Tensorflow2.0:(三)神经网络搭建八股
第三章 神经网络搭建八股
本次Tensorflow2.0学习笔记参考北京大学曹健老师《人工智能实践:Tensorflow笔记》课程。
课程链接:https://www.icourse163.org/course/PKU-1002536002
B站链接:https://www.bilibili.com/video/BV1B7411L7Qt?p=1
课程代码及自制数据集下载:https://github.com/jlff/tf2_notes
该课程适合无基础的初学者入门,在保证主线完整的前提下,各章节略有增删改简。
学习目的
- 神经网络搭建八股
- iris数据集识别鸢尾花代码复现
- MNIST数据集识别手写数字代码复现
- FASHION数据集识别衣裤鞋包代码复现
一、六步法
- keras简介
- 什么是keras?keras 是一个用 Python 编写的高级神经网络 API,它能够以 TensorFlow, CNTK, 或者 Theano 作为后端运行。它的开发由Google支持,支持GPU和CPU,主要包括Models API、Layers API、Callbacks API、Data preprocessing、Optimizers、Metrics、Losses、Built-in small datasets、Keras Applications、Utilities等10个模块包,参见文档:https://keras.io/api/
- keras vs. tf.keras? TensorFlow 2.0发布后, keras 正式成为 TensorFlow 的官方高级 API。2019年随着 keras 2.3.0 的发布,keras的创建者和首席维护者Francois Chollet 声明: keras v2.3.0 是首个与 tf.keras 同步的版本,也将是最后一个支持除 TensorFlow 以外的后端(即 Theano,CNTK 等)的最终版本。
- keras搭建神经网络六步法
- 第一步:import
import相关模块,如import tensorflow as tf - 第二步:train,test
指定输入网络的训练集和测试集 - 第三步:model = tf.keras.models.Sequential / class MyModel(Model) model=MyModel
逐层搭建网络结构
model = tf.keras.models.Sequential([网络结构]) #描述各层网络
"""
例如:
拉直层:tf.keras.layers.Flatten()
全连接层:tf.keras.layers.Dense(神经元个数, activation="激活函数“ ,kernel_regularizer=哪种正则化)
activation(字符串给出)可选: relu、softmax、sigmoid 、tanh
kernel_regularizer可选:tf.keras.regularizers.l1()、tf.keras.regularizers.l2()
卷积层:tf.keras.layers.Conv2D(filters = 卷积核个数, kernel_size= 卷积核尺寸,
strides = 卷积步长,padding = " valid" or "same")
LSTM层:tf.keras.layers.LSTM()
"""
使用Sequential可以快速搭建网络结构,但是如果网络包含跳连等其他复杂网络结构,Sequential就无法表示了。这时就需要使用class来自定义网络结构。
class MyModel(Model):
def __init__(self):
# 定义网络结构块
super(MyModel, self).__init__()
def call(self, x):
# 调用网络结构块,实现前向传播
return y
model= MyModel()
- 第四步:model.compile
配置训练方法:优化器、损失函数和最终评价指标。优化器、损失函数在第二章中有介绍。
model.compile(optimizer = 优化器, loss = 损失函数, metrics = [“准确率”])
"""
Optimizer可选:
‘sgd’ or tf.keras.optimizers.SGD(lr=学习率,momentum=动量参数)
‘adagrad’ or tf.keras.optimizers.Adagrad(lr=学习率,decay=学习率衰减率)
‘adadelta’ or tf.keras.optimizers.Adadelta(lr=学习率,decay=学习率衰减率)
‘adam’ or tf.keras.optimizers.Adam(lr=学习率, beta_1=0.9, beta_2=0.999)
loss可选:
‘mse’ or tf.keras.losses.MeanSquaredError()
‘sparse_categorical_crossentropy’ or tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False)
Metrics可选:
‘accuracy’ :y_和y都是数值,如y_=[1] y=[1]
‘categorical_accuracy’ :y_和y都是独热码(概率分布),如y_=[0,1,0] y=[0.256,0.695,0.048]
‘sparse_categorical_accuracy’ :y_是数值,y是独热码(概率分布),如y_=[1] y=[0.256,0.695,0.048]
"""
- 第五步:model.fit
执行训练过程
model.fit(训练集的输入特征, 训练集的标签, batch_size= , epochs= ,
validation_data=(测试集的输入特征,测试集的标签),
validation_split=从训练集划分多少比例给测试集,validation_freq= 多少次epoch测试一次)
- 第六步:model.summary
打印网络结构,统计参数数目
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 3) 15
=================================================================
Total params: 15
Trainable params: 15
Non-trainable params: 0
_________________________________________________________________
二、iris数据集识别鸢尾花
使用Sequential
# 第一步import
import tensorflow as tf
from sklearn import datasets
import numpy as np
# 第二步train test
x_train = datasets.load_iris().data # 测试集的输入特征x_test和标签y_test可以像x_train和y_train一样直接从数据集获取,也可以如上述在fit中按比例从训练集中划分,本例选择从训练集中划分,所以只需加载x_train,y_train即可
y_train = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_train) # 将数据集乱序
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
# 第三步models.Sequential
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(3, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
]) # 使用单层全连接网络,第一个参数表示神经元个数,第二个参数表示网络所使用的激活函数,第三个参数表示选用的正则化方法
# 第四步model.compile
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy']) # 使用SGD优化器,并将学习率设置为0.1,选择SparseCategoricalCrossentrop作为损失函数,输出为概率分布,所以metrics需要设置为sparse_categorical_accuracy
# 第五步model.fit
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20) # batch_size表示神经网络进行一次训练样本数,epochs表示所有样本进行迭代的次数validation_split表示数据集中验证集的划分比例,validation_freq表示每迭代20次在测试集上测试一次准确率。
