Transformer
论文资源
The Illustrated Transformer
Attention Is All You Need
前言
Transformer抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成,Bert就是基于Transformer构建的,这个模型广泛应用NLP邻域,例如机器翻译,问答系统,文本摘要和语音识别等等方向
原理
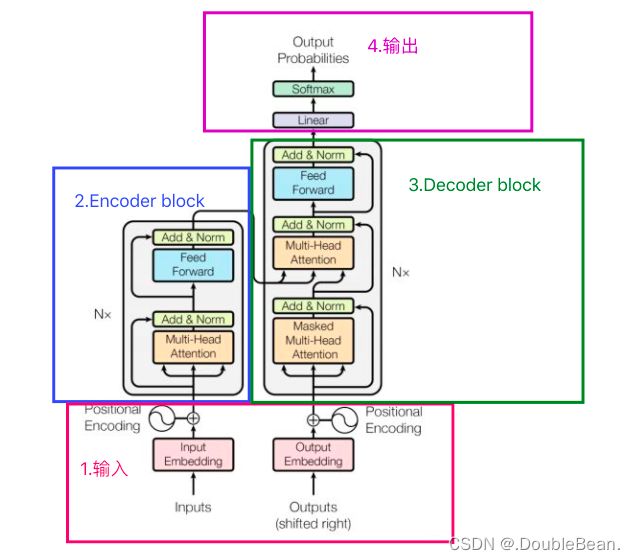
Transformer整体结构

大致可以分为4个部分: Input、Encoder block、Decoder block、Output
Encoder: 输入是单词的Embedding,再加上位置编码,然后进入一个统一的结构,这个结构可以循环很多次(N次),也就是说有很多层(N层)。每一层又可以分成Attention层和全连接层,再额外加了一些处理,比如Skip Connection,做跳跃连接,然后还加了Normalization层。其实它本身的模型还是很简单的
Decoder: 第一次输入是前缀信息,之后的就是上一次产出的Embedding,加入位置编码,然后进入一个可以重复很多次的模块。该模块可以分成三块来看,第一块也是Attention层,第二块是cross Attention,不是Self-Attention,第三块是全连接层。也用了跳跃连接和Normalization
输出: 最后的输出要通过Linear层(全连接层),再通过softmax处理
Self Attention Mechanism(自注意机制)
拿到不同的数据,我们的关注点可能会不同,关注度最大的区域将描述当前的数据有着怎样的特点,有着怎样的分辨能力。例如提取图像特征的时候,使用图像的热度图可视化方法,通过观察高响应区域便可判断出哪块区域被当作重点了。文本同理。
举个例子(句中it指代的是什么?):
The animal didn't cross the street because it was too tired
由tired可知这里的it指代的是animal,所以对于it来说关注的重点是animalThe animal didn't cross the street because it was too narrow
由narrow可知这里的it指代的是street,所以对于it来说关注的重点是street
下图中颜色的深浅表示影响力的强弱(相当于权重越大影响越大),可以很容易的看出对it影响最大的是The和animal这两个单词

从例子可以看出,不同的语境it将指代不同的含义,所以在词做编码的时候,不能简单的考虑当前这一个词,还需要考虑当前词所处的上下文语境,也就是说要把整个上下文语境融入到当前词向量当中
Self-Attention就是查看句子中的单词与其他单词之间的相互影响,也就是在文本中,每个单词它对于该句子的其他单词关注度最大的是哪些单词?
Self-Attention in Detail
-
论文中引入了三个矩阵作为辅助,来表征注意力的强弱,分别是Q(Query)、K(Key)、V(Value)

如图所示,X是输入句子Embedding后的结果,x1和x2是其中的两个单词。x1转换成了三个不一样的向量,分别叫q1、k1、v1,x2同样转换成了三个不一样的向量,分别叫q2、k2、v2。Q、K、V是由X线性映射得到
q1=x1WQ q2=x2WQ
k1=x1WK k2=x2WK
v1=x1WV v2=x2WV
上述过程中,不同的xi共用了同一个WQ、WK、WV ,也就是说,通过共享权值,x1和x2在某种程度上有着一定的信息交换 -
计算self-attention的值,该值决定了当我们在某一个位置encode一个单词时,对句子的所有单词的关注程度。q1代表Thinking的query vector,k1和k2分别代表Thinking和Machines对应的key vector,则计算Thinking的attention score是计算q1与k1、k2的点乘,即q1·k1和q1·k2 (Thinking和Machines是论文中举的例子)
点乘: a·b = |a||b|cos

