机器学习入门与Python实战(十):数据降维PCA主成分分析
目录
现实问题思考:金融股价预测
数据降维
为什么需要数据降维
数据降维最常用的方法:主成分分析(PCA)
知识巩固
Python实战:PCA+逻辑回归预测检查者是否患糖尿病
拓展学习
现实问题思考:金融股价预测
想建立一个AI模型,筛选金融股票,潜在数据指标:

价格、交易量、换手率、股东人数、最近N日涨跌幅、RSI指标、威廉指标、市值、营业额、净利润、负债率、利润增长率…多达几百、上千个因子
两大问题:
求解困难、模型过拟合
数据降维
在一定的限定条件下,按照一定的规则,尽可能保留原始数据集重要信息的同时,降低数据集特征的个数。

为什么需要数据降维
Curse of dimensionality - 维数灾难
随着特征数量越来越多,为了避免过拟合,对样本数量的需求会以指数速度增长。
任务:通过一封邮件的上百个特征,预测这封邮件是不是垃圾邮件
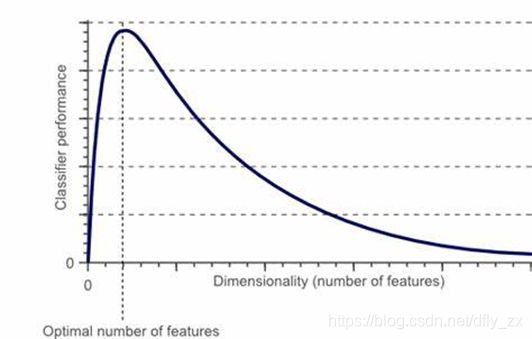
当样本数量确定时,特征数量并不是越多越好。数据降维可以降低我们对样本数量的需求,同时简化学习过程。
数据可视化
高维数据不能可视化,只有降低到二维或三维才能可视化。
任务: 输入是包含14个特征的脑电波数据[1],用来预测被测试者的状态。
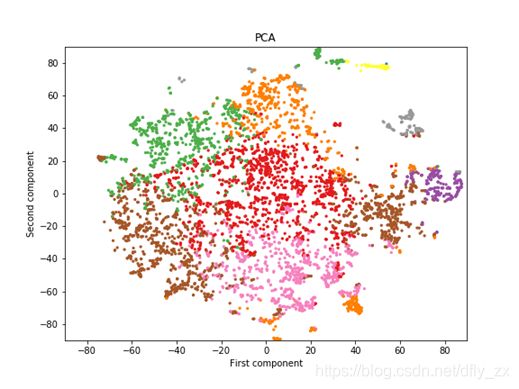
使用PCA将14维数据降成2维,实现了可视化。

3D数据降维到2D数据
数据降维最常用的方法:主成分分析(PCA)
也称主分量分析,按照一定规则把数据变换到一个新的坐标系统中,使得任何数据投影后尽可能可以分开(新数据尽可能不相关、分布方差最大化)。
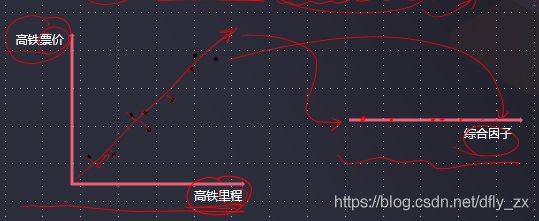
核心:投影后的数据尽可能分得开(即不相关)
如何实现?
使投影后数据的方差最大,因为方差越大数据也越分散
计算过程:
1. 数据预处理(数据分布标准化:=0, =1)
2. 计算协方差矩阵特征向量、及数据在各特征向量投影后的方差
3. 根据需求(任务指定或方差比例)确定降维维度k
4. 选取k维特征向量,计算数据在其形成空间的投影
参考资料:
1、https://blog.csdn.net/dfly_zx/article/details/107908497


3维到2维:
投影到u1、u2形成的平面
n维到k维:
投影到u1、u2…uk形成的空间

知识巩固
问题:我们常认为信息越多越有助于做出正确判断,在机器学习过程中,数据特征信息在很多、很少的情况下分别会导致什么问题,如何解决这些问题?
Python实战:PCA+逻辑回归预测检查者是否患糖尿病
基础环境: Python语言;安装核心工具包numpy、pandas、sklearn、matplotlib;环境管理软件Anaconda;Jupyter notebook
环境配置参考:机器学习入门与Python实战核心工具篇:pip源、python、anaconda、工具包(完整版)https://blog.csdn.net/dfly_zx/article/details/110188923
任务:基于diabetes_data数据,结合PCA降维技术与逻辑回归预测检查者患病情况。

