机器学习(一)——基于决策树算法建立用户流失预测模型
目录
一、项目背景
1.1 流失用户定义
1.2 探究用户流失目的
1.3 项目描述
1.3.1 项目简介
1.3.2 分析工具
二、数据预处理
2.1 数据采集与预览
2.2 数据清洗
2.2.1 数据类型转换
2.2.2 缺失值处理
2.2.3 重复值处理
2.2.4 异常值处理
三、数据可视化分析
3.1 流失客户占比
3.2 样本基本特征对客户流失率的影响
3.3 样本特征相关性分析
3.3.1 特征值提取与编码
3.3.2 构造相关系数矩阵
3.3.3 使用热力图显示相关系数
3.3.4 电信用户是否流失与各变量之间的相关性
3.3.5 各项业务服务队客户流失率的影响
3.3.6 合约签订期限对客户流失率的影响
3.3.7 付款方式对客户流失率的影响
四、数据建模
4.1 特征值筛选与转换
4.1.1 特征值筛选
4.1.2 特征值标准化
4.2 数据切分
4.2.1 切分特征与标签
4.2.2 切分训练数据集和测试数据集
4.3 模型训练与评估
4.3.1 模型训练
4.3.2 模型评估
五、模型优化
5.1 决策树预剪枝,绘制最大深度学习曲线
5.2 GridSearchCV网格搜索,寻找最优参数
5.3 构建最优参数模型
六、结论
6.1 总结
6.2 建议
七、源代码
一、项目背景
1.1 流失用户定义
不同产品都存在不同的使用周期,因此在定义流失用户上,需要进行用户调研,如可对时隔1周、1个月、3个月、半年未下单客户进行用户调研,从而了解用户不再产生浏览和购买行为的原因,进而定义流失。
1.2 探究用户流失目的
研究用户流失的首要目的是避免用户继续流失,其次才是挽回流失。在研究过程中,可通过观察用户的生命周期来判断其流失原因:
(1)获取期:新用户通过推广、宣传来到产品中,属尝鲜型;
(2)提升期:用户有购买行为;
(3)成熟期:用户存在复购和交叉购买行为;
(4)衰退期:用户购买行为和频次开始衰退,这是最需要预警的时期;
(5)离开期:达到流失标准;
根据以上五个生命周期为用户打上标签,从而判断用户是在哪个时期流失,相应的流失原因不同,则应采取不同措施对产品进行改进。
1.3 项目描述
1.3.1 项目简介
随着电信行业的竞争日益激烈,获取一个新用户所需的成本已远高于保留现有客户的成本,因此,如何挽留更多的用户已成为电信行业的一项关键业务指标。对于电信行业而言,可通过数据挖掘等方式来分析可能影响客户决策的各种因素,从而预测他们是否会产生流失。
本案例利用Kaggle上公开的某电信公司的用户数据,借此数据集进行分析并建立用户流失预测模型。
1.3.2 分析工具
(1)开发环境:python3、Spyder
(2)相关库的导入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import cross_val_score,train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report,precision_score,recall_score,f1_score
from sklearn.model_selection import GridSearchCV
from sklearn import tree二、数据预处理
2.1 数据采集与预览
#读取数据文件
tel = pd.read_csv(r"C:\Users\HP\Desktop\电信用户流失数据.csv")
#数据预览
tel.info()运行结果:
RangeIndex: 7043 entries, 0 to 7042
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 customerID 7043 non-null object
1 gender 7043 non-null object
2 SeniorCitizen 7043 non-null int64
3 Partner 7043 non-null object
4 Dependents 7043 non-null object
5 tenure 7043 non-null int64
6 PhoneService 7043 non-null object
7 MultipleLines 7043 non-null object
8 InternetService 7043 non-null object
9 OnlineSecurity 7043 non-null object
10 OnlineBackup 7043 non-null object
11 DeviceProtection 7043 non-null object
12 TechSupport 7043 non-null object
13 StreamingTV 7043 non-null object
14 StreamingMovies 7043 non-null object
15 Contract 7043 non-null object
16 PaperlessBilling 7043 non-null object
17 PaymentMethod 7043 non-null object
18 MonthlyCharges 7043 non-null float64
19 TotalCharges 7043 non-null object
20 Churn 7043 non-null object
dtypes: float64(1), int64(2), object(18)从运行结果可知,数据集一共提供了7043条用户样本信息,且无缺失值,其中每条样本包含21列属性,由多个维度的客户特征信息以及用户是否流失的标签组成。 各用户特征信息及相关含义如下:
| 变量名 |
描述 |
数据类型 |
