2022年斯坦福AI指数报告中文全解读-第二章 2.1 机器视觉——图像
斯坦福大学的人工智能机构 Stanford Institute for Human-Centered Artificial Intelligence (HAI)发布的这第五版《AI指数报告》(2022)英文版一共230页。为了方便阅读,我将他翻译成中文记录下来,本文仅摘取重要且有趣的部分,且有部分自己的阅读感受和见解,需要阅读原文的请至链接2022年斯坦福AI指数报告-深度学习文档类资源-CSDN下载。
人工智能指数报告跟踪、整理、提炼和可视化与人工智能相关的数据。这份报告的使命是为政策制定者、研究人员、企业高管、媒体记者提供公正、经过严格审查的全球数据,使得公众对复杂的人工智能领域有更透彻、更细致入微的理解。它旨在成为世界上最可信、最权威的人工智能数据和见解来源。
第二章. 人工智能模型性能
今年,模型性能章节包含了对人工智能更多技术子领域的分析,包括计算机视觉、语言、语音、推荐、强化学习、硬件和机器人技术。本次调研使用了许多量化测量方法,从常见的人工智能基准算法和对泛化领域调研的大赛挑战,来突出表现那些最佳人工智能模型的发展历程。
概要:
- 数据,数据,数据:基于实验室基准条件的模型技术结果则越来越依赖于使用更多的训练数据来获得更先进的结果。换言之,模型本身的设计好坏往往差别不大,而更多的训练数据能带来更好的实验效果。截至 2021 年,斯坦福大学AI指标报告中的 10 个基准测试中有 9 个最先进的 AI 系统经过了更多的训练。这种趋势隐隐指引着私营参与者倾向去寻找大量的数据集。
- 对特定计算机视觉子任务的兴趣日益浓厚:2021 年,研究界在一些具体的计算机视觉子任务上有着更高的兴趣水平,例如医学图像分割和蒙面人脸识别(我的导师张百灵教授在2015年左右就在研究这几个领域的具体任务,我想现在研究界只是有更多来自工程学院和生物学院的教授关心这类识别为他们在特定领域研究带来的创新成果,仅此而已)。例如,2020年前只有 3 篇研究论文针对 Kvasir-SEG 医学成像测试了系统基准。2021 年,有 25 篇研究论文。这种增长表明人工智能研究是在转向更直接、更实际应用的研究。
- AI 尚未掌握复杂的语言任务:AI 在基本阅读技术基准的性能上已经超过了人类的水平,SuperGLUE 和 SQuAD 等阅读理解基准表现提高了 1%–5%。虽然人工智能系统仍然无法在更复杂的语言任务上达到可媲美人类的表现,例如溯因自然语言推理(aNLI),但差异正在缩小。2019年,人类的表现仅领先 9个百分点(aNLI)。截至 2021 年,这一差距已缩小到 1%。
- 转向更通用的强化学习:在过去十年中,人工智能系统已经能够掌握一定限制条件下的强化学习任务。这要求系统最大限度地提高某项特定技能的表现,例如国际象棋。顶级国际象棋软件引擎现在比 Magnus Carlsen 的最高 ELO 分数高出 24%。然而,在过去两年,人工智能系统在新环境、更通用的强化学习任务上也提高了129%(Procgen) 。这一趋势预示着人工智能系统未来的发展可以学习更广泛地思考能力。
- 人工智能变得更实惠、性能更高:自 2018 年以来,训练图像分类系统的成本降低了 63.6%,而训练次数提高了 94.4%。其他 任务也出现训练成本降低、但训练时间加快的趋势:推荐系统,物体检测和语言处理,并有利于更广泛的人工智能商业应用。
- 机械臂正在变得更便宜:一项人工智能指数调查显示,机械臂的中位数价格在过去六年中下降了 4 倍——从2016 年每只手臂 50,000 美元下降到 2021 年的 12,845 美元。关于机器人的研究变得更容易获得,且负担得起。
2.1 机器视觉——图像
Holi的导览指南:
目录
第二章. 人工智能模型性能
概要:
2.1 机器视觉——图像
图像分类任务 IMAGE CLASSIFICATION
ImageNet
ImageNet: Top-1 Accuracy
ImageNet: Top-5 Accuracy
图像生成任务 IMAGE GENERATION
STL-10: Fréchet Inception Distance (FID) Score
CIFAR-10: Fréchet Inception Distance (FID) Score
深度伪造检测 DEEPFAKE DETECTION
FaceForensics++
Celab-DF
人体姿态估计 HUMAN POSE ESTIMATION
Leeds Sports Poses: Percentage of Correct Keypoints (PCK)
Human3.6M: Average Mean Per Joint Position Error (MPJPE)
语义分割任务 SEMANTIC SEGMENTATION
Cityscapes
医学图像分割任务 MEDICAL IMAGE SEGMENTATION
CVC-ClinicDB and Kvasir-SEG
人脸检测和识别 FACE DETECTION AND RECOGNITION
National Institute of Standards and Technology (NIST) Face Recognition Vendor Test (FRVT)
人脸检测:戴口罩的影响 FACE DETECTION: EFFECTS OF MASK-WEARING
Face Recognition Vendor Test (FRVT): Face-Mask Effects
Masked Labeled Faces in the Wild (MLFW)
视觉推理 VISUAL REASONING
Visual Question Answering(VQA) Challenge
图像分类任务 IMAGE CLASSIFICATION
图像分类是指机器对他们在图像中看到的内容进行分类的能力。实际上,图像识别系统可以帮助汽车识别周围的物体,帮助医生检测肿瘤,帮助工厂经理发现生产缺陷。在过去的十年中,我们看到了图像识别模型的技术能力巨大的进步。尤其是随着研究人员学习了更多的机器学习技巧。此外,算法、硬件和数据技术的进步意味着图像识别变得更实惠,更广泛适用,并且比以往任何时候都可访问。
ImageNet
ImageNet是一个数据库,其中包括,研究人员可公开使用的超过1400万张图像处理20,000个类别的图像分类问题。创建于2009年,ImageNet现在是科学家对图像分类的基准算法改进最常见的方式之一。
ImageNet: Top-1 Accuracy
ImageNet 上的基准测试是通过准确率指标来衡量的,它量化了 AI 模型分配给定图像正确标签的频率。Top-1 准确率衡量给定图像的分类模型最高预测率与实际目标标签的相似度。近年来,人们越来越普遍地通过额外的预训练其他图像数据集的数据提高ImageNet 的系统性能。
下图中显示2021 年底比 2012 年底,顶级图像分类模型使每 10 次分类尝试的 Top-1 准确率从平均出现 4 个错误提升到平均 1 个错误。 2021 年,最好的预训练系统是 Google Brain 团队的 CoAtNets模型。

