面部特征点检测(使用opencv+dlib)
作为计算机视觉工程师和研究人员,很久以前,我们就一直在努力理解人类的面孔,从很早的时候起。面部分析最明显的应用是人脸识别。但是为了能够识别图像中的一个人,我们首先需要找到图像中脸所在的位置。因此,人脸检测-在图像中定位人脸并返回包含人脸的边框矩形/正方形是一个热门的研究领域。早在2001年,保罗·维奥拉和迈克尔·琼斯的开创性论文题为“使用简单特征的增强级联快速目标检测”,几乎解决了这个问题。在OpenCV的早期,甚至在某种程度上,OpenCV的杀手应用就是Paul Viola和Michael Jones面部检测器的一个很好的实现。 一旦你在图像中确定了脸的包围框,那么显而易见的研究问题就是看你是否能准确地找到不同面部特征的位置(例如 眼角、眉毛、嘴、鼻尖等)。面部特征检测在文献中也被称为“面部地标检测”、“面部关键点检测”和“面部对齐”,您可以在Google中使用这些关键字来寻找关于该主题的其他资料。
面部关键点检测的应用
关键点检测在人脸中有几个有趣的应用。下面列出其中的几项。
人脸特征检测增强人脸识别
面部地标可以用来将面部图像对齐到一个平均的面部形状,这样对齐后,面部地标在所有图像中的位置大致相同。直观地说,用对齐图像训练的面部识别算法会表现得更好,这种直接的使用已经被许多研究论文所证实。
头部姿态估计
一旦你知道了人脸的几个关键点,你也可以估计头部的姿势。换句话说,你可以弄清楚头部在空间中的朝向,或者这个人在看什么地方。例如本文中描述的CLM-Framework也返回了头部姿态。
面部调整
面部地标可以用来对齐面部,然后可以变形,将几张不同的人脸图像进行融合产生新的人脸图像。
虚拟美颜
检测到的地标被用来计算嘴、眼睛等的轮廓,进而渲染化妆。看下图

面部替换
如果你在两张脸上提取了面部特征点,你可以将一张脸与另一张脸对齐,然后无缝地将一张脸克隆到另一张脸上。
人脸特征检测库
因为有一些高质量的开源软件库已经实现了人脸特征检测的算法,所以我们最好不要重复造轮子,当然对底层算法感兴趣的朋友可以深挖这些开源代码的实现并尝试重写。Dlib和CLM-framework 是最常用的2个人脸特征检测库。
Dlib(C++/Python)
在机器学习、计算机视觉、图像处理和线性代数中,Dlib包含这几个领域的多种算法。同时具有c++和python接口。 相对其他任何面部特征检测库我更喜欢Dlib,因为其代码非常简洁,有很好的文档说明,允许在商业应用程序中免费使用,他们实现的算法非常高效和准确,您可以通过包含头文件轻松集成到C++项目中。
CLM-Framework(C++)
CLM-framework,也被称为Cambridge Face Tracker,是一个用于面部关键点检测和头部姿态估计的C++库。有两种重要的原因使Dlib优于CLM-Framework。第一,DLib比CLM-Framework高效得多。第二,Dlib的许可证允许您在商业应用程序中自由使用它。如果我必须选,我会用Dlib。有趣的是,CLM-Framework依赖于Dlib!
接下来,我来做一个具体的实验来演示。
先看效果:
1个银儿