取值 |
| customerID |
用户ID |
string |
7043个不重复值 |
| gender |
性别 |
string |
Male,Female |
| SeniorCitizen |
是否为老年人 |
int |
0,1 |
| Partner |
是否有配偶 |
string |
Yes,NO |
| Dependents |
是否有家属 |
string |
Yes,No |
| tenure |
入网月数 |
int |
0~72 |
| PhoneService |
是否开通电话业务 |
string |
Yes,NO |
| MultipleLines |
是否开通多线业务 |
string |
Yes,No,No phone service |
| InternetService |
是否开通互联网业务 |
string |
DSL, Fiber optic, No |
| OnlineSecurity |
是否开通在线安全业务 |
string |
Yes,No,No internet service |
| OnlineBackup |
是否开通在线备份业务 |
string |
Yes,No,No internet service |
| DeviceProtection |
是否开通设备保护业务 |
string |
Yes,No,No internet service |
| TechSupport |
是否开通技术支持业务 |
string |
Yes,No,No internet service |
| StreamingTV |
是否开通网络电视业务 |
string |
Yes,No,No internet service |
| StreamingMovies |
是否开通网络电影业务 |
string |
Yes,NO,No internet service |
| Contract |
合约期限 |
String |
Month-to-Month,One Year,Two Year |
| PaperlessBilling |
是否采用电子结算 |
string |
Yes,NO |
| PaymentMethod |
付款方式 |
string |
check,Mailed check |
| MonthlyCharges |
每月费用 |
float |
18.25~118.75 |
| TotalCharges |
总费用 |
string |
18.80~8684.80 |
| Churn |
客户是否流失 |
string |
Yes,No |
2.2 数据清洗
2.2.1 数据类型转换
#将TotalCharges强制转换为数值型数据,以便后续分析,不可转换的值变为nan
tel.TotalCharges = pd.to_numeric(tel['TotalCharges'],errors='coerce')
tel['SeniorCitizen'] = tel['SeniorCitizen'].astype('object')2.2.2 缺失值处理
#查看缺失值
pd.isnull(tel).sum()
#删除缺失值
tel.dropna(inplace = True)
#再次查看缺失值
pd.isnull(tel).sum()处理结果:
Out[87]:
customerID 0
gender 0
SeniorCitizen 0
Partner 0
Dependents 0
tenure 0
PhoneService 0
MultipleLines 0
InternetService 0
OnlineSecurity 0
OnlineBackup 0
DeviceProtection 0
TechSupport 0
StreamingTV 0
StreamingMovies 0
Contract 0
PaperlessBilling 0
PaymentMethod 0
MonthlyCharges 0
TotalCharges 0
Churn 0
dtype: int64从输出结果可以看出,处理后的数据集中不含缺失值。
2.2.3 重复值处理
tel = tel.drop_duplicates()
2.2.4 异常值处理
(1)分类数据异常值检测
tel2 = tel.drop(axis=1,columns=['customerID','tenure','MonthlyCharges','TotalCharges'])
#输出分类数据各记录值
for i in tel2.columns:
print(i, "--" ,tel2[i].unique())检测结果:
gender -- ['Female' 'Male']
SeniorCitizen -- [0 1]
Partner -- ['Yes' 'No']
Dependents -- ['No' 'Yes']
PhoneService -- ['No' 'Yes']
MultipleLines -- ['No phone service' 'No' 'Yes']
InternetService -- ['DSL' 'Fiber optic' 'No']
OnlineSecurity -- ['No' 'Yes' 'No internet service']
OnlineBackup -- ['Yes' 'No' 'No internet service']
DeviceProtection -- ['No' 'Yes' 'No internet service']
TechSupport -- ['No' 'Yes' 'No internet service']
StreamingTV -- ['No' 'Yes' 'No internet service']