ImageNet: Top-5 Accuracy
如图所示,Top-5 准确率考虑了模型与图像标签对齐的前 5 个最高概率答案,人工智能系统目前实现了近乎完美的 Top-5 估计。目前,预训练 Top-5 准确率的最先进性能是 99.0% ,于 2021 年 11 月由微软云和微软 AI 的 Florence-CoSwim-H 模型达成。
ImageNet 上 Top-5 准确率的改进似乎是停滞不前的,这也许不足为奇。如果你的系统在 100 次分类中正确分类 98 或 99 次,也只能有这样的准确率了。

图像生成任务 IMAGE GENERATION
图像生成是与真实图像无异的生成图像任务。图像生成可以在视觉内容必须虚拟创建的领域中广泛使用,例如娱乐业(像 NVIDIA 这样的公司已经使用图像生成器来创建用于游戏的虚拟世界)、时尚业(设计师可以让 AI 系统生成不同的设计模式)和医疗保健(图像生成器可以综合创造新药
化合物)。下图说明了去年由人工智能系统综合生成的图像生成任务进展中呈现一些人脸。

STL-10: Fréchet Inception Distance (FID) Score
Fréchet Inception Distance 算法分数跟踪人工生成的一组图像和生成它的真实图像的相似度。低分意味着生成的图像更类似于真品,零分表示虚假图像与真实图像完全相同。
下图记录了在 STL-10 数据集上使用 FID 制作生成模型的增益,这是在计算机视觉中最广泛使用的数据集之一。在 STL-10 数据集上最先进的模型是由韩国高级科学技术研究所研究人员和首尔大学联合开发的, FID 分数为 7.7,比 2020 年最先进的结果更显著。

CIFAR-10: Fréchet Inception Distance (FID) Score
图像生成的进展也可以在 CIFAR-10 数据集上作为基准,一个包含 60,000 个彩色图像的10类不同的对象数据集。2021 年发布在 CIFAR-10 数据集上的最先进结果是由来自英伟达的研究人员实现的。
顶级图像生成模型在 CIFAR-10 数据集上所获得的 FID 分数比 STL-10 数据集上低得多。这种差异可能是由于在 CIFAR-10 (32 x 32 像素)数据集上包含比 STL-10(96 x 96 像素)数据集上分辨率低得多的图像。

