Paper Reading - 综述系列 - Everything you need to know about NAS(下)
目录
One-Shot
Efficient Nerual Architecture Search
Slimmable Neural Networks
BigNAS
AutoML
Summary
Paper Reading - NAS系列 - Everything you need to know about NAS - 综述 - 知乎
接着上文继续说,接下来主要阐述目前主流的One-Shot NAS方法
One-Shot
最开始关于NAS思路是利用将神经网络模型结构抽象化,从小网络或者各个独立模块开始,进行堆叠添加最终得到一个完整的模型,自底向上。
One-Shot则是自顶向下,先训练一次 超网Supernet,随后针对各种计算资源,得到多种不同的 sub-network。且一般分成两个阶段,分别是 training stage 和 searching stage,那么本文会接着介绍一下比较经典的OneShot NAS论文
Efficient Nerual Architecture Search
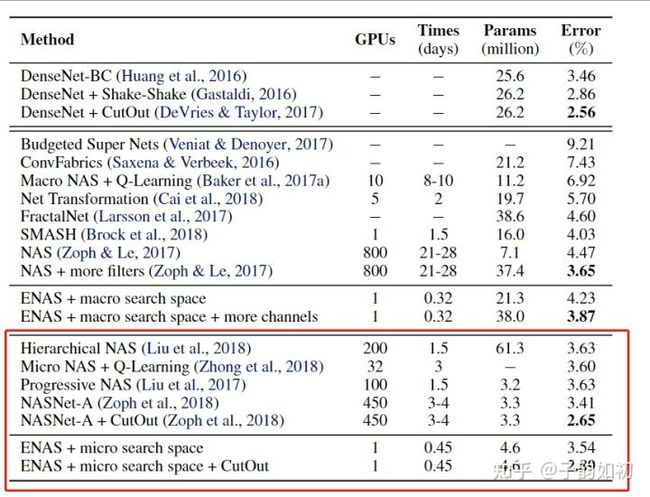
Efficient Nerual Architecture Search(ENAS) 的提出大大减少了nas过程的计算量。作者假设 NAS 的计算瓶颈在于当前NAS方法需要对每个模型进行收敛的训练,测试其准确率,然后就丢掉该模型训练过的权重以及所有信息。
但是在研究和实践中已经反复证明,接受过类似训练任务的网络具有相似的权重,迁移学习有助于在短时间内实现更高的精度。ENAS 算法强制让所有模型共享权重,而不是去从头训练从头收敛。 因此,每次训练新的模型的时候,实际上都进行了迁移学习,这样收敛速度会非常快。
ENAS任务NAS中的候选网络可以被认为是一个从超网络结构中抽取得到的有向无环子图,超网保证节点直接都进行连接,从超网中采样就能得到的一个单向无环图,这样ENAS就可以让所有子网络都共享相同的参数。然后ENAS使用LSTM作为控制器在超网络结构中找到最优子网络结构。因此可以避免让每个子网络从头开始训练,可以更好地提高网络的搜索效率。
在 ENAS 中,有两组可学习参数,Controller LSTM 中的参数θ 和 子模型共享的权重参数w。具体流程是:
- LSTM 采用出一个子模型,然后训练模型w, 通过标准的反向传播算法进行训练,训练完成以后在验证集上进行测试。
- 通过验证集上结果反馈给 LSTM,计算θ 的梯度,更新 LSTM 的参数。
- 如此进行迭代,可以训练出一个 LSTM 能够让模型在验证集上的性能最佳。
下表显示了使用单个 1080Ti 进行训练,使用 ENAS 的效率要高得多。
Slimmable Neural Networks
对于NAS的工程性也是不可忽略的一个问题,也就是是说如何在一定的计算资源(内存,算力和latency)下运行的模型。以往的工程师的做法一般是针对目前的计算设备重新设计并训练一个模型,得到合适的网络。如此是费时费力的
Slimmable neural networks作者希望能够训练一个宽度可变的模型,在部署时,工程师能够根据计算资源限制来选择特定的宽,因此作者直接在一个权重共享的网络上面对于不同宽度进行训练,不过这样会导致无法收敛。作者分析是因为feature map的channel不同,导致channel的mean和varience不同。随后给每个网络设置了独立的BN解决
BigNAS
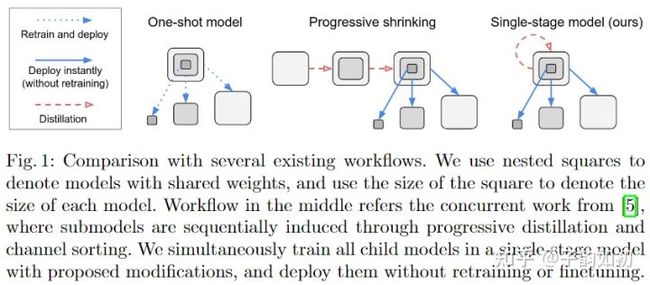
