【TPAMI 2022】A Survey on Vision Transformer
文章目录
- WHAT
- Contents
-
- 2. Formulation of Transformer
-
- 2.1 Self-Attention
- 2.2 Other Key Concepts in Transformer
- 3 VISION TRANSFORMER
-
- 3.1 Backbone for Representation Learning
-
- 3.1.1 Pure Transformer
- 3.1.2 Transformer with Convolution
- 3.1.3 Self-supervised Representation Learning
- 3.1.4 Discussions
- 3.2 High/Mid-level Vision
-
- 3.2.1 Generic Object Detection
- 3.2.2 Segmentation
- 3.2.3 Pose Estimation
- 3.2.4 Other Tasks
- 3.2.5 Discussions
- 3.3 Low-level Vision
-
- 3.3.1 Image Generation
- 3.3.2 Image Processing
- 3.4 Video Processing
-
- 3.4.1 High-level Video Processing
- 3.4.2 Low-level Video Processing
- 3.4.3 Discussions
- 3.5 Multi-Modal Tasks
- 3.6 Efficient Transformer
-
- 3.6.1 Pruning and Decomposition
- 3.6.2 Knowledge Distillation
- 3.6.3 Quantization
- 3.6.4 Compact Architecture Design
- 4 CONCLUSIONS AND DISCUSSIONS
-
- 4.1 Challenges
- 4.2 Future Prospects
WHAT
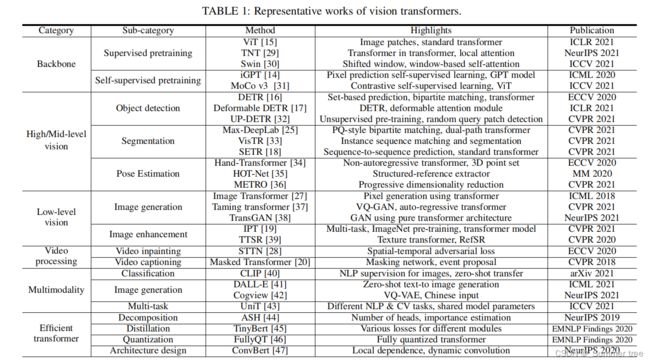
- 在本文中,我们对这些视觉转换器模型进行了综述,并根据不同的任务对其进行了分类,分析了它们的优缺点。
- 探讨的主要类别:
- 骨干网络
- 高/中级视觉
- 低级视觉、
- 视频处理
- 介绍高效的transformer方法用于将transformer推广到真实的基于设备的应用程序中
- 简要地介绍了计算机视觉中的自注意机制,因为它是transformer的基本组件。
- 我们讨论了视觉transformer面临的挑战,并提出了未来的几个研究方向。
Transformer是一种新型的神经网络。它主要利用自注意机制[7],[8]来提取内在特征[9],在人工智能应用中具有广阔的应用前景.
Contents
2. Formulation of Transformer

Each transformer block is composed of a multi-head attention layer, a feed-forward neural network, shortcut connection and layer normalization.
2.1 Self-Attention
the input vector is first transformed into three different vectors: the query vector q, the key vector k and the value vector v with dimension dq = dk = dv = dmodel = 512.
Vectors derived from different inputs are then packed together into three different matrices, namely, Q, K and V.

Vectors with larger probabilities receive additional focus from the following layers.
Note that the preceding process is invariant to the position of each word, meaning that the self-attention layer lacks the ability to capture the positional information of words in a sentence.
a positional encoding with dimension dmodel is added to the original input embedding. Specifically, the position is encoded with the following equations
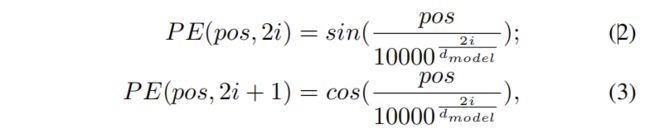
in which pos denotes the position of the word in a sentence, and i represents the current dimension of the positional encoding.
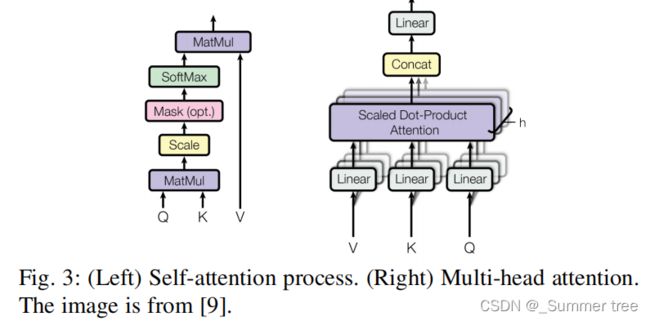
Multi-Head Attention.
