机器学习之特征工程(数据清洗)
为数据挖掘与机器学习过程中提供干净、准确、简洁的数据,提高数据挖掘的准确性和效率,数据预处理是特别重要的一部分,它在数据挖掘整个流程中可以占到70%的处理时间。
文章目录
-
- 1、缺失值的处理
- 2、重复值的处理
- 3、异常值的处理
- 4、噪声的处理
- 5、标准化
- 6、离散化与二值化
- 7、python实战
1、缺失值的处理
- 直接删除
若某特征存在缺失值,且在数据挖掘过程中用不上它的话,可以直接删除该特征。如果缺失的数据条数较少,不超过20%(依数据而异),可以直接删除这些数据。 - 填充常量值/缺省值
如果某特征存在较少的缺失值,可以使用事先确定好的常量值进行填充;但该特征缺失值较多,就不能用常量值,因为这样会影响数据挖掘的结果。例如:利用M表示缺失值。 - 特征均值或中位数填充
因为均值或中位数可以代表该特征的一个平均水平,因此我们可以利用均值或中位数进行填充缺失值。例如:顾客的平均收入为1万元,则用此值填充所有缺失值。 - 同类均值或中位数填充
这种方法尤其是在分类挖掘时使用,因为数据集已经被分类打上标签了。例如:不同年龄段的平均收入肯定是有所差别的,因此可以利用不同年龄段的平均收入填充相对应的年龄段的人的收入。 - 利用算法模型计算出的值填充缺失值
利用回归分析、贝叶斯或决策树推断出该条记录特定属性的最大可能的取值。。例如:利用数据集中其它顾客的特征值,可以构造决策树预测该特征的缺失值。
2、重复值的处理
- 直接删除
重复值较多可以直接删除,例如:用户信息表,有些用户重复记录了,就可以直接删除了。 - 不处理
并非看到重复值就删除。例如:订单表,某用户网购买了5件外套,但在订单信息中显示了5条订单数据,此时就不能直接删除了,否则会影响订单销售额及销售量。
3、异常值的处理
- 定义:模型通常是对整体样本数据结构的一种表达方式,表达的是整体样本的一个一般性特点,而那些与整体样本不一致的数据,称其为异常值。查看你异常值的一个重要方法就是查看特征的箱线图。
- 删除
根据分位数删除异常值,或者明显数据错误的,例如:订单表中某条数据价格6元,但优惠价格10元,明显数据错误。 - 将异常值视为缺失值
例如:订单表中少部分用户的年龄超出100岁,显然年龄100岁有些异常了,我们就可以将其按照缺失值处理。 - 用平均值/其他值修正
例如:订单表中日期存在1970年的,很明显是异常值,因此需人工审查到底是怎么回事,如果日期错了,可以使用正确的日期修正。 - 不处理
例如:订单表中平均付款金额为2万元,但某用户的付款金额达到了5万元,看起来是异常值吧,我们可以看看他买的是什么,如果商品就是5万元的,可以不处理。
4、噪声的处理
- 噪声是指被测量的变量的随机误差或方差。
- 分箱
- 例如:现有用户的年龄分别为5,12,24,31,67,89。明显年龄差距有点大,我们可以利用分箱将其分组,划分为bins1={5,12},bins2={24,31},bins3={67,89} ,成了年龄段属性,将其变为离散型特征。
- 聚类方法
- 通过聚类分析找出孤立点,去除孤立点以消除噪声数据。
- 回归方法
- 利用回归分析方法获得回归函数,让数据适应回归函数来平滑数据,去除噪声。
5、标准化
数据标准化是为了消除不同指标量纲的影响,方便指标间的可比性,量纲差异会影响某些模型中距离计算的结果。
- 最小—最大标准化\0—1标准化:将数据映射到[0,1]之间
x ′ = x − m i n m a x − m i n x' =\frac{x-min}{max-min} x′=max−minx−min - 均值-方差标准化\z-score标准化:是数据服从正态分布
x ′ = x − μ σ x'=\frac{x-\mu}{\sigma} x′=σx−μ, μ \mu μ是均值, σ \sigma σ是方差
6、离散化与二值化
有些数据挖掘算法,特别是分类算法,要求数据是分类属性形式,发现关联模式的苏纳法要求是二值属性格式。这样,常常要将连续属性变换成分类属性(离散化)并且连续和离散属性可能都需要变换成一个或多个二元属性(二值化)。
- 二值化(独热编码)没有大小之分
关联分析中需要非对称的二值属性,其中只有属性的出现(值为1)才是最重要的。因此对于关联问题,需要为每一个类别引入一个二值属性。例如:现有一个特征包含5个值{awful,poor,ok,good,great} ,将该特征二值化。如图:5个值分别引入一个特征变量, x i x_i xi分别代表5个值。以x3(ok)为例,若改行的分类值为OK,那么x3=1,否则x3=0。这就是二值化,仅有0—1值。
| 分类值 | 整数值 | x1 | x2 | x3 | x4 | x5 |
|---|---|---|---|---|---|---|
| awful | 0 | 1 | 0 | 0 | 0 | 0 |
| poor | 1 | 0 | 1 | 0 | 0 | 0 |
