Swin Transformer V2论文解读
文章目录
- 创新点
- 算法
-
- Swin Transformer
- 放大模型能力
- 放大window分辨率
- GPU内存消耗优化
- 引入自监督方法
- 模型
- 实验
-
- 图像分类
- 目标检测
- 语义分割
- 视频行为分类
- 消融实验
- 结论
论文: 《Swin Transformer V2: Scaling Up Capacity and Resolution》
代码: https://github.com/microsoft/Swin-Transformer
创新点
增大视觉模型,没有像NLP一样进行广泛探究,主要存在以下难点:
1、视觉模型面临放大不稳定问题;
2、下游视觉任务需要高分辨率图片或window,但是不清楚如何将小分辨率预训练模型用于大分辨率;
3、当增大分辨率时,GPU内存消耗也是一个问题;
为解决这些问题,作者使用如下方法:
1、后归一化技术和缩放余弦attention方法,以提高大型视觉模型的稳定性;
2、一种对数空间的连续位置偏置技术,可有效地将低分辨率预训练模型迁移到高分辨率上;
3、分享节约GPU内存消耗方法,使得训练大分辨率模型可行;
算法
Swin Transformer
可参考之前文章Swin Transformer
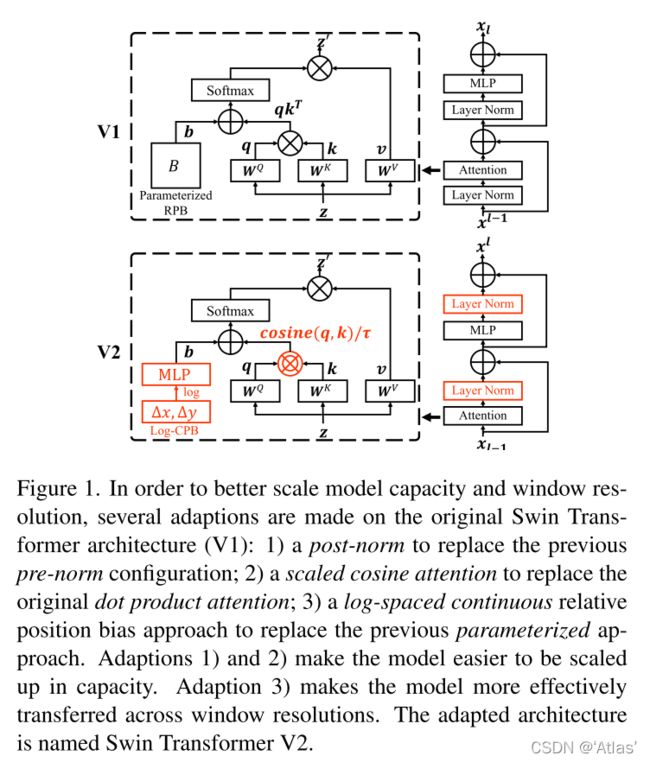
Swin Transformer中归一化位置如图1上所示,在残差之后
Attention计算如式1,
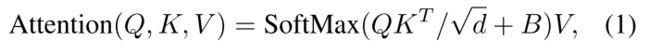
放大模型能力
大视觉模型训练过程不稳定,其由层间激活函数振幅差异造成,而振幅差异由残差单元输出之间加回主分支导致;
因此,作者将LN层后置,如图1下.