一个单一的自我注意层限制了我们专注于一个或多个特定位置的能力,而不会同时影响对其他同等重要位置的注意。
对于不同的头部使用不同的查询矩阵、键值矩阵,这些矩阵通过随机初始化,训练后可以将输入向量投射到不同的表示子空间中。

2.2 Other Key Concepts in Transformer
-
FFN :consists of two linear transformation layers and a nonlinear activation function within them, and can be denoted as the following function :
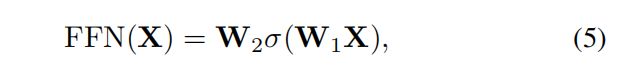
-
Residual Connection in the Encoder and Decoder.: The output of these operations can be described as:

-
Final Layer in the Decoder.:这是通过一个线性层和一个softmax层实现的。线性层将该向量投影为具有dword维数的logits向量,其中dword是词汇表中的单词数、。然后使用softmax层将logit向量转换为概率。
3 VISION TRANSFORMER
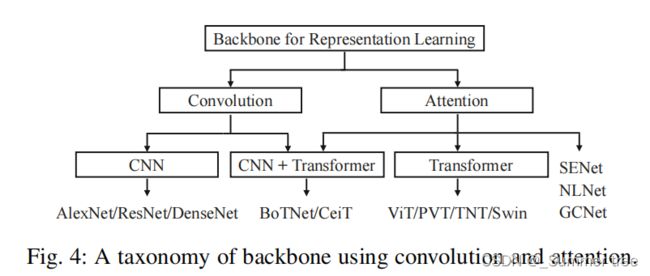
3.1 Backbone for Representation Learning

3.1.1 Pure Transformer
ViT:
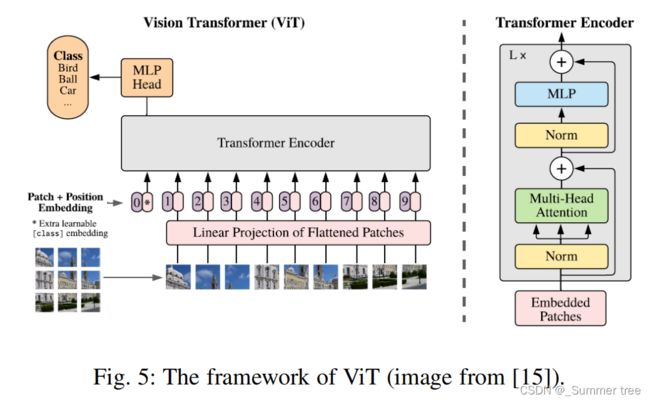
- Vision Transformer (ViT) [15] is a pure transformer directly applies to the sequences of image patches for image classification task.
- Figure 5 shows the framework of ViT.
DeiT: 一种竞争性的无卷积转换器,称为数据效率图像转换器(DeiT),通过仅对ImageNet数据库进行训练
Variants of ViT :
- TNT [29]: further divides the patch into a number of subpatches and introduces a novel transformer-in-transformer architecture which utilizes an inner transformer block to model the relationship between sub-patches and an outer transformer block for patch-level information exchange.
- Swin Transformers [60], [64] performs local attention within a window and introduces a shifted window partitioning approach for cross-window connections.
- . DeepViT [68] proposes to establish crosshead communication to re-generate the attention maps to increase the diversity at different layers.
- KVT [69] introduces the k-NN attention to utilize locality of images patches and ignore noisy tokens by only computing attentions with top-k similar tokens.
- XCiT [71] performs self-attention calculation across feature channels rather than tokens, which allows efficient processing of high-resolution images.
自注意机制的计算复杂度和注意精度是未来优化的两个重点。
3.1.2 Transformer with Convolution
there are still gaps in performance between transformers and existing CNNs. One main reason can be the lack of ability to extract local information.. combining the transformer with convolution can be a more straightforward way to introduce the locality into the conventional transformer.
3.1.3 Self-supervised Representation Learning
Generative Based Approach.
