二叉搜索树笔记及模拟实现
文章目录
- 二叉搜索树
-
- 概念
-
- 中译中
- 要点
- 例子
- 二叉搜索树有什么用(这种结构的优点在哪?)
- 二叉搜索树的实现
-
- 二叉搜索树的结点
- 框架
- 默认构造
- 拷贝构造
- 赋值重载
-
- 不存在拷贝构造
- 存在拷贝构造
- 查找
-
- 非递归写法
- 递归写法
- 插入
-
- 非递归写法
- 递归写法
- 删除
-
- 非递归写法
- 递归写法
- 闲谈
- K模型
- KV模型
- 小结
- K模型
- KV模型
- 小结
二叉搜索树
概念
二叉查找树 (Binary Search Tree),它或者是一棵空树,或者是具有下列性质的 二叉树 : 若它的左子树不空,则左子树上所有结点的值均小于它的 根结点 的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为 二叉排序树 。–百度百科
中译中
- 左子树所有节点小于根节点,右子树所有节点大于根节点,同时左子树和右子树都是二叉搜索树
- 空树是二叉搜索树
要点
- 空树也是二叉搜索树
- 二叉搜索树也叫二叉排序树,有序二叉树等
- 同一组数据构成的二叉搜索树可能不同
- 二叉搜索树没有相同的数据,传送门,大体意思就是构造二叉搜索树时,插入的结点一定树里是没有出现过的同时插入的结点肯定会作为叶子结点。如果树里存在(出现了)要插入的结点(结点的值一样就叫出现过),那么就不插入。
- 二叉搜索树的中序遍历序列是升序序列,以int为例,遍历完肯定是1,2,3,4,5,6,7这种升序序列
例子
二进制树可视化器 - 二叉搜索树 (melezinek.cz)
二叉搜索树,AVL树 - VisuAlgo
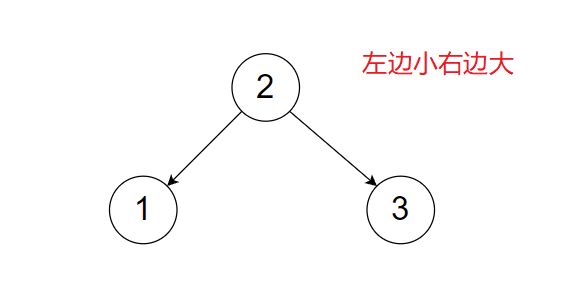

二叉搜索树有什么用(这种结构的优点在哪?)
搜索和动态排序,理论上二叉搜索树的查找、插入和删除的时间一般是是O(logn),但是这是最好情况,实际上进行这些操作的效率与这棵树的结构密切相关,左右子树高度相差较小时效率高,相差较大时效率低,而左右子树的高度与根结点值的选择密切相关。考虑最坏情况(单支树),所以二叉搜索树各操作的时间复杂度是O(N)