深度伪造检测 DEEPFAKE DETECTION
许多人工智能系统现在可以生成与真人无异的虚假图像。相关技术涉及将一个人的脸叠加到另一个人的脸上,创建所谓的“深度伪造”。将 Deepfake 用于广告或生成厌恶女性的色情和虚假信息的各种目的(例如,2018 年奥巴马对特朗普亵渎讲话的 deepfake 视频在网上流传超过 200 万次)。在过去的几年里,人工智能研究人员已经试图通过制作更强大的深度伪造检测算法跟上改进 deepfake 技术的步伐。
FaceForensics++
FaceForensics++ 是一个 deepfake 检测基准测试数据集,包含来自 YouTube 视频大约 1,000 个原始视频序列。FaceForensics++ 的模型进展以准确性为衡量标准:算法可以正确地识别改变的图像百分比。
尽管 FaceForensics ++ 是在 2019 年推出的,研究人员已经测试了现存的 deepfake 检测方法以跟踪随着时间的推移在 deepfake 检测算法的模型进展,如下图。在过去的十年中,AI系统在检测 deepfake 深度伪造的图像方面变得越来越好。2012 年,表现最佳的模型系统在所有四个 Faceforenics ++ 数据集中可以正确识别 69.9% 的深度伪造图像。在 2021 年,该数量增加到 97.7%。

Celab-DF
Celeb-DF deepfake 检测数据集由 590 个原创名人 YouTube 视频被操纵成 5,639 个深度伪造图像。Celeb-DF 于 2019 年被推出。2021年,Celeb-DF 的最高分是 76.9 ,来自中国科技大学和阿里巴巴集团的研究人员。
在 Celeb-DF 数据集上比 FaceForensics++ 数据集上,顶级检测模型的表现明显更差(20%),表明 Celeb-DF 是一个更具挑战性的数据集测试技术。随着 deepfake 技术在未来几年的不断发展,这将很重要地继续监测在 Celeb-DF 数据集上和其他同样具有挑战性的 deepfake 检测数据集方面的进展。

人体姿态估计 HUMAN POSE ESTIMATION
人体姿态估计是从单个图像估计不同人体关节位置(手臂、头部、躯干等)的任务,然后整合
正确标记人类所采取姿势的估计。
人体姿态估计可用于促进体育分析、人群监控、CGI 开发、虚拟环境设计、和交通运输等目的的活动识别(例如,识别机场跑道管制员的身体语言标志)。

Leeds Sports Poses: Percentage of Correct Keypoints (PCK)
Leeds Sports Poses 利兹运动姿势数据集包含了收集到的 Flickr 参加一项运动的 2,000 张运动员图像。每个图像包含 14 个不同身体关节点信息。利兹运动姿势的表现基准是通过正确估计关键点的百分比来评估的。
2021 年,表现最好的人体姿态估计模型正确识别了利兹运动姿势数据集上 99.5% 的运动姿势关键点,如图。鉴于利兹运动姿势数据集上的准确率上限是 100.0%,人体姿态估计更具挑战性的基准必须被开发,因为我们非常接近了饱和基准。

Human3.6M: Average Mean Per Joint Position Error (MPJPE)
3D 人体姿态估计是一种更具挑战性的姿态估计任务类型,要求人工智能系统在三维而不是二维空间中进行姿态估计。在 Human3.6M 数据集上跟踪 3D 人体姿态估计的进展。 Human3.6M 数据集是超过 360 万个集合 17 种不同类型的人体姿势的图像(聊电话、讨论和吸烟等)。在Human3.6M 上的表现会测量每个关节的算术平均值,产生以毫米为单位的位置误差,这是在 AI 模型的位置估计和实际位置之间位置平均差异。
2014 年,表现最好的模型平均每关节误差 16 厘米,是标准学术尺寸的一半。 2021年,这个数字下降到1.9厘米,小于一般回形针的大小。

语义分割任务 SEMANTIC SEGMENTATION
语义分割是分配单个图像像素一个类别(例如人,自行车或背景)的任务。太多现实世界的领域需要像素级图像细分,例如自动驾驶(识别汽车看到的图像的哪些部分是行人和哪些部分是道路),图像分析(区分照片中的前景和背景),以及医学诊断(在肺中分割肿瘤)。

Cityscapes
Cityscapes 数据集包含来自 50 个城市环境的街道图像,在不同季节的白天来评估广泛的语义分割任务(实例级,全景模拟和 3D 车辆)。
大多数研究人员提交的任务是像素级的语义标签,人工智能系统必须面临的挑战是在每个像素级别上对图像进行语义标记。挑战者在并集交集 (IoU) 上进行评估度量,IoU 得分越高,对应越好的分割精度。实际上,分数更高意味着模型预测的更大比例图像部分与真实图像有重叠。
2021 年,在 Cityscapes 数据集上表现最好的 AI 系统报告分数比 2015 年的高出了 14.6 个百分点。与其他计算机视觉任务一样,在 Cityscapes 数据集上的模型已经在过去几年经过了其他训练数据的预训练了。