- 以 iGPT [14]为例。
- consists of a pre-training stage followed by a finetuning stage.
- During the pre-training stage, auto-regressive and BERT objectives are explored. To implement pixel prediction, a sequence transformer architecture is adopted instead of language tokens (as used in NLP).
- 当与早期停止结合使用时,预训练可以被认为是一个有利的初始化或正则化。
- During the fine-tuning stage, they add a small classification head to the model. This helps optimize a classification objective and adapts all weights.



The difference of iGPT and ViT-like models mainly lies on 3 aspects:
- The input of iGPT is a sequence of color palettes by clustering pixels, while ViT uniformly divided the image into a number of local patches
- The architecture of iGPT is an encoder-decoder framework, while ViT only has transformer encoder;
- iGPT utilizes auto-regressive selfsupervised loss for training, while ViT is trained by supervised image classification task.
Contrastive Learning Based Approach.
- MoCo v3 framework, which is an incremental improvement of MoCo [112].
- the authors take two crops for each image under random data augmentation. They are encodes by two encoders Fq和fk,输出向量q和k。

The encoder fq consists of a backbone (e.g., ViT), a projection head and an extra prediction head; while the encoder fk has the backbone and projection head, but not the prediction head. fk is updated by the moving-average of fq, excluding the prediction head.
The model can still be unstable if the learning rate is too big and the first layer is unlikely the essential reason for the instability.
3.1.4 Discussions
All of the components of vision transformer including;
- multihead self-attention,
- multi-layer perceptron,
- shortcut connection,
- layer normalization,
- positional encoding
- network topology
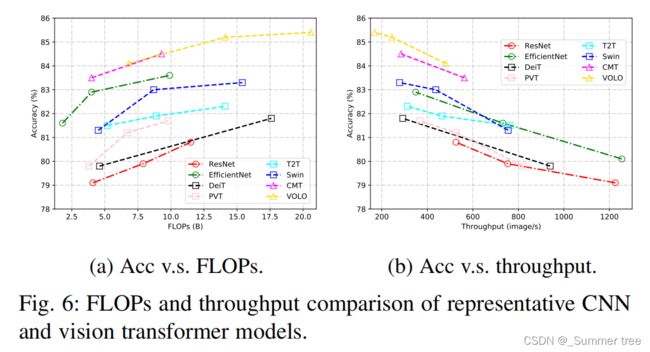
From the results in Figure 6, we can see that combining CNN and transformer achieve the better performance, indicating their complementation to each other through local connection and global connection.
3.2 High/Mid-level Vision
- object detection [16], [17], [113], [114], [115],
- lane detection [116], 道路检测
- segmentation [33], [25], [18]
- pose estimation [34], [35], [36], [117].
3.2.1 Generic Object Detection
Transformer-based object detection methods are broadly categorized into two groups:
- transformerbased set prediction methods [16], [17], [120], [121], [122]
- transformer-based backbone methods [113], [115]

与基于cnn的检测器相比,基于Transformer的检测器在精度和运行速度方面都表现出了很强的性能。
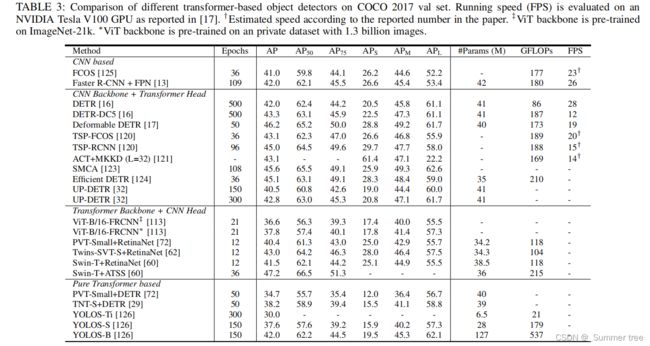
Transformer-based Set Prediction for Detection:
-
DETR: a simple and fully end-to-end object detector, treats the object detection task as an intuitive set prediction problem, eliminating traditional hand-crafted components such as anchor generation and non-maximum suppression (NMS) post-processing.