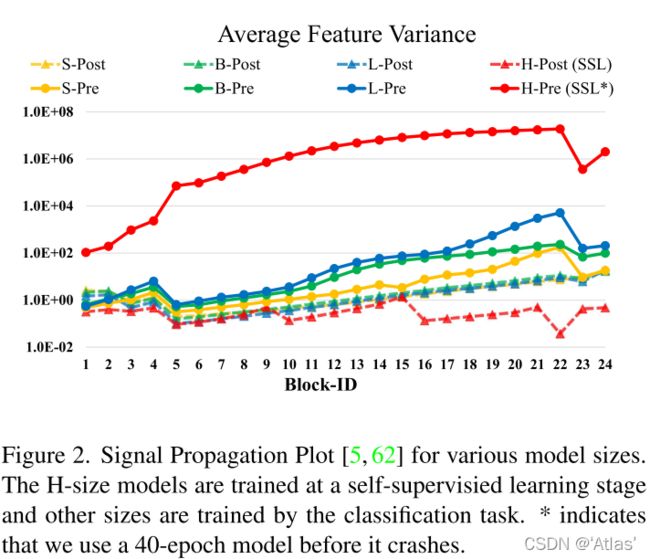
post-norm相对于pre-norm,激活值降低,如图2所示;在最大模型(Swin V2-H、Swin V2-G)训练过程中,为了训练稳定,每6个Transformer模块额外引入一个LN层;
作者发现attention经常被几个像素对所支配,尤其在使用post-norm后,为了缓和这个情况,我们提出scaled cosine attention,如式2;
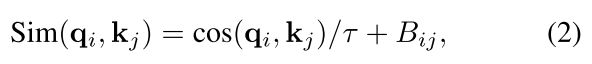
γ \gamma γ为可学习参数
放大window分辨率
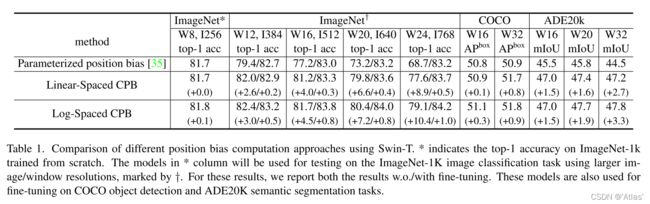
默认预训练模型attention所使用window大小为8*8,通过双三次差值将其其直接迁移到大分辨率下测试,性能出现下降,如表1(parameterized position bias),
为了平滑生成相关位置偏置,作者通过小网络G生成,如式3,
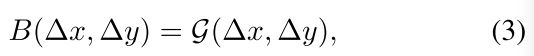
因此,G可以为任意相对位置生成对应偏置,因此可迁移至任意window大小;
当迁移至大window时,大部分相对坐标范围需要外推,为解决此问题,将线性空间转为对数空间,如式4,对数空间外推比例大大降低;
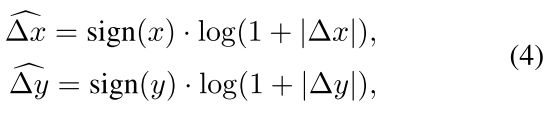
比如:对于 8 ∗ 8 8*8 8∗8的窗口,输入相对坐标范围为 [ − 7 , 7 ] ∗ [ − 7 , 7 ] [-7,7]*[-7,7] [−7,7]∗[−7,7](因为为相对位置,因此可能为-7),而 16 ∗ 16 16*16 16∗16的窗口,输入相对坐标位置范围为 [ − 15 , 15 ] ∗ [ − 15 , 15 ] [-15,15]*[-15,15] [−15,15]∗[−15,15],因此外推比例为 8 / 7 = 1.14 8/7=1.14 8/7=1.14倍,在对数空间,对于 8 ∗ 8 8*8 8∗8的窗口,输入相对坐标范围为 [ − 2.079 , 2.079 ] ∗ [ − 2.079 , 2.079 ] [-2.079,2.079]*[-2.079,2.079] [−2.079,2.079]∗[−2.079,2.079],对于 16 ∗ 16 16*16 16∗16的窗口,输入相对坐标范围为 [ − 2.773 , 2.773 ] ∗ [ − 2.773 , 2.773 ] [-2.773,2.773]*[-2.773,2.773] [−2.773,2.773]∗[−2.773,2.773],外推比例为0.33倍。