医学图像分割任务 MEDICAL IMAGE SEGMENTATION
医学图像分割任务指的是AI系统分割特定对象的能力,例如器官,医学图像中的病变或肿瘤,如图。这项任务的技术进步对于精简医学诊断的过程来说至关重要。医学影像分割任务的进展意味着医生可以用更少的时间诊断,并争分夺秒地去治疗患者。
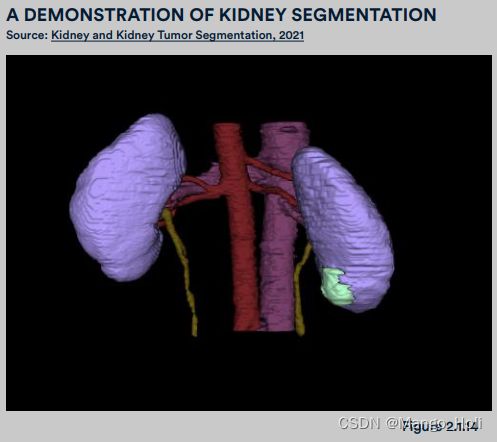
CVC-ClinicDB and Kvasir-SEG
CVC-ClinicDB 是一个数据集,包括来自 31 个结肠镜检查的 600 多张高分辨率图像。 Kvasir-SEG 是一个 1,000 个由医生手动分割并由专业胃肠病学家交叉验证过的(具有专家高度准确性发)高分辨率胃肠息肉图片组成的公共数据集。这两个数据集用于跟踪医学图像分割任务的模型发展进度。模型性能以平均 DICE 指标衡量,代表着由AI系统和手动分割产生的图片平均重叠率。
人工智能系统现在能够在 CVC-ClinicDB 数据集上正确分割结肠镜息肉发生率的准确率为 94.2%,且自 2015 年以来提高了 11.9 个百分点,自2020 年以来提高了 1.8 个百分点。在 Kvasir-SEG 数据集上也取得了类似的进展,目前表现最好的人工智能模型能以 92.2% 的准确率正确分割胃肠息肉。专为医学图像分割而设计的最早的卷积神经网络之一 MSRF-Net 在 CVC-ClinicDB 和 Kvasir-SEG 数据集上的基准测试保持着最好的表现。

在 Kvasir-SEG 数据集上的基准测试也指向了医学图像分割任务的病毒式传播。早在 2020 年之前,该数据集仅在三篇学术论文中被引用。到2020 年,这个数字上升到 6 个,到 2021 年飙升到 25 个。去年还举办了 KiTS21(肾脏和肾肿瘤分割挑战赛),来自学术界和工业界的医学研究人员创建对肾肿瘤和肾脏周围的解剖结构自动分割的最佳系统。
人脸检测和识别 FACE DETECTION AND RECOGNITION
在人脸面部检测中,人工智能系统的任务是识别图像或视频中的人。虽然人脸识别技术已经存在了几十年,该项技术也在过去几年取得了重大进展。一些当今性能最佳的面部识别算法在具有挑战性的数据集上的成功率接近 100%。
人脸识别可便于跨境旅行,在防欺诈中保护敏感信息文件,并在在线的监考中识别考试作弊行为。然而,面部识别最大的应用是在于它助力安防的潜力,这使得这项技术对世界各地的军队和政府(例如,18/24 个美国政府机构已经在使用一些面部识别技术)。
National Institute of Standards and Technology (NIST) Face Recognition Vendor Test (FRVT)
美国国家标准与技术研究院(NIST)的人脸识别供应商测试标准(FRVT)在各类国土安全和执法任务中负责衡量面部识别算法的好坏,例如不同新闻摄影图像的面部识别,拐卖儿童受害者面部识别,护照重复数据的删除,和签证图像的交叉验证。面部识别算法的进步是根据虚假不匹配率(false non-match rate, FNMR)或错误率(模型无法将图像与人匹配的概率)。
2017年,一些表现最好的面部识别算法在某些 FRVT测试上的错误率超过 50.0%。 2021 年,没有人发布的模型错误率高于3.0%。2021 年所有数据集中表现最佳的模型(签证照片)的错误率为 0.1%,这意味着对于每 1,000 个人脸,模型能正确识别了 999 个人脸。