-
Deformable DETR: deformable attention module attends to a small set of key positions around a reference point rather than looking at all spatial locations on image feature maps as performed by the original multi-head attention mechanism in transformer
该方法大大降低了计算复杂度,具有较快的收敛速度。
可变形注意模块可以很容易地应用于多尺度特征的融合。 -
TSP-FCOS and TSP-RCNN: a new bipartite matching scheme is designed for greater training stability and faster convergence and two transformerbased set prediction models
-
Spatially Modulated Co-Attention (SMCA): to accelerate the convergence by constraining co-attention responses to be high near initially estimated bounding box locations.
-
Adaptive Clustering Transformer (ACT) : to reduce the computation cost of pre-trained DETR. ACT adaptively clusters the query features using a locality sensitivity hashing (LSH) method and broadcasts the attention output to the queries represented by the selected prototypes.
ACT用于替换预训练DETR模型的自我注意模块,而无需进行任何再训练。
Transformer-based Backbone for Detection;
- Fast R-CNN: The input image is divided into several patches and fed into a vision transformer, whose output embedding features are reorganized according to spatial information before passing through a detection head for the final results.
- A massive pretraining transformer backbone could bring benefits to the proposed ViT-FRCNN.
- 也有相当多的方法来探索多功能视觉Transformer主干设计[29],[72],[60],[62],并将这些主干转移到传统的检测框架,如RetinaNet[127]和Cascade R-CNN[128]。例如,Swin Transformer[60]通过ResNet-50骨干网获得4盒AP增益,使用类似的FLOPs用于各种检测框架。
Pre-training for Transformer-based Object Detection.:
- Dai et al. [32] proposed unsupervised pre-training for object detection (UP-DETR). Specifically, a novel unsupervised pretext task named random query patch detection is proposed to pre-train the DETR model.
- UP-DETR still outperforms DETR, demonstrating the effectiveness of the unsupervised pre-training scheme.
- Fang et al. [126] explored how to transfer the pure ViT structure that is pre-trained on ImageNet to the more challenging object detection task and proposed the YOLOS detector.
- the proposed YOLOS first drops the classification tokens in ViT and appends learnable detection tokens. Besides, the bipartite matching loss is utilized to perform set prediction for objects. With this simple pre-training scheme on ImageNet dataset, the proposed YOLOS shows competitive performance for object detection on COCO benchmark.
3.2.2 Segmentation
- panoptic segmentation, 全景分割
- instance segmentation
- semantic segmentation
Transformer for Panoptic Segmentation.
- Wang et al. [25] proposed Max-DeepLab to directly predict panoptic segmentation results with a mask transformer, without involving surrogate sub-tasks such as box detection.
- Max-DeepLab streamlines the panoptic segmentation tasks in an end-to-end fashion and directly predicts a set of nonoverlapping masks and corresponding labels.
- MaxDeepLab adopts a dual-path framework that facilitates combining the CNN and transformer.
Transformer for Instance Segmentation.
- VisTR, a transformerbased video instance segmentation model, was proposed by Wang et al. [33] to produce instance prediction results from a sequence of input images. A strategy for matching instance sequence is proposed to assign the predictions with ground truths. In order to obtain the mask sequence for each instance, VisTR utilizes the instance sequence segmentation module to accumulate the mask features from multiple frames and segment the mask sequence with a 3D CNN.
- Hu et al. [130] proposed an instance segmentation Transformer (ISTR) to predict low-dimensional mask embeddings, and match them with ground truth for the set loss. ISTR conducted detection and segmentation with a recurrent refinement strategy which is different from the existing top-down and bottom-up frameworks.
Transformer for Semantic Segmentation.
- Zheng et al. [18] proposed a transformer-based semantic segmentation network (SETR). SETR utilizes an encoder similar to ViT [15] as the encoder to extract features from an input image. A multi-level feature aggregation module is adopted for performing pixel-wise segmentation.
- Strudel et al. [134] introduced Segmenter which relies on the output embedding corresponding to image patches and obtains class labels with a point-wise linear decoder or a mask transformer decoder.
- Xie et al. [135] proposed a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with lightweight multilayer perception (MLP) decoders, which outputs multiscale features and avoids complex decoders.
Transformer for Medical Image Segmentation.
- .Cao et al. [30] proposed an Unet-like pure Transformer for medical image segmentation, by feeding the tokenized image patches into the Transformer-based U-shaped Encoder-Decoder architecture with skip-connections for local-global semantic feature learning.
- Valanarasu et al. [136] explored transformer-based solutions and study the feasibility of using transformer-based network architectures for medical image segmentation tasks and proposed a Gated Axial-Attention model which extends the existing architectures by introducing an additional control mechanism in the self-attention module.