二叉搜索树的实现
二叉搜索树的结点
template
struct BSTreeNode
{
BSTreeNode(const K&key=K())//给定默认的
:left(nullptr)
,right(nullptr)
,val(key)
{}
BSTreeNode* left;//指向左孩子
BSTreeNode* right;//指向右孩子
K val;//结点的值
};

框架
template //模板
class BSTree
{
public:
typedef BSTreeNode Node;
BSTree();
//bool insert(const K& key);
//bool Erase(const K& key);
//Node* find(const K& key);
BSTree(const BSTree& t);
const BSTree& operator=(const BSTree& t);
const BSTree& operator=(const BSTree t);
~BSTree();
Node* find(const K& key);
bool Insert(const K& key);//找到位置然后插入
bool EraseR(const K& key);
bool Erase(const K& key);
void InOrder();
private:
Node* _root;
bool _EraseR(Node*& root, const K& key);//递归必须传引用 传引用,即传实参相当于多了个parent指针
bool _Insert(Node*& root, const K& key);//递归版本的的子函数
Node* _find(Node*& root, const K& key);//递归版本的的子函数
void _Destroy(Node* node);//递归版本的的子函数
Node* _Copy(Node* root);//递归版本的的子函数
void _InOrder(Node* root);//递归版本的的子函数
};
默认构造
BSTree()
:_root(nullptr)
{}

拷贝构造
-
递归拷贝一棵树
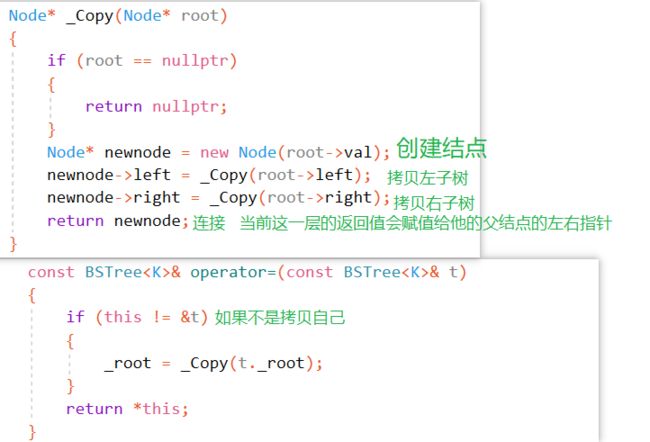
Node* _Copy(Node* root)//拷贝一棵树 { if (root == nullptr) { return nullptr; } Node* newnode = new Node(root->val); newnode->left = _Copy(root->left); newnode->right = _Copy(root->right); return newnode; } BSTree(const BSTree& t) { _root = _Copy(t._root); }
赋值重载
不存在拷贝构造
- 树的赋值重载本质上就是拷贝一棵树,递归拷贝
因为没有拷贝帮忙构造出一棵临时数,所以得一个节点一个节点的拷贝
- 传参传的是引用
Node* _Copy(Node* root)
{
if (root == nullptr)
{
return nullptr;
}
Node* newnode = new Node(root->val);
newnode->left = _Copy(root->left);
newnode->right = _Copy(root->right);
return newnode;
}
const BSTree& operator=(const BSTree& t)//赋值重载
{
if (this != &t)
{
_root = _Copy(t._root);
}
return *this;
}
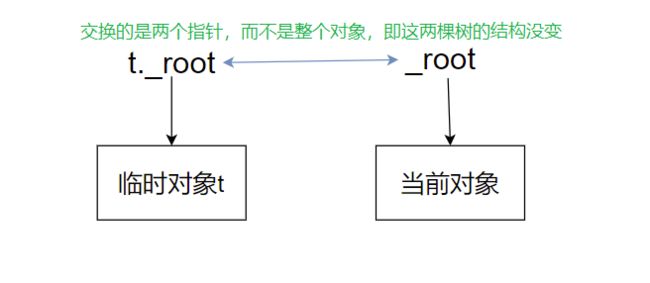
存在拷贝构造
传参时传值,因为存在拷贝构造,传值则会调用拷贝构造,构造出一个临时对象,交换指向临时对象和当前对象的根节点的指针即可.
const BSTree& operator=(const BSTree t)
{
