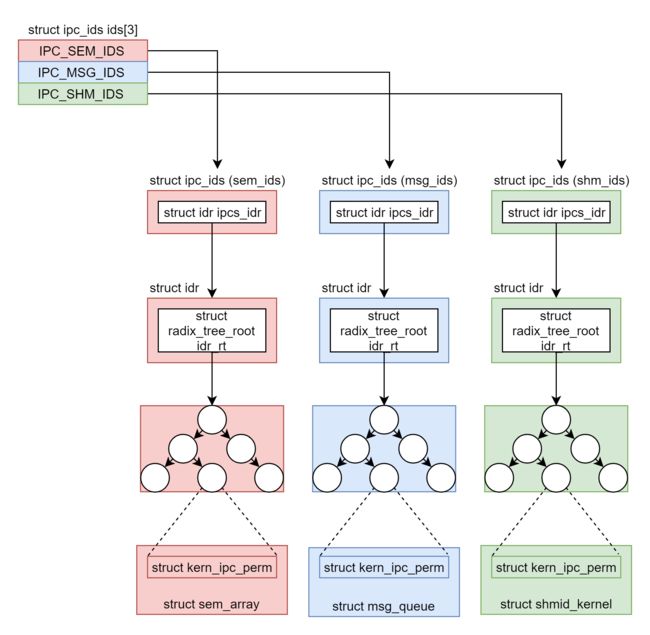
struct ipc_namespace {
atomic_t count; /* 被引用的次数 */
struct ipc_ids ids[3];//--->对应 信号量 消息队列 共享内存
/* 以下都是对三种 IPC 机制设置的限制,诸如共享内存页的最大数量等 */
int sem_ctls[4];
----------------------------------
unsigned int msg_ctlmax;
-------------------------------
size_t shm_ctlmax;
------------------------------
};
[0] struct kern_ipc_perm <==> struct shmid_kernel
struct ipc_namespace => struct ipc_ids => struct idr => [1] struct kern_ipc_perm <==> struct shmid_kernel
[2] struct kern_ipc_perm <==> struct shmid_kernel
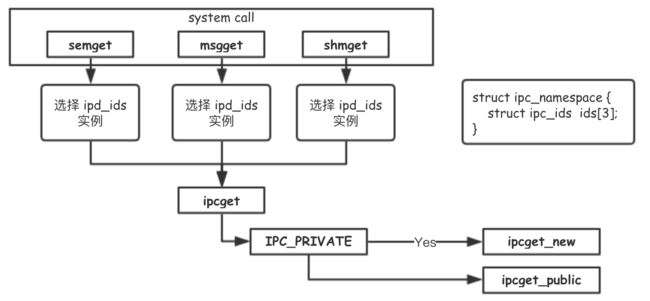
继续看shmget:
int ipcget(struct ipc_namespace *ns, struct ipc_ids *ids,
const struct ipc_ops *ops, struct ipc_params *params)
{
if (params->key == IPC_PRIVATE)
return ipcget_new(ns, ids, ops, params);
else
return ipcget_public(ns, ids, ops, params);
}
如果传进来的参数是IPC_PRIVATE(这个宏的值是0)的话,无论是什么mode,都会创建一块新的共享内存。如果非0,则会去已有的共享内存中找有没有这个key的,有就返回,没有就新建。
新建的函数newseg()
**
* newseg - Create a new shared memory segment
* @ns: namespace
* @params: ptr to the structure that contains key, size and shmflg
*
* Called with shm_ids.rwsem held as a writer.