| ok | 2 | 0 | 0 | 1 | 0 | 0 |
| good | 3 | 0 | 0 | 0 | 1 | 0 |
| great | 4 | 0 | 0 | 0 | 0 | 1 |
- 连续数据离散化
连续属性变成分类属性需要两个关键任务:决定需要多少个分类值,及确定如何将连续属性映射到这些分类值。
在第一步中,将连续属性值排序后,通过指定n-1个分割点把它们分割成n个区间。第二步中,将一个区间中的所有值映射到相同的分类值。因此,离散化问题就是决定选择多少个分割点和确定分割点位置的问题。例如学生成绩就是连续的0—100分不等,我们可以将其分类,分数在[0,60),[60,80),[80,100)区间内的分别属于不及格、良好、优秀三个类别。后续研究过程可以将三个类别数值化,记为1,2,3类。
7、python实战
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] =['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
data=pd.read_csv('qunar_freetrip.csv',index_col=0)
data.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 5100 entries, 0 to 5099
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 出发地 5098 non-null object
1 目的地 5099 non-null object
2 价格 5072 non-null float64
3 节省 5083 non-null float64
4 路线名 5100 non-null object
5 酒店 5100 non-null object
6 房间 5100 non-null object
7 去程航司 5100 non-null object
8 去程方式 5100 non-null object
9 去程时间 5100 non-null object
10 回程航司 5100 non-null object
11 回程方式 5100 non-null object
12 回程时间 5100 non-null object
dtypes: float64(2), object(11)
memory usage: 557.8+ KB
# 存在缺失值:价格、节省、目的地、出发地
- 缺失值处理
#去除空格
data.columns = [x.strip() for x in data.columns] # 列名可能存在空格 去除
#均值填补价格和节省缺失值
data['价格'].fillna(round(data['价格'].mean()), inplace=True)
data['节省'].fillna(round(data['节省'].mean()), inplace=True)
data[data['出发地'].isnull() | data['目的地'].isnull()] # 部分结果
出发地 目的地 价格 节省 路线名
NaN 烟台 647.0 348.0 大连-烟台3天2晚 | 入住烟台海阳黄金海岸
深圳 NaN 2149.0 494.0 深圳-大连3天2晚 | 入住大连黄金山大酒店
NaN 西安 1030.0 326.0 济南-西安3天2晚 | 入住西安丝路秦国际青年旅舍钟楼回民街店
# 知道路线名,所以我们可以从路线名中提取出发地和目的地
# 从路线名提取地点,填充缺失值
data.loc[data['出发地'].isnull(), '出发地'] = [str(x)[:2] for x in data.loc[data['出发地'].isnull(), '路线名']]
data.loc[data['目的地'].isnull(), '目的地'] = [str(x)[:2] for x in data.loc[data['目的地'].isnull(), '路线名']]
# 结果看没有缺失值了
<class 'pandas.core.frame.DataFrame'>
Int64Index: 5100 entries, 0 to 5099
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 出发地 5100 non-null object
1 目的地 5100 non-null object
2 价格 5100 non-null float64
3 节省 5100 non-null float64
4 路线名 5100 non-null object
5 酒店 5100 non-null object
6 房间 5100 non-null object
7 去程航司 5100 non-null object
8 去程方式 5100 non-null object
