人工智能之父麦卡锡给出的定义
-
构建智能机器,特别是智能计算机程序的科学和工程。
-
人工智能是一种让计算机程序能够"智能地"思考的方式
-
思考的模式类似于人类。
什么是智能?
智能的英语是 Intelligence
推理,知识,规划,学习,交流,感知,移动和操作物体。
智能 不等于 智力 (IQ:智商 比较类似计算机的计算能力)
如何算有智能?
-
可以根据环境变化而做出相应变化的能力。
-
具有"存活" 这最基本的动因
-
自主意识,自我意识等等。
抢小孩子西瓜吃,小孩子护住西瓜就是自主意识。
图灵测试(Turing Test)
-
图灵于1950年提出的一个关于判断机器是否足够智能的著名试验。
评委,评判目标是机器和人。评委与被评判目标以墙隔开。评委向人和机器人来提出问题。
评委事先不知道对面谁是机器人,谁是人。评委提的问题机器人和人分别做出回答。
当评委不能分辨是人还是机器人后,说明机器拥有了与人类似的思维。
暂时还没有机器通过图灵测试。
智能分类: 自然智能 & 人工智能
人造出来的智能
Artificial Intelligence 人造智能
人工智能的前景
人工智能的需求:
-
提高品质
-
增加效率
-
解决难题
人工智能的前景好在哪里?
支持: 企业支持 科技支持(大数据,硬件设备) 国家支持
2017年7月20日中国国务院发布了《新一代人工智能发展规划》
2020年中国与世界平齐
Excel 等将用Python 替代 VBA
Python 被加入高考
CCTV 的 机智过人 节目
人工智能产品 和 人类高手比拼 ,中央电视台和中国科学院共同举办。
嘉宾 柯洁 撒贝宁 林书豪 江一燕 知名人士 智能人士
微软小冰可以作曲写词,画画。
人工智能需要的基本数学知识
数学;
论文 & 自己的实践研究
实战性课程 基本的了解就行
人工智能的历史
-
人工神经网络被提出(AI缘起)
-
Artificial Neural Network(简称 Neural Network)
-
沃伦.麦卡洛克和沃尔特.皮茨在1943创造了神经网络的计算模型。
-
为以后的深度学习打下了重要的基础
-
达特茅斯会议(定义AI)
-
达特茅斯学院(Dartmouth College) 是美国一所私立大学
由约翰.麦卡锡等人于1956年8月31日发起。
-
标志着AI(人工智能)的正式定义(诞生)
-
感知器(Perceptron)
-
一种最简单的人工神经网络,是生物神经网络机制的简单抽象、


-
一种最简单的人工神经网络, 是生物神经网络机制的简单抽象
-
由罗森布拉特于1957年发明
-
将人工智能的研究推向第一个高峰。
-
人工智能的第一个寒冬
-
1970年开始的十几年里
-
传统的感知器耗费的计算量和神经元数目的平方成正比
-
当时的计算机也没有能力完成神经网络模型所需要的超大计算量。
-
霍普菲尔德神经网络
-
一种递归神经网络( Recurrent Neural Network)
-
由约翰.霍普菲尔德在1982年发明
-
具有反馈(Feed back)机制

-
反向传播(Back Propagation) 算法。
-
1974年哈佛大学的保罗沃伯斯发明,当时没有受到重视。
-
1986年大卫.鲁姆哈特等学者出版的书中完整的提出了BP算法
-
使大规模神经网络训练成为可能,将人工智能推向第二个高峰。
-
人工智能第二个寒冬
1990年开始
-
人工智能计算机 Darpa没能实现(美国政府花了巨资的)
-
政府投入缩减
-
深度学习(deep learning)
-
基于深度(指"多层") 神经网络
-
2006年由杰弗里.辛顿(Geoffrey Hinton)提出
-
人工智能性能获得突破性进展
-
进入感知智能时代
-
深度学习在语音和视觉识别上分别达到99% 和 95%的识别率
-
2013年开始
-
人工智能三个时代:
-
运算智能(深蓝打败俄罗斯象棋选手,通过暴力运算,算出所有可能的下棋步骤)
-
感知智能,语音图像,类似触觉的时代
-
认知智能: 人类特有的能力,一个非常高等的能力。
-
AlphaGo击败众多人类选手
Google 买下的Deepmind公司的AlphaGo (基于TensorFlow)
2016年接连击败围棋界顶尖棋手。
深度学习被广泛关注,掀起了学习人工智能热潮
-
未来由我们创造
-
你应该感到自豪,因为你学习了人工智能
-
虽然我们不能过分乐观,未来也许还会有低潮
但人工智能是大势所趋,学了绝对不会吃亏。
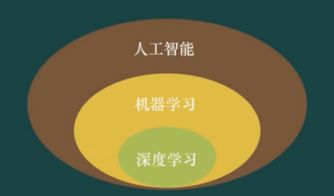
Ai和机器学习、深度学习的关联
人工智能的知识图谱

