AlexNet论文解读以Pytorch实现
AlexNet论文解读以Pytorch实现
- 一、AlexNet背景
-
- 1、ILSVRC
- 2、GPU
- 二、AlexNet研究成果及意义
-
- 1、研究成果
- 2、研究意义
- 三、AlexNet网络结构
-
- 1、网络结构层的具体操作
- 2、具体操作
-
- (1)激活函数
- (2)LRN(目前几乎不采用)
- (3)pooling(池化)
- 四、AlexNet训练技巧
-
- 1、Data Augmentation
- 2、Dropout
- 五、实验结果即分析
-
- 1、实验结果
- 2、卷积核可视化
- 3、特征的相似性
- 六、结论
- 七、代码实现
作者是:加拿大多伦多大学 的 Alex Krizhevsky(第一作者)
下面给出论文
《ImageNet Classification with Deep ConvolutionalNeural Networks》
一、AlexNet背景
1、ILSVRC
在讨论AlexNet之前,首先要知道一个著名的竞赛,即ILSVRC(ImageNet Large Scale Visual Recognition Challenge)大规模图像识别挑战赛,是李飞飞等人于2010年创办的图像识别挑战赛,自2010年已经举办了8届。也是近年来机器视觉领域最受追捧也是最具权威的学术竞赛之一。
比赛项目涵盖:图像分类(lassification)、目标定位(Object localization)、目标检测(Object detection)、视频目标检测(Object detection from video)、场景分类(Scene classification)、场景解析(Scene parsing)。
竞赛中脱颖而出大量经典模型: alexnet, vgg, googlenet, resnet, densenet等
实际上ILSVRC数据集不等同于ImageNet数据集,而是从中挑选出来的。大规模的数据集为AlexNet成功大下了基础。

下面是ILSVRC的网址链接
ILSVRC网址
2、GPU
Alexnet的成功除了得益于大规模的数据集还得意于强大的计算资源即GPU
二、AlexNet研究成果及意义
1、研究成果
AlexNet在ILSVRC-2012以超出第二名10.9个百分点夺冠。下表是错误率
| Model | Top-1(val) | Top-5(val) | Top-5(test) | 注 |
|---|---|---|---|---|
| SIFT+FVs[7] | - | - | 26.2% | ILSVRC 2012分类任务第二名的结果 |
| 1 CNN | 40.7% | 18.2% | - | 训练一个AlexNet的结果 |
| 5 CNNs | 38.1% | 16.4% | 16.4% | 训练五个AlexNet取平均值结果 |
| 1 CNN* | 39.0% | 16.6% | - | 最后一个池化层后额外添加第六个卷积层并使用ImageNet 2011 (秋) 数据集预训练 |
| 7 CNNs* | 36.7% | 15.4% | 15.3% | 两个预训练微调,与5CNNs取平均值 |
2、研究意义
2012年之前分类任务大都采用机器学习方法即特征提取->特征筛选->输入分类机器。
2012年之后采用深度学习方法,即将特征工程与分类集于一体。
由此拉开了卷积神经网络统治计算机视觉的序幕,加速了计算机视觉应用的落地。
三、AlexNet网络结构
1、网络结构层的具体操作
下面是论文中作者的网络结构图
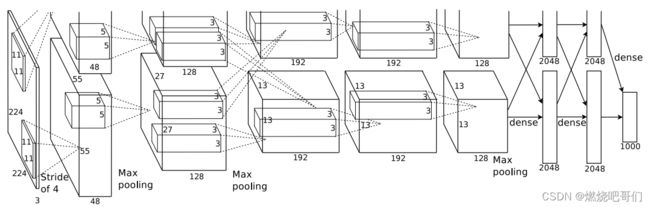
首先我们要知道AlexNet网络的一些基础:
1、由5层卷积层和3层全连接层网络构成。
2、由于算力限制,作者分两个GPU进行训练(图中上下代表两个GPU,第1层和第3层与前面所有信息进行连接,不过以现在的GPU算力用一块GPU也可以)
3、LRN(之后介绍)在第1个和第2个卷积层之后出现,不过之后有论文提出LRN所起的效果不明显,pytorch中将其去掉了。
4、pooling:第1、2、5个卷积层之后出现
5、ReLU:所有层都采用
6、Dropout:在前两层全连接层中使用
第一层操作:
conv1->ReLU->Pool->LRN
关于论文中作者输入图像大小是224*224说法上有一定问题,根据公式在没有padding的情况下,计算(224-11)/4+1=54与论文原图中的55不一致,若不加入padding输入大小应该为227 * 227,pytorch中导入的模型AlexNet网络将padding设置为了2.
第二层操作:
conv2->ReLU->Pool->LRN
第三层操作:
conv3->ReLU
这里实现了特征层的交互
第四层操作:
conv4->ReLU
第五层操作:
conv5->ReLU->Pool
第六层操作:
Dropout->Linear->ReLu
第七层操作:
Dropout->Linear->ReLu
第八层操作:
Linear
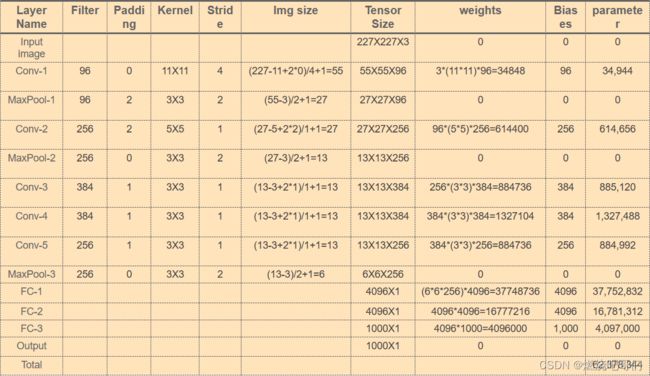
下面这张图是每层的尺寸计算,以及参数量大小,关于相关的一些计算之前的基础文章很详细的讲解了,这里不再过度强调。
2、具体操作
(1)激活函数
激活函数在我的这篇文章中提到过
卷积神经网络的深入理解-基础篇(卷积,激活,池化,误差反传)
论文中作者提到了两种饱和的激活函数sigmoid激活函数和tanh激活函数