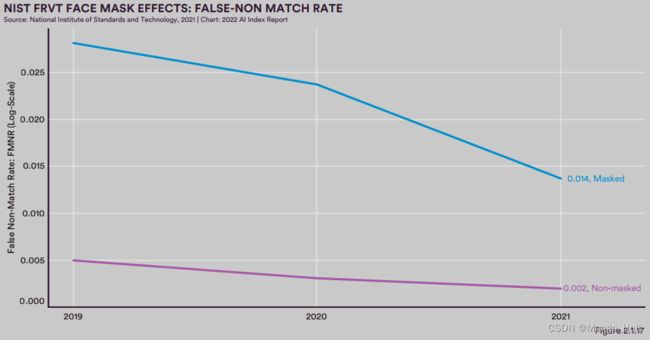
人脸检测:戴口罩的影响 FACE DETECTION: EFFECTS OF MASK-WEARING
Face Recognition Vendor Test (FRVT): Face-Mask Effects
随着 COVID-19 大流行的爆发和附带的戴口罩人脸识别任务,人脸识别变得更具挑战性。戴口罩的人脸识别任务要求 AI 模型测试识别两个签证数据集上的人脸照片,包括蒙面的脸和无遮挡的脸。
从 FRVT 测试中收集到三个重要的趋势:(1)面部识别系统仍然可以在戴口罩的人脸上相对较好地执行; (2) 戴口罩的人脸识别模型表现比无遮挡的人脸要差; (3)自 2019 年以来,模型效果差距已经在逐步缩小。
Although facial recognition technology has existed for several decades, the technical progress in the last few years has been significant. Some of today’s top-performing facial recognition algorithms have a near 100% success rate on challenging datasets.
虽然人脸识别技术已经存在了几十年,过去几年的技术进步一直非常重要。今天的最好表现的人脸识别算法在具有挑战性的数据集上有接近 100% 的成功率。
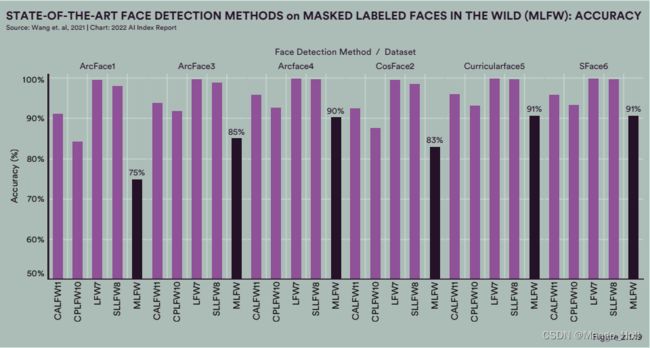
Masked Labeled Faces in the Wild (MLFW)
2021 年,来自北京邮电大学和中国电信的研究人员发布了6000张戴口罩的人脸识别数据集以应对大规模戴口罩带来的新的识别挑战。

EXAMPLES OF MASKED FACES IN THE MASKED LABELED FACES IN THE WILD (MLFW) DATABASE
Source: Wang et al., 2021
作为数据集发布的一部分,研究人员运行了一系列现有最先进的面部识别算法,包括他们的,以确定戴口罩的人脸图片对算法检测的性能下降程度有什么影响。他们的估计表明,最顶尖的模型在识别戴口罩的人脸时比不戴口罩的人脸识别要差 5 至 16 个百分点。这些发现在一定程度上确认了来自 FRVT 戴口罩的人脸识别测试的见解:戴口罩时识别性能会下降,但不是太显着。
视觉推理 VISUAL REASONING
视觉推理任务评估人工智能系统如何通过一个视觉与文字结合的数据来进行推理的效果。视觉推理能力可以使开发的AI系统做更广泛的推理。现有的人工智能已经可以在某些窄边界的视觉任务中做的比人类更好,例如图像分类、人脸检测和分割对象。但是很多AI系统在面临挑战时会挣扎着更抽象地推理——例如,产生对图像中动作执行人具体行为或动机的有效推论。

Visual Question Answering(VQA) Challenge
在视觉问答挑战中,人工智能系统的任务是回答关于图像的开放式问题。为了巧妙回答高水平的问题,人工智能系统必须有一个对语言、视觉的组合理解和常识推理。

自 VQA 挑战赛开始以来的六年里,最先进的模型性能提高了 24.4 个绝对百分点。 2015年,表现最好的系统只能正确回答 55.4% 的问题。截至 2021 年,最高表现性能为 79.8% —— 接近了 80.8% 的人类问答基线。