*/
static int newseg(struct ipc_namespace *ns, struct ipc_params *params)
{
key_t key = params->key;
int shmflg = params->flg;
size_t size = params->u.size;
int error;
struct shmid_kernel *shp;// 描述共享内存的结构体 内核使用
size_t numpages = (size + PAGE_SIZE - 1) >> PAGE_SHIFT;
struct file *file;
char name[13];
int id;
vm_flags_t acctflag = 0;
-------------------------------------
shp = ipc_rcu_alloc(sizeof(*shp));//1. 在内核空间-直接映射区分配 struct shmid_kernel
if (!shp)
return -ENOMEM;
// shmid_kernel 结构保存有 key 和权限等信息
shp->shm_perm.key = key;
shp->shm_perm.mode = (shmflg & S_IRWXUGO);
shp->mlock_user = NULL;
shp->shm_perm.security = NULL;
-------------------------------------
// 2. 在 shmem 文件系统创建一个文件
// shmem 文件系统即 struct file_system_type shmem_fs_type
sprintf(name, "SYSV%08x", key);
if (shmflg & SHM_HUGETLB) {
------------------------------------------
file = hugetlb_file_setup(name, hugesize, acctflag,
&shp->mlock_user, HUGETLB_SHMFS_INODE,
(shmflg >> SHM_HUGE_SHIFT) & SHM_HUGE_MASK);
} else {
/*__shmem_file_setup() 会创建新的 shmem 文件对应的 dentry 和 inode,
并将它们两个关联起来,然后分配一个 struct file 结构来表示新的 shmem 文件,
并且指向独特的 shmem_file_operations。*/
-----------------------------------
file = shmem_kernel_file_setup(name, size, acctflag);
}
error = PTR_ERR(file);
if (IS_ERR(file))
goto no_file;
shp->shm_cprid = task_tgid_vnr(current);
shp->shm_lprid = 0;
shp->shm_atim = shp->shm_dtim = 0;
shp->shm_ctim = get_seconds();
shp->shm_segsz = size;
shp->shm_nattch = 0;
shp->shm_file = file;
shp->shm_creator = current;
// 3. 此处将 kvmalloc 分配的 shmid_kernel 挂到 ipc_ids 的基数树上,且生成对应id
//shm_perm *new->id = ipc_buildid(id, new->seq);
//对于idx 基数树的实现 可以详细看代码
id = ipc_addid(&shm_ids(ns), &shp->shm_perm, ns->shm_ctlmni);
if (id < 0) { //次id是指idx 基数树的节点id
error = id;
goto no_id;
}
//将 shmid_kernel 挂到当前进程的 sysvshm队列上
list_add(&shp->shm_clist, ¤t->sysvshm.shm_clist);
/*
* shmid gets reported as "inode#" in /proc/pid/maps.
* proc-ps tools use this. Changing this will break them.
*/
file_inode(file)->i_ino = shp->shm_perm.id;
ns->shm_tot += numpages;
error = shp->shm_perm.id;
ipc_unlock_object(&shp->shm_perm);
rcu_read_unlock();
return error;
-----------------------------
}
主要逻辑:
- 参数及共享内存系统限制检查
- 分配共享内存管理结构shmid_kernel
- 在tmpfs中创建共享内存文件,以获取物理内存
- 将shmid_kernel添加到共享内存基数树中,并获得基数树id根据此id 使用pc_buildid(id, new->seq); 生成ipc id
- 初始化shmid_kernel结构
- 返回共享内存IPC id
如果创建时传入一个已有的key,也就是进程B根据key查找对应的内存的方向看待问题,即ipcget_public()的逻辑
先去找有没有这个key。没有的话还是创建一个新的,如果找到了就判断一下权限有没有问题,没有问题就直接返回IPC id
ipcget_public(struct ipc_namespace *ns, struct ipc_ids *ids,
const struct ipc_ops *ops, struct ipc_params *params)
{struct kern_ipc_perm *ipcp;
int flg = params->flg;
int err;
down_write(&ids->rwsem);
ipcp = ipc_findkey(ids, params->key);
if (ipcp == NULL) {