::swap(_root, t._root);
return *this;
}
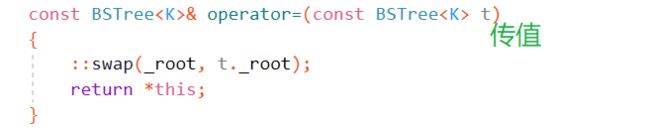
函数结束后会自动调用这个临时对象的析构函数去销毁这个临时对象,销毁一颗二叉树是根据根节点往下找的,又因为交换的只是指向根节点的指针(_root是一个指针),所以交换后并没有改变两棵树,所以根据根节点可以成功销毁临时对象,而不会影响当前对象.
查找
查找的值比当前结点的值小,那就去当前结点的左子树去找,如果查找节点的值比当前结点的值的值大,那就去当前节点的右子树去找.如果找到叶子结点的下一个(空指针)还找不到那就不存在这个值
找到了则返回结点的指针,找不到就返回空指针
非递归写法
Node* find(const K& key)
{
Node* cur = _root;
while (cur!=nullptr)
{
if (key < cur->val)
{
cur = cur->left;
}
else if (key > cur->val)
{
cur = cur->right;
}
else
{
return cur;
}
}
return nullptr;
}
递归写法
Node* _find(Node*& root, const K& key)
{
if (root == nullptr)
{
return nullptr;
}
if (key > root->val)
{
_find(root->right, key);
}
else if (key < root->val)
{
_find(root->left, key);
}
else
{
return root;
}
}
Node* find(const K& key)
{
return _find(_root, key);
}
插入
找到合适的位置然后插入,插入后的结点肯定作为叶子
合适的位置:插入后依旧是二叉搜索树
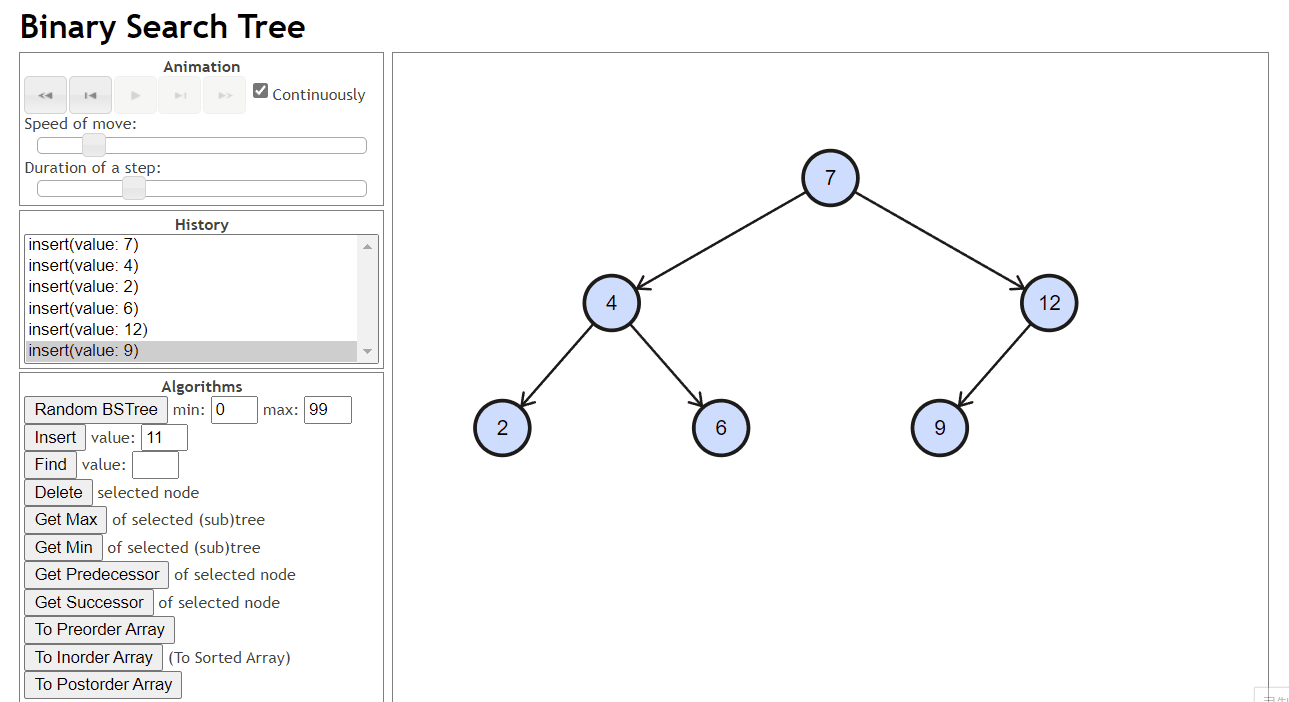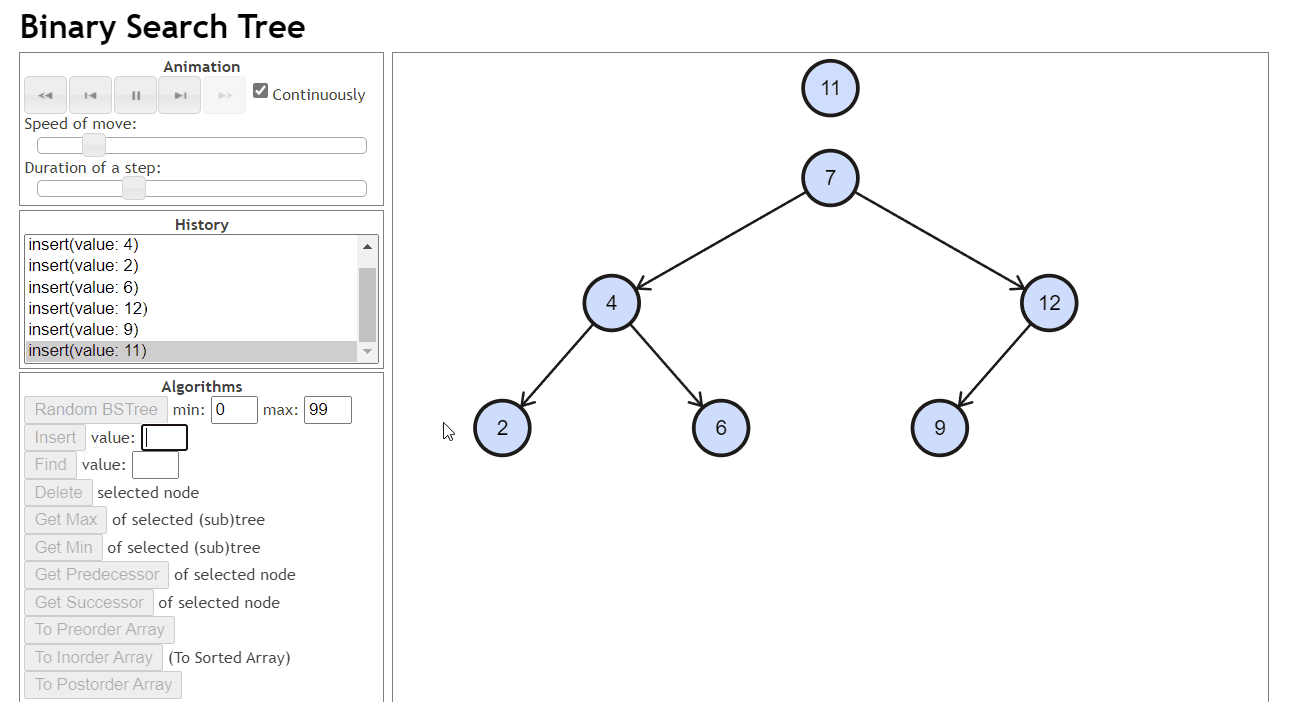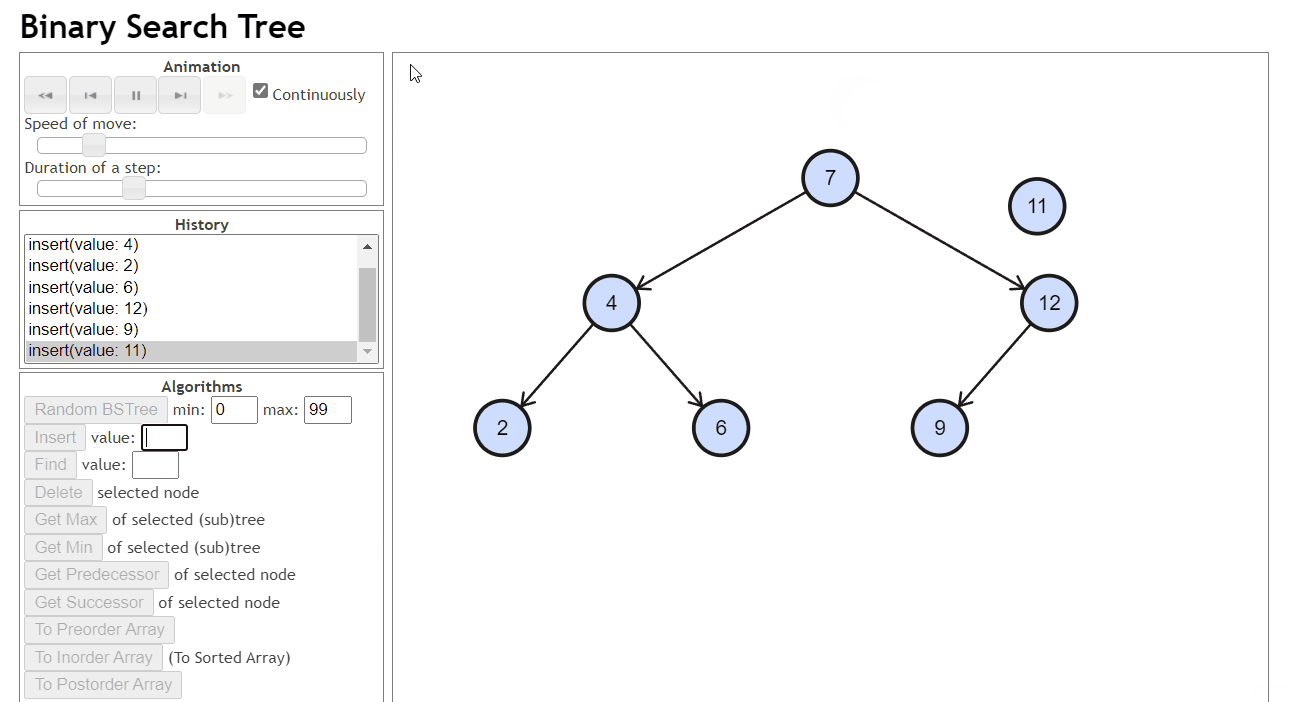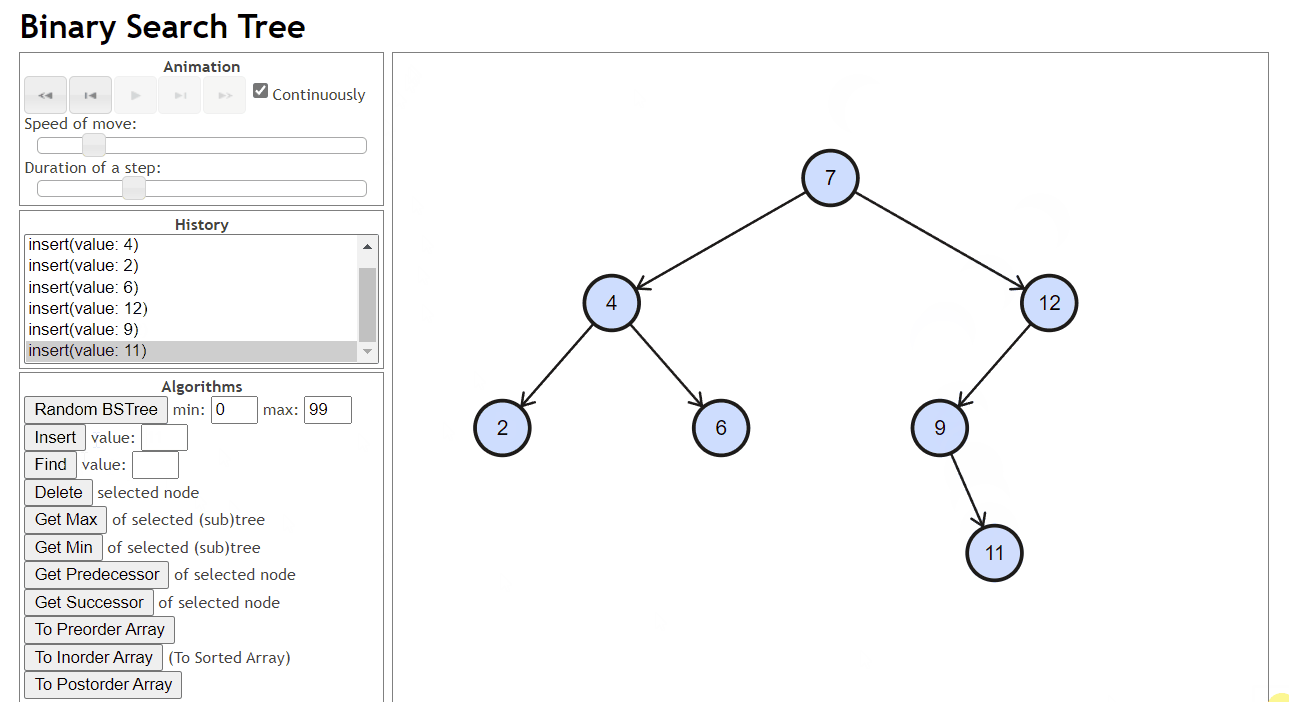