-
将self-attention score进行一个softmax的计算,然后把Value和Softmax得到的值进行线性组合,便可得到z1和z2,有了z1和z2,再通过全连接层,就能输出Encoder层的输出r1和r2
z 1 = θ 11 v 1 + θ 12 v 2 z 2 = θ 21 v 1 + θ 22 v 2 [ θ 11 , θ 12 ] = s o f t m a x ( q 1 k 1 d k , q 1 k 2 T d k ) [ θ 21 , θ 22 ] = s o f t m a x ( q 2 k 1 d k , q 2 k 2 T d k ) z_{1} = θ_{11}v_{1} + θ_{12}v_{2} \\ z_{2} = θ_{21}v_{1} + θ_{22}v_{2} \\ [θ_{11}, θ_{12}] = softmax(\frac{q_{1}k_{1}}{\sqrt{d_{k}}}, \frac{q_{1}k_{2}^{T}}{\sqrt{d_{k}}}) \\ [θ_{21}, θ_{22}] = softmax(\frac{q_{2}k_{1}}{\sqrt{d_{k}}}, \frac{q_{2}k_{2}^{T}}{\sqrt{d_{k}}}) z1=θ11v1+θ12v2z2=θ21v1+θ22v2[θ11,θ12]=softmax(dkq1k1,dkq1k2T)[θ21,θ22]=softmax(dkq2k1,dkq2k2T)
式子中的dk是向量q或k的维度,向量q和向量k的维度一定是一样的,因为要做点积,而v的维度和向量q或k的维度不一定相同 (图中除以8是论文中举的例子)

为何要除以√dk 论文中给了解释,是为了把注意力矩阵变成标准正态分布,使得softmax归一化之后的结果更加稳定:

-
这里用矩阵运算(矩阵运算可以用GPU加速),就是把输入的所有向量合并成矩阵形式,所有的Query、Key、Value向量也合并成了矩阵形式,用公式表示就是:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V Attention(Q,K,V)=softmax(dkQKT)V
Multi-headed Attention
类似于卷积神经网络中的filter,一种卷积核可以在原始图像中提取出一种特征,可以用多种卷积核堆叠来提取多种特征。Encoder中一组Q、K、V能得到一组当前词的特征表达,如果用不同的WQ、WK、Wv,就能得到不同的Q、K、V,好处是有多个Q、K、V就能得到多个特征表达,可以从多个角度来看待Attention,也就是可以让Attention有更丰富的层次。一般有8个head就差不多了

将多个特征z拼接成一个长的向量,然后通过一层全连接层进行降维,也就是乘以一个矩阵WO

下图用了八个Attention,从蓝色到灰色分别用八种不同的颜色表示,我们可以看到以一个单词在八个Attention上对句子里每个单词的权重。这里只挑出橙色和绿色,先看橙色部分,对单词it进行编码时,连接的权重最大的是animal,说明最关注的是animal,再看绿色部分,它的注意力集中在tired上。所以模型对it这个单词的特征体现在animal和tired上

Attention Mask – Padding Mask
在上面的self attention的计算中,x的维度是[batch size, max sequence length],我们通常使用mini batch来计算,也就是一次计算多句话,一个mini batch是由多个不等长的句子组成,我们就需要按照这个mini batch中最大的句长进行补齐长度,一般是用0进行填充,这个过程叫做padding
但这时进行softmax的时候就会产生问题,回顾softmax函数 σ ( z ) i = e z i ∑ j = 1 K e z j σ(z)_{i} = \frac{e^{z_{i}}}{\sum\limits_{j=1}^{K}e^{z_{j}}} σ(z)i=j=1∑Kezjezi,e0是1,是有值的,这样的话softmax中被Padding的部分就参与了运算,就等于是让无效的部分参与了运算,会产生很大的隐患
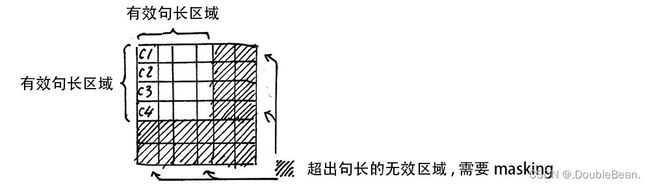
这时就需要做一个mask让这些无效区域不参与运算,我们一般给无效区域加一个很大的负数的偏置,也就是:
z i l l e g a l = z i l l e g a l + b i a s i l l e g a l b i a s i l l e g a l → − ∞ z_{illegal} = z_{illegal} + bias_{illegal} \\ bias_{illegal} →-∞ zillegal=zillegal+biasillegalbiasillegal→−∞
e-∞ 基本上为0,就不会对softmax造成影响
Positional Encoding(位置编码/位置嵌入)
输入模型的数据不仅要有word embedding还要有positional embedding,这是为了让网络知道这个单词所在句子中的位置,也就是想让网络在做Self-Attention时不但要知道注意力聚焦在哪个单词上,还要知道单词之间的相互距离
Q: 为何要知道单词之间的相对位置?
A: Transformer模型没有RNN的迭代操作,为了让模型能利用序列的顺序,必须输入每个字的位置信息给Transformer,才能识别出语言中的顺序关系

论文中是使用sin和cos函数来提供模型位置信息
P E p o s , 2 i = s i n ( p o s 1000 0 2 i / d m o d e l ) PE_{pos, 2i}=sin(\frac{pos}{10000^{2i/d_{model}}}) PEpos,2i=sin(100002i/dmodelpos)
P E p o s , 2 i + 1 = c o s ( p o s 1000 0 2 i / d m o d e l ) PE_{pos, 2i+1}=cos(\frac{pos}{10000^{2i/d_{model}}}) PEpos,2i+1=cos(100002i/dmodelpos)
上式中,pos指的是句中字的位置,取值范围是[0, max sequence length),i指的是词向量的维度,取值是[0, embedding dimension),sin和cos则是对应着embedding dimension维度的一组奇数和偶数序号的维度
举例:

维度解析
这里强推b站视频,讲的是真的好 从零解读碾压循环神经网络的transformer模型(一) - 注意力机制 - 位置编码 - attention is all you need
- 输入X的维度是 [batch size, max sequence length]
- 经过Input Embedding,查询词库表 (词库表的维度是 [vacab size, embedding dimension]) 得到字的词向量Embedding Lookup,维度是 [batch_size, max sequence length, embedding dimension]
- Positional Embedding的维度是 [max sequence length, embedding dimension]
Xembedding = Embedding Lookup(X) + Positional Embedding
Xembedding的维度是 [batch size, max sequence length, embedding dimension] - 对Xembedding做线性映射,也就是分配三个权重矩阵WQ、WK、Wv,这三个权重矩阵维度是 [embedding dimension, embedding dimension],矩阵相乘得到Q、K、V三个矩阵,和线性变换之前的维度一致
- 进行多头注意力机制,也就是multi head attention,因为要用多头注意力机制来提取多重语意的含义,首先定义head的数量(num of heads / h),注意embedding dimension必须整除h,因为要把embedding dimension分割成h份
分割后Q、K、V的维度是 [batch size, max sequence length, h, embedding dimension / h]
之后我们把Q、K、V中的max sequence length, h进行一下转置,为了方便后续的计算,则转置后的Q、K、V的维度是 [batch size, h, max sequence length, embedding dimension / h]

- 计算Q与K.T的乘积,从图中可以看到,注意力矩阵的第一行第一列是c1c1,含义是第一个单词与第一个单词的注意力机制,然后依次向后求得c1c2,c1c3, …,所以每一行指的是当前字与句子中所有字的关联程度,要使得每一行的关联程度的和为1,也就是要使得每个字与句中所有字的注意力权重的和为1,需要进行softmax操作,也就是沿着列进行softmax归一化

- 注意力矩阵的作用就是一个注意力权重的概率分布,我们要用注意力矩阵的权重给V进行加权

上图中,我们从注意力矩阵取出一行(和为1)然后依次点乘V的列,矩阵V的每一列代表着每个字向量的数学表达,也就是用注意力权重进行这些数学表达的加权线性组合,从而使得每个字向量都含有当前句子内所有字向量的信息

Decoder
Decoder也是由若干个layers堆叠而成,上层的layer接受下层layer的输出作为输入,这和encoder是一样的,Decoder每一层的结构和encoder很类似,只是在下面的Multi head self attention是经过masked,并且多了Encoder-Decoder Multi-head Attention
Shift Right

以翻译为例:
- 输入:我爱中国
- 输出: I Love China
因为输入(“我爱中国”)在Encoder中进行了编码,这里我们具体讨论Decoder的操作,也就是如何得到输出(“I Love China”)的过程
Decoder执行步骤
Time Step 1
- 初始输入: 起始符 + Positional Encoding(位置编码)
- 中间输入:(我爱中国)Encoder Embedding
- 最终输出:产生预测“I”
Time Step 2
- 初始输入:起始符 + “I”+ Positonal Encoding
- 中间输入:(我爱中国)Encoder Embedding
- 最终输出:产生预测“Love”
Time Step 3
- 初始输入:起始符 + “I”+ “Love”+ Positonal Encoding
- 中间输入:(我爱中国)Encoder Embedding
- 最终输出:产生预测“China”
Shifted Right实质上是给输出添加起始符/结束符,方便预测第一个输出/结束预测的过程
Sequence mask
Encoder中的self-attention使用了padding mask,而Decoder还需要防止标签泄露,即在t时刻不能看到t时刻之后的信息,因此为了防止模型提前看到待预测的内容,在上述padding mask的基础上,还要加上sequence mask

上三角区域全部设为-inf,由于e-∞=0不会对softmax造成影响
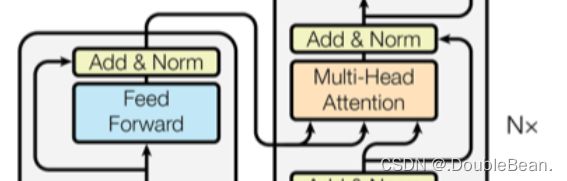
Encoder-Decoder Multi-head Attention
Decoder中的第二层注意力层,输入不仅有前一层的输出x,还有来自Encoder的输出m,然后把Encoder产生的向量m作为Decoder的Key和Value,Decoder的x作为Query,然后进行Self-Attention
Q=xWQ K = mWK V = mWv
参考资源
- 超详细图解Self-Attention
- Transformer - Attention is all you need
- Self-Attention和Transformer
- 从零解读碾压循环神经网络的transformer模型(一) - 注意力机制 - 位置编码 - attention is all you need