爬虫学习——获得数据后的数据存储(csv & Excel 的写入与读取)
目录
一. 获得数据后常用的存储数据的方式
二. csv 写入与读取
三. Excel 写⼊与读取
四. 代码实战
总结
爬虫文章专栏
一. 获得数据后常用的存储数据的方式
常用的存储数据的方式有两种——存储成 csv 格式文件、存储成 Excel 文件。
1.1 csv 和 Excel 的区别
- csv 也是⼀种字符串⽂件的格式,它组织数据的语法就是在字符串之间加分隔符——⾏与⾏之间是加换⾏符,同列之间是加逗号分隔。
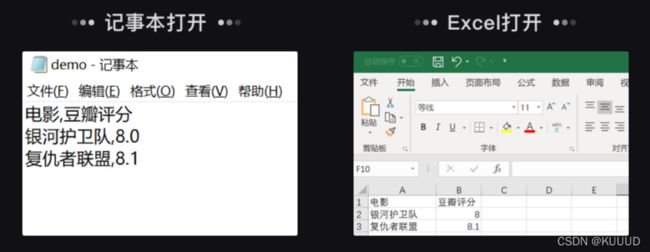
- 它可以⽤任意的⽂本编辑器打开(如记事本),也可以⽤ Excel 打开,还可以通过 Excel把⽂件另存为 csv 格式(因为 Excel ⽀持 csv 格式⽂件)。
1)csv ⽂件⽤记事本打开

2)csv ⽂件⽤ Excel 打开

注意:csv ⽂件⾥的逗号可以充当分隔同列字符串的作用;
1.2 csv 和 Excel 的优缺点
- csv 格式存储数据,读写⽐较⽅便,易于实现,⽂件也会⽐ Excel ⽂件⼩。但 csv ⽂件缺少Excel ⽂件本身的很多功能,⽐如不能嵌⼊图像和图表,不能⽣成公式。
- Excel ⽂件,不⽤我多说你也知道就是电⼦表格。它有专⻔保存⽂件的格式,即 xls 和xlsx(Excel2003 版本的⽂件格式是 xls,Excel2007 及之后的版本的⽂件格式就是 xlsx)

1.3 存储数据的基础知识
二. csv 写入与读取
2.1 模块调用:
因为 csv 为内置函数,无需安装,即可使用;
import csv2.2 创建 csv 文件 :
# 引用csv模块。
import csv
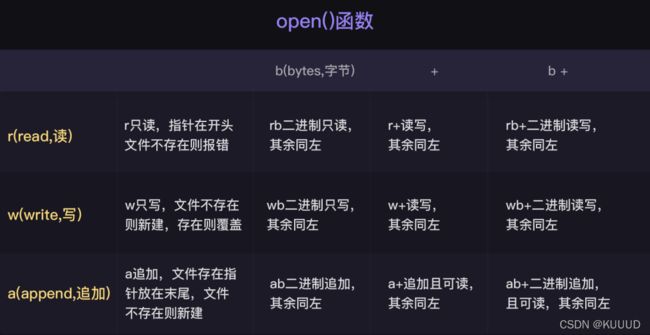
# 创建csv文件,我们要先调用open()函数,传入参数:文件名“demo.csv”、写入模式“w”、newline=''、encoding='utf-8'。
csv_file = open('demo.csv','w',newline='',encoding='utf-8')
- 'demo.csv' 为我们新创建的⼀个 csv 文件;
- 'w' 就是 writer,即文件写⼊模式,它会以覆盖原内容的形式写入新添加的内容;
2.3 创建 writer 对象
# 引用csv模块。
import csv
# 调用open()函数打开csv文件,传入参数:文件名“demo.csv”、写入模式“w”、newline=''、encoding='utf-8'。
csv_file = open('demo.csv','w',newline='',encoding='utf-8')
# 用csv.writer()函数创建一个writer对象。
writer = csv.writer(csv_file)2.4 往 csv ⽂件写⼊新的内容
调用 writer 对象的 writerow() ⽅法(提醒:writerow() 函数⾥,需要放⼊列表参数,所
以我们得把要写⼊的内容写成列表。就像 ['电影','⾖瓣评分'] )
# 引用csv模块。
import csv
# 调用open()函数打开csv文件,传入参数:文件名“demo.csv”、写入模式“w”、newline=''、encoding='utf-8'。
csv_file = open('demo.csv','w',newline='',encoding='utf-8')
# 用csv.writer()函数创建一个writer对象。
writer = csv.writer(csv_file)
# 调用writer对象的writerow()方法,可以在csv文件里写入一行文字 “电影”和“豆瓣评分”。
writer.writerow(['电影','豆瓣评分'])
# 在csv文件里写入一行文字 “银河护卫队”和“8.0”。
writer.writerow(['银河护卫队','8.0'])
# 在csv文件里写入一行文字 “复仇者联盟”和“8.1”。
writer.writerow(['复仇者联盟','8.1'])
