基于深度学习的SDN家庭网关加密网络流量分类
写在前面:
本文翻译供个人研究学习之用,不保证严谨与准确
github链接:https://github.com/WithHades/network_traffic_classification_paper
本文原文:Wang, P., Ye, F., Chen, X., & Qian, Y. (2018). Datanet: Deep learning based encrypted network traffic classification in SDN home gateway. IEEE Access, 6, 55380–55391. https://doi.org/10.1109/ACCESS.2018.2872430
基于深度学习的SDN家庭网关加密网络流量分类
- 基于深度学习的SDN家庭网关加密网络流量分类
-
- I. 介绍
- II. 相关工作
- III. 应用感知SDN家庭网关框架综述
- IV. 数据包预处理
-
- A. 预处理包字节向量
- B. 预处理数据包字节矩阵
- V. 基于深度学习的加密数据分类器(DATANET)设计
-
- A. 基于MLP的数据网
- B. 基于数据网的SAE
- C. 基于数据网的CNN
- VI. 评估和实验结果
-
- A. 实验设置
- B. 创建数据网
- C. 数据网分类精度
- D. 计算性能
- VII. 总结
基于深度学习的SDN家庭网关加密网络流量分类
摘要
智能家庭网络将支持各种智能设备和应用,例如家庭自动化设备、电子健康设备、常规计算设备等。智能家庭中的大多数设备通过家庭网关(HGW)访问互联网。本文提出了一个软件定义网络(SDN)HGW框架,用于更好地管理分布式智能家庭网络,支持SDN控制核心网络。SDN控制器基于核心网的实时流量监控和资源分配,实现高效的网络服务质量管理。然而,它不能在分布式智能家庭中提供网络管理。我们提出的SDN-HGW将控制扩展到接入网络,即智能家庭网络,以实现更好的端到端网络管理。具体地说,提出的SDN-HGW可以通过对智能家庭网络中的数据流量进行分类来实现分布式应用感知。大多数现有的流量分类解决方案,例如深度包检查,无法为加密数据流量提供实时应用程序感知。为了解决这些问题,我们开发了基于三种深度学习方案的加密数据分类器(称为数据网),即多层感知器、叠层自动编码器和卷积神经网络,使用一个开放数据集,它有来自15个应用程序的超过200000个加密数据样本。提出了一种数据预处理方案,对原始数据包和测试数据集进行处理,从而建立数据网。实验结果表明,所开发的数据网可以应用于未来智能家庭网络中的分布式应用感知SDN-HGW。
关键词: 加密流量分类,家庭网关,分布式网络管理,深度学习,SDN
I. 介绍
智能家庭有一个支持各种智能设备的网络,包括家庭自动化、医疗保健和娱乐[1]、[2]。这些智能设备由网络运营商、服务提供商和家庭用户独立操作和管理。由于不同的网络服务质量(QoS)要求,为智能家庭用户提供高效的端到端网络管理具有挑战性[3],[4]。在本文中,我们提出了一种适用于分布式智能家庭网络的应用感知软件定义网络(SDN)家庭网关框架(SDN-HGW)。
SDN是一种新兴的、有前途的网络模式,它可以极大地简化网络管理,提高网络资源利用率,降低运营成本,促进创新和发展[5],[6]。目前SDN控制着核心网络的QoS监控和管理[7],[8]。但是,由于应用程序和最终用户的QoS要求不同,以及安全和隐私问题,SDN控制器可能无法管理端到端网络QoS。
此外,基于核心网络控制器的解决方案通常需要相对较高的计算资源[9],[10]。智能家庭网络中的QoS管理需要一种轻量级的分布式方案来实现本地实时应用感知。为了解决这个问题,我们提出的SDN-HGW框架利用了SDN的概念,在计算资源方面具有高级控制和灵活性[11]–[16]。