StreamingMovies -- ['No' 'Yes' 'No internet service']
Contract -- ['Month-to-month' 'One year' 'Two year']
PaperlessBilling -- ['Yes' 'No']
PaymentMethod -- ['Electronic check' 'Mailed check' 'Bank transfer (automatic)' 'Credit card (automatic)']
Churn -- ['No' 'Yes']通过检测结果可知,样本分类特征数据无异常值,因此无需异常处理。
(2)数值型数据异常值检测
#绘制箱线图观察数据异常情况
plt.subplots(3,1,figsize=(14,14))
tel3 = tel[['tenure','MonthlyCharges','TotalCharges']]
for i,j in zip(tel3.columns,(1,2,3)):
plt.subplot(3,1,j)
plt.boxplot(tel3[i],vert=False,widths=0.8)
plt.title(i,fontsize=16)运行结果:

由箱线图可以看出,这三列特征变量中不存在明显的异常值,因此不需要进行异常处理。
三、数据可视化分析
3.1 流失客户占比
#查看用户流失情况
tel['Churn'].value_counts()
#流失客户占比
ch =np.array(tel['Churn'])
ch[ch=='Yes'] = '已流失'
ch[ch=='No'] = '未流失'
df_ch = pd.DataFrame(ch)
labels = df_ch[0].value_counts().index
value =df_ch[0].value_counts()
plt.rcParams['font.sans-serif']=['SimHei']
plt.pie(value, labels=labels, colors=['blue','yellow'], explode=(0.1,0), autopct='%1.1f%%', shadow=True)
plt.title("流失客户占比")
plt.show()
运行结果:
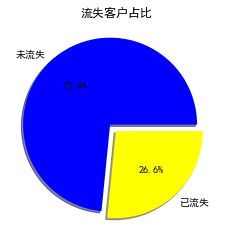
由图中结果可以看出,流失客户只占整体客户的26.6%,这将导致样本数据不均衡。
3.2 样本基本特征对客户流失率的影响
base = ['gender','SeniorCitizen','Partner','Dependents']
#绘制柱形图
plt.subplots(2,2,figsize=(14,14))
for i,j in zip(base,range(4)):
x1 = pd.crosstab(tel[i],tel['Churn']).iloc[:,0]
x2 = pd.crosstab(tel[i],tel['Churn']).iloc[:,1]
plt.subplot(2,2,j+1)
plt.bar(x1.index,x1)
plt.bar(x1.index,x2,bottom=x1)
plt.xticks(x1.index,fontsize=18)
plt.yticks(fontsize=16)
plt.title('Churn by '+ i,fontsize=20)
plt.legend(['No','Yes'],title='Churn',fontsize=14)运行结果:
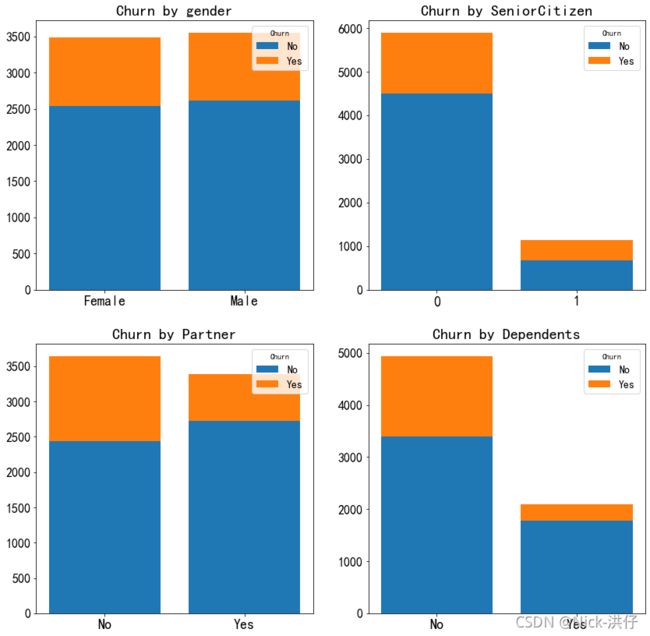
由图中可以看出,男性与女性用户之间的流失情况基本没有差异,即性别对客户流失率没有影响;而老年用户群体中流失占比明显高于非老年群体,因此年龄对客户流失率有影响;在样本数据中未婚用户与已婚用户数量持平,但未婚中流失人数高出已婚近一倍;从经济独立情况看,经济未独立的用户流失率要远远高于经济独立的用户。
3.3 样本特征相关性分析
3.3.1 特征值提取与编码
#选取数字特征进行factorize编码
tel['Churn'].replace('Yes','1',inplace = True)
tel['Churn'].replace('No','0',inplace = True)
df2 = tel.iloc[:,1:18]
fac = df2.apply(lambda x: pd.factorize(x)[0])编码前:

编码后:
3.3.2 构造相关系数矩阵
#构造相关系数矩阵
corr = fac.corr()
3.3.3 使用热力图显示相关系数
plt.figure(figsize=(24,16))
sns.heatmap(corr,xticklabels=corr.columns, yticklabels=corr.columns, linewidths=0.3, cmap='YlGnBu',annot=True)
plt.title('相关系数矩阵热力图',fontsize=20)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)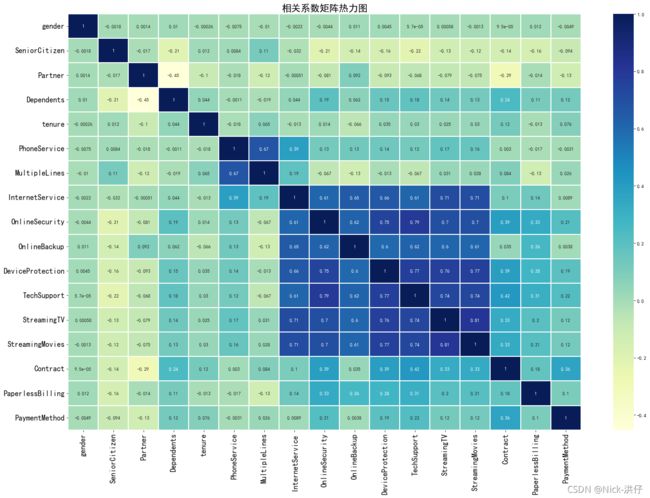
从热力图可以看出,互联网服务、网络安全服务、在线备份业务、设备保护业务、技术支持服务、网络电视以及网络电影之间存在较强的相关性,多线业务和电话服务之间也有很强的相关性,且呈强正相关关系。
3.3.4 电信用户是否流失与各变量之间的相关性
tel['Churn'] = tel['Churn'].astype('int')
tel_dummies = pd.get_dummies(tel.iloc[:,1:21])
plt.figure(figsize=(16,8))
