python信号处理教程_python玩转信号处理与机器学习入门
python玩转信号处理与机器学习入门
作者:王镇
面对毫无规律的随机信号,看着杂乱无章的振动波形,你是否也像曾经的我一样一头雾水,不知从何处下手。莫慌,接下来小编就带你入门怎样用python处理这些看似毫无卵用实则蕴藏巨大信息的随机信号。我们日常生活中所见的心电图,声波图都是信号在时域上的一种表现,但它们无法呈现出信号在频域上的信息。因此,本文将主要介绍信号从时域到频域上的一些变换,常见的有FFT(快速傅里叶变换),PSD(功率谱密度),auto-correlation(自相关分析)。最后小编将带你完成一个实例,通过手机采集的振动信号识别人体的动作。
一、介绍
本部分将介绍FFT,PSD,auto-correlation的基本概念以及python代码实现。
1.1 混合信号
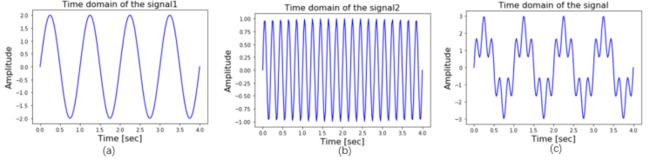
图1 信号在时域上的表现
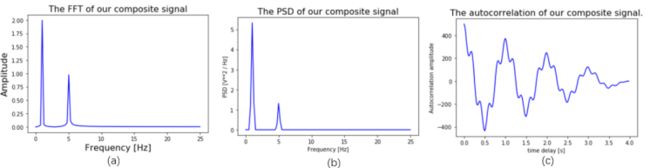
图2 信号在频域上的表现
上图展示了混合信号在时域上的表现形式,图(a)为一频率为1Hz,振幅为2的正弦波信号,图(b)为一频率为5Hz,振幅为1的正弦波信号,图(c)为(a)、(b)两信号的叠加结果。
1.2 FFT
FFT英文全称Fast Fourier Transformation,即快速傅里叶变换,它可以轻松地分析出混合信号中的各频率组成成分。对上述中的混合信号做FFT变换,结果如图2(a),可以明显地看到混合信号包含频率分别为1Hz和5Hz的成分。FFT变换的代码如下:
from scipy.fftpack import fft
def get_fft_values(y_values, N, f_s):
f_values = np.linspace(0.0, f_s/2.0, N//2)
fft_values_ = fft(y_values)
fft_values = 2.0/N * np.abs(fft_values_[0:N//2])
return f_values, fft_values
1.3 PSD
PSD英文全称Power Spectral Density,即功率谱密度,它和FFT一样,反映的是信号在频域上的信息。其中PSD频谱图脉冲下方的面积表示信号在该频率上的能量分布。
对上述中的混合信号做PSD变换,结果如图2(b),可以明显地看到混合信号在频率为1Hz和5Hz上的能量分布。PSD变换的代码如下:
from scipy.signal import welch
def get_psd_values(y_values, N, f_s):
f_values, psd_values = welch(y_values, fs=f_s)
return f_values, psd_values
1.4 Autocorrelation
Autocorrelation是自相关的意思,它可以求出信号的自相关性,即信号经过一个时延后与自身的相似性。对上述中的混合信号计算Autocorrelation,结果如图2(c)所示
。有趣的是Autocorrelation与PSD是一组FFT变换对,对Autocorrelation作FFT变换可得到PSD,对PSD作IFFT(快速傅里叶逆变换)可得到Autocorrelation。
def autocorr(x):
result = np.correlate(x, x, mode='full')
return result[len(result)//2:]
def get_autocorr_values(y_values, N, f_s):
autocorr_values = autocorr(y_values)
x_values = np.array([ 1.0*jj/f_s for jj in range(0, N)])
return x_values, autocorr_values
二 实例
经过上面的简单介绍相信你已经了解并掌握了信号在频域上的变换。写下来让我们运用刚学的知识结合机器学习知识来分析一个实例 Human Activity Recognition Using Smartphones Data Set。该数据集通过在30个不同年龄分布的志愿者上做实验采集得到,在志愿者的腰上固定一手机,手机以50Hz的采样频率采集内嵌加速度计和陀螺仪的数据,志愿者被要求做以下六个动作:walking(行走),walking upstairs(爬楼梯),walking downstairs(下楼梯),sitting(坐着),standing(站着),laying(躺下)。在滤除噪声之后,通过滑动窗口的方式将信号切分成2.56s的窗口,每个窗口包含128个样本。该数据集包含三组数据three-axial linear body acceleration(去除重力加速度的加速度计数据)、three-axial linear total acceleration(包含重力加速度的加速度计数据)、three-axial angular velocity(陀螺仪的数据),因此共有九个分量,其中训练集有7392个窗口,测试集有2947个窗口。

图3 数据集分布
2.1 数据可视化
随机选取一信号,绘出其在时域和频域上的波形图如下所示,绘图代码详见项目链接:
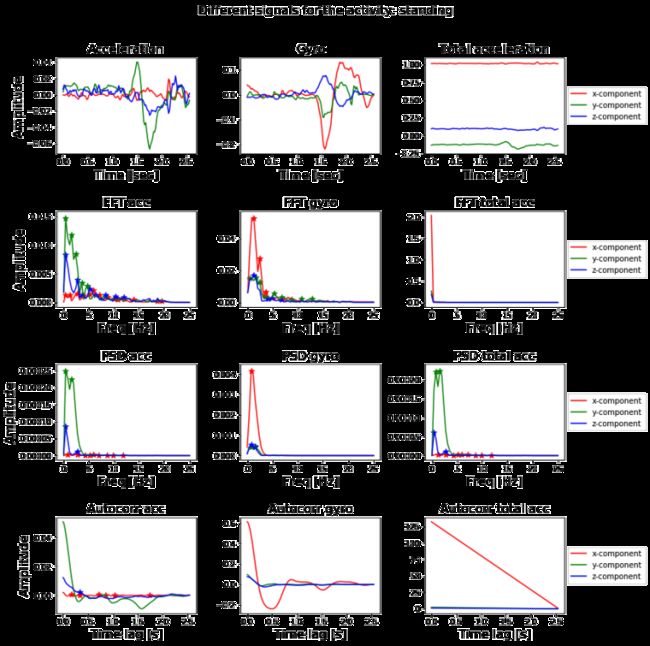
图4 一个例子的展示
2.2 特征提取