为了保护用户隐私,许多应用程序都应用了安全协议,如HTTPS、SSH、SSL等[17]、[18]。现有的应用软件解决方案大多是基于数据包检测(DPI)和机器学习(ML)。然而,这些解决方案无法提供准确的实时流量分类加密网络应用程序[19]-[22]。在这项工作中,我们使用三种方法来设计和开发数据网(即加密数据包分类器):多层感知器(MLP)、叠层自动编码器(SAE)和卷积神经网络(CNN),基于从“ISCX-VPN-nonVPN”加密流量数据集中选择的数据集[23]。作为概念上的证明,所选数据集包含来自15种应用程序的20000多个数据包。实验结果表明,所开发的数据网能够为分布式家庭网络中的SDN-HGW提供实时、细粒度的应用感知。这项工作的主要贡献总结如下:
- 提出了一种适用于智能家庭网络的应用感知SDN-HGW框架。
- 数据网是使用三种基于深度学习的方法开发的,用于基于开放数据集的加密数据分类。
- 实验证明了所开发数据网的准确性。并用实际的HGW设置对计算效率进行了评估。
论文的其余部分安排如下。相关工作在第II节讨论。第III节说明了所提出的应用感知SDN-HGW框架,第IV节给出了数据预处理方案,第V节描述了数据网的核心开发。第VI节给出了评价和实验结果。最后,第VII节给出了结论和今后的工作。
II. 相关工作
SDN是一种新的网络模式,它通过分离控制和数据平面化来实现网络基础设施虚拟化,从而创建一个动态、灵活、自动化和可管理的体系结构[1],[5]。核心网中的SDN控制器是整个SDN体系结构的关键组成部分,它主要控制SDN交换机来管理整个数据流[1],[24]。SDN控制器实现了高效的流量控制,但由于没有对终端用户的控制,无法实现分布式的端到端QoS管理。
流量分类已经在网络管理领域得到了广泛的研究,主要有三种方法:基于端口的[25]-[27]、统计方法[28]、[29]和基于有效载荷的[21]、[22]、[30]、[31]。基于端口的方法是最早的流量分类方法之一。它使用TCP/UDP报头中的端口与IANA[27]分配的已知TCP/UDP端口号的关联。基于端口的方法简单快速。然而,由于动态端口分配、隧道和网络地址端口转换(NAPT)[25]、[26],并非所有协议都可以按端口分类。统计方法使用与负载无关的参数,如包长度、到达间隔时间、流持续时间等进行分类。例如,DPI是最被接受的技术之一[21]、[22]、[31]。然而,DPI技术在加密有效负载加密、用户隐私方面和隧道运输有局限性。根据统计方法,很多研究者都使用机器学习(ML)算法[29],[32],[33],虽然这种算法可以减轻DPI的一些限制,但是现有的基于流的解决方案不能提供实时性,细粒度流量分类,以支持应用程序感知的智能家庭网络。
最近,研究人员试图将深度学习[34]、[35]应用于流量分类[36]、[37]。Wang[36]提出了一种基于SAE的非加密数据流量识别方法。然而,数据集并没有向公众开放,这项工作也没有展示它在加密流量方面的应用。Lotfulahi等人[37]介绍了基于SAE和CNN的加密流量分类方法,但是,未提供计算性能的评估。
在这项工作中,我们考虑到在社区中受欢迎的程度,使用三种基于深度学习的方法(MLP、SAE和CNN)开发和评估数据网。此外,从具有所有加密数据流量的开放源代码中选择的数据集用于数据网开发。所开发的数据集可以帮助实现SDN模式下的分布式端到端网络测量和网络管理。这项工作的成功将使网络的进一步发展成为可能,例如网络资源管理、新的业务计划等,而不会损害服务提供商或用户的安全/隐私。
III. 应用感知SDN家庭网关框架综述
图1显示了所提出的SDN-HGW框架的概述。该框架旨在对来自SDN-HGW的加密流量提供细粒度和应用程序级的流量分类。该框架由智能家居基础设施、数据平面、控制平面和应用平面组成,如下所述。
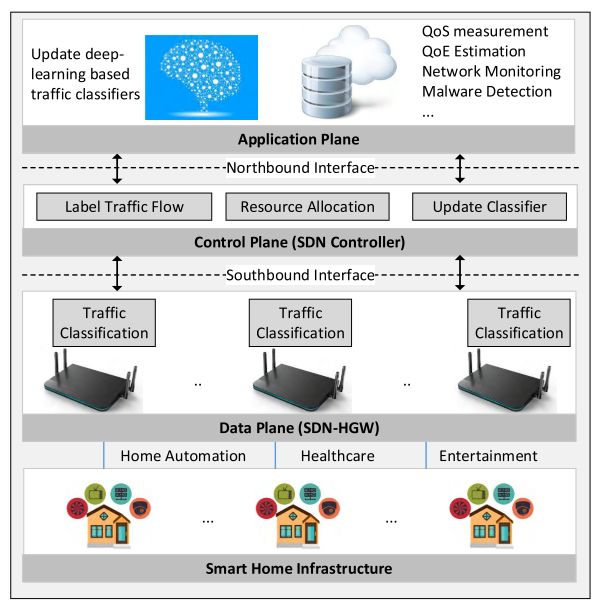
智能家庭基础设施由家庭网络中的智能设备组成。智能设备一般可分为三类:家庭自动化、医疗保健和娱乐[2]。所有智能设备通过SDN-HGW接入外部网络(如互联网)。
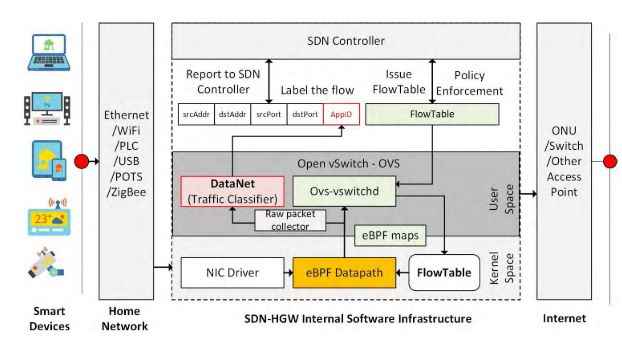