plt.rcParams['axes.unicode_minus']=False
l = tel_dummies.corr()['Churn'].sort_values(ascending=False)
plt.bar(l.index, height=l)
plt.xticks(rotation = 90, fontsize=14)
plt.title('用户是否流失与各变量之间相关性柱状图', fontsize=16)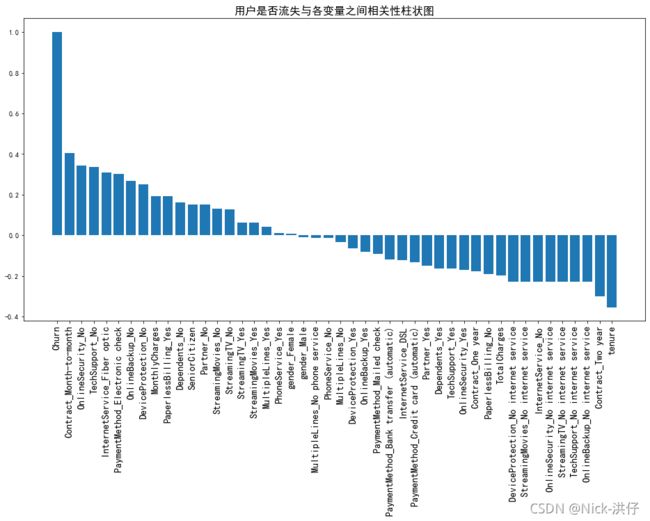
由柱形图可以看出,变量gender和PhoneService的值接近于0,因此这两个变量对电信客户流失预测影响非常小,可以直接舍弃。
3.3.5 各项业务服务对客户流失率的影响
items = ['OnlineSecurity','OnlineBackup','DeviceProtection','TechSupport','StreamingTV','StreamingMovies']
#绘制扇形图
for i,j in zip(items,range(6)):
fig = plt.figure(figsize=(11,4.5))
plt.title('Churn by '+i,fontsize=20)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
for p in range(3):
f = fig.add_subplot(1,3,p+1)
pi = tel[tel['OnlineSecurity'] == tel[i].unique()[p]]['Churn'].value_counts()
f.pie(pi, labels=['No','Yes'], colors=['blue','yellow'], autopct='%1.2f%%', explode=(0.1,0),shadow=True,textprops={'fontsize':14})
plt.tight_layout()
plt.title(str(tel[i].unique()[p]),fontsize=15)
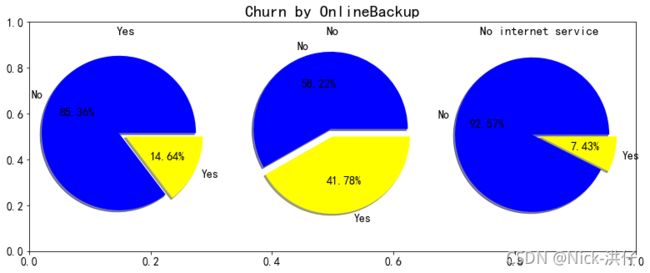

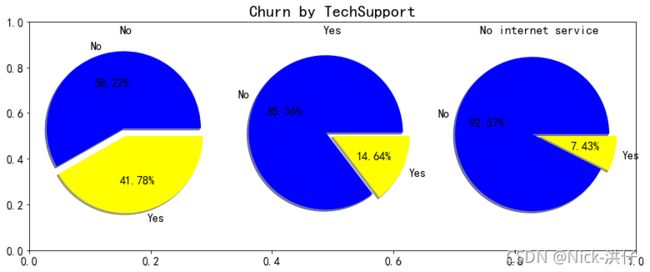

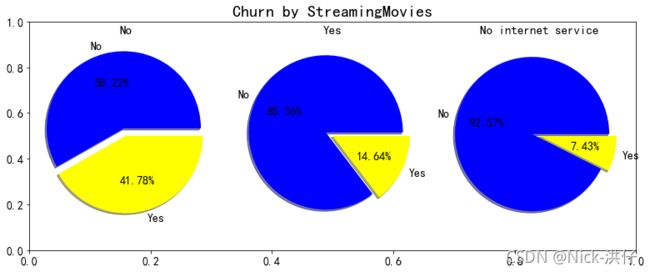
由上图可以看出,在网络安全服务、在线备份业务、设备保护业务、技术支持服务、网络电视和网络电影六个变量中,没有开通互联网服务的客户流失率均为7.43%,可以判断以上六个要素只有在客户使用互联网服务是才会影响客户的决策,而不会对不使用互联网服务的客户决定是否流失产生影响。此外,以上六项互联网服务开通之后的客户流失率明显降低,因此可以认为多绑定业务有助于用户的留存。
3.3.6 合约签订期限对客户流失率的影响
sns.barplot(x="Contract",y="Churn", data=tel, order= ['Month-to-month', 'One year', 'Two year'])
plt.title('Churn by Contract type')
由上图可以看出,合约签订的期限越长,客户流失率越低,可以认为,设定长期合同有助于留住现有客户。
3.3.7 付款方式对客户流失率的影响
plt.figure(figsize=(10,5))
sns.barplot(x="PaymentMethod",y="Churn", data=tel, order= ['Bank transfer (automatic)', 'Credit card (automatic)', 'Electronic check','Mailed check'])
plt.title("Churn by PaymentMethod type") 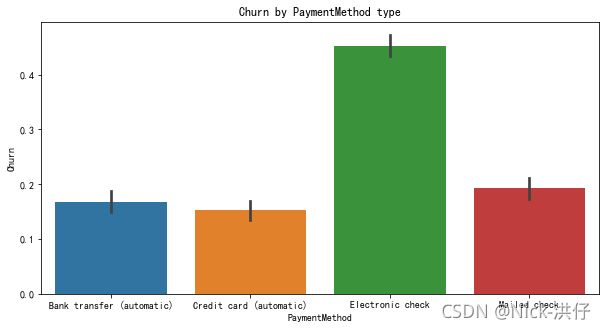
由上图可以看出,在四种支付方式中,使用电子支付的用户流失率远高于其他三种,原因可能是采用电子支付多为签订月合同期限的用户。
四、数据建模
4.1 特征值筛选与转换
4.1.1 特征值筛选
根据前文分析可知,特征值gender、PhoneService与客户流失率相关性低,可认为其对客户是否流失无影响,而CustomerID表示每个客户的随机字符,对后续建模不影响,因此可剔除这三项特征数值。
tel.drop(['customerID', 'gender', 'PhoneService'],inplace=True,axis=1)
tel.shape4.1.2 特征值标准化
由前文可知,各分类特征值的取值情况如下:
gender -- ['Female' 'Male']
SeniorCitizen -- [0 1]
Partner -- ['Yes' 'No']
Dependents -- ['No' 'Yes']
PhoneService -- ['No' 'Yes']
MultipleLines -- ['No phone service' 'No' 'Yes']
InternetService -- ['DSL' 'Fiber optic' 'No']
OnlineSecurity -- ['No' 'Yes' 'No internet service']
OnlineBackup -- ['Yes' 'No' 'No internet service']
DeviceProtection -- ['No' 'Yes' 'No internet service']
TechSupport -- ['No' 'Yes' 'No internet service']
StreamingTV -- ['No' 'Yes' 'No internet service']
