Python 爬取携程景点用户评论信息教程_以武汉木兰草原景点为例
Python 爬取携程景点用户评论教程
话不多说,先看结果,满意再点赞+关注+收藏!
这是爬取武汉木兰草原的用户评论

携程木兰草原页面网址
https://you.ctrip.com/sight/wuhan145/50956.html
爬取中
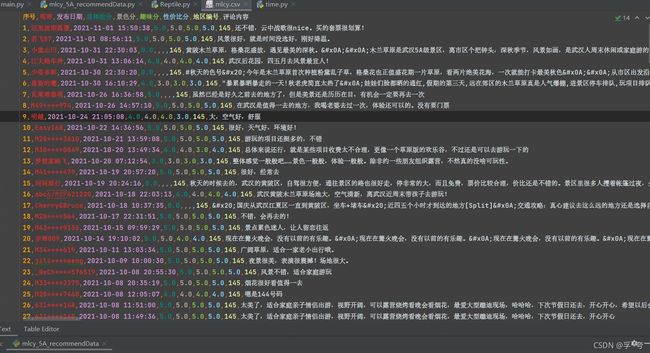
爬取后保存为.CSV文件
上代码!
编写爬虫类
// An highlighted block
import csv
import json
import time
import requests
class Reptile: #创建一个爬虫类,方便在其他文件中调用
def __init__(self, postURL, user_agent, poiId, cid, startPageIndex, endPageIndex, file):
self.postURL = postURL
self.user_agent = user_agent
self.poiId = poiId
self.cid = cid
#上面这些对应着包中的头部信息填就是了
self.startPageIndex = startPageIndex #开始爬取的页码
self.endPageIndex = endPageIndex #结束爬取的页码
self.file = file #保存记录的.csv文件的文件名,一定要将后缀名也写上,如:"****.csv"
self.dataListCSV = [] #用来暂存爬取结果,是一个二维列表,dataListCSV中的每一个元素对应一条记录,便于写入CSV文件
def get(self):
for i in range(int(self.startPageIndex), int(self.endPageIndex)+1): #爬取第 i 页
requestParameter = {
'arg': {'channelType': '2',
'collapseType': '0',
'commentTagId': '0',
'pageIndex': str(i), #爬取的评论页面的页码索引
'pageSize': '10', #每页的评论数量
'poiId': str(self.poiId), #景点地址代码
'sortType': '1',
'sourceType': '1',
'starType': '0'},
'head': {'auth': "",
'cid': self.cid, #不同景点的cid不同,因此需要自行设置
'ctok': "",
'cver': "1.0",
'extension': [],
'lang': "01",
'sid': "8888",
'syscode': "09",
'xsid': ""}
}
html = requests.post(self.postURL, data=json.dumps(requestParameter)).text
html = json.loads(html) #得到第i页字典形式的全部评论数据
for element in html["result"]["items"]: #处理景色、趣味、性价比得分
if element['scores']:
if element['scores'][0]:
sceneryScore = str(element['scores'][0]["score"])
else:
sceneryScore = ""
if element['scores'][1]:
interestScore = str(element['scores'][2]["score"])
else:
interestScore = ""
if element['scores'][3]:
costScore = str(element['scores'][4]["score"])
else:
costScore = ""
else:
sceneryScore = ""
interestScore = ""
costScore = ""
#处理评论时间的格式
publishTime = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(int(element["publishTime"][6:16])))
self.dataListCSV.append([len(self.dataListCSV)+1, element["userInfo"]["userNick"], publishTime, element["score"], sceneryScore, interestScore, costScore, element["districtId"], element["content"]])
print(f"页面 {i} 已爬取", type(html))
time.sleep(4)
print(self.dataListCSV)
with open(self.file, "w+", encoding="utf8", newline="") as f: #将dataListCSV列表内容写入.csv文件中
write = csv.writer(f)
write.writerow(["序号","昵称", "发布日期", "总体给分", "景色分", "趣味分", "性价比分", "地区编号", "评论内容"])
write.writerows(self.dataListCSV)
调用爬虫
// An highlighted block
#我的Reptile类是放在dataProcurement包下的
from dataProcurement.Reptile import Reptile
postURL = "https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031083119044546256"
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.30"
poiId = 83520
cid = "09031083119044546256"
startPageIndex = 1
endPageIndex = 20
reptile = Reptile(postURL, user_agent, poiId, cid, startPageIndex, endPageIndex, "mlcy.csv")
reptile.get()
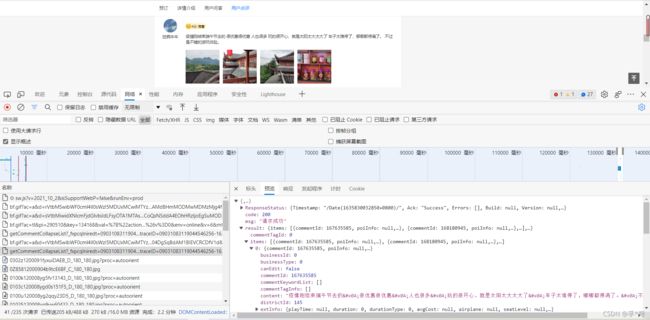
浏览器对应包结构如下图
找到networks(网络)中的getCommentCollapseList包,postURL见标头部分的请求URL,写到https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031083119044546256
即可,不要全写。
poiId和cid见请求负载部分,
user_agent就不用再多说了,能找到这篇文章的朋友应该都懂。