3.2.3 Pose Estimation
Transformer for Hand Pose Estimation.
- Huang et al. [34] proposed a transformer based network for 3D hand pose estimation from point sets.
- The encoder first utilizes a PointNet [138] to extract point-wise features from input point clouds and then adopts standard multi-head self-attention module to produce embeddings.
- a feature extractor such as PointNet++ [139] is used to extract hand joint-wise features, which are then fed into the decoder as positional encodings.
- Huang et al. [35] proposed HOT-Net (short for hand-object transformer network) for 3D hand-object pose estimation.
- HOT-Net uses a ResNet to generate initial 2D hand-object pose and then feeds it into a transformer to predict the 3D hand-object pose.
- A spectral graph convolution network is therefore used to extract input embeddings for the encoder.
- Hampali et al. [140] proposed to estimate the 3D poses of two hands given a single color image.
- appearance and spatial encodings of a set of potential 2D locations for the joints of both hands were inputted to a transformer, and the attention mechanisms were used to sort out the correct configuration of the joints and outputted the 3D poses of both hands.
Transformer for Human Pose Estimation.
- Lin et al. [36] proposed a mesh transformer (METRO) for predicting 3D human pose and mesh from a single RGB image.
- METRO extracts image features via a CNN and then perform position encoding by concatenating a template human mesh to the image feature.
- A multi-layer transformer encoder with progressive dimensionality reduction is proposed to gradually reduce the embedding dimensions and finally produce 3D coordinates of human joint and mesh vertices.
- METRO randomly mask some input queries during training
- Yang et al. [117] constructed an explainable model named TransPose based on Transformer architecture and low-level convolutional blocks.
- The attention layers built in Transformer can capture long-range spatial relationships between keypoints and explain what dependencies the predicted keypoints locations highly rely on
- Li et al. [141] proposed a novel approach based on Token representation for human Pose estimation (TokenPose).
- Mao et al. [142] proposed a human pose estimation framework that solved the task in the regression-based fashion.
- Jiang et al. [143] proposed a novel transformer based network that can learn a distribution over both pose and motion in an unsupervised fashion rather than tracking body parts and trying to temporally smooth them.
- Hao et al. [144] proposed to personalize a human pose estimator given a set of test images of a person without using any manual annotations
3.2.4 Other Tasks
Pedestrian Detection.
- Endto-end Detector (PED): employs a new decoder called Dense Queries and Rectified Attention field (DQRF) to support dense queries and alleviate the noisy or narrow attention field of the queries.
- They also proposed V-Match, which achieves additional performance improvements by fully leveraging visible annotations.
Lane Detection
- LSTR: improves performance of curve lane detection by learning the global context with a transformer network.
- LSTR regards lane detection as a task of fitting lanes with polynomials and uses neural networks to predict the parameters of polynomials.
- Liu et al. [147] utilized a transformer encoder structure for more efficient context feature extraction.
Scene Graph. :
Scene graph is a structured representation of a scene that can clearly express the objects, attributes, and relationships between objects in the scene [148].
- Graph R-CNN [149] utilizes self-attention to integrate contextual information from neighboring nodes in the graph.
- Sharifzadeh et al. [150] employed transformers over the extracted object embedding.
- Sharifzadeh et al. [151] proposed a new pipeline called Texema and employed a pre-trained Text-to-Text
Transfer Transformer (T5) [152] to create structured graphs from textual input and utilized them to improve the relational reasoning module.
Tracking.
such as TMT [153], TrTr [154] and TransT [155]. All these work use a Siamese-like tracking pipeline to do video object tracking and utilize the encoder-decoder network to replace explicit cross-correlation operation for global and rich contextual inter-dependencies.
the transformer encoder and decoder are assigned to the template branch and the searching branch, respectively.
- Sun et al. proposed TransTrack [156], which is an online joint-detection-and-tracking pipeline.
Re-Identification.
- He et al. [157] proposed TransReID to investigate the application of pure transformers in the field of object re-identification (ReID)
- Both Liu et al. [158] and Zhang et al. [159] provided solutions for introducing transformer network into video-based person Re-ID
Point Cloud Learning.
- Guo et al. [161] proposed a novel framework that replaces the original selfattention module with a more suitable offset-attention module, which includes implicit Laplace operator and normalization refinement.