StreamingMovies -- ['No' 'Yes' 'No internet service']
Contract -- ['Month-to-month' 'One year' 'Two year']
PaperlessBilling -- ['Yes' 'No']
PaymentMethod -- ['Electronic check' 'Mailed check' 'Bank transfer (automatic)' 'Credit card (automatic)']
Churn -- ['No' 'Yes']综合之前的结果来看,在六个变量中存在No internet service和No phone service,这两个取值与No意义相同,为便于后续建模分析,可分别将其与No合并。
#将No internet service、No phone service分别与No合并
tel.replace(to_replace='No internet service', value='No', inplace=True)
tel.replace(to_replace='No phone service', value='No', inplace=True)
#使用Scikit-learn编码,将分类数据转换为整数编码
def t_encode(col):
tel[col] = LabelEncoder().fit_transform(tel[col])
for i in range(0,len(tel.columns)):
t_encode(tel.columns[i])
tel.index=range(len(tel))将特征值合并并编码后结果如下:
SeniorCitizen -- [0 1]
Partner -- [1 0]
Dependents -- [0 1]
MultipleLines -- [0 1]
InternetService -- [0 1 2]
OnlineSecurity -- [0 1]
OnlineBackup -- [1 0]
DeviceProtection -- [0 1]
TechSupport -- [0 1]
StreamingTV -- [0 1]
StreamingMovies -- [0 1]
Contract -- [0 1 2]
PaperlessBilling -- [1 0]
PaymentMethod -- [2 3 0 1]
Churn -- [0 1]4.2 数据切分
4.2.1 切分特征与标签
X = tel.iloc[:,0:-1]
Y = tel['Churn']
#由于样本中流失用户只有1869条数据,未流失用户有5163条数据,为避免样本不均衡,使用上采样对样本进行补充
sm = SMOTE(random_state=20)
X, Y = sm.fit_resample(X,Y) #补充后样本流失与未流失用户数据均为5163条4.2.2 切分训练数据集和测试数据集
X_train,X_test,Y_train,Y_test = train_test_split(X, Y, test_size=0.2,random_state=0)
for i in [X_train,X_test,Y_train,Y_test]:
i.index = range(i.shape[0])4.3 模型训练与评估
4.3.1 模型训练
trees = DecisionTreeClassifier(random_state=0)
trees = trees.fit(X_train,Y_train)
score = trees.score(X_test,Y_test)
print(score)模型初次训练得分为:0.78702807357212
4.3.2 模型评估
召回率(recall):原本为对的当中,预测结果为对的比例(值越大越好,1为理想状态);
精确度(precision):预测结果为对的当中,原本为对的比例(值越大越好,1为理想状态);
F1分数(F1-Score):(2*r*p)/(r+p),该指标综合Precision与Recall的产出结果。
pred = trees.predict(X_test)
r = recall_score(Y_test,pred)
p = precision_score(Y_test,pred)
f1 = f1_score(Y_test,pred)
print("召回率:" + str(r) + '\n'
"精确度:" + str(p) + '\n'
"f1分数:" + str(f1))召回率:0.7867924528301887
精确度:0.7958015267175572
f1分数:0.7912713472485768
五、模型优化
5.1 决策树预剪枝,绘制最大深度学习曲线
tr = []
te = []
for i in range(20):
trees = DecisionTreeClassifier(random_state=0,max_depth=i+1,criterion='gini')
trees = trees.fit(X_train,Y_train)
score_tr = trees.score(X_train,Y_train)
score_te = cross_val_score(trees,X,Y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
plt.plot(range(1,21),tr,color='red',label='train')
plt.plot(range(1,21),te,color='blue',label='test')
plt.xticks(range(1,21))
plt.legend()
plt.show()