数据平面位于SDN-HGW,为最后一跳提供分布式网络QoS管理,以满足不同的应用需求。如图2所示,所提出的SDN-HGW不仅通过南边的接口,同时也可以作为智能家庭网络中流量识别的探针。首先,探测器将从原始数据包采集器接收数据包,原始数据包采集器可以是一个eBPF程序,专注于从eBPF数据路径捕获数据包[38]。其次,探针使用了一个流量分类器,在该框架中定义为数据网。与现有的SDN控制器设计不同,DataNet需要在下一代网络网关中嵌入一个本地人工智能(或神经网络)协处理器。结果将被标记为SDN控制器的AppID,以便进一步进行网络管理。请注意,建议的SDN-HGW可以收集SDN控制器或核心网络可能难以收集的边缘业务流。例如,某些包(如ARP、DNS、DHCP等)可能仅在边缘网络网关处可见[24]。
SDN控制器支持控制平面执行三项任务。首先,它用每个SDN-HGW的探测结果标记每个数据流。其次,SDN控制器定期更新数据网,并将最新的分类器下载到每个SDN-HGW。第三,SDN控制器基于核心网络中准确标记的业务流来管理网络资源。
应用程序平面通过与SDN控制器的北向接口支持应用程序。特别是在应用层部署了一个基于深度学习的训练平台。该平台负责根据从各种网络应用程序收集的数据样本创建和更新数据网。请注意,与SDN-HGW相比,训练平台具有更强大的计算资源,可以快速、准确地开发数据网。
IV. 数据包预处理
数据网是SDN-HGW框架的核心。然而,捕获的原始数据包不是理想的数据网处理(和开发)形式。例如,本工作中使用的数据包是PCAP或PCAPNG格式的[39]。原始数据包包括分类不需要的信息,例如TCP/UDP/ICMP的总数等。在本节中,我们将介绍预处理原始数据包和原始数据集的过程,以便在训练平台上创建数据网,并在每个SDN-HGW上探测数据包。
A. 预处理包字节向量
原始数据包的预处理包括三个步骤:解析、截断/填充和规范化。预处理过程的概述如图3所示。原始数据包是逐字节处理的,类似于图像的像素,可以很容易地导入到基于深度学习的分类器中。解析是删除原始数据包的以太网头。诸如MAC地址、帧类型等数据链路层信息,其在分组分类中没有用处。解析过程减少了数据包的输入大小。此外,为了提高分类精度,在分类过程中对噪声进行了滤除。
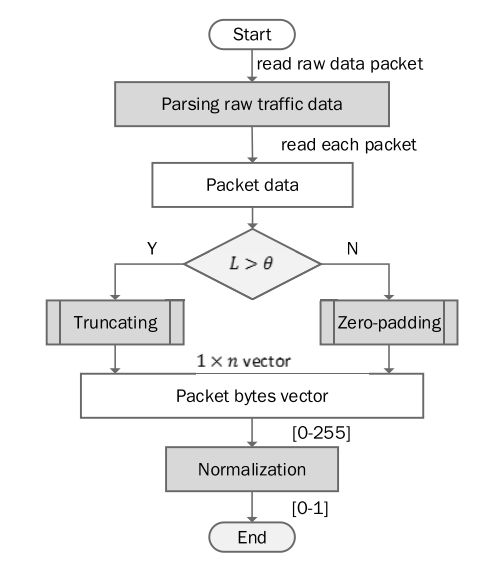
截断和零填充是为了固定输入到分类器的每个数据包的大小。所提出的基于深度学习的分类器要求所有输入的大小相等。特别是,将n定义为DataNet的目标输入大小,其中0 < n < 1500。最大传输单元的大小为1500字节。输入包被截断或填充为零,这取决于它与n相比的长度。
经过截断和零填充的输入被定义为包字节向量(PBV)。例如,第i-th PBV描述如下:
X i = { x i 1 , x i 2 , x i 3 , . . . , x i n } (1) X_i = \{x_{i1}, x_{i2}, x_{i3}, ..., x_{in}\}\tag{1} Xi={xi1,xi2,xi3,...,xin}(1)
其中 x i j x_{ij} xij是 X i X_i Xi的第j个字节。为了更快的分类,每次PBV被正则化为[0, 1],为了简单起见,我们假设 X i X_i Xi是第i个PBV的规范化结果。数据包的分类使用规范化的PBV进行处理。
B. 预处理数据包字节矩阵
为了创建数据网,在图4所示的步骤中处理带有标记的原始数据包的数据集。
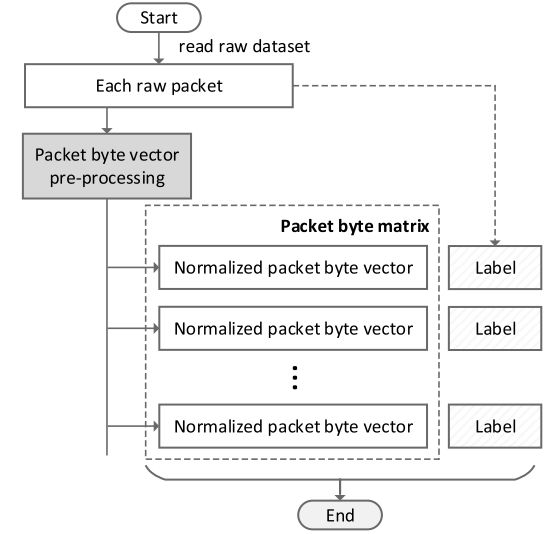
原始数据集被处理成包字节矩阵(PBM)X,如下所示:
X = { X 1 T , X 2 T , X 3 T , . . . , X m T } (2) X = \{X_1^T, X_2^T, X_3^T, ..., X_m^T\}\tag{2} X={X1T,X2T,X3T,...,XmT}(2)
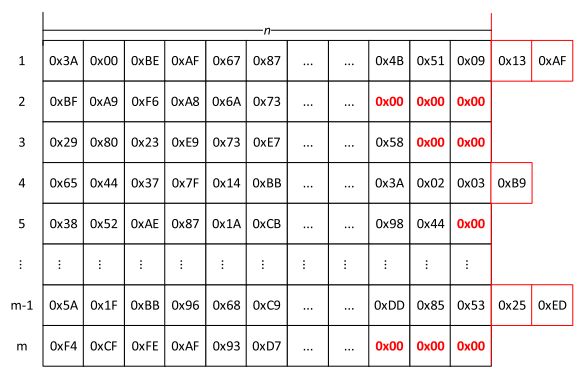
( . ) T (.)^T (.)T是转置函数,m是数据集中原始数据包的数量。图5是一个PBM的图解。
每个PBV X i X_i Xi和标签 L i L_i Li相关,比如AIM、电子邮件、Netflix等。预处理之后,原始数据集由一个PBM和一个标签向量组成,如下所示:
X = [ X 1 X 2 . . . X m ] ⟵ [ L 1 L 2 . . . L m ] (3) X = \begin{bmatrix}X_1\\X_2\\...\\X_m\end{bmatrix}\longleftarrow\begin{bmatrix}L_1\\L_2\\...\\L_m\end{bmatrix}\tag{3} X=⎣⎢⎢⎡X1X2...Xm⎦⎥⎥⎤⟵⎣⎢⎢⎡L1L2...Lm⎦⎥⎥⎤(3)
标签PBM的示例如表1所示。由于即使对于同一类应用程序,数据的维度也会有所不同,因此固定大小的应用程序将有助于在将来向系统中添加更多的应用程序,从而简化维护和更新。在不失概括性的前提下,本文选择1480作为其余部分。

V. 基于深度学习的加密数据分类器(DATANET)设计
预处理后,应用X创建数据网,即加密数据包分类器。特别地,我们分别开发了三种基于多层感知器(MLP)、叠层自动编码器(SAE)和卷积神经网络(CNN)的数据网络。
A. 基于MLP的数据网
MLP是一类前向人工神经网络(ANN),如图6所示。MLP由三层或更多层组成。第一层用于输入数据,即PBV X i X_i Xi。一个或多个隐藏层从输入中提取特征。最后一层输出分类结果。每个隐藏层,例如第i层,由多个神经元组成,这些神经元主要是非线性激活函数,如下所示:
f ( x ) = σ ( W ( i ) ⋅ x + b ( i ) ) (4) f(x) = \sigma(W^{(i)}\cdot x + b^{(i)})\tag{4} f(x)=σ(W(i)⋅x+b(i))(4)
σ ( ⋅ ) \sigma(\cdot) σ(⋅)是一个激活函数,例如 σ ( x ) = t a n h ( x ) \sigma(x) = tanh(x) σ(x)=tanh(x)激活函数的重要特征是,当输入值改变时,它提供平滑的转换。 W ( i ) W^{(i)} W(i)是一个权重矩阵, b ( i ) b^{(i)} b(i)是一个偏置向量。可能有多个隐藏层。每一层通过一个具有不同的权重矩阵和偏移向量的同一个函数。最后一层输出最后一个隐藏层的结果,如下所示:
o ( x ) = g ( W ( j ) ⋅ x + b ( j ) ) (5) o(x) = g(W^{(j)}\cdot x + b^{(j)})\tag{5} o(x)=g(W(j)⋅x+b(j))(5)
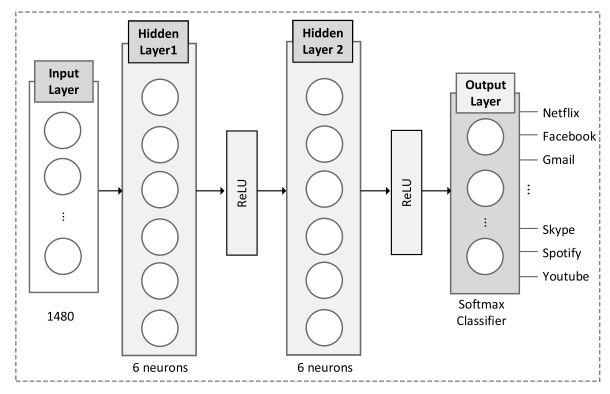
为所提出的分组分类器指定的MLP结构如图6所示。它由一个输入层、两个隐藏层和一个输出层组成。以数据包的全尺寸为例,输入层具有1480个输入。两个隐层分别由6个和6个神经元组成。输出层由15个神经元组成,以Softmax为分类器。分类过程定义如下:
- 向第一层输入PBV X i = { x i 1 , x i 2 , . . . , x i n } X_i = \{x_{i1}, x_{i2}, ..., x_{in}\} Xi={xi1,xi2,...,xin}并且采用下列公式计算输出:
z ( 1 ) = W ( 1 ) σ ( X i ) + b ( 1 ) (6) z^{(1)} = W^{(1)}\sigma(X_i) + b^{(1)}\tag{6} z(1)=W(1)σ(Xi)+b(1)(6)
σ ( ⋅ ) \sigma(\cdot) σ(⋅)是ReLU函数:
R e L U ( x ) = m a x [ 0 , x ] (7) ReLU(x) = max[0, x]\tag{7} ReLU(x)=max[0,x](7) - 对于第二个隐藏层,计算输出如下:
z ( 2 ) = W ( 2 ) σ ( z ( 1 ) ) + b ( 2 ) (8) z^{(2)} = W^{(2)}\sigma(z^{(1)}) + b^{(2)}\tag{8} z(2)=W(2)σ(z(1))+b(2)(8) - softmax形式的全连接层输出最后的结果:
y ^ = e x p ( z j ) ∑ e x p ( z i ) (9) \hat{y} = \frac{exp(z^j)}{\sum exp(z^i)}\tag{9} y^=∑exp(zi)exp(zj)(9)