- Zhao et al. [162] designed a novel transformer architecture called Point Transformer.
3.2.5 Discussions
- The key issues that need to be resolved before transformer can be adopted for high-level tasks relate to input embedding, position encoding, and prediction loss.
- Nevertheless, exploration into the use of transformers for high-level vision tasks is still in the preliminary stages and so further research may prove beneficial.
3.3 Low-level Vision
These tasks often take images as outputs (e.g., high-resolution or denoised images), which is more challenging than high-level vision tasks
3.3.1 Image Generation

as shown in Figure 9 (a). Jiang et al. [38] proposed TransGAN, which build GAN using the transformer architecture.
- Kwonjoon Lee et al. [163] proposed ViTGAN, which introduce several technique to both generator and discriminator to stabilize the training procedure and convergence.
- ViTGAN is the first work to demonstrate transformer-based GANs can achieve comparable performance to state-of-the-art CNN-based GANs.
- Parmar et al. [27] proposed Image Transformer, taking the first step toward generalizing the transformer model to formulate image translation and generation tasks in an auto-regressive manner
Image Transformer consists of two parts:
- an encoder for extracting image representation
- a decoder to generate pixels.
- Esser et al. [37] proposed Taming Transformer. Taming Transformer consists of two parts: a VQGAN and a transformer. VQGAN is a variant of VQVAE [164], which uses a discriminator and perceptual loss to improve the visual quality.
- DALL·E [41] proposed the transformer model for text-to-image generation, which synthesizes images according to the given captions.
- The whole framework consists of two stages.
- In the first stage, a discrete VAE is utilized to learn the visual codebook.
- In the second stage, the text is decoded by BPE-encode and the corresponding image is decoded by dVAE learned in the first stage.
- Then an autoregression transformer is used to learn the prior between the encoded text and image.
3.3.2 Image Processing
- Yang et al. [39] proposed Texture Transformer Network for Image Super-Resolution (TTSR), using the transformer architecture in the reference-based image super-resolution problem.
- Chen et al. [19] proposed Image Processing Transformer (IPT), which fully utilizes the advantages of transformers by using large pre-training datasets.
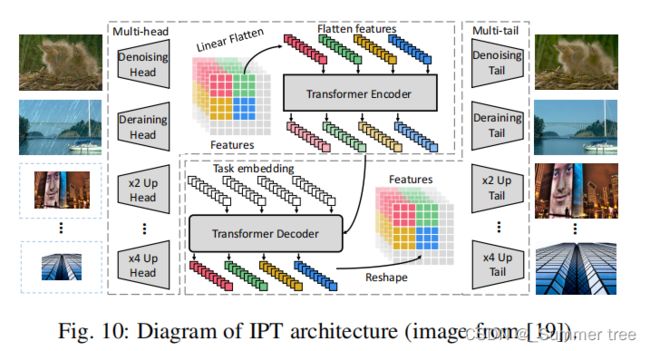
- Wang et al. [165] proposed SceneFormer to utilize transformer in 3D indoor scene generation. By treating a scene as a sequence of objects, the transformer decoder can be used to predict series of objects and their location, category, and size.

3.4 Video Processing
3.4.1 High-level Video Processing
Video Action Recognition.
- . Rohit et al. proposed the action transformer [167] to model the underlying relationship between the human of interest and the surrounding context.
- the I3D [169] is used as the backbone to extract highlevel feature maps.
- Lohit et al. [170] proposed an interpretable differentiable module, named temporal transformer network, to reduce the intra-class variance and increase the inter-class variance.
- Fayyaz and Gall proposed a temporal transformer [171] to perform action recognition tasks under weakly supervised settings.
- Gavrilyuk et al. proposed an actor-transformer [173] architecture to learn the representation, using the static and dynamic representations generated by the 2D and 3D networks as input.
Video Retrieval.
- Shao et al. [174] suggested using the transformer to model the long-range semantic dependency.
- Gabeur et al. [175] presented a multi-modal transformer to learn different cross-modal cues in order to represent videos.
Video Object Detection.
- Chen et al. introduced the memory enhanced global-local aggregation (MEGA) [176] to capture more content.
- Yin et al. [177] proposed a spatiotemporal transformer to aggregate spatial and temporal information.
Together with another spatial feature encoding component, these two components perform well on 3D video object detection tasks.
Multi-task Learning.