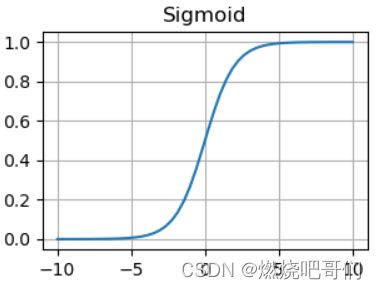

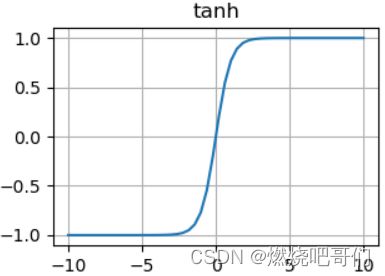
认为饱和的激活函数梯度下降会比较慢,故采用了非饱和的激活函数,以加快梯度下降的速度。
![]()
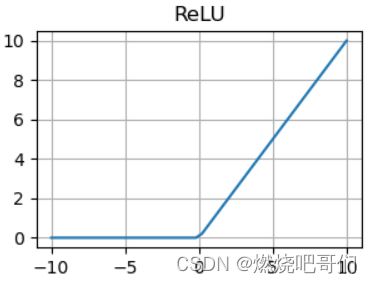
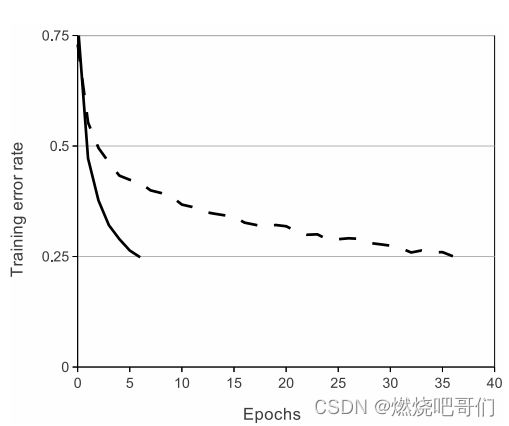
上图是作者用四层网络做的一个实验,在错误率下降到0.25时采用非饱和激活函数ReLU比饱和激活函数tanh快了六倍。
(2)LRN(目前几乎不采用)
全称Local Response Normalization,局部响应标准化,其受启发于侧抑制(lateral inhibition):细胞分化变为不同时,它会对周围细胞产生抑制信号,阻止他们向相同方向分化,最终表现为细胞命运的不同
论文中采用LRN在top-1和top-5的错误率上分别下降了1.4%和1.2%。
公式如下:
b x , y i = a x , y i / ( k + α ∑ j = m a x ( 0 , i − n / 2 ) m i n ( N − 1 , i + n / 2 ) ( a x , y i ) 2 ) β b_{x,y}^{i}=a_{x,y}^{i}/(k+\alpha \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}(a_{x,y}^{i})^2)^{\beta } bx,yi=ax,yi/(k+αj=max(0,i−n/2)∑min(N−1,i+n/2)(ax,yi)2)β
看着比较复杂,不过原理相对简单,
先来看下图,
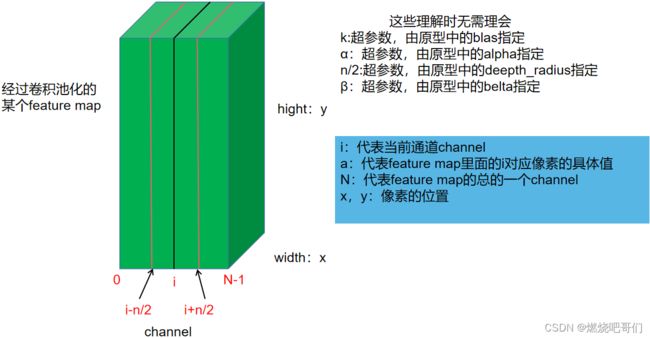
下图中假设当前位置的值为 a x , y i a_{x,y}^{i} ax,yi,那么根据LRN的原理,它必然受 i i i这个通道周围通道值得影响,假设 a x , y i a_{x,y}^{i} ax,yi受周围 n / 2 n/2 n/2个通道的值的影响,那么显然 a x , y i a_{x,y}^{i} ax,yi周围的值越大经过LRN后得到的 b x , y i b_{x,y}^{i} bx,yi的值就应该越小
( k + α ∑ j = m a x ( 0 , i − n / 2 ) m i n ( N − 1 , i + n / 2 ) ( a x , y i ) 2 ) β 就 代 表 了 周 围 的 值 , (k+\alpha \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}(a_{x,y}^{i})^2)^{\beta }就代表了周围的值, (k+αj=max(0,i−n/2)∑min(N−1,i+n/2)(ax,yi)2)β就代表了周围的值,
a x , y i 表 示 原 先 的 值 , a_{x,y}^{i}表示原先的值, ax,yi表示原先的值,