表1比较不同位置偏置计算方法模型性能,log-spaced CPB方法最佳,尤其迁移至较大window;
GPU内存消耗优化
1、Zero-Redundancy Optimizer (ZeRO);目前数据并行模式下深度学习训练,每台机器消耗固定大小全量内存;ZeRO可将内存平均分配到各个gpu上;
2、Activation check-pointing;原地操作:直接将输出值存储到输入值的内存中。内存共享:回收不再需要的中间结果使用的内存并用于另一个节点。
3、Sequential self-attention computation.作者使用顺序计算而非batch计算self attention模块;
引入自监督方法
大模型需要大数据量;为解决这个问题,之前方法使用大数据集:JFT-3B或自监督预训练,本文作者结合两者,将ImageNet-22K扩充5倍,同时使用自监督学习策略充分挖掘数据;
模型
Swin V2出了沿用V1中模型,如下,

额外扩充两个大模型,

实验
图像分类
表2作者比较之前大模型在ImageNet V1和V2上性能,
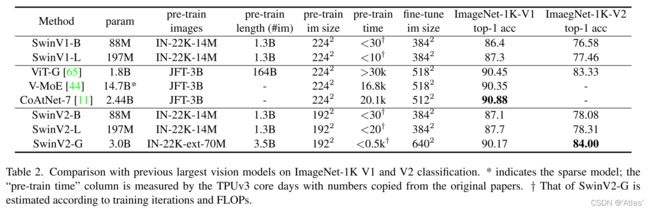
在ImageNet V1上,SwinV2-G性能(90.17)略逊于CoAtNet-7性能(90.88),作者认为一方面由于不同程度数据集过度调整导致(预训练图片差异);另一方面使用更是训练轮次和更低图像分辨率。
目标检测
表3展示在COCO数据集目标检测性能及实例分割性能,验证集上,boxAP/maskAP达到62.5/53.7,测试集上达到63.1/54.4,超越目前已有算法。
语义分割
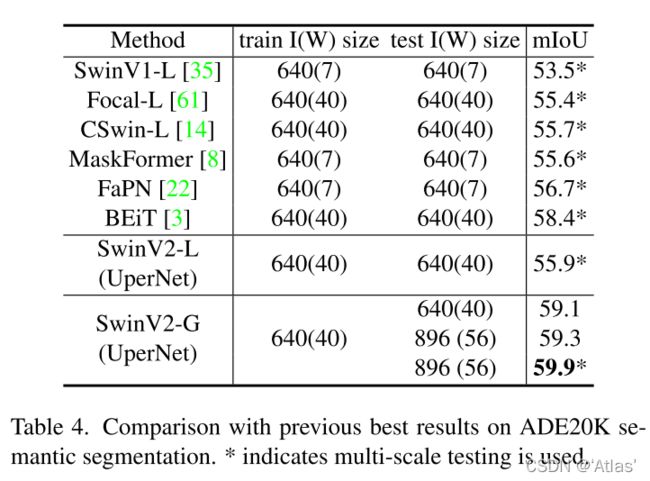
表4在ADE20K数据集上,作者比较SwinV2-G与之前最好语义分割模型性能。
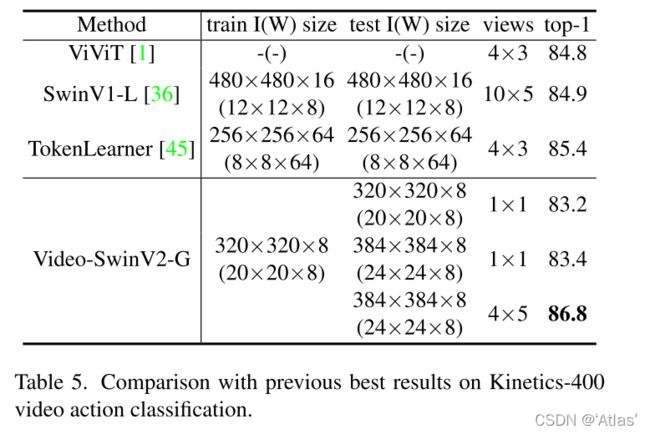
视频行为分类
表5作者在Kinetics-400视频行为数据集上,比较之前最佳模型;
消融实验
作者比较新提出的post-norm及scaled cosine attention性能;
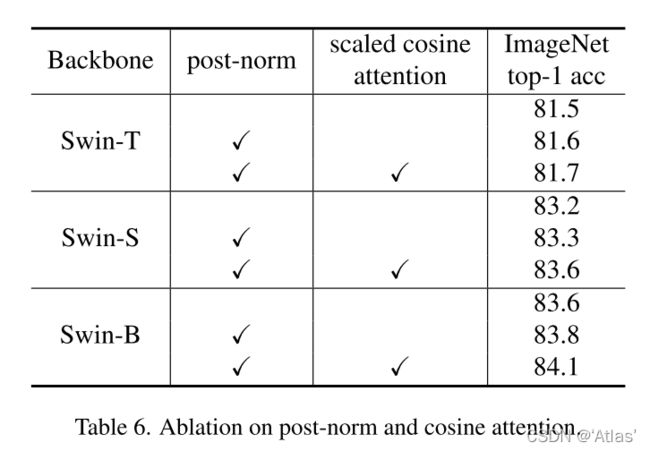
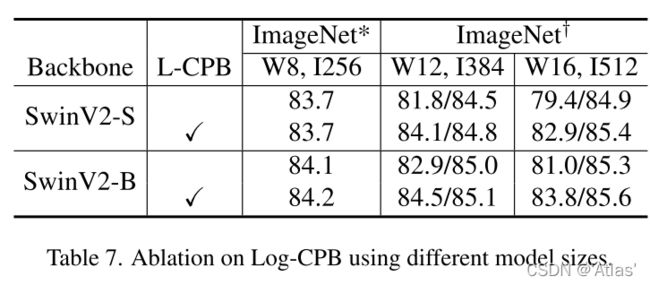
表7作者比较Log-CPB影响,
结论
Swin V2中post-norm及scaled cosine attention使得模型容易训练大分辨图像;Log-CPB(log-spaced continuous relative positional bias)使得模型更容易随着窗口分辨率迁移;
在图像分类、目标检测、语义分割、视频行为分类均取得不错性能。