- Seong et al. proposed the video multi-task transformer network [178], which handles multi-task learning on untrimmed videos.
3.4.2 Low-level Video Processing
Frame/Video Synthesis.
- Liu et al. proposed the ConvTransformer [166], which is comprised of five components: feature embedding, position encoding, encoder, query decoder, and the synthesis feed-forward network.
- Compared with LSTM based works, the ConvTransformer achieves superior results with a more parallelizable architecture
- Another transformer-based approach was proposed by Schatz et al. [179], which uses a recurrent transformer network to synthetize human actions from novel views.
Video Inpainting : Video inpainting tasks involve completing any missing regions within a frame.
- Zeng et al. proposed a spatial-temporal transformer network [28], which uses all the input frames as input and fills them in parallel.
- The spatial-temporal adversarial loss is used to optimize the transformer network.
3.4.3 Discussions
3.5 Multi-Modal Tasks
多模式任务(例如,视频-文本、图像-文本和音频-文本)
-
VideoBERT [180], which uses a CNNbased module to pre-process videos in order to obtain representation tokens. A transformer encoder is then trained on these tokens to learn the video-text representations for downstream tasks, such as video caption
-
VisualBERT [181] and VL-BERT [182], which adopt a single-stream unified transformer to capture visual elements and image-text relationship for downstream tasks such as visual question answering (VQA) and visual commonsense reasoning (VCR)
-
SpeechBERT [183] explore the possibility of encoding audio and text pairs with a transformer encoder to process autotext tasks such as speech question answering (SQA). [183] explore the possibility of encoding audio and text pairs with a transformer encoder to process autotext tasks such as speech question answering (SQA).
-
Contrastive Language-Image Pre-training (CLIP) [40] takes natural language as supervision to learn more efficient image representation.

-
DALL-E [41] synthesizes new images of categories described in an input text.
-
Ding et al. proposes CogView [42], which is a transformer with VQ-VAE tokenizer similar to DALL-E, but supports Chinese text input.
-
Unified Transformer (UniT) [43] model is proposed to cope with multi-modal multi-task learning, which can simultaneously handle multiple tasks across different domains, including object detection, natural language understanding and vision-language reasoning.
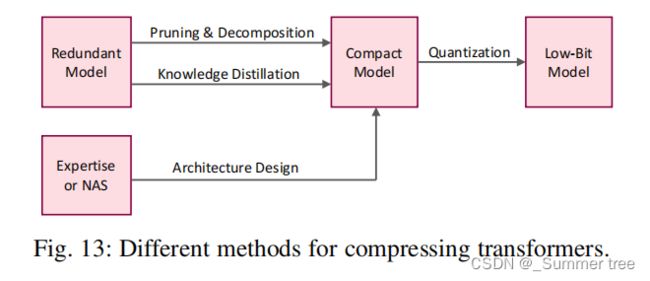
3.6 Efficient Transformer
we review the researches carried out into compressing and accelerating transformer models for efficient implementation.
This includes including:
- network pruning, 网络裁剪
- low-rank decomposition, 低秩分解
- knowledge distillation,
- network quantization,
- compact architecture design. 紧凑架构设计
Table 4 lists some representative works for compressing transformer-based models.

3.6.1 Pruning and Decomposition
- Michel et al. [44] presented empirical evidence that a large percentage of attention heads can be removed at test time without impacting performance significantly.
- Dalvi et al. [184] analyzed the redundancy in pre-trained transformer models from two perspectives:
- general redundancy
- task-specific redundancy.
- Prasanna et al. [184] analyzed the lotteries in BERT and showed that good sub-networks also exist in transformer-based models, reducing both the FFN layers and attention heads in order to achieve high compression rates.
- vision transformer [15] which splits an image to multiple patches,
- Tang et al. [186] proposed to reduce patch calculation to accelerate the inference, and the redundant patches can be automatically discovered by considering their contributions to the effective output features.
- Zhu et al. [187] extended the network slimming approach [188] to vision transformers for reducing the dimensions of linear projections in both FFN and attention modules.
- Fan et al. [198] proposed a layer-wisely dropping strategy to regularize the training of models, and then the whole layers are removed together at the test phase
- Wang et al. [200] decomposed the standard matrix multiplication in transformer models, improving the inference efficiency.
3.6.2 Knowledge Distillation
Knowledge distillation aims to train student networks by transferring knowledge from large teacher networks [201], [202], [203].