做好了频谱变换之后,我们需要从中提取特征,这样才能应用我们所熟悉的诸如随机森林,逻辑回归,支持向量机之类的机器学习模型。那么提取什么特征呢,一种方式是提取脉冲(peak)发生时所在的横纵坐标,我们提取频谱中的前5个脉冲的横纵坐标作为特征。其中提取peak信息可用detect_peaks。
def get_first_n_peaks(x, y, no_peaks=5):
x_, y_ = list(x), list(y)
if len(x_) >= no_peaks:
return x_[:no_peaks], y_[:no_peaks]
else:#少于5个peaks,以0填充
missing_no_peaks = no_peaks-len(x_)
return x_ + [0]*missing_no_peaks, y_ + [0]*missing_no_peaks
def get_features(x_values, y_values, mph):
indices_peaks = detect_peaks(y_values, mph=mph)
peaks_x, peaks_y = get_first_n_peaks(
x_values[indices_peaks], y_values[indices_peaks])
return peaks_x + peaks_y
def extract_features_labels(dataset, labels, N, f_s, denominator):
percentile = 5
list_of_features = []
list_of_labels = []
for signal_no in range(0, len(dataset)):
features = []
list_of_labels.append(labels[signal_no])
for signal_comp in range(0, dataset.shape[2]):
signal = dataset[signal_no, :, signal_comp]
signal_min = np.nanpercentile(signal, percentile)
signal_max = np.nanpercentile(signal, 100-percentile)
#ijk = (100 - 2*percentile)/10
#set minimum peak height
mph = signal_min + (signal_max - signal_min)/denominator
features += get_features(*get_psd_values(signal, N, f_s), mph)
features += get_features(*get_fft_values(signal, N, f_s), mph)
features += get_features(*get_autocorr_values(signal, N, f_s), mph)
list_of_features.append(features)
return np.array(list_of_features), np.array(list_of_labels)
X_train, Y_train = extract_features_labels(train_signals, train_labels, N, f_s, denominator)
X_test, Y_test = extract_features_labels(test_signals, test_labels, N, f_s, denominator)
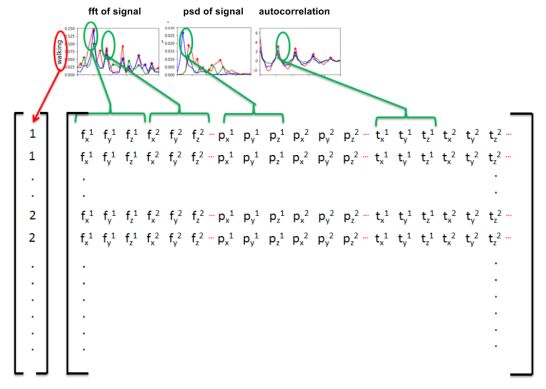
图5 特征提取详细介绍
2.3 模型训练及结果展示
当构建完特征矩阵以及其对应的标签之后,我们可以选择scikit-learn库中的相关模型进行训练。
clf = RandomForestClassifier(n_estimators=1000)
clf.fit(X_train, Y_train)
print("Accuracy on training set is : {}".format(clf.score(X_train, Y_train)))
print("Accuracy on test set is : {}".format(clf.score(X_test, Y_test)))
Y_test_pred = clf.predict(X_test)
print(classification_report(Y_test, Y_test_pred))
结果如下。
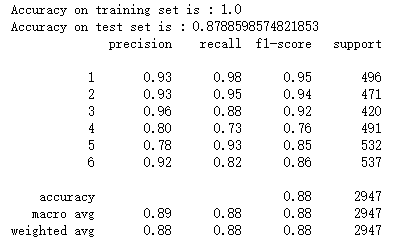
图6 分类结果展示

图7 模型比较
正如结果所展示的那样,我们能以相当高的准确率(89%)对这些信号进行分类,取得这个结果,我们甚至都没有做任何手动的特征工程,所有特征都是自动获取的,对于每个变换,我们取前五个峰值的横纵坐标(若少于五个则填充0)。可以理解的一点是,这270个特性中的一些特征将比其他特征提供更多的信息,若我们能主动地选择对分类很重要的特征进行组合,或者对超参数进行优化,相信准确率还能继续提高。
参考文献:
关于我们
Mo(网址:https://momodel.cn) 是一个支持 Python的人工智能在线建模平台,能帮助你快速开发、训练并部署模型。
近期 Mo 也在持续进行机器学习相关的入门课程和论文分享活动,欢迎大家关注我们的公众号获取最新资讯!
来源:oschina
链接:https://my.oschina.net/u/4109778/blog/4277567