z j z^j zj是第j个神经元的输出, y ^ = { y 1 ^ , y 2 ^ , y 3 ^ , . . . . . . , y N ^ } \hat{y} = \{\hat{y_1}, \hat{y_2}, \hat{y_3}, ......, \hat{y_N}\} y^={y1^,y2^,y3^,......,yN^},N是类别总数,概率最高的输出表示输入值的类别。
在我们的MLP模型中,我们使用交叉熵作为损失函数,梯度的计算以及权值和偏差的更新定义如下:
- 计算输出值和标签值之间的交叉点函数,如下所示:
L = − ∑ i = 1 n y i l n f ( x i , θ ) (10) L = -\sum_{i=1}^ny_ilnf(x_i, \theta)\tag{10} L=−i=1∑nyilnf(xi,θ)(10) - 使用下面的梯度下降法更新权重和偏置:
w ← w − η ∂ L ∂ w w \leftarrow w - \eta \frac{\partial L}{\partial w} w←w−η∂w∂L
b ← b − η ∂ L ∂ b (11) b \leftarrow b - \eta \frac{\partial L}{\partial b}\tag{11} b←b−η∂b∂L(11)
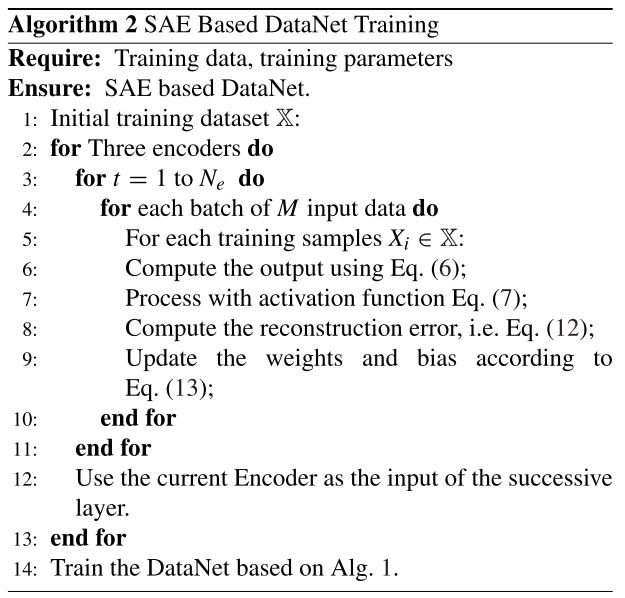
在训练过程中,训练参数设为 { N e , M , η } \{N_e,M,\eta\} {Ne,M,η},其中 N e N_e Ne是最大epoch,M是小批量随机梯度法的大小, η \eta η是学习率。算法1总结了训练的完整过程。在不丧失通用性的前提下,算法只总结了过程的基本结构。说明中未给出验证等停止条件。

B. 基于数据网的SAE
我们提出了一种基于叠层自动编码器(SAE)[40]的分类器方法,该方法通常用于降维或特征提取。通常,自动编码器用于自动特征提取。如图7所示,所提出的SAE架构由五层,分别是输入、三个编码器和输出层组成。输入层的大小为1480,三个编码器的大小分别为740、92和32个神经元。

分类过程定义如下:
- 1480个神经元的PBV X i = { x i 1 , x i 2 , . . . , x i n } X_i = \{x_{i1}, x_{i2}, ..., x_{in}\} Xi={xi1,xi2,...,xin}输入到第一层隐藏层和具有740个神经元的编码器1,使用式(6)计算输出。
- 根据式(7)激活ReLU后,结果作为输入到第二隐藏层和有92个神经元的编码器2,使用式(8)。
- 与上述相同,激活ReLU后,将结果作为输入到第三隐藏层,编码器3有32个神经元。
- 带有Softmax分类器的完全连接层将最终结果输出为公式(9)。
分类器的训练过程分为两步:训练编码器、训练分类器。如图8所示,三个编码器以贪婪的分层方式进行训练[41]。训练编码器1的过程描述如下:
- 输入PBV X i = { x i 1 , x i 2 , . . . , x i n } X_i = \{x_{i1}, x_{i2}, ..., x_{in}\} Xi={xi1,xi2,...,xin},n = 1480。采用式(6)计算输出,通过式(7)的激活函数计算这个过程的输出。
- 在ReLU激活函数之后,结果作为输出传到输出层(具有1480个神经元的解码器1),使用式(8)和式(7)计算输出。
- 使用均方误差计算输入和输出之间的重建误差,如下所示:
ε ( k ) = 1 m ∑ i = 1 m e j 2 ( k ) (12) \varepsilon (k) = \frac{1}{m}\sum_{i=1}^me_j^2(k)\tag{12} ε(k)=m1i=1∑mej2(k)(12)
其中, e j ( k ) = y ^ j ( k ) − y j ( k ) e_j(k) = \hat{y}_j(k) - y_j(k) ej(k)=y^j(k)−yj(k)是输出和目标值的错误率,m是样本的数量。 - 基于最小均方算法,通过反向传播更新权重矩阵。

更新权重如下:
Δ w j ( i ) = − η ∂ ε ( k ) ∂ z j ( k ) z i ( k ) (13) \Delta w_j(i) = -\eta\frac{\partial\varepsilon(k)}{\partial z_j(k)}z_i(k)\tag{13} Δwj(i)=−η∂zj(k)∂ε(k)zi(k)(13)
z i z_i zi是上一层神经元的输出, η \eta η是学习率。
编码器1是后续层的输入,以类似的方式训练编码器2,其中每层的大小被更新为目标大小。编码器3以编码器2作为输入进行训练。
在基于SAE的数据网训练的第二步中,最后一个分类器可以采用给出了三个编码器的算法1进行训练。注意,输入的大小是32,而不是1480。算法2总结了基于SAE的数据网的完整训练过程。训练参数为 { N e , M , η } \{N_e,M,\eta\} {Ne,M,η},其中 N e N_e Ne是最大epoch,M是小批量梯度下降法的大小, η \eta η是学习率。
C. 基于数据网的CNN
我们开发了基于CNN[42]的加密分组分类器。CNN是一种典型的应用于分类的深度学习网络。与典型的深层神经网络(如人工神经网络)不同,CNN应用函数卷积,如下所示:
y ( t ) = x ( t ) ∗ ω ( t ) (14) y(t) = x(t) * \omega(t)\tag{14} y(t)=x(t)∗ω(t)(14)
x(t)是输入函数, ω ( t ) \omega(t) ω(t)是核函数。CNN结构由三种类型的层组成:输入层、隐藏层和输出层。计算特性包括局部感受野、共享权重和偏差以及池化层,如下所述:
-
局部感受野
在普通的神经网络中,输入被描绘成一条神经元的垂直线。输入层的神经元为三维的:宽、高以及深度。第l层的每个神经元都与前一层神经元的一个小区域相连。这个小区域叫做局部感受野。我们将局部感受野滑过整个(l-1)层。每一个局部感受野的第l层都有一个不同的神经元。 -
权值共享
从一层到下一层的转换由权重矩阵和偏差定义,例如:
f ( x i , w i , b ) = ∑ i w i x i + b (15) f(x_i, w_i, b) = \sum_i w_ix_i + b\tag{15} f(xi,wi,b)=i∑wixi+b(15)
在CNN中,权值矩阵和偏差通常是针对不同的转换而共享的。共享的权重和偏差通常称为核或滤波器。应用共享权重和偏差的优点是,它大大减少了参数的数量。 -
池化层
池化层是CNN的一个重要组成部分。通常在卷积层之后使用池层来降低卷积结果的维数。同时,池化成将以降维的方式保留大部分信息。池化的一个常见过程是最大池化。在最大池化中,池化单元输出矩形子区域中最大的元素。其他流行的池化过程包括平均池化、二级池化等。
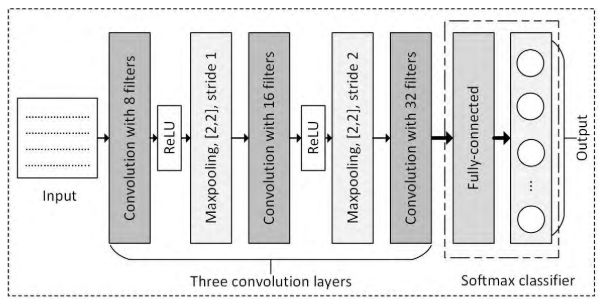
我们提出的分组分类器的CNN结构如图9所示。它由三个卷积层、两个Maxpooling层和一个以Softmax为分类器的全连接层组成。由于输入数据包被转换成二维(2D)矩阵,因此我们将放弃深度并专注于处理2D数据。分类过程定义如下:
1). 第一卷积层用8个滤波器处理输入数据,每个滤波器的大小为[3,3]。每个滤波器在一次卷积运算后移动一步。
2). 卷积层的结果被输入到激活函数,即式(7)。
3). 激活ReLU之后,结果将通过max pooling进行处理。在每个步骤中,最大池按如下方式处理[2,2]输入:
m a x p o o l i n g [ x 1 x 2 x 3 x 4 ] = m a x ( x 1 , x 2 , x 3 , x 4 ) (16) max \quad pooling {x_1\quad x_2 \brack x_3\quad x_4} = max(x_1, x_2, x_3, x_4)\tag{16} maxpooling[x3x4x1x2]=max(x1,x2,x3,x4)(16)
最大池化的步幅为1。
4). 最大池的输出由第二卷积层用16个[3,3]滤波器进行处理。这个层的步长是2。
5). 随后激活ReLU(即等式(7))处理输出。
6). 第二层中的最大池大小为[2,2]和步长为2。
7). 第三卷积层有32个[3,3]滤波器。