b x , y i 表 示 经 过 抑 制 的 值 b_{x,y}^{i}表示经过抑制的值 bx,yi表示经过抑制的值
论文中采用LRN在top-1和top-5的错误率上分别下降了1.4%和1.2%。
(3)pooling(池化)
Overlapping Pooling(带重叠的池化),其实就是设置了步长的一个池化,之前的文章中我也具体介绍过,这里不再细讲。作者所采用的是核大小为3, 步长为2的一个池化,在top-1和 top-5的错误率上分别下降了0.4%和0.3%。
四、AlexNet训练技巧
1、Data Augmentation
论文中采用如下技巧
(1)针对位置
训练阶段:
1、图片统一缩放至256256
2、随机位置裁剪出224224区域(这里改为227*227)
3、随机进行水平翻转
测试阶段:
1、图片统一缩放至256256
2、裁剪出5个224224区域(这里改为227227)
3、均进行水平翻转,共得到10张224224图片(这里改为227*227)
(2)针对颜色
通过PCA方法修改RGB通道的像素值,实现颜色扰动,效果有限,仅在top-1提升1个点(top-1 acc约62.5%),PCA方法比较麻烦,现在使用也比较少。
2、Dropout
这里我在神经网络基础部分也详细介绍过,不再细说。随机的停止某些神经元的计算,训练的时候采用,测试的时候停止。
五、实验结果即分析
1、实验结果
| Model | Top-1(val) | Top-5(val) | Top-5(test) | 注 |
|---|---|---|---|---|
| SIFT+FVs[7] | - | - | 26.2% | ILSVRC 2012分类任务第二名的结果 |
| 1 CNN | 40.7% | 18.2% | - | 训练一个AlexNet的结果 |
| 5 CNNs | 38.1% | 16.4% | 16.4% | 训练五个AlexNet取平均值结果 |
| 1 CNN* | 39.0% | 16.6% | - | 最后一个池化层后额外添加第六个卷积层并使用ImageNet 2011 (秋) 数据集预训练 |
| 7 CNNs* | 36.7% | 15.4% | 15.3% | 两个预训练微调,与5CNNs取平均值 |
集成思想
2、卷积核可视化

如图所示这个是在输入图像224 * 224(这里改为227 * 227)也就是第一层进行11*11的一个卷积核的可视化,作者发现,训练过程中会出现这种现象,GPU1核学习到了包含频率和方向的特征,而GPU2核学习到了包含颜色的特征。
3、特征的相似性

相似图片第二个全连接层输出的特征向量的欧式距离相近。由此得到启发启发:可以用AlexNet提取高级特征进行图像检索、图像聚类、图像编码,这里其实已经有很多网络采用了这种思想,比如行人重识别。
六、结论
网络层之间是有一定相关性的,移除或是加入一层都会影响网络的性能。作者在论文中提到移除任何中间层都会引起网络损失大约2%的top-1性能。