在One-Shot NAS被提出后大家倾向于直接训练一个总模型,比如之前提到的的DARTS,ENAS。然后再从总模型上采样得到符合条件的最优子模型进行重新训练、微调得到特定模型。但是在得到总模型后,后续生成子模型后的处理比较耗时,给整个流程增加了额外的计算量和复杂度。因此BigNAS的致力于解决这一问题,使得在大模型训练完成后,可以不用后续处理,直接生成各种尺寸的子模型就能达到最优的效果。
想法是非常好的,但是如何实现呢,训练超网会遇到以下难题
- 初始化:如果正确的初始化以适应大小模型。
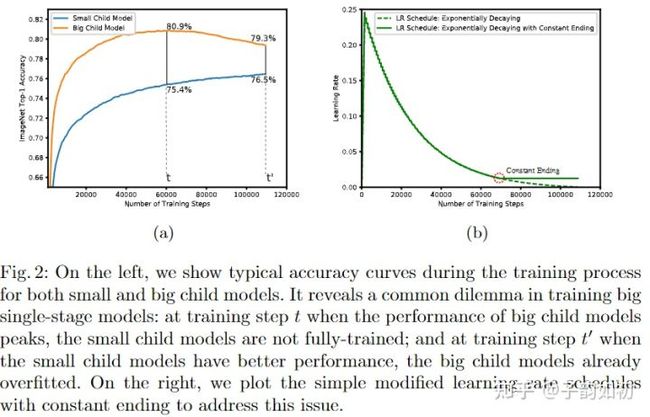
- 收敛情况不一致:大小模型不能同时收敛,且大模型更容易过拟合。
- 如何解决不同channel模型大小的正则化
文中对应问题解决的trick也非常扎实,文中每个单独段落列出了以下tricks
- SandwichRule 训练中首先采样空间中的最小最大模型,随后中间尺寸的模型随机采样n个,累计梯度一次更新。直观上来说也是合理的如此做可同时提升搜索空间中的所有子模型
- InplaceDistillation 使用最大模型的输出作为其他模型的soft label,同样也是类似的蒸馏的办法,并且减少了计算量,不用重复计算模型输出
- Initialization 同样也是使用到了之前提到的trick,设定每个残差块中最后一项BN的缩放参数γ为0,稳定训练
- Convergence Behavior 针对大小模型拟合问题使用指数衰减的方法降低学习率,在学习率达到初始设定值5%时,将学习率保持恒定。这样使用稍大一点的学习率可以让小模型学的更快,在大模型达到精度峰值时使用恒定的学习率会使梯度震荡不陷入局部最优从而缓解过拟合现象
- Regularization 只对最大的模型进行正则化(weight decay + dropout),因为只有最大的模型能够直接接触标签
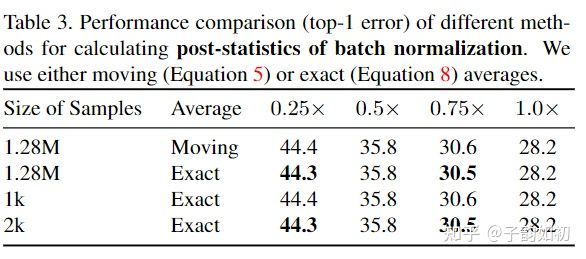
- Batch Norm Calibration 由于训练阶段是多模型训练,所以这些BN统计值的定义有问题。在模型训练结束后,作者直接重新对BN的统计量做校准参考了Universally Slimmable Networks and Improved Training Techniques。作者没有细说,slim中直接一个子网重新统计BN的mean和varience,不去计算梯度,batchsize可以很大,计算也较快且最终实验使用的统计方法是Exact Average而不是滑动平均
AutoML
AutoML 作为深度学习的新方法,无需设计复杂的深度网络,只需运行内置的 NAS 算法。例如Google Cloud AutoML 只需上传数据,Google 的 NAS 算法即可为你提供快速简便的网络架构。AutoML 做法是简单地抽象出深度学习的所有复杂部分。用户只需要提供数据。剩下的让 AutoML 来处理。这样一来,深度学习就会像其他工具一样,成为插件工具。

Summary
使用 ENAS 经过一天的训练就可以得到相当不错的结果。但是我们的搜索空间仍然非常有限,目前的 NAS 算法仍然使用手工设计的结构和构建块,只是将它们以不同的方式组合在一起而已。并且相对于普通训练,NAS算法在训练以及推理部分所需要的资源以及复杂度还是远远不足以支持落地。后续也会持续关注NAS领域发展
相关文章
Once-for-All: Train One Network and Specialize it for Efficient Deployment
DARTS: Differentiable Architecture Search
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
BigNAS: Scaling Up Neural Architecture Search with Big Single-Stage Models
Slimmable Neural Networks