8). 带有Softmax分类器的全连接层(即公式(9))输出最终结果。
在模型训练过程中,基于交叉熵定义损失函数,即式(10)。采用随机梯度法求出计算最小损耗的权值和偏差。
开始训练前,训练参数设置为 { N e , M , η , K , S } \{N_e,M,\eta, K, S\} {Ne,M,η,K,S},其中 N e N_e Ne是最大epoch,M是小批量梯度下降法的大小, η \eta η是学习率,K是滤波器数量,S是步幅,完整的训练过程总结如下:

VI. 评估和实验结果
在这一部分中,我们将给出实验结果来评估所提出的数据网的准确性。此外,我们还比较了三个开发的数据网的计算资源需求。
A. 实验设置
- 评估数据集
要评估的数据集是从“ISCX VPN-nonVPN流量数据集”中选择的[23]。如表2所示:
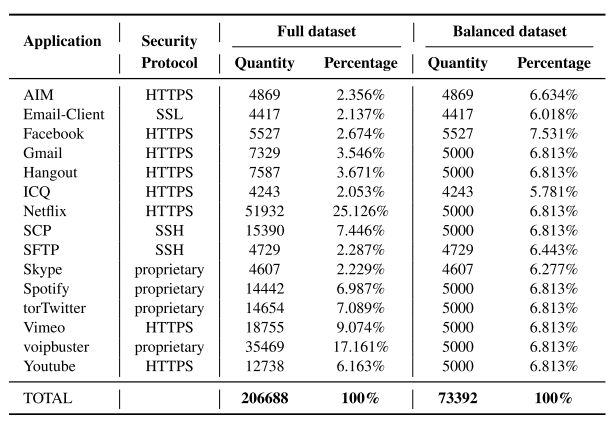
用于评估的数据集由15个应用程序组成,如Facebook、Y outube、Netflix等。所选应用程序使用各种安全协议加密,包括HTTPS、SSL、SSH和专有协议。所选数据集中总共包括206688个数据包。为了减少不平衡数据集[43]的影响,例如Netflix占总数据集的25.126%,我们进一步为每个应用程序创建一个包含更多平衡数据样本的子集。平衡子集共有73392个数据包。它由相同的15个应用程序组成,每个类约占整个子集的6.18%。
-
实验计算平台配置
性能评估使用Thinkpad笔记本电脑进行,该电脑配备2.8GHz的Intel I7-7600U CPU、8GB RAM和通过Thunderbolt 3连接的外部GPU(Nvidia GeForce GTX 1080)。数据预处理基于Python包Scapy[44]来解析PCAP文件。深度学习软件平台建立在Keras库[45]上,后台支持Tensorflow[46](基于GPU的版本1.4.0)。 -
性能指标
用于评估的性能指标包括精确性、召回率和F1-score[47]。- 精确性:精确性 r p r_p rp是真阳性 n T P n_T^P nTP与假阳性 n F P n_F^P nFP之和的比率。在所提出的分类方法中,精度是正确分类的包的百分比。
r P = n T P n T P + n F P (17) r_P = \frac{n_T^P}{n_T^P + n_F^P}\tag{17} rP=nTP+nFPnTP(17) - 召回率:召回率 r C r_C rC是 n P n_P nP与 n T P n_T^P nTP和假阴性 n N P n_N^P nNP的总和之比或应用程序类别中正确识别的数据包的百分比。
r C = n T P n T P + n F N (18) r_C = \frac{n_T^P}{n_T^P + n_F^N}\tag{18} rC=nTP+nFNnTP(18) - F1分数: r f r_f rf是信息检索和分类中广泛使用的一种度量标准,它同时考虑了精度和召回率,如下所示:
r f = 2 r P ⋅ r C r P + r C (19) r_f = \frac{2r_P \cdot r_C}{r_P + r_C}\tag{19} rf=rP+rC2rP⋅rC(19)
为简单起见,本工作中的评估使用全尺寸数据包进行,即每包1480字节。截断/填充的不同设置将在我们以后的工作中进行评估。
- 精确性:精确性 r p r_p rp是真阳性 n T P n_T^P nTP与假阳性 n F P n_F^P nFP之和的比率。在所提出的分类方法中,精度是正确分类的包的百分比。
B. 创建数据网
我们首先创建两组分别从完整数据集和平衡数据集训练的数据网。每组评估由三种方法训练的三个数据网组成,即基于MLP、SAE和CNN的方法。每个训练过程使用60%用于训练,20%用于验证,20%用于测试。对SDH-HGW的分组分类器,共评估了6个数据网的精度。三种方法的设置见表3。

C. 数据网分类精度
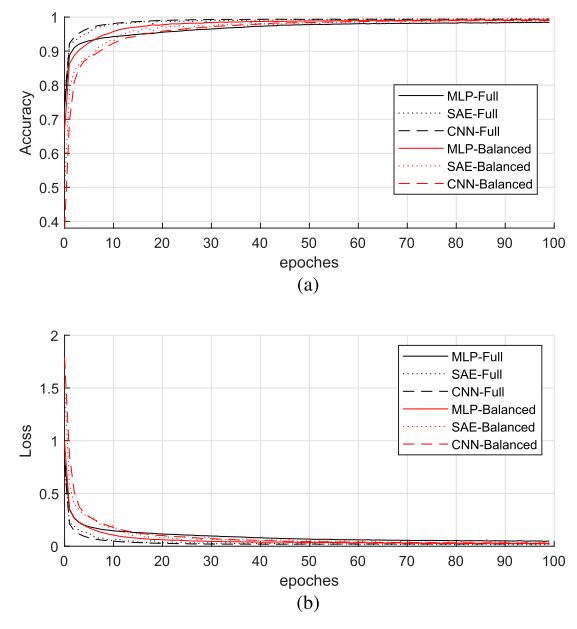