te.index(max(te))
剪枝后最优深度为:7
5.2 GridSearchCV网格搜索,寻找最优参数
#设置超参数取值范围
parameters = {
'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,20)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(X_train,Y_train)
#输出最优参数组合与及其最佳得分
GS.best_params_
GS.best_score_最优参数组合:{'criterion': 'entropy',
'max_depth': 9,
'min_impurity_decrease': 0.0,
'min_samples_leaf': 41,
'splitter': 'best'}
最佳得分:0.8013317191283293
接下来将最优参数组合放入模型中进行训练。
5.3 构建最优参数模型
clf = DecisionTreeClassifier(random_state=0,criterion='entropy',max_depth=9,min_impurity_decrease=0,min_samples_leaf=41,splitter='best')
clf = clf.fit(X_train,Y_train)
score = clf.score(X_test,Y_test)
#模型评估
pred = clf.predict(X_test)
r = recall_score(Y_test,pred)
p = precision_score(Y_test,pred)
f1 = f1_score(Y_test,pred)
print("召回率:" + str(r) + '\n'
"精确度:" + str(p) + '\n'
"f1分数:" + str(f1))召回率:0.8452830188679246
精确度:0.8021486123545211
f1分数:0.8231511254019294
优化后的模型三个得分指标较优化前都有了一定程度的提升,且都达到0.8以上,预测效果较理想,因此可将此模型做为最终预测模型,该模型可视化结果如下:
六、结论
6.1 总结
通过以上分析,我们可以大致归纳出易流失的用户特征:
用户属性:老年用户、未婚用户、经济未独立的用户更容易流失;
服务属性:未开通相关附加增值服务的用户更容易流失;
合同属性:签订的合同期限越短、采用电子支付的用户更容易流失。
此外,是否开通电话服务对用户的留存基本无影响。
6.2 建议
(1)针对老年用户、未婚用户及经济未独立的用户群体,可以根据其喜好特征,为其制定多样化专属套餐,以提升其用户体验,从而降低流失率;
(2)针对存量老客户,可以根据其行为特征分析其购买相关增值服务的可能性,针对可能性较高的用户进行重点宣传,同时将相关增值服务进行捆绑销售,以促使用户进一步购买,加强用户对产品的黏性;对于新用户,可以在购买时赠送相关增值服务体验资格,以增强用户对增值服务的认知度与体验感;
(3)在与客户签订合同时,可以实行相应的价格优惠政策,激励客户签订长期合同,如签订两年期额外赠送两个月优惠,一年期和半年期给予相应程度的优惠等。此外,在用户支付方面,可以问卷调研等形式,了解用户对电子账单支付的体验感并进行改善,同时鼓励宣传用户采用其他方式支付等。
七、源代码
#导入相关库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import cross_val_score,train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report,precision_score,recall_score,f1_score
from sklearn.model_selection import GridSearchCV
from sklearn import tree
#读取数据文件
tel = pd.read_csv(r"C:\Users\HP\Desktop\电信用户流失数据.csv")
#数据预览
tel.info()
#转换数据类型
tel.TotalCharges = pd.to_numeric(tel['TotalCharges'],errors='coerce')
tel['SeniorCitizen'] = tel['SeniorCitizen'].astype('object')
#处理缺失值
pd.isnull(tel).sum()
tel.dropna(inplace = True)
pd.isnull(tel).sum()
#重复值处理
tel = tel.drop_duplicates()
#异常值处理
#分类数据异常值检测
tel2 = tel.drop(axis=1,columns=['customerID','tenure','MonthlyCharges','TotalCharges'])
for i in tel2.columns:
print(i, "--" ,tel2[i].unique())
#数值型数据异常值检测
plt.subplots(3,1,figsize=(14,14))
tel3 = tel[['tenure','MonthlyCharges','TotalCharges']]
for i,j in zip(tel3.columns,(1,2,3)):
plt.subplot(3,1,j)
plt.boxplot(tel3[i],vert=False,widths=0.8)
plt.title(i,fontsize=20)
plt.xticks(fontsize=16)
plt.yticks(fontsize=20)
#查看用户流失情况