- 找到位置:如果插入的结点的值小于当前节点,就往当前节点的左子树找,否则就往右子树找,找到一个为空的位置放入这个值
- 连接:把这个位置和他的父亲进行连接
- 实现过程中要记录找到的这个位置的父亲,也即我们要知道这个位置是谁的孩子才好进行连接
非递归写法
bool Insert(const K&key)//找到位置然后插入 非递归写法
{
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* parent = nullptr;
Node* cur = _root;
while (cur!=nullptr)
{
if (key < cur->val)//插入的数比当前数小 往左子树放
{
parent = cur;
cur = parent->left;
}
else if (key > cur->val)//插入的数比当前数大 往右子树放
{
parent = cur;
cur = parent->right;
}
else
{
return false;
}
}
Node* newnode = new Node(key);
if (key < parent->val)//当前值小于父亲的值 放在父亲的左边
{
parent->left =newnode;
}
else//当前值大于父亲的值 放在父亲的右边
{
parent->right = newnode;
}
return true;
}
递归写法
注意传根节点传的是实参,传引用相当于已经有了指向关系,只要放入值即可(可以画递归图理解
bool _Insert(Node*& root, const K& key)//子函数
{
if (root == nullptr)
{
root = new Node(key);
return true;
}
if (key < root->val)//key小于当前节点的值,去左边找
{
_Insert(root->left, key);