人工智能不仅仅是一个独立的学科,它与很多其他的学科都有交集。
机器学习和深度学习都与其他学科有交集。但是机器学习总的是属于人工智能,而深度学习属于机器学习的一个子领域。
横穿而过的是神经网络。深度学习是基于神经网络的。
AI ML 和 DL 的关系
-
机器学习是实现人工智能的一种方法,深度学习是机器学习的一个分支

人工智能能够王者归来,深度学习功不可没
-
深度学习是引领人工智能热潮的火箭
-
深度学习作为后代,却给爷爷和爸爸争光了。

人工智能搭上了深度学习的火箭。
什么是机器学习?
机器学习是实现人工智能的一种方法,深度学习是机器学习的一个分支。
什么是学习?
过程: 一个系统,能够通过执行某个过程,改善了性能。
说的更深入一些,学习的目的是"减熵"
热力学第二定律: 一个孤立系统倾向于增加熵(混乱程度)
生命活着就是在减熵
适应环境
机器学习的必要性
很多软件无法靠人工编程: 自动驾驶,计算机视觉,自然语言处理。
识别鸢尾花难以用人工编程
花瓣数,花颜色,花纹形状,等等。
人工编程难以定性。
-
人类常会犯错,(比如紧张,累了,困了),机器不容易犯错
-
机器的计算能力越来越强 提高我们生活质量加快科技发展
"晦涩"的机器学习定义
对于某类任务T (Task) 和性能度量 P(Performance)
通过经验E(Experience) 改进后
在任务T上由性能度量P 衡量的性能有所提升。
简单的机器学习的定义
机器学习: 让机器学习到东西。

mark
人类思考 VS 机器学习

机器学习: 用数据来解答问题
数据对应 训练过程
解答问题 对应着推测的过程。
练习 & 考试
学生学习: 用做练习题来提高考试的成绩
做练习题对应训练
考试 对应你对新情况的推测
AlphaGo 学下围棋
围棋博弈: 用和自己下棋来提高下棋胜率
和自己下棋对应训练
与人类下棋对应推测
传统编程 VS 机器学习


mark
机器学习大致等同于找一个好的函数(Function)/模型

机器学习的分类
-
监督学习
-
非监督学习
-
半监督学习
-
强化学习
什么是监督学习?
Supervised Learning: 有标签。
近义词: 分类(Classification)

数据有给定的正确标签。

什么是非监督学习?
Unsupervised Learning: 没有标签 近义词: 聚类(Cluster)

把类似的数据归为一堆。

预测到规定好的堆中。
什么是半监督学习?
Semi-Supervised Learning: 有少部分标签 最类似人的生活。
父母教给我们怎么做?让座+好孩子。 独立生活+自己判断

想要判断c是不是精英。
物以类聚。半监督也是基于聚类的cluster实现。
什么是强化学习?
前面都是基于有没有标签,或者是有标签所占的比例。
Reinforcement Learning: 基于环境而行动,以取得最大化预期利益。

玩游戏,如果挂掉分数-1,如果赢了分数+1.

总得分:
通过分数的奖励去刺激它进行进一步的强化。
机器学习的算法多种多样。如何去选择一个适合我们的机器学习方法。我们可以依照skit-learn给出的图。

从右上角的start开始:
-
你的样本数是否大于50,如果不是那么你需要有更多的样本。
-
预测类别,如果是要预测类别
-
你有没有加标签的数据。
-
分类 & 回归/预测 & 聚类 & 维度下降
为什么回归叫regression(回归)
-
回归用于预测(比如股票),它的输出是连续的,与离散的分类不同。
-
回归之所以叫回归是英国生物学家兼统计学家高尔顿在研究人类遗传问题时提出的。
-
人类身高不会无限的增高(两种身高 父亲的儿子的身高) 有向他们父辈的平均身高回归的趋势。
机器学习的六步走
-
收集数据 -> 准备数据(抽取特征) -> 选择/建立模型 -> 训练模型
-
测试模型 -> 调节参数

mark
机器学习的"关键三步"
-
找一系列函数来实现预期的功能: 建模问题
-
找一组合理的评价标准,来评估函数的好坏: 评价问题
-
快速找到性能最佳的函数: 优化问题(比如梯度下降就是这个目的)
面对ai我们应有的态度
人工智能大热
火到连Android都被比了下去,连Kotlin和Go都有点黯然失色
1950年就被提出。

审时度势
-
千万不要跟风,不要头脑发热。
AR VR寒冬
人工智障
-
目前的人工智能,其实还停留在比较初级的阶段
马云说人工智能应该做那些计算机擅长而人类不擅长的事。现在很多的人工智能还只是模仿人类做的事,还远远没有达到机器智能的程度。
离真正的机器智能还比较遥远,毕竟人脑太强大,很难被模仿。
人类从未创造生命
-
人类到目前为止只不过能复制生命,从没有从无到有来创造
多利羊只是复制。克隆。
对生命对自然有一颗敬畏之心。
目前两个派别
马斯克: 特斯拉的ceo