# 写入完成后,关闭文件就大功告成啦!
csv_file.close()
运行代码后,名为“demo.csv”的文件会被创建。用Excel或记事本打开这个文件:
补充一点:csv模块本身还有很多函数和方法,附上csv模块官方文档链接,有兴趣的朋友自取:https://yiyibooks.cn/xx/python_352/library/csv.html#module-csv

三. Excel 写⼊与读取
3.1 Excel 的基本概念
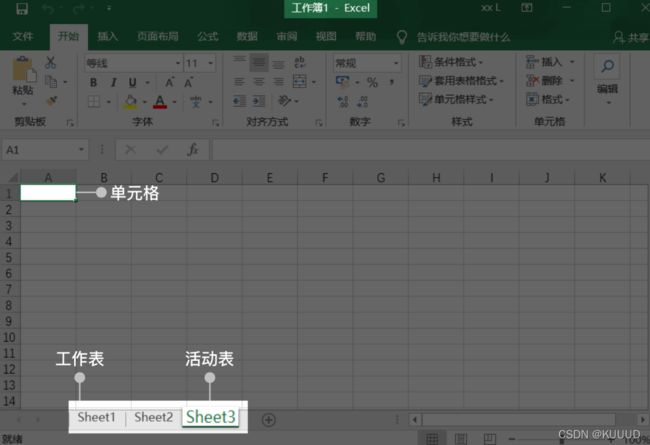
- ⼀个Excel⽂档也称为⼀个⼯作薄(workbook),每个⼯作薄⾥可以有多个⼯作表(wordsheet),当前打开的⼯作表又叫活动表;
- 每个⼯作表⾥有⾏和列,特定的行与列相交的⽅格称为单元格(cell)。比如上图第A列和第1⾏相交的⽅格我们可以直接表示为A1单元格。
3.2 Excel 的写⼊读写
1)模块安装:
- window 电脑:在终端输⼊命令:pip install openpyxl,按下 enter 键;
- mac 电脑:在终端输⼊命令:pip3 install openpyxl,按下 enter 键。
2)模块调用 :
import openpyxl3)创建新的工作簿:
# 引用openpyxl
import openpyxl
# 利用openpyxl.Workbook()函数创建新的workbook(工作簿)对象,就是创建新的空的Excel文件。
wb = openpyxl.Workbook()4)获取工作表:
# wb.active就是获取这个工作簿的活动表,通常就是第一个工作表。
sheet = wb.active
# 可以用.title给工作表重命名。现在第一个工作表的名称就会由原来默认的“sheet1”改为"new title"。
sheet.title = 'new title'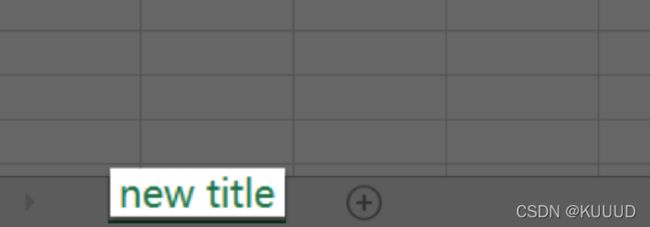
5)单元格内写入内容:
# 把'漫威宇宙'赋值给第一个工作表的A1单元格,就是往A1的单元格中写入了'漫威宇宙'。
sheet['A1'] = '漫威宇宙' 接下来可以用append 函数往工作表内写入内容:
# 把我们想写入的一行内容写成列表,赋值给row。
row = ['美国队长','钢铁侠','蜘蛛侠']
# 用sheet.append()就能往表格里添加这一行文字。
sheet.append(row)6)保存 Excel 文件:
# 保存新建的Excel文件,并命名为“Marvel.xlsx”
wb.save('Marvel.xlsx')7)完整代码 :
import openpyxl
# 写入的代码:
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = 'new title'
sheet['A1'] = '漫威宇宙'
rows = [['美国队长','钢铁侠','蜘蛛侠','雷神'],['是','漫威','宇宙', '经典','人物']]
for i in rows:
sheet.append(i)
print(rows)
wb.save('Marvel.xlsx')
# 读取的代码:
wb = openpyxl.load_workbook('Marvel.xlsx')
sheet = wb['new title']
sheetname = wb.sheetnames
print(sheetname)
A1_cell = sheet['A1']
A1_value = A1_cell.value
print(A1_value)
四. 代码实战
以爬取博主自己博客为例,代码如下:
import requests