}
else if (key > root->val)
{
_Insert(root->right, key);
}
else
{
return false;
}
}
bool Insert(const K& key)//找到位置然后插入
{
return _Insert(_root, key);
}
删除
分为三种情况,有些细节需要注意,比如删除节点为根时
- 删除的结点只有左子树:删除的结点的父亲去接管这个结点的左子树

- 删除的结点只有右子树:删除的结点的父亲去接管这个结点的右子树
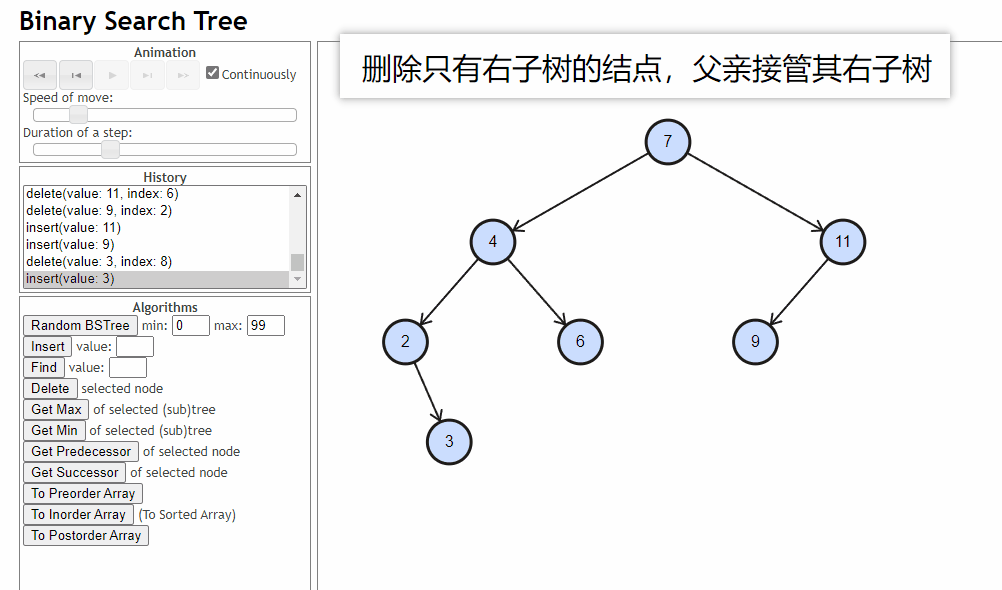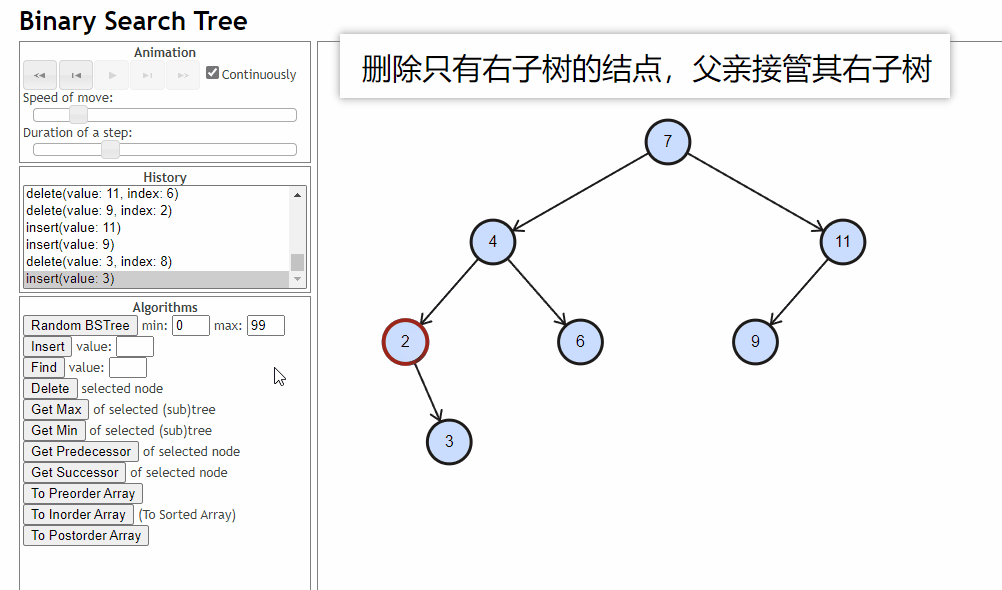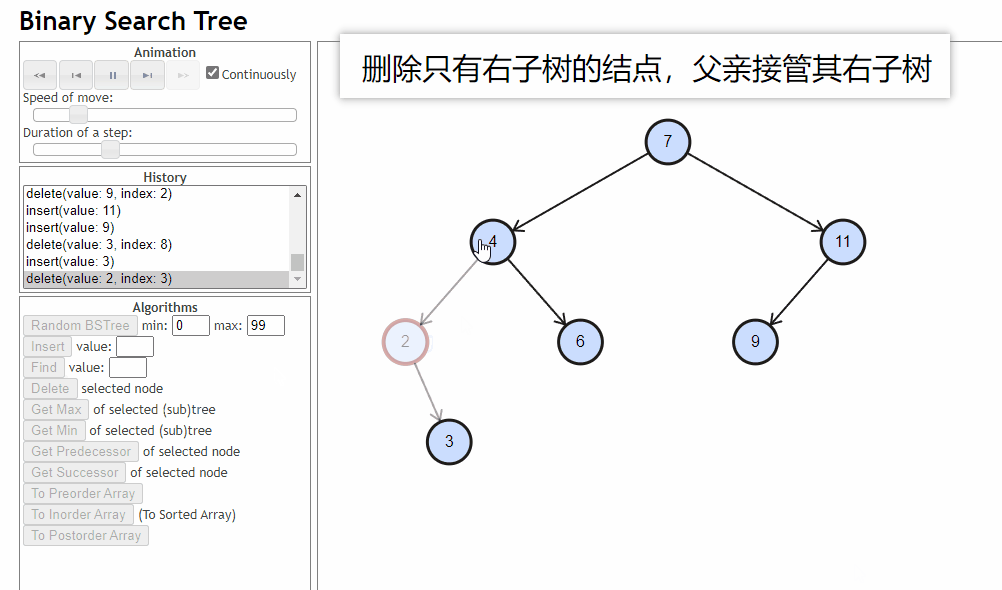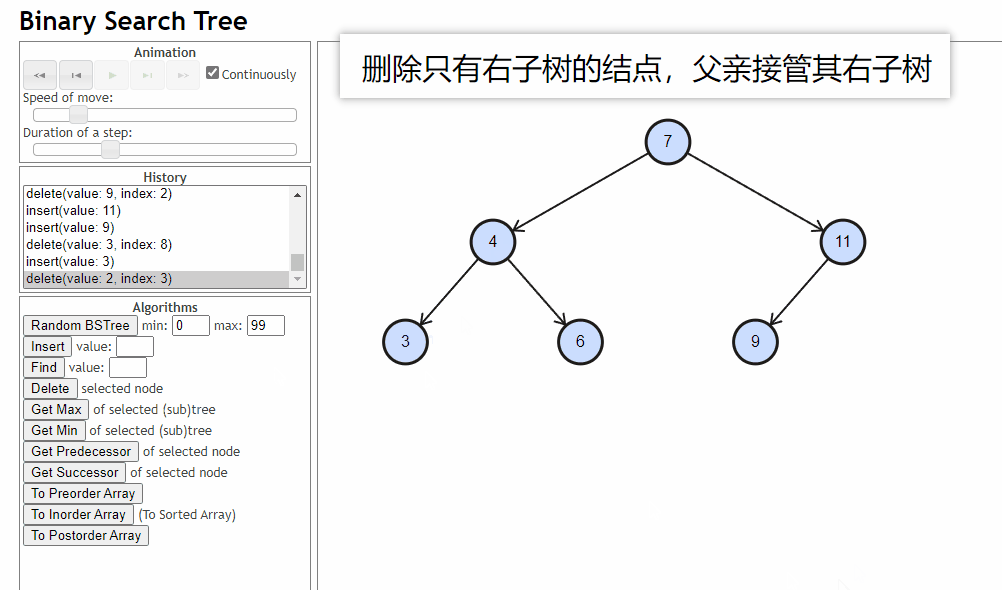
-
删除的结点有左右子树:要删除的结点记为B,替代删除法,找到一个结点A去替代B的位置,交换两个结点的值,删除结点A
怎么找到这个替代的结点?该结点的右子树最左边的叶子,或者该结点左子树最右边的叶子,实现代码选择右子树最左边的叶子

-
删除的结点没有左右子树:直接删,这种情况实现删除时可以并入第一种或者第二种情况

非递归写法
bool Erase(const K& key)
{
//先找到再删
Node* parent = nullptr;
Node* cur = _root;
while (cur != nullptr)
{
if (key > cur->val)
{
parent = cur;
cur = parent->right;
}
else if (key < cur->val)
{
parent = cur;
cur = parent->left;
}
else//找到了
{
if (cur->left == nullptr)
{
if (cur == _root)//删除的结点是根节点时
{
_root = cur->right;
}
else
{
if (key < parent->val)