Facebook ceo 和 Google ceo
反省自己比担心AI更重要。
人心比万物都诡诈,与人心相比,AI真的太简单了。
全知并非全能
-
即使这类人工智能存在,它得和人类的经济和资源竞争。
需要适当的防备AI
-
可能AI 会在不断学习的过程中习得一些不可控的思维。
借人工智能来认识自己
-
人类的大脑是怎么运作的,我们还知之甚少,更不用说模仿或者改造
人机合作
AI 有 机智过人 和 技不如人 人机合作 惊为天人
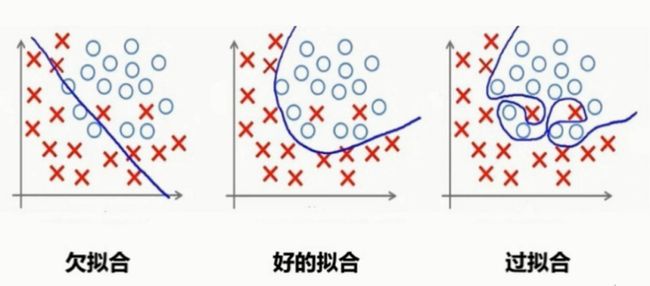
什么是过拟合?
过分拟合。: OverFitting
fitting是拟合,曲线能不能很好的表现样本,并且拥有很好的泛化能力。
拟合的结果有三种:

UnderFitting: 欠拟合。样本不够或算法不精,测试样本特征没学到。
Fitting right: 拟合完美,恰当地拟合测试数据,泛化能力强
Overfitting: 过拟合 "一丝不苟"拟合测试数据,泛化能力弱。
回归(regression) 问题中三种拟合状态

分类(Classification) 问题中三种拟合状态
打个比方;谈恋爱
你为了迎合女朋友的习惯总结了一套恋爱的圣经,但是你所总结的恋爱圣经只是针对于这个女孩的性格。太过于拟合这个女孩了。
谈其他女朋友时,想如法炮制就行不通了。
打个比方: 做菜
开始训练出来的模型只会做一道菜,太贴合这个模型。让它做其他的菜,各种各样菜不能泛化

欠拟合好解决: 增加训练量训练数据。把算法弄的精确一点。
解决过拟合的一些方法
方法:
- 降低数据量
- 正则化
- Dropout
Dropout: 丢弃、退出 退学者
全连接的神经网络,将其中一些连接取消掉

只用部分的连接来构建神经网络。不会过分的贴合样本,起到一个好的泛化的作用。
学校里学到了知识,我没有死记硬背。能够很好适应社会。
什么是深度学习?
机器学习是实现人工智能的一种方法,深度学习是机器学习的一个分支。

基于深度神经网络的学习研究称之为深度学习

只有一个两个隐藏层的简单神经网络,不把它成为深度神经网络,大于两个隐藏层的神经网络我们称之为深度神经网络。
输入层和输出层都只会有一个,深指隐藏层层数很多。
深度学习为什么兴起?
传统的机器学习存在瓶颈。

数据量比较小的时候,其实表现类似。深度学习要想表现好,数据量是关键。
深度学习能有高回报的必要条件:
-
大数据: 全球每天都有海量数据产生,大公司更是大权在握。
-
强计算力: 云计算,GPU ,越来越快的CPU
复杂模型: 一般来说隐藏层越多,效果越好。
现在这些条件都已满足,请开始你的表演。
深度学习的形象比喻: 恋爱

初恋期:输入参数
隐藏层: 跳转权重,激励函数参数。
输出层: 与预期去对比
第一阶段初恋期:
相当于神经网络的输入层,不同的参数设置
第二阶段磨合期:
相当于神经网络的隐藏层,调整参数权重
第三阶段稳定期:
相当于神经网络的输出层,输出结果和预期比较。
错误(Error)了: 与期望的误差(Loss/Cost)
损失函数和成本(代价)函数
BP算法: 误差反向传递(Back Propagation)
改: 调整(Tuning)参数的权重(Weight)
我错了我要改。
调整对应参数的权重
-
调整"逛街"的权重(重要性)
-
调高榴莲味蛋糕权重,调低巧克力味蛋糕的权重。
-
调高聊天权重
女友说: 你变好了不少啊,开心!
磨合过程: 不断的调整各个参数
-
在神经网络中正向传播参数信号,经过隐藏层处理,输出结果。
-
计算和预期的差距(误差),反向传播误差,调整网络参数权重
-
不断地进行: 反向传播->计算误差->反向传播->调整权重

最终结果:

其实不仅调参,还涉及到模型的调整,如增加神经元,灭活神经元等。