1、对原数据建立逻辑回归模型,计算模型预测准确率;
2、对数据进行标准化处理,选取glucose维度数据可视化处理后的效果;
3、进行与原数据等维度PCA,查看各主成分的方差比例;
4、保留2个主成分,可视化降维后的数据;
5、基于降维后数据建立逻辑回归模型,与原数据表现进行对比,思考结果变化原因
#数据加载
import pandas as pd
import numpy as np
data = pd.read_csv('task2_data.csv')
data.head()
#X y 赋值
X = data.drop(['label'],axis=1)
y = data.loc[:,'label']
X.head()
y.head()
print(X.shape,y.shape)![]()
#逻辑回归模型
from sklearn.linear_model import LogisticRegression
model1 = LogisticRegression(max_iter=1000)
model1.fit(X,y)
#结果预测
y_predict = model1.predict(X)
print(y_predict)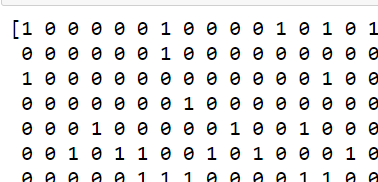
#模型评估
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)![]()
#数据的标准化
from sklearn.preprocessing import StandardScaler
X_norm = StandardScaler().fit_transform(X)
print(X_norm)
#计算均值与标准差
x1_mean = X.loc[:,'glucose'].mean()
x1_norm_mean = X_norm[:,1].mean()
x1_sigma = X.loc[:,'glucose'].std()
x1_norm_sigma = X_norm[:,1].std()
print(x1_mean,x1_sigma,x1_norm_mean,x1_norm_sigma)![]()
from matplotlib import pyplot as plt
fig1 = plt.figure(figsize=(12,5))
fig1_1 = plt.subplot(121)
plt.hist(X.loc[:,'glucose'],bins=100)
fig1_2 = plt.subplot(122)
plt.hist(X_norm[:,1],bins=100)
plt.show()
#pca分析
from sklearn.decomposition import PCA
pca = PCA(n_components=8)
X_pca = pca.fit_transform(X_norm)
#计算分析后各成分的方差以及方差比例
var = pca.explained_variance_
var_ratio = pca.explained_variance_ratio_
print(var)
print(var_ratio)
print(sum(var_ratio))
#可视化方差比例
fig2 = plt.figure(figsize=(10,5))
plt.bar([1,2,3,4,5,6,7,8],var_ratio)
plt.show()
#数据降维到2维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_norm)
print(X_pca.shape,X_norm.shape)
#计算方差比例
var_ratio2 = pca.explained_variance_ratio_
print(var_ratio2)
#降维数据的可视化
fig3 = plt.figure()
plt.scatter(X_pca[:,0][y==0],X_pca[:,1][y==0],marker='x',label='negative')
plt.scatter(X_pca[:,0][y==1],X_pca[:,1][y==1],marker='*',label='positive')
plt.legend()
plt.show()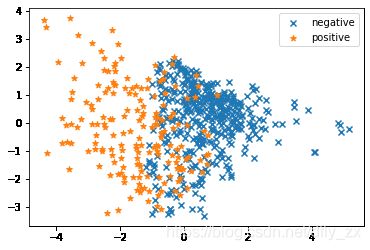
#降维后的模型建立与训练
model2 = LogisticRegression()
model2.fit(X_pca,y)#模型预测
y_predict_pca = model2.predict(X_pca)
accuracy_pca = accuracy_score(y,y_predict_pca)
print(accuracy_pca)![]()
PCA+逻辑回归预测检查者是否患糖尿病实战summary:
1、通过对原始数据建立逻辑回归模型,实现了糖尿病人检测,并达到了92%的准确率;
2、实现了各个维度数据的标准化处理,并且通过可视化对比了处理后的数据分布变化;
3、完成了PCA分析,并通过各主成分的方差比例帮助更好的理解信息的保留情况;
4、基于PCA技术成功将数据从8D降维到2D,并将其可视化进行直观的观察;
5、对降维后数据建立新的逻辑回归模型,新模型亦达到了88%的准确率,说明我们在将为的同时保留了最主要的信息。
核心算法参考链接:https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
拓展学习
如果现在就想开始学习机器学习,你还可以:
1、添加微信:ai_flare,领取Python编程课(AI方向)、Python实现机器学习,免费领取(仅限前100名)

2、人工智能学习路线:专为AI小白设计的人工智能实战课 - Python3入门人工智能 基础+实战 学习视频教程-CSDN学院
