pytorch实现反向传播
1.总述
1.Python、PyCharm和pytorch
1.Python是一种解释型、面向对象、动态数据类型的高级程序设计语言。虽然Python自带了一个解释器IDLE用来执行.py脚本,但是却不利于我们书写调试大量的代码。常见的是用Notepade++写完脚本,再用idle来执行,但却不便于调试。这时候就出现了PyCharm等IDE,来帮助我们调试开发。
2.PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制。此外,该IDE提供了一些高级功能,以用于支持Django框架下的专业Web开发。
但是Python自身缺少numpy、matplotlib、scipy、scikit-learn…等一系列包,需要我们用pip来导入这些包才能进行相应运算(在cmd终端输入:pip install numpy就能安装numpy包了。)
虽然PyCharm也能自动搜索和下载包,但是总会遇到有些包下载失败或查询不到,很不方便,此时就出现了Anaconda大蟒蛇来解决这个问题。
3.PyTorch 是一个提供两个高级功能的 python 包:
- 具有强 GPU 加速度的张量计算 (如 numpy)
- 深层神经网络建立在基于磁带的自动调整系统上
注: PyTorch 中的 Torch 和 TensorFlow 中的 Tensor 是一个意思.
2.安装所需软件及环境配置
1.安装pycharm,配置python环境。
在pycharm官网选择适合自己的版本下载。对于大部分人来说使用Community版本即可。
由于专业版(Professional)需要激活,并且社区版(Community)已经包含了我们所需要的基本功能,所以这里我们选择社区版(Community)下载。由于在之前课程中经常使用pycharm,在此不对pycharm安装过程进行赘述。
2.安装python
在cmd命令中输入python,如果出现版本号等信息,证明已经安装了python。
 如果没有安装则会自动打开并在在Microsoft Store下载安装,建议选择3.9版本。等待安装结束再重新在cmd运行python,看到版本号等信息证明安装完成。
如果没有安装则会自动打开并在在Microsoft Store下载安装,建议选择3.9版本。等待安装结束再重新在cmd运行python,看到版本号等信息证明安装完成。
2.安装Pytorch
1.进入pytorch官网,点击Install。
2.选择如图所示的配置,复制命令。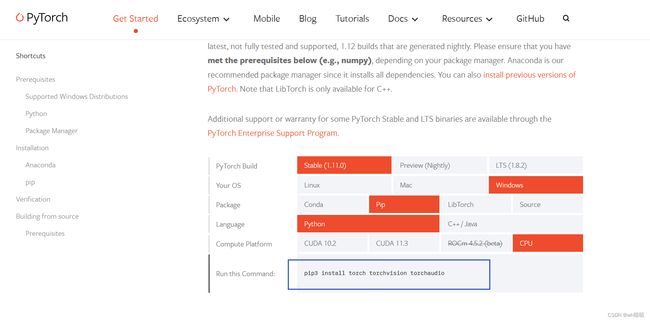
3.打开cmd窗口,将复制的命令粘贴至命令行,将“pip3”中的3删除,按回车运行。
即运行
pip install torch torchvision torchaudio
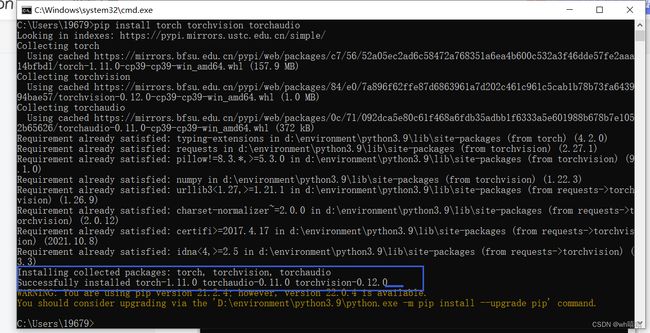
当出现下图的Successfully installed torch-1.11.0 torchaudio-0.11.0 torchvision-0.12.0即证明安装完成。由于我已经安装过一次,为了演示又卸载重装,所以界面和第一次安装不一样,不过只要出现Successfully installed torch-1.11.0 torchaudio-0.11.0 torchvision-0.12.0就可以了。
3.使用Pytorch实现反向传播
代码如下。
import torch
x_data = [1.0, 2.0, 3.0] # 输入值
y_data = [2.0, 4.0, 6.0] # 输出值
w = torch.Tensor([1.0])
w.requires_grad = True
# 权重初始值(设置w的初始值),在grad求导时会将这里设置的初始值带入
# Tensor创建时默认不计算梯度,需要计算梯度设置为ture,自动记录求w的导
# y_predict = x * w
def forward(x):
return x * w
# 损失函数,return激活函数后得到的
def loss(x,y):
y_pred = forward(x)
return (y_pred - y) ** 2
# 训练过程
# 第一步:先算损失Loss
# 第二步:backward,反向传播
# 第三步:梯度下降
for epoch in range(100): #训练100次
for x, y in zip(x_data,y_data) :
l = loss(x,y) # 前向传播,求Loss(损失函数),构建计算图
l.backward() # 反向传播,求出计算图中所有梯度存入w中
print("\tgrad: ",x,y,w.grad.item())
# w.grad.data:获取梯度,用data计算,不会建立计算图,每次获取叠加到grad
w.data = w.data - 0.01 * w.grad.data # 修正一次w,learningrate=0.01(类似步长
w.grad.data.zero_() # 注意:将w中记录的梯度清零,消除本次计算记录,只保留新的w,开启下一次前向传播
print("pregress:", epoch, l.item()) # item取元素精度更高,得到的是loss
得到如下结果:
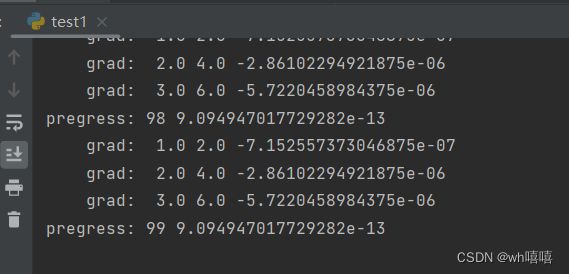
在上面的训练过程中,只要一进行backward,计算图就没有了。在下一次训练的时候,会重新创建一个计算图。因为有可能在构建神经网络的过程中,每次运行的时候,计算图可能是不一样的。所以每进行一次反向传播,就要把该计算图释放,准备下一次的计算图,这是一个非常灵活的过程。
4.总结
1.首先我们的w设置一个初始值,将w设置为需要梯度,然后就构建出整个计算图。
2.构建出计算图之后,我们使用 backward 来反向计算L 对 w的导数,就存放在 w.grad成员里面。这里需要注意的是 grad 也是一个 Tensor,所以为了避免计算导数的时候构建计算图,需要使用 grad 中的成员 data 进行计算。
参考文献:
06 Pytorch实现反向传播
深度学习02-神经网络和反向传播算法-pytorch实现反向传播算法