# 第六步model.summary()
model.summary()
...
Epoch 499/500
4/4 [==============================] - 0s 2ms/step - loss: 0.3691 - sparse_categorical_accuracy: 0.9306
Epoch 500/500
4/4 [==============================] - 0s 14ms/step - loss: 0.3634 - sparse_categorical_accuracy: 0.9304 - val_loss: 0.3516 - val_sparse_categorical_accuracy: 0.8667
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 3) 15
=================================================================
Total params: 15
Trainable params: 15
Non-trainable params: 0
_________________________________________________________________
使用自定义Class IrisModel(Model)
# 第一步import
import tensorflow as tf
from tensorflow.keras.layers import Dense
from tensorflow.keras import Model
from sklearn import datasets
import numpy as np
# 第二步train test
x_train = datasets.load_iris().data
y_train = datasets.load_iris().target
np.random.seed(116)
np.random.shuffle(x_train)
np.random.seed(116)
np.random.shuffle(y_train)
tf.random.set_seed(116)
# 第三步class IrisModel
class IrisModel(Model):
def __init__(self):
super(IrisModel, self).__init__()
self.d1 = Dense(3, activation='sigmoid', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, x):
y = self.d1(x)
return y
model = IrisModel()
# 第四步model.compile
model.compile(optimizer=tf.keras.optimizers.SGD(lr=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
# 第五步model.fit
model.fit(x_train, y_train, batch_size=32, epochs=500, validation_split=0.2, validation_freq=20)
# 第六步model.summary()
model.summary()
...
Epoch 499/500
4/4 [==============================] - 0s 2ms/step - loss: 0.3691 - sparse_categorical_accuracy: 0.9306
Epoch 500/500
4/4 [==============================] - 0s 16ms/step - loss: 0.3634 - sparse_categorical_accuracy: 0.9304 - val_loss: 0.3516 - val_sparse_categorical_accuracy: 0.8667
Model: "iris_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) multiple 15
=================================================================
Total params: 15
Trainable params: 15
Non-trainable params: 0
_________________________________________________________________
三、MNIST数据集识别手写数字
查看数据格式
import tensorflow as tf
from matplotlib import pyplot as plt
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 可视化训练集输入特征的第一个元素
plt.imshow(x_train[0], cmap='gray') # 绘制灰度图
plt.show()
# 打印出训练集输入特征的第一个元素
print("x_train[0]:\n", x_train[0])
# 打印出训练集标签的第一个元素
print("y_train[0]:\n", y_train[0])
# 打印出整个训练集输入特征形状
print("x_train.shape:\n", x_train.shape)
# 打印出整个训练集标签的形状
print("y_train.shape:\n", y_train.shape)
# 打印出整个测试集输入特征的形状
print("x_test.shape:\n", x_test.shape)
# 打印出整个测试集标签的形状
print("y_test.shape:\n", y_test.shape)
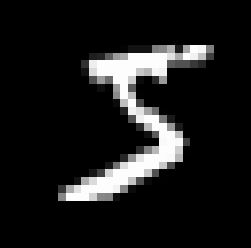
x_train[0]:
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136 175 26 166 255 247 127 0 0 0 0]
[ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0 0 0]
[ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251 93 82 82 56 39 0 0 0 0 0]
[ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119 25 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253 150 27 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252 253 187 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249 253 249 64 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253 253 207 2 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253 250 182 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201 78 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]
y_train[0]:
5
x_train.shape:
(60000, 28, 28)
y_train.shape:
(60000,)
x_test.shape:
(10000, 28, 28)
y_test.shape:
(10000,)
使用Sequential训练模型
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0 # 将输入特征的灰度值归一化到[0,1]区间,这可以使网络更快收敛
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(), # 输入全连接网络时需要先将数据拉直为一维数组,把784个像素点的灰度值作为输入特征输入神经网络
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
...