err = ops->getnew(ns, params);
} else {
}
up_write(&ids->rwsem);
return err;
}
static struct kern_ipc_perm *ipc_findkey(struct ipc_ids *ids, key_t key)
{
struct kern_ipc_perm *ipc;
int next_id;
int total;
for (total = 0, next_id = 0; total < ids->in_use; next_id++) {
ipc = idr_find(&ids->ipcs_idr, next_id);
-------------------------------
if (ipc->key != key) {
total++;
continue;
}
----------------------
return ipc;
}
return NULL;
}
PS:
基数树(radix tree)是将long整数与指针键值相关联的机制,它存储有效率,并且可快速查询,用于整数值与指针的映射,对于长整型数据的映射,如何解决Hash冲突和Hash表大小的设计是一个很头疼的问题,利用radix树可以根据一个长整型(比如一个长ID)快速查找到其对应的对象指针。这比用hash映射来的简单,也更节省空间,使用hash映射hash函数难以设计,不恰当的hash函数可能增大冲突,或浪费空间。
基数树和字典树的实现机制很像,都是将key拆分成一部分映射到树形结构中,基数树是将key按指针地址bit位拆分,而字典树是将key的字符串值按字符拆分。但是基数树的层高是相对固定的(因为指针地址的bit位是固定的),而字典树的高度与字符串的长度相关,而树的高度决定了树的空间占用情况,所以基数树明显更节约空间。
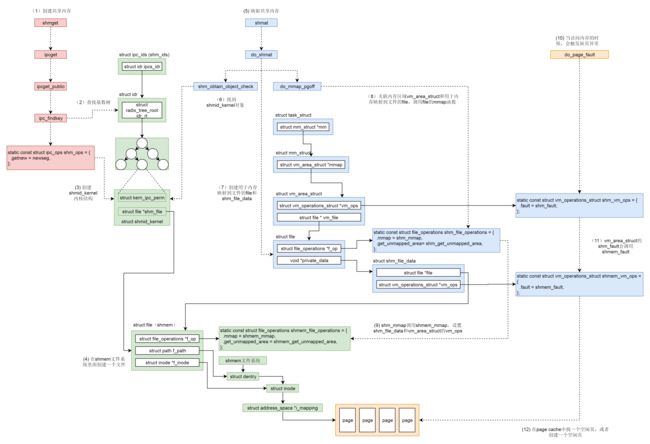
shmat:
SYSCALL_DEFINE3(shmat, int, shmid, char __user *, shmaddr, int, shmflg)
{
unsigned long ret;
long err;
err = do_shmat(shmid, shmaddr, shmflg, &ret, SHMLBA);
if (err)
return err;
force_successful_syscall_return();
return (long)ret;
}
/*
* Fix shmaddr, allocate descriptor, map shm, add attach descriptor to lists.
*
* NOTE! Despite the name, this is NOT a direct system call entrypoint. The
* "raddr" thing points to kernel space, and there has to be a wrapper around
* this.
*/
long do_shmat(int shmid, char __user *shmaddr, int shmflg, ulong *raddr,
unsigned long shmlba)
{
struct shmid_kernel *shp;
unsigned long addr;
unsigned long size;
struct file *file;
int err;
unsigned long flags;
unsigned long prot;
int acc_mode;
struct ipc_namespace *ns;
struct shm_file_data *sfd;
struct path path;
fmode_t f_mode;
unsigned long populate = 0;
-------------------
/*
* We cannot rely on the fs check since SYSV IPC does have an
* additional creator id...
*/
ns = current->nsproxy->ipc_ns;
rcu_read_lock();
// 1. 依据 shmid 获取 ipc_ids 基数树上对应的 shm 数据结构 shmid_kernel
shp = shm_obtain_object_check(ns, shmid);
if (IS_ERR(shp)) {
err = PTR_ERR(shp);
goto out_unlock;
}
err = -EACCES;
if (ipcperms(ns, &shp->shm_perm, acc_mode))
goto out_unlock;
err = security_shm_shmat(shp, shmaddr, shmflg);
if (err)
goto out_unlock;
ipc_lock_object(&shp->shm_perm);
/* check if shm_destroy() is tearing down shp */
if (!ipc_valid_object(&shp->shm_perm)) {
ipc_unlock_object(&shp->shm_perm);
err = -EIDRM;
goto out_unlock;
}
path = shp->shm_file->f_path;
path_get(&path);
shp->shm_nattch++;
size = i_size_read(d_inode(path.dentry));
ipc_unlock_object(&shp->shm_perm);
rcu_read_unlock();
err = -ENOMEM;
// 2. 新建shm_file_data 结构体
sfd = kzalloc(sizeof(*sfd), GFP_KERNEL);
if (!sfd) {
path_put(&path);
goto out_nattch;
}
// 3. 新建当前进程 struct file
file = alloc_file(&path, f_mode,
is_file_hugepages(shp->shm_file) ?