2个银儿
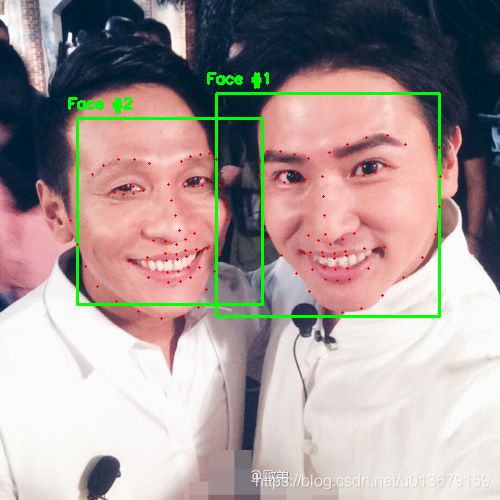
3个银儿

我们将使用dlib和OpenCV来检测图像中的面部特征点。 面部特征点被用来定位和表示面部的突出区域,如: 眼睛 眉毛 鼻子 嘴巴 脸颊。
检测人脸特征点一般分两步:
1、定位图片中的人脸位置
2、检测人脸的特征点。
人脸检测有很多方法可以实现,我们可以使用opencv内建的Haar级联检测器,也可以使用HOG + Linear SVM 目标检测器,当然也可以使用深度学习模型进行人脸检测。不管使用哪种方法检测图像中的人脸位置都无所谓。重要的是能获取到人脸的包围框就行。
有很多人脸特征点检测器,但所有方法都是用于定位和标记以下面部区域:嘴巴、左眼眉、右眼眉、左眼、右眼、鼻子、下巴。
dlib库中的人脸特征点检测器基于One Millisecond Face Alignment with an Ensemble of Regression Trees(Kazemi and Sullivan (2014))实现的。
理解dlib的人脸特征点检测器
dlib库自带的预训练的人脸特征点检测器用于获取脸部的特定区域对应的68(x,y)个坐标点。69个坐标点的位置如下:

这个68点模型来自于dlib所使用的训练数据集iBUG 300-W dataset,当然也有其他的训练数据集,如HELEN dataset,可以在该数据集上训练194点的人脸特征点检测器。
无论使用哪个数据集,都可以利用相同的dlib框架来训练输入训练数据上的特征检测器-如果您想训练面部地标检测器或自己的自定义形状预测器,这一点很重要。
接下来我会演示如何提取出人脸特征点。
使用dlib、opencv、python提取人脸特征点
看完整代码:
# USAGE
# python facial_landmarks.py --shape-predictor shape_predictor_68_face_landmarks.dat --image images/example_01.jpg
# import the necessary packages
import numpy as np
import argparse
import imutils
import dlib
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
def rect_to_bb(rect):
# take a bounding predicted by dlib and convert it
# to the format (x, y, w, h) as we would normally do
# with OpenCV
x = rect.left()
y = rect.top()
w = rect.right() - x
h = rect.bottom() - y
# return a tuple of (x, y, w, h)
return (x, y, w, h)
def shape_to_np(shape, dtype="int"):
# initialize the list of (x, y)-coordinates
coords = np.zeros((68, 2), dtype=dtype)
# loop over the 68 facial landmarks and convert them
# to a 2-tuple of (x, y)-coordinates
for i in range(0, 68):
coords[i] = (shape.part(i).x, shape.part(i).y)
# return the list of (x, y)-coordinates
return coords
# initialize dlib's face detector (HOG-based) and then create
# the facial landmark predictor
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
# load the input image, resize it, and convert it to grayscale
image = cv2.imread(args["image"])
image = imutils.resize(image, width=500)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# detect faces in the grayscale image
rects = detector(gray, 1)
# loop over the face detections
for (i, rect) in enumerate(rects):
# determine the facial landmarks for the face region, then
# convert the facial landmark (x, y)-coordinates to a NumPy
# array
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# convert dlib's rectangle to a OpenCV-style bounding box
# [i.e., (x, y, w, h)], then draw the face bounding box
(x, y, w, h) = rect_to_bb(rect)
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the face number
cv2.putText(image, "Face #{}".format(i + 1), (x - 10, y - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# loop over the (x, y)-coordinates for the facial landmarks
# and draw them on the image
for (x, y) in shape:
cv2.circle(image, (x, y), 1, (0, 0, 255), -1)
# show the output image with the face detections + facial landmarks
cv2.imshow("Output", image)
cv2.waitKey(0)先解释两个通用功能函数,rect_to_bb和shape_to_np。
rect_to_bb接收一个参数rect,rect是人脸检测测返回的矩形包围框,它包括包围框的坐上角坐标和右下角坐标,但是opencv中的矩形框表示形式为 “(x, y, width, height)”,所以该函数将rect转变为opencv的格式返回。
人脸特征检测器返回一个shape对象,该对象包括68个坐标点,使用shape_to_np,我们可以将68个坐标点组成一个numpy数组,便于python代码处理。
接下来分析主流程:
1、导入主要的模块
2、处理命令行参数:
-
--shape-predictor:这是dlib预训练的人脸特征检测器的路径。你可在这里下载here
-
--image:要获取人脸特征点的图像的路径
3、初始化人脸检测器和人脸特征点检测器。
4、读取图片,调整图片大小,将RGB图像转为灰度图,检测人脸。
5、对检测到的每个人脸矩形框进行人脸特征点提取。
6、将人脸矩形框画在图片上,将68个特征点画在图片上。
你可以用如下命令运行代码:
ython facial_landmarks.py --shape-predictor shape_predictor_68_face_landmarks.dat --image images/example_01.jp结果:

参考链接:https://www.learnopencv.com/facial-landmark-detection/
参考链接:https://www.pyimagesearch.com/2017/04/03/facial-landmarks-dlib-opencv-python/
一个有趣的应用:https://www.auduno.com/clmtrackr/examples/facesubstitution.html