9 去程时间 5100 non-null object
10 回程航司 5100 non-null object
11 回程方式 5100 non-null object
12 回程时间 5100 non-null object
dtypes: float64(2), object(11)
memory usage: 557.8+ KB
- 重复值处理
data.duplicated().sum() # 100 输出重复值数量
data=data.drop_duplicates() # 删除重复值
- 异常值处理
# 删除异常值(价格<节省)
data = data[data['节省'] <= data['价格']]
data.describe().T
count mean std min 25% 50% 75% max
价格 4997.0 1768.276566 2597.723990 578.0 1256.0 1637.0 2029.0 179500.0
节省 4997.0 472.796878 154.090652 306.0 358.0 436.0 530.0 1640.0
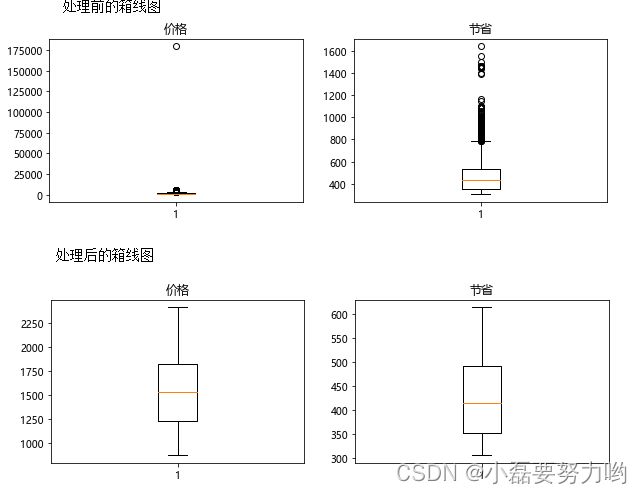
# 结果中 看出价格中最高179500元,属于异常值;节省中1640元也属于异常值,因为它们远远高于各自的3/4位数
# 处理异常值 截取 价格或节省的钱在 [3/4位数-1.5*(3/4位数-1/4位数,1/4位数+1.5*(3/4位数-1/4位数)]
price_h = data['价格'].quantile(q=0.75)
price_l = data['价格'].quantile(q=0.25)
sub_h = data['节省'].quantile(q=0.75)
sub_l = data['节省'].quantile(q=0.25)
data = data[(data['价格']< price_l+1.5*(price_h-price_l)) & (data['价格']>price_h-1.5*(price_h-price_l))]
data = data[(data['节省']< sub_l+1.5*(sub_h-sub_l)) & (data['节省']>sub_h-1.5*(sub_h-sub_l))]
# 查看两个特征的箱线图
fig= plt.figure(figsize=(10,3))
ax1 = fig.add_subplot(121)
plt.boxplot(data['价格'])
plt.title('价格')
ax2 = fig.add_subplot(122)
plt.boxplot(data['节省'])
plt.title('节省')
plt.show()
- 标准化
from sklearn.preprocessing import minmax_scale,StandardScaler # 最小最大标准化 、均值方差标准化
df = pd.DataFrame()
df['价格1'] = minmax_scale(data['价格'])
df['节省1'] = minmax_scale(data['节省'])
df['价格2'] = StandardScaler().fit_transform(np.array(data['价格']).reshape(-1,1))
df['节省2'] = StandardScaler().fit_transform(np.array(data['节省']).reshape(-1,1))
round(df['价格1'].min(),2),round(df['价格1'].max(),2) # (0.0, 1.0) 最小—最大值标准化 即最小值为0 最大值为1
round(df['价格2'].mean(),2),round(df['价格2'].std()**2,2) # (0.0, 1.0) 均值方差标准化服从标准正态分布 即 均值为0,方差为1
- 二值化
- pandas中
way_dummis=pd.get_dummies(data['去程方式'])
way_dummis
- numpy中
from sklearn.preprocessing import OneHotEncoder
a = np.array(data['去程方式']).reshape(-1,1) # 转成二维矩阵
b = OneHotEncoder(categories='auto').fit(a) # 拟合数据
way = b.transform(a).toarray() # #输出转化值
way
array([[1., 0.],
[1., 0.],
[1., 0.],
...,
[1., 0.],
[0., 1.],
[1., 0.]])
b.get_feature_names() #获取转换后数值的标签
array(['x0_直飞', 'x0_经停'], dtype=object)