&shm_file_operations_huge :
&shm_file_operations);
----------------------------
//并初始化私有数据shm_file_data
file->private_data = sfd;
file->f_mapping = shp->shm_file->f_mapping;
sfd->id = shp->shm_perm.id;
sfd->ns = get_ipc_ns(ns);
sfd->file = shp->shm_file;
sfd->vm_ops = NULL;
--------------------
if (down_write_killable(¤t->mm->mmap_sem)) {
err = -EINTR;
goto out_fput;
}
-------------------------------------
//将shm文件映射到进程地址空间(do_mmap实现是将tmpfs文件映射到进程地址空间)
// 4. 分配虚拟内存对应的 vm_area_struct,最后调用shm_file_operations.mmap建立 file 与虚拟内存的映射关系
// 5. 当触发缺页中断时最终会调用 shmem 文件系统的 shmem_vm_ops.fault找到空闲物理页面
addr = do_mmap_pgoff(file, addr, size, prot, flags, 0, &populate);
//do_mmap_pgoff->mmap_region->mmap会调用--file->f_op->mmap(file, vma);-->shm文件的shm_mmap函数
*raddr = addr;
err = 0;
if (IS_ERR_VALUE(addr))
err = (long)addr;
invalid:
up_write(¤t->mm->mmap_sem);
if (populate)
mm_populate(addr, populate);
out_fput:
fput(file);
out_nattch:
down_write(&shm_ids(ns).rwsem);
shp = shm_lock(ns, shmid);
shp->shm_nattch--;
//attach计数器shm_nattch减1,由于在shm文件映射时shm_mmap->shm_open会将shm_nattch加1
if (shm_may_destroy(ns, shp))
shm_destroy(ns, shp);
else
shm_unlock(shp);
up_write(&shm_ids(ns).rwsem);
return err;
out_unlock:
rcu_read_unlock();
out:
return err;
}
static const struct file_operations shm_file_operations = {
.mmap = shm_mmap,
.fsync = shm_fsync,
.release = shm_release,
#ifndef CONFIG_MMU
.get_unmapped_area = shm_get_unmapped_area,
#endif
.llseek = noop_llseek,
.fallocate = shm_fallocate,
};
shm_mmap() 中调用了 shm_file_data 中的 file 的 mmap() 函数,这次调用的是 shmem_file_operations 的 mmap,也即 shmem_mmap()
static int shm_mmap(struct file *file, struct vm_area_struct *vma)
{
struct shm_file_data *sfd = shm_file_data(file);
int ret;
/*
* In case of remap_file_pages() emulation, the file can represent
* removed IPC ID: propogate shm_lock() error to caller.
*/
ret =__shm_open(vma);
if (ret)
return ret;
ret = sfd->file->f_op->mmap(sfd->file, vma); //sfd->file 是在newseg 中 创建的 其ops->map为shmem_file_operations
//实际上执行---->ret=shmem_mmap(sfd->file, vma);
if (ret) {
shm_close(vma);
return ret;
}
/*这里vm_area_struct 的 vm_ops 指向 shmem_vm_ops。