tel['Churn'].value_counts()
#流失客户占比
ch =np.array(tel['Churn'])
ch[ch=='Yes'] = '已流失'
ch[ch=='No'] = '未流失'
df_ch = pd.DataFrame(ch)
labels = df_ch[0].value_counts().index
value =df_ch[0].value_counts()
plt.rcParams['font.sans-serif']=['SimHei']
plt.pie(value, labels=labels, colors=['blue','yellow'], explode=(0.1,0), autopct='%1.1f%%', shadow=True)
plt.title("流失客户占比")
plt.show()
#样本基本特征对客户流失率的影响
base = ['gender','SeniorCitizen','Partner','Dependents']
plt.subplots(2,2,figsize=(14,14))
for i,j in zip(base,range(4)):
x1 = pd.crosstab(tel[i],tel['Churn']).iloc[:,0]
x2 = pd.crosstab(tel[i],tel['Churn']).iloc[:,1]
plt.subplot(2,2,j+1)
plt.bar(x1.index,x1)
plt.bar(x1.index,x2,bottom=x1)
plt.xticks(x1.index,fontsize=18)
plt.yticks(fontsize=16)
plt.title('Churn by '+ i,fontsize=20)
plt.legend(['No','Yes'],title='Churn',fontsize=14)
#选取数字特征进行factorize编码
tel['Churn'].replace('Yes','1',inplace = True)
tel['Churn'].replace('No','0',inplace = True)
df2 = tel.iloc[:,1:18]
fac = df2.apply(lambda x: pd.factorize(x)[0])
#构造相关系数矩阵
corr = fac.corr()
print(corr)
corr=corr.astype(float)
#相关系数矩阵的热力图显示
plt.figure(figsize=(24,16))
sns.heatmap(corr,xticklabels=corr.columns, yticklabels=corr.columns, linewidths=0.3, cmap='YlGnBu',annot=True)
plt.title('相关系数矩阵热力图',fontsize=20)
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
#用户是否流失与各变量之间的相关性
tel['Churn'] = tel['Churn'].astype('int')
tel_dummies = pd.get_dummies(tel.iloc[:,1:21])
plt.figure(figsize=(16,8))
plt.rcParams['axes.unicode_minus']=False
l = tel_dummies.corr()['Churn'].sort_values(ascending=False)
plt.bar(l.index, height=l)
plt.xticks(rotation = 90, fontsize=14)
plt.title('用户是否流失与各变量之间相关性柱状图', fontsize=16)
#网络安全服务、在线备份业务、设备保护业务、技术支持服务、网络电视、网络电影和无互联网服务队客户流失率的影响
items = ['OnlineSecurity','OnlineBackup','DeviceProtection','TechSupport','StreamingTV','StreamingMovies']
for i,j in zip(items,range(6)):
fig = plt.figure(figsize=(11,4.5))
plt.title('Churn by '+i,fontsize=20)
plt.xticks(fontsize=14)
plt.yticks(fontsize=14)
for p in range(3):
f = fig.add_subplot(1,3,p+1)
pi = tel[tel['OnlineSecurity'] == tel[i].unique()[p]]['Churn'].value_counts()
f.pie(pi, labels=['No','Yes'], colors=['blue','yellow'], autopct='%1.2f%%', explode=(0.1,0),shadow=True,textprops={'fontsize':14})
plt.tight_layout()
plt.title(str(tel[i].unique()[p]),fontsize=15)
#合约签订期限对客户流失率的影响
sns.barplot(x="Contract",y="Churn", data=tel, order= ['Month-to-month', 'One year', 'Two year'])
plt.title('Churn by Contract type')
#付款方式对客户流失率的影响
plt.figure(figsize=(10,5))