通过50次测试,对每个数据网模型的准确性进行了评估。每个测试使用从完整数据集中随机选择的平衡子集进行。在每个选择的子集中,40%是随机选择的分类测试。例如,为了测试Netflix,从51932的总样本中随机选择5000个样本。然后进一步选取2000个样本进行分类试验。对于每个数据网,衡量了其精度。召回率以及F1分数。培训图10(a)和图10(b)示出了6个数据网的精度和丢失。这三种方法在训练数据网时都显示出良好的收敛性。六个数据网的评估结果汇总在表4中。

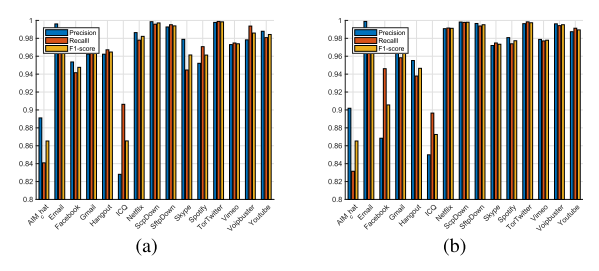
为了更好地说明,图11示出了每个数据网的详细分类的平均结果。图表对角线上的元素表示准确的分类结果。可以从图11(a)和图11(d)验证使用MLP数据网的ICQ分类的不精确性。如我们所见,许多ICQ包被错误地归类为AIM_Chat,反之亦然。基于SAE的数据网的类似结果(图11(a)和11(d))和基于CNN的数据网(图11(c)和11(f))。我们可以看到,SAE和CNN数据网在对两个在线聊天应用程序进行分类时都有更好的性能。下面将详细讨论每种类型的数据网。
基于MLP的数据网的评估结果如图12所示。从完整数据集训练的MLP数据网在大多数应用中实现了高精度,如图12(a)所示。具体来说,Email、Netflix、ScpDown、sftpown和TorTwitter接近100%。AIM-Chat和ICQ的精度相对较低,分别为88%和83%。相似地是,召回率和F1分数对于除了AIM_Chat和ICO的大部分应用都很高。大多数应用程序的三个指标的平均结果为96%。相比之下,从平衡数据集训练的MLP数据网具有相对较低的性能。事实上,使用从平衡数据集训练的MLP数据网,Spotify分类的召回率甚至低于80%。
基于SAE的数据网的评估结果如图13所示。我们可以看到,所有的精度,召回率和F1分数都远远高于基于MLP的数据网。这三个指标对基于SAE的数据网的平均结果都达到了98%。
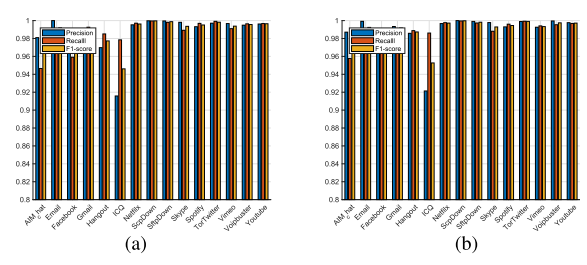
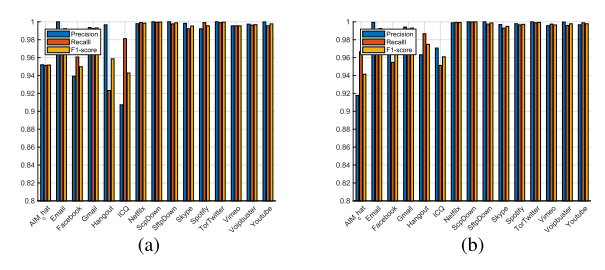
基于CNN的数据网的评估结果如图14所示。如我们所见,基于CNN的数据网在精确性、召回率和F1得分方面取得了更好的结果。这三个指标的平均结果为98%。
D. 计算性能
我们评估这三种类型的数据网的计算性能。在不丧失通用性的情况下,使用从平衡数据集训练的三个数据网进行评估。对每个数据网进行50次测试。每个测试记录150000个数据包分类的计算性能。通过相对强大的配置,例如设置用于训练的配置,可以对带宽超过100mbps的家庭网络实时执行分类过程,如表5所示。
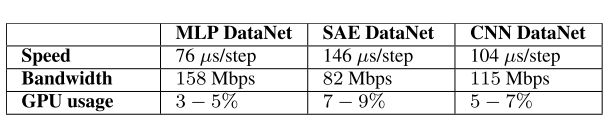
为了实现本地用户(如家庭用户)的实时网络管理,应在SDN-HGW而不是SDN核心网络控制器处理提出的数据网。然而,SDN-HGW在CPU、内存和闪存上的计算能力有限。我们使用配置有4核CPU(超过1500DMIPS)、512MB RAM以及128MB Flash的SDN-HGW进行了一个案例研究。如表6所示,MLP数据网具有最高的计算效率。它每秒可以处理10900多个数据包,大约16.48 MB。换句话说,MLP数据网的实时处理能力超过131mbps。

由于方案的不同复杂性,CPU和内存的使用可能会有所不同。如图15所示,基于MLP的数据网在三种方案中消耗最少的计算资源,从而为实时处理提供最大的带宽。我们将进一步研究这一问题,以便在今后的工作中取得更好的成绩。

VII. 总结
本文提出了一种支持分布式端到端网络QoS管理的SDN-HGW框架。该框架的核心是基于深度学习的加密数据包分类器DataNet。所提出的数据网是用三种方法开发的,包括MLP、SAE和CNN。用于开发和测试所提出的数据网的数据集来自一个开放的数据集,包含来自15个应用程序的20000多个数据包。实验结果表明,所开发的数据网可以应用于所提出的SDN-HGW框架,具有准确的分组分类和较高的计算效率,用于智能家庭网络的实时处理。在今后的工作中,我们将继续提高数据网的性能,并将其应用于加强网络资源管理、启用新的业务计划等,同时不损害服务提供商和用户的安全/隐私。