Epoch 4/5
1875/1875 [==============================] - 3s 1ms/step - loss: 0.0554 - sparse_categorical_accuracy: 0.9830 - val_loss: 0.0746 - val_sparse_categorical_accuracy: 0.9769
Epoch 5/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0402 - sparse_categorical_accuracy: 0.9885 - val_loss: 0.0766 - val_sparse_categorical_accuracy: 0.9780
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
_________________________________________________________________
dense_2 (Dense) (None, 128) 100480
_________________________________________________________________
dense_3 (Dense) (None, 10) 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
使用自定义Class MnistModel(Model)
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras import Model
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class MnistModel(Model):
def __init__(self):
super(MnistModel, self).__init__()
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.flatten(x)
x = self.d1(x)
y = self.d2(x)
return y
model = MnistModel()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
...
Epoch 4/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0559 - sparse_categorical_accuracy: 0.9827 - val_loss: 0.0786 - val_sparse_categorical_accuracy: 0.9763
Epoch 5/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0443 - sparse_categorical_accuracy: 0.9869 - val_loss: 0.0774 - val_sparse_categorical_accuracy: 0.9755
Model: "mnist_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_2 (Flatten) multiple 0
_________________________________________________________________
dense_4 (Dense) multiple 100480
_________________________________________________________________
dense_5 (Dense) multiple 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
四、FASHION数据集识别衣裤鞋包
使用Sequential训练模型
import tensorflow as tf
fashion = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
...
Epoch 4/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0559 - sparse_categorical_accuracy: 0.9827 - val_loss: 0.0786 - val_sparse_categorical_accuracy: 0.9763
Epoch 5/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0443 - sparse_categorical_accuracy: 0.9869 - val_loss: 0.0774 - val_sparse_categorical_accuracy: 0.9755
Model: "mnist_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_2 (Flatten) multiple 0
_________________________________________________________________
dense_4 (Dense) multiple 100480
_________________________________________________________________
dense_5 (Dense) multiple 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
使用自定义Class MnistModel(Model)
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras import Model
fashion = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class MnistModel(Model):
def __init__(self):
super(MnistModel, self).__init__()
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.flatten(x)
x = self.d1(x)
y = self.d2(x)
return y
model = MnistModel()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1)
model.summary()
...
Epoch 4/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.3151 - sparse_categorical_accuracy: 0.8848 - val_loss: 0.3678 - val_sparse_categorical_accuracy: 0.8659
Epoch 5/5
1875/1875 [==============================] - 3s 2ms/step - loss: 0.2976 - sparse_categorical_accuracy: 0.8902 - val_loss: 0.3643 - val_sparse_categorical_accuracy: 0.8717
Model: "mnist_model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_4 (Flatten) multiple 0
_________________________________________________________________
dense_8 (Dense) multiple 100480
_________________________________________________________________
dense_9 (Dense) multiple 1290
=================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
_________________________________________________________________
五、参考
【1】keras官方文档:https://keras.io/zh/
【2】tf.keras官方文档:https://tensorflow.google.cn/api_docs/python/tf/keras
【3】keras vs. tf.keras:https://www.pyimagesearch.com/2019/10/21/keras-vs-tf-keras-whats-the-difference-in-tensorflow-2-0/