sns.barplot(x="PaymentMethod",y="Churn", data=tel, order= ['Bank transfer (automatic)', 'Credit card (automatic)', 'Electronic check','Mailed check'])
plt.title("Churn by PaymentMethod type")
#特征值的筛选
tel.drop(['customerID', 'gender', 'PhoneService'],inplace=True,axis=1)
tel.shape
#特征值替换
tel.replace(to_replace='No internet service', value='No', inplace=True)
tel.replace(to_replace='No phone service', value='No', inplace=True)
#特征值标准化
def t_encode(col):
tel[col] = LabelEncoder().fit_transform(tel[col])
for i in range(0,len(tel.columns)):
t_encode(tel.columns[i])
tel.index=range(len(tel))
for i in tel.columns:
print(i, "--" ,tel[i].unique())
#切分特征与标签
X = tel.iloc[:,0:-1]
Y = tel['Churn']
sm = SMOTE(random_state=20)
X, Y = sm.fit_resample(X,Y)
pd.Series(Y).value_counts()
#切分训练数据集和测试数据集
X_train,X_test,Y_train,Y_test = train_test_split(X, Y, test_size=0.2,random_state=0)
for i in [X_train,X_test,Y_train,Y_test]:
i.index = range(i.shape[0])
#模型训练与评估
#模型训练
trees = DecisionTreeClassifier(random_state=0)
trees = trees.fit(X_train,Y_train)
score = trees.score(X_test,Y_test)
print(score)
#模型评估
pred = trees.predict(X_test)
r = recall_score(Y_test,pred)
p = precision_score(Y_test,pred)
f1 = f1_score(Y_test,pred)
print("召回率:" + str(r) + '\n'
"精确度:" + str(p) + '\n'
"f1分数:" + str(f1))
#模型优化,剪枝,绘制最大深度学习曲线
tr = []
te = []
for i in range(20):
trees = DecisionTreeClassifier(random_state=0,max_depth=i+1,criterion='gini')
trees = trees.fit(X_train,Y_train)
score_tr = trees.score(X_train,Y_train)
score_te = cross_val_score(trees,X,Y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
plt.plot(range(1,21),tr,color='red',label='train')
plt.plot(range(1,21),te,color='blue',label='test')
plt.xticks(range(1,21))
plt.legend()
plt.show()
te.index(max(te))
#网格搜索,寻找最优参数
parameters = {
'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,20)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(X_train,Y_train)
#查看最优参数组合
GS.best_params_
GS.best_score_
#将最优参数组合导入模型进行训练
clf = DecisionTreeClassifier(random_state=0,criterion='entropy',max_depth=9,min_impurity_decrease=0,min_samples_leaf=41,splitter='best')
#拟合数据
clf = clf.fit(X_train,Y_train)
score = clf.score(X_test,Y_test)
score
#查看优化后各预测得分指标
pred = clf.predict(X_test)
r = recall_score(Y_test,pred)
p = precision_score(Y_test,pred)
f1 = f1_score(Y_test,pred)
print("召回率:" + str(r) + '\n'
"精确度:" + str(p) + '\n'
"f1分数:" + str(f1))
#决策树可视化
fig, axes = plt.subplots(nrows = 1,ncols = 1,figsize = (160,80), dpi=70)
tree.plot_tree(clf,filled = True)
fig.savefig(r"C:\Users\HP\Desktop\决策树.png")