shm_file_data 的 vm_ops 指向了 shmem_vm_ops,
而 vm_area_struct 的 vm_ops 改为指向 shm_vm_ops。*/
sfd->vm_ops = vma->vm_ops;
vma->vm_ops = &shm_vm_ops;// file->f_op->mmap(file, vma),最后设置成shmem_mmap
return 0;
}
static int shmem_mmap(struct file *file, struct vm_area_struct *vma)
{
file_accessed(file);
vma->vm_ops = &shmem_vm_ops;
return 0;
}
static const struct vm_operations_struct shm_vm_ops = {
.open = shm_open, /* callback for a new vm-area open */
.close = shm_close, /* callback for when the vm-area is released */
.fault = shm_fault,
};
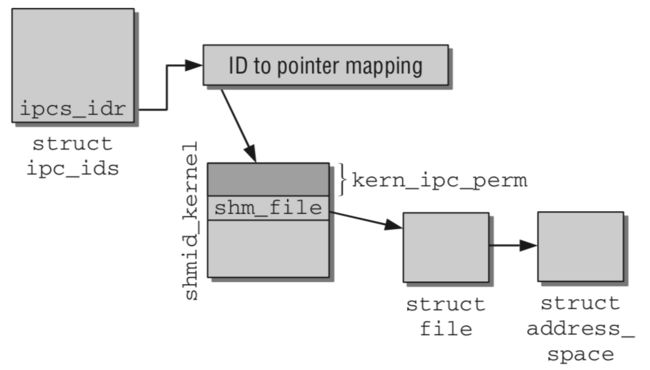
- 调用
shm_obtain_object_check()通过共享内存的id,在基数树中找到对应的struct shmid_kernel结构,通过它找到shmem上的内存文件base。 - 分配结构体
struct shm_file_data sfd表示该内存文件base。 - 创建
base的备份文件file,指向该内存文件base,并将private_data保存为sfd。在源码中注释部分已经叙述了为什么要再创建一个文件而不是直接使用base,简而言之就是base是共享内存文件系统shmem中的shm_file,用于管理内存文件,是一个中立、独立于任何一个进程的文件。新创建的struct file则专门用于做内存映射。 - 调用
do_mmap_pgoff(),分配vm_area_struct指向虚拟地址空间中未分配区域,其vm_file指向文件file,接着调用shm_file_operations中的mmap()函数,即shm_mmap()完成映射。
在前文内存映射中,我们提到了实际物理内存的分配不是在映射关系建立时就分配,而是当实际访问的时候通过缺页异常再进行分配。对于共享内存也是一样。当访问不到的时候,先调用 vm_area_struct 的 vm_ops,也 即 shm_vm_ops 的 fault 函数 shm_fault()。然后它会转而调用 shm_file_data 的 vm_ops,也即 shmem_vm_ops 的 fault 函数 shmem_fault()。shmem_fault() 会调用 shmem_getpage_gfp() 在 page cache 和 swap 中找一个空闲页,如果找不到就通过 shmem_alloc_and_acct_page() 分配一个新的页,他最终会调用内存管理系统的 alloc_page_vma 在物理内存中分配一个页。
static const struct vm_operations_struct shmem_vm_ops = {
.fault = shmem_fault,
.map_pages = filemap_map_pages,
#ifdef CONFIG_NUMA
.set_policy = shmem_set_policy,
.get_policy = shmem_get_policy,
#endif
};
shmdt
当进程不想再访问共享内存时,会将其从地址空间中移除。
找到传入的shmaddr对应的虚拟内存数据结构vma,检查它的地址是不是正确的,然后调用do_munmap()函数断开对共享内存的连接。注意此操作并不会销毁共享内存,即使没有进程连接到它也不会,只有手动调用shmctl(id, IPC_RMID, NULL)才能销毁
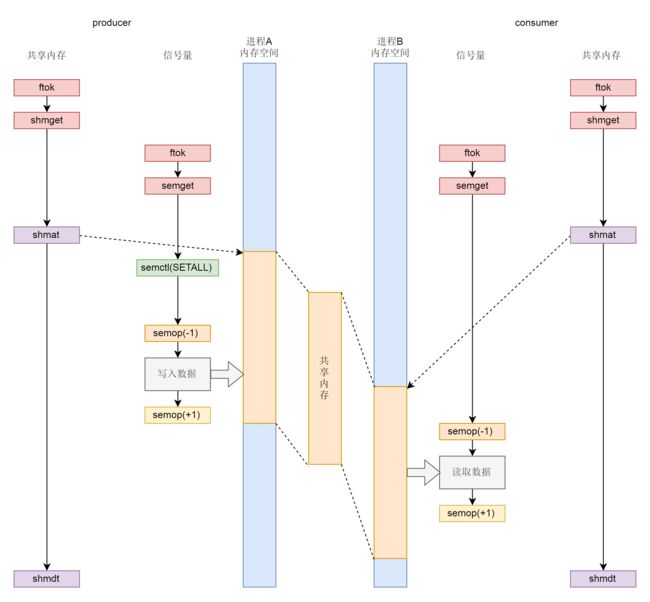
共享内存的使用包括
- 调用
shmget()创建共享内存 - 调用
shmat()映射共享内存至进程虚拟空间 - 调用
shmdt()接触映射关系
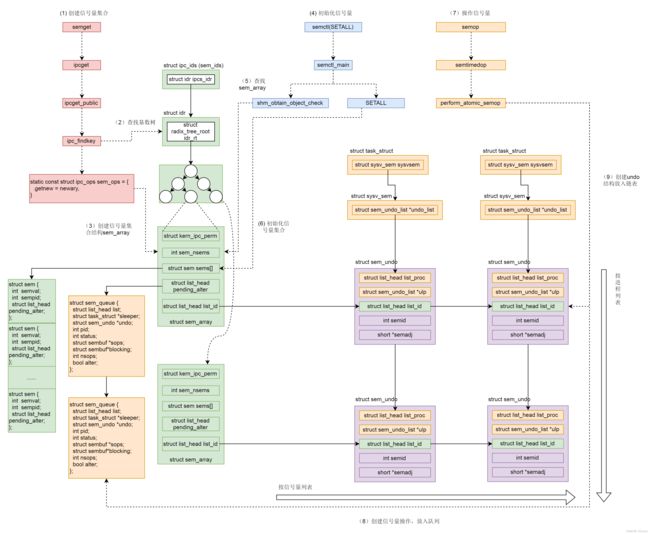
信号量有着类似的操作
- 调用
semget()创建信号量集合。 - 调用
semctl(),信号量往往代表某种资源的数量,如果用信号量做互斥,那往往将信号量设置为 1。 - 调用
semop()修改信号量数目,即加锁和解锁之用
原文
https://blog.csdn.net/Morphad/article/details/9148437
https://segmentfault.com/a/1190000003860236