{
parent->left = cur->right;
}
else
{
parent->right = cur->right;
}
}
delete cur;
return true;
}
else if (cur->right == nullptr)
{
if (cur == _root)//删除结点是根节点时
{
_root = _root->left;
}
else
{
if (key < parent->val)//在父亲的左边,是父亲的左孩子
{
parent->left = cur->left;
}
else
{
parent->right = cur->left;
}
}
delete cur;
return true;
}
else//左右子树都不为空
//替代法:用右子树最小的(右子树最左边的叶子)去替代或者用左子树最大的(左子树最右边的叶子)去替代
//这里选择用右子树最左边的去替代要删除的结点,去替代别人的结点没有左子树,转为第一种去做
{
//找到右子树最左边的结点
Node* minRight = cur->right;
Node* minRightParent = cur;
while (minRight->left != nullptr)
{
minRightParent = minRight;
minRight = minRightParent->left;
}
cur->val = minRight->val;
//去删除minRight
if (minRightParent->left = minRight)
{
minRightParent->left = minRight->right;
}
else if (minRightParent->right = minRight)
{
minRightParent->right = minRight->right;
}
//minRightParent->left = minRight->right;//minRight左子树为空 不能这么写 如果只有三个节点呢? 所以必须判断是在父亲节点的左边还是右边!
