mysql事务和锁 SELECT FOR UPDATE
mysql事务和锁 SELECT FOR UPDATE
事务:
当然有的人用begin /begin work .推荐用START TRANSACTION 是SQL-99标准启动一个事务。
start transaction #开始一个事务
操作
savepoint sp1 #保存点名称
操作
ROLLBACK
ROLLBACK To sp1 #回退到 sp1点
commit当用set autocommit = 0 的时候,你以后所有的sql都将作为事务处理,直到你用commit确认或 rollback结束,注意当你结束这个事务的同时也开启了新的事务!mysql 默认 autocommit=1,是自动提交的。
隔离级别
SQL标准定义的四个隔离级别为:
1.读未提交(Read Uncommitted):在READ COMMITED的事务隔离级别下,除了唯一性的约束检查以及外键约束的检查需要Gap Lock,InnoDB存储引擎不会使用Gap Lock的锁算法。这种隔离级别可以让当前事务读取到其它事物还没有提交的数据。这种读取应该是在回滚段中完成的。通过上面的分析,这种隔离级别是最低的,会导致引发脏读,不可重复读,和幻读。
2.读已提交(Read Committed):这种隔离级别可以让当前事务读取到其它事物已经提交的数据。通过上面的分析,这种隔离级别会导致引发不可重复读,和幻读。
3.可重复读取(Repeatable Read):这种隔离级别可以保证在一个事物中多次读取特定记录的时候都是一样的。通过上面的分析,这种隔离级别会导致引发幻读。
4.串行(Serializable):在SERIALIZBLE的事务隔离级别,InnoDB存储引擎会对每个SELECT语句后自动加上LOCK IN SHARE MODE,即给每个读取操作加一个共享锁,因此在这个事务隔离级别下,读占用锁了,一致性的非锁定读不再予以支持,一般不再本地事务中使用SERIALIZBLE的隔离级别,SERIALIZABLE的事务隔离级别主要用于InnoDB存储引擎的分布式事务。
查看当前会话的事务隔离级别
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set (0.03 sec)查看全局事务隔离级别
mysql> select @@global.tx_isolation;
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| REPEATABLE-READ |
+-----------------------+
1 row in set (0.04 sec)分布式事务
通过XA事务可以来支持分布式事务的实现,在使用分布式事务时,InnoDB存储引擎必须使用SERIALIZABLE的隔离级别,查看是否启用了XA事务支持(默认开启)
mysql> show variables like 'innodb_support_xa';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| innodb_support_xa | ON |
+-------------------+-------+mysql悲观锁
悲观锁,正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度,因此,在整个数据处理过程中,将数据处于锁定状态。悲观锁的实现,往往依靠数据库提供的锁机制(也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据)。
MySQL SELECT ... FOR UPDATE 的Row Lock 与Table Lock
举个例子:
使用场景:机器池resource表中有一个字段 status,status=0代表机器未被使用,status =job_id(!=0)表示机器已被某个job使用,那么分配机器时就要确保该机器 status=0。
如果不采用锁,那么操作方法如下:
1.查询出机器信息:select resource_id from resource where status=0 limit 1;
2.将该机器分配给该 job:update resource set status= where resource_id =<刚查出的>; 上面这种场景在高并发访问的情况下很可能会出现问题:在A连接查出 status=0的任务时,当我们执行到第二步时 update时,可能有B 连接已经先把该 resource 的status更新为该 job_id,当 A 连接再更新时,会将 B 的更新覆盖掉。所以说这种方式是不安全的
所以应该使用锁机制,当我们在查询出goods信息后就把当前的数据锁定,直到我们修改完毕后再解锁。
设置MySQL为非autocommit模式:
set autocommit=0;
设置完autocommit后,我们就可以执行我们的正常业务了。具体如下:
//0.开始事务
begin;/begin work;/start transaction; (三者选一就可以,推荐start transaction)
//1.查询出商品信息
select resource_id from resource where status=0 limit 1 for update;
//2.修改商品status为2
update resource set status= where resource_id=;
//4.提交事务
commit;/commit work; 假设有个表单products ,里面有id 跟name 二个栏位,id 是主键。
例1: (明确指定主键,并且有此数据,row lock)
SELECT * FROM products WHERE id='3' FOR UPDATE;
例2: (明确指定主键,若查无此数据,无lock)
SELECT * FROM products WHERE id='-1' FOR UPDATE;
例2: (无主键,table lock)
SELECT * FROM products WHERE name='Mouse' FOR UPDATE;
例3: (主键不明确,table lock)
SELECT * FROM products WHERE id<>'3' FOR UPDATE;
例4: (主键不明确,table lock)
SELECT * FROM products WHERE id LIKE '3' FOR UPDATE;
注1: FOR UPDATE 仅适用于InnoDB,且必须在事务区块(start sta/COMMIT)中才能生效。
注2: 要测试锁定的状况,可以利用MySQL 的Command Mode ,开二个视窗来做测试。
以上就是关于数据库主键对MySQL锁级别的影响实例,需要注意的是,除了主键外,使用索引也会影响数据库的锁定级别
因为悲观锁大多数情况下依靠数据库的锁机制实现,以保证操作最大程度的独占性。如果加锁的时间过长,其他用户长时间无法访问,影响了程序的并发访问性,同时这样对数据库性能开销影响也很大,特别是对长事务而言,这样的开销往往无法承受。所以与悲观锁相对的,我们有了乐观锁,具体参见下面介绍:
mysql 乐观锁
乐观锁( Optimistic Locking ) 相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。那么我们如何实现乐观锁呢,一般来说有以下2种方式:
1.使用数据版本(Version)记录机制实现,这是乐观锁最常用的一种实现方式。何谓数据版本?即为数据增加一个版本标识,一般是通过为数据库表增加一个数字类型的 “version” 字段来实现。当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的version值进行比对,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据。用下面的一张图来说明:
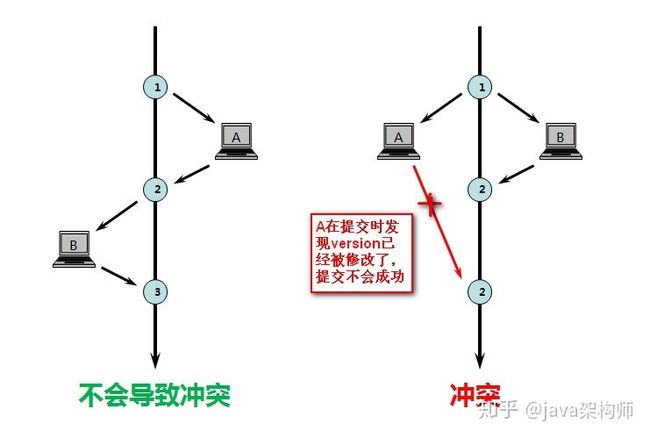
举例:
还是机器池资源表 resource ,除了resource_id,machine_name,status,再增加 version字段,
1.查询出机器信息:
select resource_id,version from resource where status=0 limit 1;
2.将该机器分配给该 job:
update resource set status= where resource_id =<刚查出的> and version=<刚查出 version+1>; 这样就实现了乐观锁。
小编是一个有着5年工作经验的java'开发工程师,关于java'编程,自己有做材料的整合,一个完整的java编程学习路线,学习材料和工具,能够进我的群收取,免费送给**830783865**大家,希望你也能凭着自己的努力,成为下一个优秀的程序员。