# 引用requests模块
import openpyxl
# 创建工作簿
wb = openpyxl.Workbook()
# 获取工作簿的活动表
sheet = wb.active
# 工作表重命名为KUUUD。
sheet.title = 'KUUUD'
sheet['A1'] = '文章题目'
sheet['B1'] = '文章网址'
sheet['C1'] = '点赞数'
sheet['D1'] = '观看量'
sheet['E1'] = '评论数'
sheet['F1'] = '发布时间'
url = 'https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=weixin_53919192'
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'}
res_articles = requests.get(url,headers=headers)
# 调用get方法,下载评论列表
json_articles = res_articles.json()
# 使用json()方法,将response对象,转为列表/字典
list_title = json_articles['data']['list']
# 一层一层地取字典,获取评论列表
for article in list_title:
# list_comments是一个列表,comment是它里面的元素
article_name = article['title']
article_url = article['url']
article_diggCount = article['diggCount']
article_viewCount = article['viewCount']
article_commentCount = article['commentCount']
article_postTime = article['postTime']
sheet.append([article_name, article_url, article_diggCount, article_viewCount, article_commentCount, article_postTime])
print(article_name, article_url, article_diggCount, article_viewCount, article_commentCount, article_postTime)
# 最后保存并命名这个Excel文件
wb.save('KUUUD.xlsx') 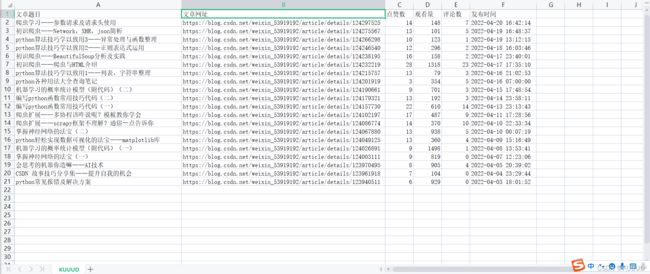
总结
程序员写代码并不是从0开始的,我们也是需要借助多个模板拼接,使得代码能够实现我们的想法,而且也并非默写出来,毕竟学习编程是开卷学习,开卷使用,本文介绍了网页爬虫获取数据后数据存储两种方法,而且应该注意的是本文的代码不一定一直具有有效性,毕竟爬虫与防爬也在一直进步,但本文爬虫的模板概念的介绍还是一直有效的,希望对你有帮助,加油,希望你我一同走进爬虫的世界~~
欢迎大家留言一起讨论问题~~~
注:本文是参考风变编程课程资料(已经授权)及部分百度资料整理所得,系博主个人整理知识的文章,如有侵权,请联系博主,感谢~
爬虫文章专栏
https://blog.csdn.net/weixin_53919192/category_11748211.html https://blog.csdn.net/weixin_53919192/category_11748211.html
https://blog.csdn.net/weixin_53919192/category_11748211.html