- Mukherjee et al. [204] used the pre-trained BERT [10] as a teacher to guide the training of small models, leveraging large amounts of unlabeled data.
- Wang et al. [205] train the student networks to mimic the output of self-attention layers in the pre-trained teacher models.
- . A teacher’s assistant [206] is also introduced in [205], reducing the gap between large pre-trained transformer models and compact student networks, thereby facilitating the mimicking process.
- Jiao et al. [45] design different objective functions to transfer knowledge from teachers to students.
- Jia et al. [207] proposed a finegrained manifold distillation method, which excavates effective knowledge through the relationship between images and the divided patches.
3.6.3 Quantization
Quantization aims to reduce the number of bits needed to represent network weight or intermediate features [208], [209]. Quantization methods for general neural networks have been discussed at length and achieve performance on par with the original networks [210],
[211], [212].
- Shridhar et al. [215] suggested embedding the input into binary high-dimensional vectors, and then using the binary input representation to train the binary neural networks.
- Cheong et al. [216] represented the weights in the transformer models by low-bit (e.g., 4-bit) representation
- Zhao et al. [217] empirically investigated various quantization methods and showed that kmeans quantization has a huge development potential.
- Prato et al. [46] proposed a fully quantized transformer, which, as the paper claims, is the first 8- bit model not to suffer any loss in translation quality.
- Liu et al. [218] explored a post-training quantization scheme to reduce the memory storage and computational costs of vision transformers.
3.6.4 Compact Architecture Design
-
Jiang et al. [47] simplified the calculation of self-attention by proposing a new module — called spanbased dynamic convolution — that combine the fully-connected layers and the convolutional layers
-
Interesting “hamburger” layers are proposed in [220], using matrix decomposition to substitute the original self-attention layers
-
Su et al. [82] searched patch size and dimensions of linear projections and head number of attention modules to get an efficient vision transformer.
-
Li et al. [223] explored a self-supervised search strategy to get a hybrid architecture composing of both convolutional modules and self-attention modules.
-
Katharopoulos et al. [224] approximated self-attention as a linear dot-product of kernel feature maps and revealed the relationship between tokens via RNNs.
The preceding methods take different approaches in how they attempt to identify redundancy in transformer models (see Figure 13).
4 CONCLUSIONS AND DISCUSSIONS
4.1 Challenges
Although researchers have proposed many transformer-based models to tackle computer vision tasks, these works are only the first steps in this field and still have much room for improvement.
the transformer architecture in ViT [15] follows the standard transformer for NLP [9], but an improved version specifically designed for CV remains to be explored.
The generalization and robustness of transformers for computer vision are also challenging.
- Compared with CNNs, pure transformers lack some inductive biases and rely heavily on massive datasets for large-scale training [15].
- the quality of data has a significant influence on the generalization and robustness of transformers
- There is still a long way to go in order to better generalize pre-trained transformers on more generalized visual tasks.
- Although the robustness has been investigated in [232], [233], [234], it is still an open problem waiting to be solved.
- it remains a challenging subject to clearly explain why transformer works well on visual tasks.
- Position embeddings are added into image patches to retain positional information, which is important in computer vision tasks.
- developing efficient transformer models for CV remains an open problem.
- Although several methods have been proposed to compress transformer, they remain highly complex.
- Consequently, efficient transformer models are urgently needed so that vision transformer can be deployed on resource-limited devices.
4.2 Future Prospects
- One direction is the effectiveness and the efficiency of transformers in computer vision.
- The goal is to develop highly effective and efficient vision transformers;
- transformers with high performance and low resource cost.
- The effectiveness is usually correlated with the efficiency, so determining how to achieve a better balance between them is a meaningful topic for future study
- Most of the existing vision transformer models are designed to handle only a single task.
- We believe that more tasks can be involved in only one model. Unifying all visual tasks and even other tasks in one transformer (i.e., a grand unified model) is an exciting topic.
- CNNs perform well on small datasets, whereas transformers perform better on large datasets. The question for the future is whether to use CNN or transformer
- By training with large datasets, transformers can achieve stateof-the-art performance on both NLP [11], [10] and CV benchmarks [15]. It is possible that neural networks need big data rather than inductive bias.
- Can transformer obtains satisfactory results with a very simple computational paradigm (e.g., with only fully connected layers) and massive data training?