delete minRight;
return true;
}
}
}
return false;
}
细节:
- 删除的结点为根节点且只有左子树或者右子树时,未注意会导致解引用空指针的问题
- 替代结点虽然是右子树最左边的结点,不一定就在他的父亲的左边,依旧需要去判断替代结点是在它的父亲的左边还是右边

递归写法
注意传根节点传的是引用,递归这样传相当于已经有了树的结构,而且需要**理解root本质上是指向结点的指针而非结点**。第1次理解时只觉得写的很妙
bool _EraseR(Node*& root, const K& key)//递归必须传引用 传引用,即传实参相当于多了个parent指针
{
if (root == nullptr)
{
return false;
}
if (key < root->val)
{
_EraseR(root->left, key);
}
else if (key > root->val)
{
_EraseR(root->right, key);
}
else//找到了准备去删
{
if (root->left == nullptr)
{
Node* tmp = root;
root = root->right;
delete tmp;
return true;
}
else if (root->right == nullptr)
{
Node* tmp = root;
root = root->left;
delete tmp;
return true;
}
else
{
Node* minRight = root->right;
Node* minRightParent = root;
while (minRight->left)
{
minRightParent = minRight;
minRight = minRightParent->left;
}
root->val = minRight->val;
if (minRightParent->left == minRight)
{
minRightParent->left = minRight->right;
}
else
{
minRightParent->right = minRight->right;
}
delete minRight;
minRight = nullptr;
return true;
}
}
}
bool EraseR(const K& key)
{
//找到再删
return _EraseR(_root, key);
}
闲谈
二叉搜索树的性能关键在于查找,或者说是搜索效率,插入和删除前面有一步都是查找,比如先找到位置再插入,找到要删除的点再删除,查找的效率理论上应该是logn(注意二叉搜索树增删查的时间复杂度是O(N),因为时间复杂度取决于最坏情况),但实际用起来却不一定是logn。
搜索效率与树的高度有直接关系,树的高度与根结点选择有很大的关系,性能最差的情况就是二叉树退化成了单支树,那就成链表了,搜索效率不高,导致增删效率也不高.
我们前面说过影响查找效率的是树的高度,两边高度相差不大时效率最高(层数不就没那么多,单支树n个结点高度为n,和链表有啥区别)
为了提高查找效率,就有了升级版的AVL树,AVL树在二叉搜索树的基础上加了平衡因子,控制左右子树的高度不超过1,AVL树会之后加以探讨,
挖坑一直都可以的
K模型
只存储key值,搜索的查找的就是key
类比STL的set
KV模型
存储key和value,一个key对应一个value,树里存储的是
类比STL的map,默认以key排序,要自定义以value排序也可以自己写函数
小结
-
搜索二叉树可以理解为是对链表和数组的折中,数组随机访问效率高,插入删除效率低,链表插入删除效率高,查找效率低,而二叉搜索树增删和查找效率都还可以(以上来自一位大佬的理解)
-
搜索二叉树增删效率取决于查找效率,查找则取决于树的高度(结构),因此衍生出了AVL和红黑树等
-
二叉搜索树操作的时间复杂度是O(N),子树高度相差不大时是O(logn)
-
画图理解递归写法为啥传引用(实参)而不是传值
,搜索效率不高,导致增删效率也不高.
我们前面说过影响查找效率的是树的高度,两边高度相差不大时效率最高(层数不就没那么多,单支树n个结点高度为n,和链表有啥区别)
为了提高查找效率,就有了升级版的AVL树,AVL树在二叉搜索树的基础上加了平衡因子,控制左右子树的高度不超过1,AVL树会之后加以探讨,
挖坑一直都可以的
K模型
只存储key值,搜索的查找的就是key
类比STL的set
KV模型
存储key和value,一个key对应一个value,树里存储的是
类比STL的map,默认以key排序,要自定义以value排序也可以自己写函数
小结
-
搜索二叉树可以理解为是对链表和数组的折中,数组随机访问效率高,插入删除效率低,链表插入删除效率高,查找效率低,而二叉搜索树增删和查找效率都还可以(以上来自一位大佬的理解)
-
搜索二叉树增删效率取决于查找效率,查找则取决于树的高度(结构),因此衍生出了AVL和红黑树等
-
二叉搜索树操作的时间复杂度是O(N),子树高度相差不大时是O(logn)
-
画图理解递归写法为啥传引用(实参)而不是传值
代码汇总放在github传送门